 |


■後藤弘茂のWeekly海外ニュース■CellのSPEはJAVA VMのハードウェア化? |
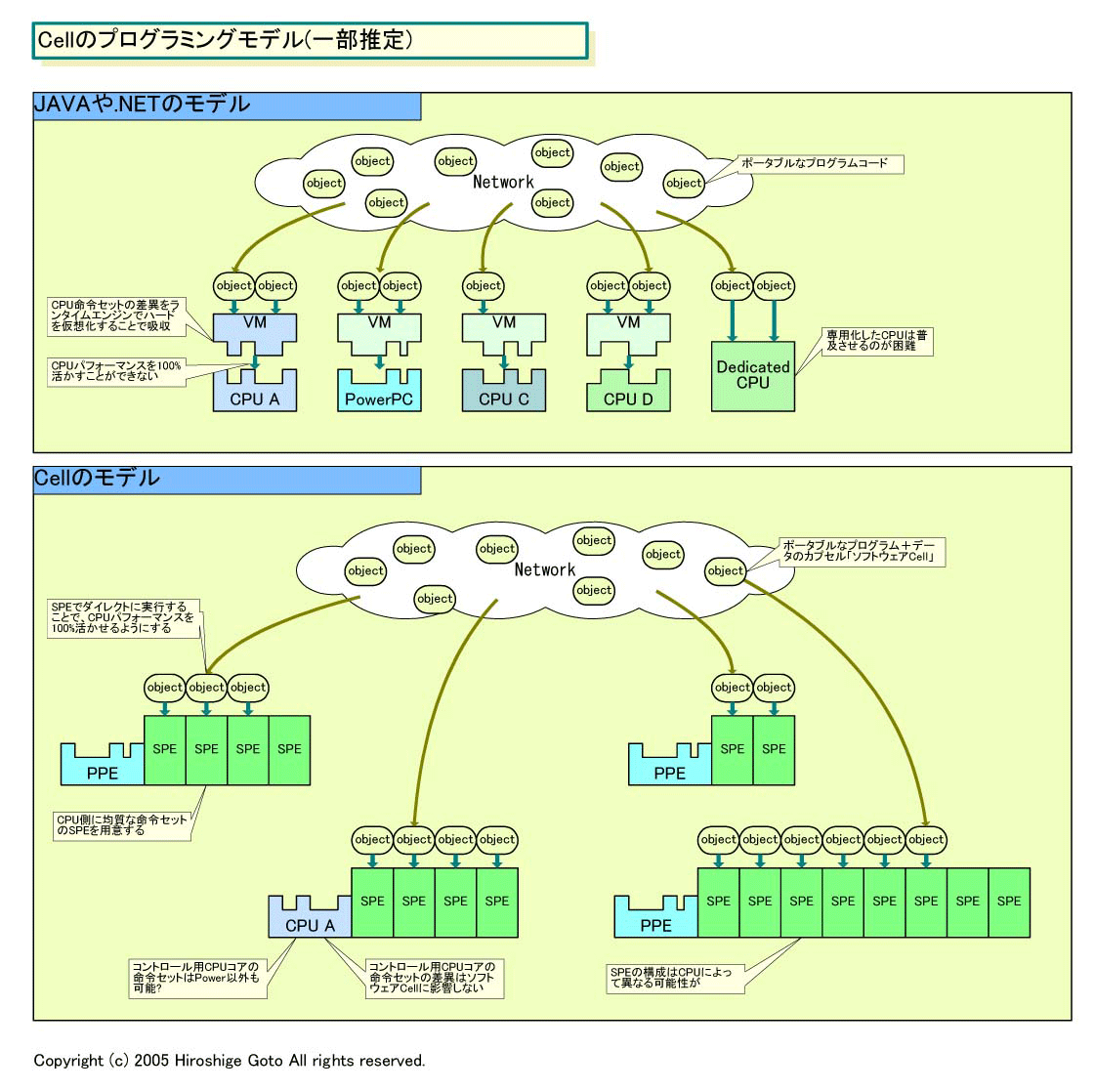
●JAVAや.NETのアナロジーとしてのCell
CellはCPUコアを2種類に分化させることで効率化を図ったCPUだ。主にOSのコントロール系タスクに特化したCPUコア「PPE(Power Processor Element)」1個と、主にアプリケーションのデータ処理に特化したCPUコア「SPE(Synergistic Processor Element)」8個を備えている。命令セットアーキテクチャ(ISA)が異なるPPEとSPEという2種のプロセッサコアの混載は複雑に見えるかもしれない。しかし、これは、Cellの根本思想に立ち戻るとずっとすっきりと整理できる。
「SPEの命令セットアーキテクチャは、JAVAや.NETつまりCLR(Common Language Runtime)などのそれと、ある意味で類似のものだ」とSCEIの鈴置雅一氏(Vice President of Microprocessor Development Department, SCEI)は語る。
なぜ、Cellで、JAVAや.NETが引き合いに出させるのか。それは、Cellの元々の思想がJAVAや.NETのポータビリティを、高いパフォーマンスで実現することにあるからだ。JAVAや.NETの目的は、プログラムを特定のCPUの命令セットアーキテクチャ(ISA)への依存から解き放つことにある。JAVAや.NETでは、基本的には中間コードにコンパイルされたプログラムを、ランタイムソフトウェアが各CPUのネイティブコードにリアルタイムでコンパイルする。そのため、同じコードを、異なる命令セットのCPU上で走らせることができるが、トランスレーションのオーバーヘッドがあるため、CPUパフォーマンスをフルに活かすことが難しい。特に、リアルタイム処理が要求されるマルチメディア系アプリケーションでは、この問題は大きな障壁になっている。
●Cellの思想はポータビリティ
そこで、Cellでは、CPU側にアーキテクチャ的な均質なプロセッサモジュールを用意、各モジュール上で共通のコードを走らせることでポータビリティを実現する。均質なアーキテクチャのプロセッサモジュールを、用途や分野の異なる多種のCPUに実装することで、そのモジュールのネイティブ命令セットのコードをポータブルにする。ゲーム機、ワークステーション、サーバー、ホームサーバー、デジタルTV、携帯機器といった多様な機器に、それぞれフィットするCellを用意することで、異なる機器間でポータブルに走るリアルタイム性の強いプログラムを実現する。また、Cell搭載機器間での、ネットワーク上での分散処理も容易になる。これが、Cellコンピューティングの基本的な考え方だ。
こうしたCellの思想から、実際のCellプロセッサを見ると違った見え方をしてくる。すごく乱暴な言い方をしてしまえば、JAVA Virtual Machineや.NETのCLRをハードウェア化したものがSPEだ。ソフトウェアのJAVA VMや.NET CLRでコード走らせる代わりに、ハードウェアのSPEでコードを走らせると考えればわかりやすい。もちろん、実際には様々な違いがあるが、基本的なコンセプトはそこから来ている。
そうした見方で言うと、原理的にはSPEを搭載するCPUなら、同じアプリケーションが走ることになる。例えば、比較的シンプルなPPEの代わりにシングルスレッド性能も追求した大型CPUコアと、8個のSPEといった組み合わせも可能になる。もちろん、その逆に、OS用のPPEをもっと小型化し、SPEの数を減らした携帯機器向けの構成も考えられる。あるいは、PPEの代わりにx86系CPUコアやMIPS系CPUコアを搭載したバージョンですら、理論上はありえる。
●アドレススペース面でポータブルに
「我々の最終ゴールはSPEプログラムを、アドレススペースの観点からポータブルにすることだった。そのために、我々は各SPEにアタッチしたDMAコントローラに、PowerPC互換のアドレス変換メカニズムを実装した」、「アドレス変換、アイソレートSPEモードこうした要素がポータビリティを実現する」と鈴置氏は語る。
SPEの内蔵メモリ「Local Store(LS)」は、各SPEがそれぞれ別個のアドレス空間を持っている。アドレス空間は各コア間で共有されない。これは、IntelやAMDのマルチコアが、同じメモリ空間を共有し、各CPUコアに干渉するキャッシュを備えることと大きく異なる。SPEのメインメモリに対するアクセスは、SPEそれぞれに1個ずつアタッチされたDMAを通して行なう。この際に、PowerPCのメモリアドレス空間にアドレス変換する。DMA経由のメインメモリアクセスで整合性を取る。
SPEはメモリアドレス空間から見ると、それぞれ独立しており、それによってポータビリティを保つことができる。一見ムダに見える、SPE単位でのDMAコントローラの実装はこのためだという。ちなみに、SCEIの申請したCell関連特許では、内蔵DRAMを前提としてサンドボックス(sandbox)型のメモリ制御が説明されていた。
●PPEがSPEのリソースをアロケート
SCEIの申請特許では、SPEのプログラム+データを「ソフトウェアCell」として規定の形式のヘッダを備えたオブジェクトフォーマットにカプセル化するモデルが説明されている。もちろん、ソフトウェアCellをCellハードが直接扱うわけではなく、ソフトウェア層がソフトウェアCellのヘッダの解析などを行なう。ソフトウェアCellを使わないプログラミングモデルもありうる。
実際のCellでの制御では、PPEが各SPEにタスクを振り分ける。
「コントロールプロセッサ(PPE)は、リソースを調整して、各データポイントプロセッサ(SPE)にそれぞれ専用の仕事を割り当てる。非常に調停的な調整を行なうため、マシンを非常に効率的に走らせることが可能となる」とCell開発を担当したIBMのJim Kahle(ジム・ケール)氏(IBM Fellow)は語る。
具体的なSPEへのPPEのコントロールは次のように行なう。
「プログラミングモデルにも依存するが、PPEは、まず、ストリーミングプログラミングのキックを行なう必要がある。具体的には、(ストリームの)最初のプログラムとデータのセットをSPEのローカルストアに送り、プログラムをキックする。しかし、そのあとは、SPE自身がSPE内蔵DMAコントローラをキックすることで、(PPEを介することなく)自動的に(プログラムとデータのローカルストアへの転送)操作を続ける。PPEがしなければならないのは、最初のキックだけだ」(SCEIの鈴置雅一氏)
SPEは、特にストリーム型の処理を意識して設計されている。ストリームの最初のピースをSPEに転送すると、あとはSPE側が継続して処理を行なうため、PPEの負担は最小で済む。PPE側はSPEに割り当てたタスクが終了するまで、基本的には何もする必要がない。ソフトウェア側でも、SPEへの転送を意識する必要はない。
●Coarse-Grain型でタスクを制御
ただし、1つのタスクでは、メインメモリからのデータ転送のレイテンシのためにSPEの処理がストールしてしまう可能性がある。そのため、SPE上で2スレッドを走らせ、各スレッドのデータロード待ちを隠蔽するといった手法を考えている。「SPE内部では、ダブルバッファリングを行なうことで、処理を途切れさせることなくできる」(SCEI、鈴置氏)
つまり、ローカルストアを128KBずつといった分割で、それぞれに2スレッドのデータプログラムを置いて、ロード待ちが入った時点でタスクを切り替えることで、SPEをストールさせないで処理を継続させる。もっとも、SPEはタスクスイッチのペナルティが大きいため、粒度の大きなCoarse-Grain型のタスク管理となる。多くのタスクをスケジューリングして、1個のSPEに割り当てるといった形はとらない。
「SPEについては、我々は非常に粗い(Coarse-Grain)タスクスケジューリングを考えている。SPEには、粒度の細かいスケジューリングは合わないからで、タスクの粒度は非常に大きい。そのため、我々はスケジューリングではなくリソースアロケーションと呼んでいる。リソースアロケーションにはリアルタイムの側面を含んでおり、PPEはSPEリソースだけでなく、EIB(Element Interconnect Bus:Cellの内部バス)帯域もアロケートする」(SCEI、鈴置氏)
また、SPE同士を連携させることもできる。「SPEは他の要素と同期とコミュニケーションのメカニズムを備えている。だから、互いに連携することができる」と東芝の増渕美生氏(Director of Engineering, Toshiba America Electronic Components)は語る。
例えば、1個のSPEにある処理を行なわせ、次のSPEが続く処理を行なうといったパイプライニングを自動的に行なうようにすることが可能だという。また、複数のSPEを並列に並べて処理を分担させることもできる。SPEを柔軟に組み合わせることで、処理量に最適なパイプラインの構成とロードバランシングが可能になるという。
こうして見ると、CellとPlayStation 2のEmotion Engineでは、リソースの制御でも大きく異なることがわかる。単純に比較すると、MIPSコアと「VU(Vector unit)」とDMA転送を手作業で制御するEmotion Engineに対して、Cellはよりインテリジェントで自動化されたリソース管理を行なう。より、ソフトウェア開発者にとってフレンドリになっている。
 |
| Cellのプログラミングモデル(一部推定) PDF版はこちら |
【2月25日】【海外】Pentium 4ベースのCellプロセッサの可能性
http://pc.watch.impress.co.jp/docs/2005/0225/kaigai159.htm
【2月18日】【海外】CPUの新しいトレンド「ヘテロジニアスマルチコア」
http://pc.watch.impress.co.jp/docs/2005/0218/kaigai158.htm
【2月12日】【海外】Cellのパワーの源「SPE」の正体
http://pc.watch.impress.co.jp/docs/2005/0212/kaigai156.htm
【2月9日】【海外】PlayStation 3に搭載されるCellの性能
http://pc.watch.impress.co.jp/docs/2005/0209/kaigai154.htm
(2005年2月28日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] 個別にご回答することはいたしかねます。
Copyright ©2005 Impress Corporation, an Impress Group company. All rights reserved.