 |


■後藤弘茂のWeekly海外ニュース■GeForce FX 5800(NV30)はじつは4パイプ?
|
●ATIはRADEON 9800が真の8パイプであることを強調
NVIDIAのGeForce FX 5800(NV30)ははたして8ピクセルパイプなのか4ピクセルパイプなのか。これがネットなどで議論を呼んでいる。GeForce FX 5800の性能が予想より低いのは、じつは4パイプだからというストーリだ。RADEON 9700/9800は8パイプだから、4パイプは数字の上では貧弱だ。
NV30=4パイプは、ウワサだけではない。先々週にサンノゼで開催されたゲーム開発者向けカンファレンス「GDC (Game Developers Conference)」では、NVIDIA以外のGPU業界関係者が口々にそのポイントを指摘した。彼らの間では、それはもう確認済みの事実という口ぶりだ。ATI Technologiesも2週間前にサンノゼで開いたRADEON 9800(R350)発表会で、R350が“真の8ピクセルパイプ”であることを強調。さらにATIは、下のようなTシャツで、NV30のアーキテクチャを揶揄していた。
 |
| ATIのTシャツ |
要は、RADEON 9700/9800は本当に8パイプを持っているが、4(パイプで8と称しているの)はパイプドリーム(大ぶろしき)だと言っているわけだ。4の部分からはNVIDIAのコーポレートカラーのグリーンになっているところに注意。ちなみに、パイプドリームは、ATIがRADEON 9700のラウンチの時に使ったデモCGのタイトル名でもある。
では、NV30は本当に4パイプGPUなのか。
先々週にサンノゼで開催されたGDCでのインタビューで、NVIDIAはこの問題についての事実を(ある程度まで)明らかにした。しかし、答えを簡潔に伝えるのは難しい。というのは、NVIDIAのNV3x系アーキテクチャは、従来のGPUの常識からは測りにくいからだ。
「GeForce FX 5800ではクロック当たり4つの(各色)32bit浮動小数点演算が可能で、それと同時にクロック当たり4つの整数演算ができる。だから、シェーダ(プログラム)が32bit浮動小数点データしか使わなければ、4が上限になる。しかし、シェーダをうまく作れば、浮動小数点演算と同時に整数演算と並列に行うことで、最大8ピクセル/クロックができる。Cgコンパイラ(NVIDIAのシェーダプログラム用コンパイラ)はそうした最適化ができる」とNVIDIAのGeoff Ballew氏(Product Line Manager)は語る。
●設計思想が大きく異なるNVIDIA
つまり、NV30は8パイプであるが、浮動小数点ピクセルを処理する場合には最大4ピクセル/secしか出ない。ただし、同時に整数ピクセルの処理ができるため、合計では8ピクセル/secの出力(浮動小数点4+整数4)が可能というわけだ。
そのため、NV30のパイプが4か8かという問題は、どう計算するかによる。単純に4か8かとは言いにくい。ただし、NV30の性能が、現状のShader 2.0対応ベンチマークでも期待ほど上がらない原因のひとつがここにあるのは明らかだ。R300/R350は、浮動小数点ピクセル処理でも最大8ピクセル/secとピーク値は2倍だからだ。
なぜこんな設計にNVIDIAはしたのか。これは設計ミスなのか。
そうではない。というのは、NVIDIAにはこうしたアーキテクチャを取った明快な理由があるからだ。それは、現在のアプリケーションではなく、将来のアプリケーションへの最適化やオフラインCG制作を意識した設計をしたこと。それに対して、ATIは将来アプリケーションやオフラインCGも重要だが、そこに最適化してしまうにはまだ早いと判断した。その設計思想の違いが明確に現れている。
「我々とATIは異なる(アーキテクチャの)インプリメンテーションをした。ある状況では片方が有利になるし、別な状況ではもう片方が有利になる」とBallew氏は言う。
実際、アーキテクチャをよく検討すると、問題の本質はパイプ本数という部分にはないことがわかってくる。ポイントは、パイプライン型アーキテクチャか、ユニット分解型アーキテクチャかという点にある。
●パイプ毎にユニットをまとめたATIのアーキテクチャ
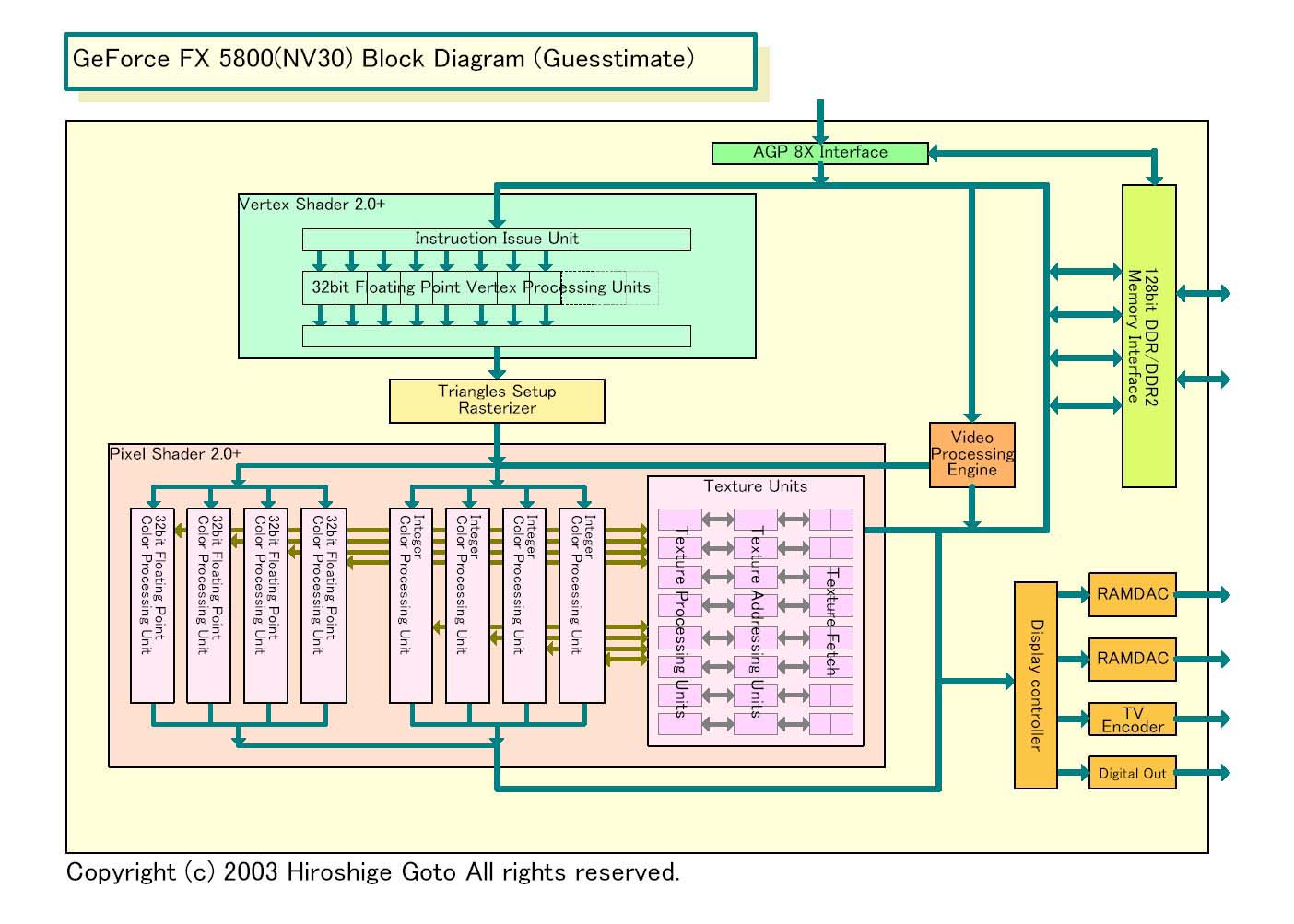
この話を理解するために、まずNVIDIAの説明をベースに、推定されるNV30のブロック図を作ってみた。新情報により、以前作ったものとはピクセル処理部の推定構造が大きく変わった。もうひとつの図は、比較用に作ったRADEON 9700/9800(R300/R350)の図だ。ATIは今回内部構造をかなり明らかにしているため、この図はほぼ正確だと思う。
 |
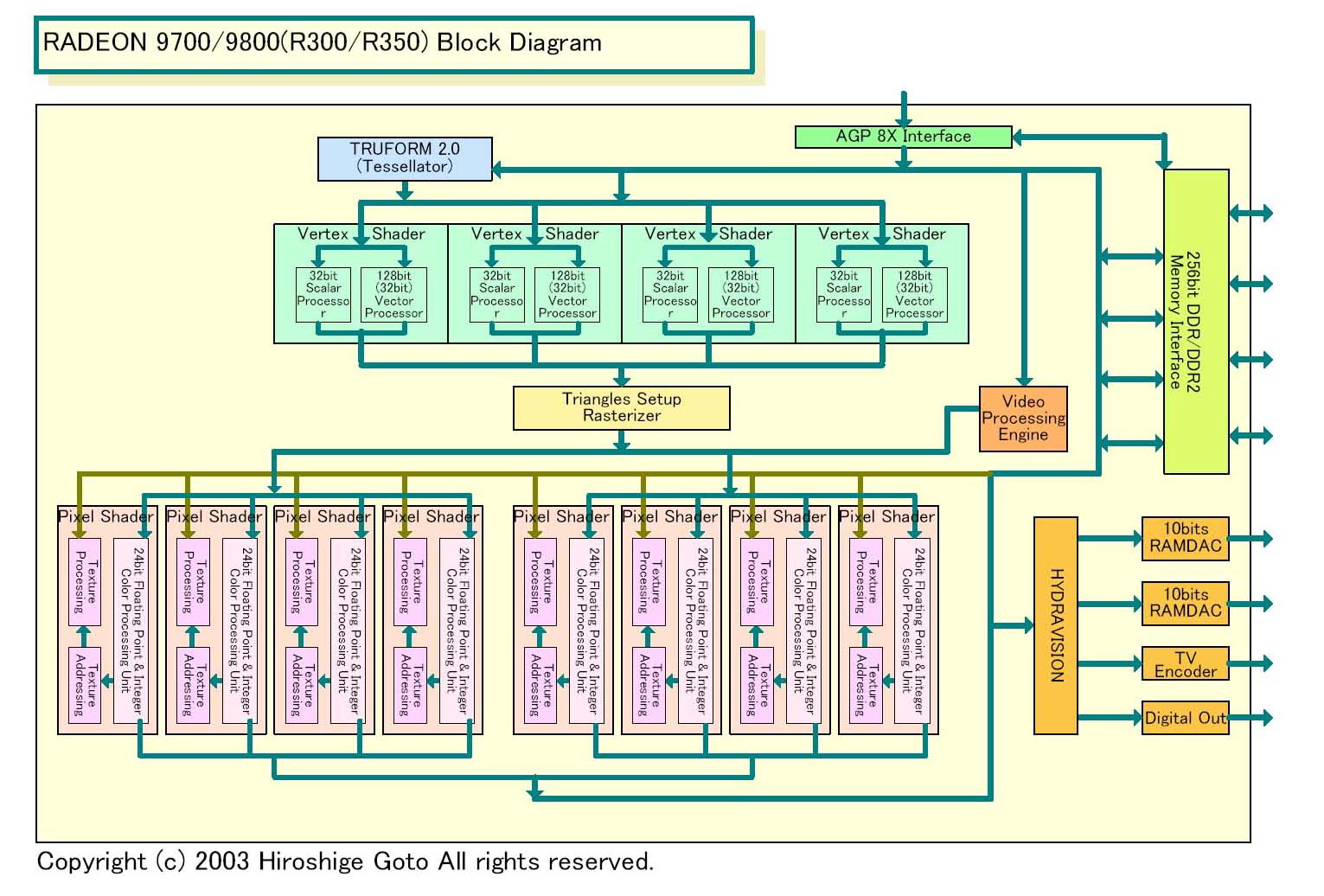 |
| 【NV30ブロック図】 | 【R300/R350ブロック図】 |
まず最初に、ピクセルパイプと言った場合にそこに何が含まれているのかを整理しよう。ATIの資料をベースにすると、DirectX 9世代のPixel Shader 2.0では、内部に次のサブ機能ユニットを含む。
・浮動小数点カラー&アルファ演算ユニット
・浮動小数点テクスチャ演算ユニット
・浮動小数点テクスチャアドレスユニット
このうちテクスチャ演算ユニットはテクスチャフィルタリングユニットとセットになっている。テクスチャアドレスユニットは実際には、テクスチャアドレス生成とテクスチャフェッチ(読み込み)部に分けられると推測される。また、データタイプが全て浮動小数点になるわけではないので、各ユニットは整数演算も可能にしなければならない。整数演算サブユニットを備えている可能性もある。その他に、レガシーの固定機能のフォッグやアルファブレンディングのユニットもパイプには含まれる。
ここでR300/R350の図を見るとわかるように、ATIのアーキテクチャでは、これらのサブユニットは全て各ピクセルパイプに含まれている。また、どのパイプも各色24bitの浮動小数点ピクセル演算と整数演算の両方が可能だ。パイプ毎に内容に違いはないため、パイプが2本になればサブユニット数も2倍になる。じつにわかりやすい、従来型アーキテクチャだ。
ちなみにATIは4パイプ毎にスケジューリング制御を行なっている。また、Pixel Shader内部の3つのサブユニットは並列に動作が可能なので、最大3シェーダ命令の並列実行が可能になる。
●Shaderを分解してユニットをフレキシブルに構成可能にしたNVIDIA
次にNV30。こちらは対照的に、Pixel Shaderを構成するサブユニットが完全にばらばらに分けられている。そして、Ballew氏の説明の通りだとすると、おそらく4個の32bit浮動小数点カラー演算ユニットと、4個の整数カラー&アルファ演算ユニットが含まれる。ちなみに、Ballew氏は浮動小数点演算では4演算/クロックが制約だと語ったが、整数ピクセルしか使わなかった場合、4ピクセルなのか8ピクセルなのかは言及しなかった。そのため、浮動小数点ユニット側で整数演算もできる可能性もある。
テクスチャユニットは8個だが、これはカラー&アルファ演算ユニットとは分離されている。つまり、テクスチャユニットとカラー&アルファ演算ユニットは、かなりフレキシブルな組み合わせが可能のようだ。NV30はよく2テクスチャ/パイプと言われているが、これは、4パイプ動作の時には各パイプ2テクスチャユニットになるためだと思われる。また、テクスチャユニットは浮動小数点データに対応しても、それほどはトランジスタ数が増えないと推測される。そのため、どのテクスチャユニットも浮動小数点データ対応になっていると推測される。
ちなみに、NV30では、テクスチャユニット群の構成もちょっと変わっている。「GeForce FX 5800は8個のテクスチャユニットを備えるが、テクスチャアドレスユニットは16個ある。16アクディブテクスチャを保持できる。つまり、16の異なるテクスチャに対して、読み出しをかけられる」とBallew氏は説明する。
これはどうなっているのか。まず、16のアクティブテクスチャを持てると言っても、テクスチャアドレス生成を16テクスチャ/クロックでやる必要があるとは思えない。テクスチャ演算ユニット自体は8個だから、8以上のスループットは不要だ。そうすると、もっともありそうなのは、テクスチャアドレス生成ユニットは8個で、そのアドレスに対してフェッチをかけるユニットが16個あるという構成だ。テクスチャのフェッチはGPU外のDRAMアクセスが伴うためレイテンシが大きい。それを隠蔽するために、こうした構造になっていると推測される。ちなみに、今時のCPUは、アドレス生成ユニットとロードストアユニットが分かれているのが普通だ。
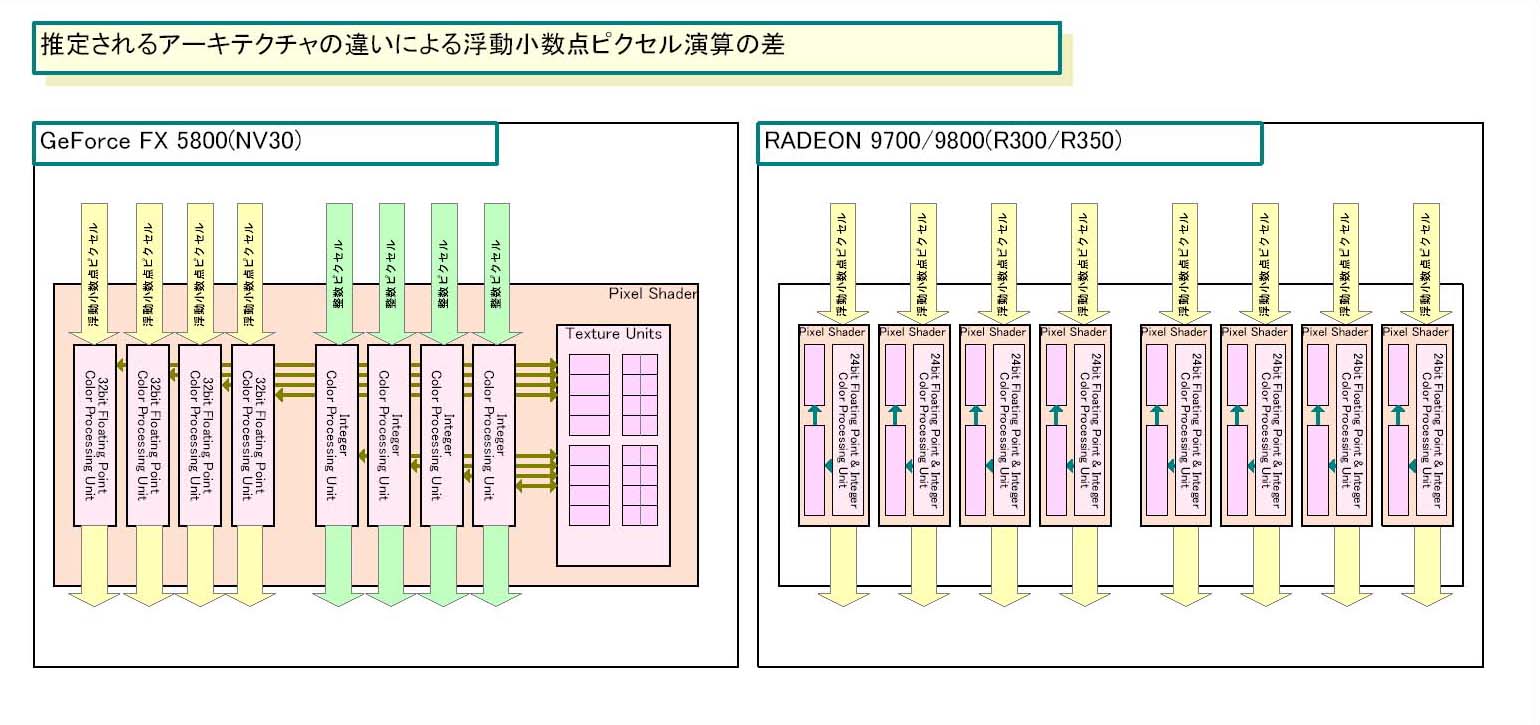 |
| 【NV30とR300/350の浮動小数点ピクセル演算の差】 |
こうして2つのGPUの構造を比べると、浮動小数点ピクセルの処理の際の違いは明白だ。R300/R350は8つの各色24bit(96bit)浮動小数点データを並列に処理できる。それに対して、NV30は4つの各色32bit(128bit)浮動小数点データと、4つの整数データを処理できる。もしユニットの性能が同じだったとしたら、これだけで差は2倍近くになってしまう。
ところが、話はそう簡単ではない。まず、今後のアプリケーションの変化によって、GPU内部のボトルネックがどんどん変わって行く可能性があるからだ。NVIDIAは、明らかにそこに合わせてNV30を設計している。
また、アーキテクチャの差も大きい。NV30の方がShaderの命令セットがリッチで、長いシェーダプログラムをオーバーヘッドなしで走らせることができる。また、オフラインCG制作の場面と同じデータ精度(32bit)を保持できる。これは、大きなアドバンテージだが、その一方で、NVIDIAにとってもう1つの足かせとなっている。このあたりは次回に説明したい。
(2003年3月20日)
[Reported by 後藤 弘茂]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2003 Impress Corporation All rights reserved.