

 |
|
 |
| (1) Willametteのパイプラインのステージ構成 |
まず、(1)の図は、WillametteコアとP6(Pentium Pro/II/III)コアの、基本パイプラインのステージ構成を比較した図だ。IDFで、IntelはP6コアの10ステージに対して、Willametteは20ステージで構成されていると説明した。つまり2倍ということだが、実際には、デコード(x86命令を内部命令μopに変換)のステージがWillametteの基本パイプラインにはないため、Willametteのステージはさらに細分化されている。これだけ細分化されたパイプラインは、まず見たことがない。『ハイパーパイプライン』というネーミングは、ダテではない。
Willametteでは、デコードは図のようにトレースキャッシュ(TC)の前で行なわれる。このパイプラインは、TCのμopをフェッチするところから始まっている。したがって、TCでミスした場合は、その前のデコードと2次キャッシュからのフェッチから始めることになり、ペナルティは非常に大きくなる。Willametteの弱点は、当然、ここになる。つまり、トレースキャッシュのミスをいかに回避するかに、Willametteの性能はかかっている。
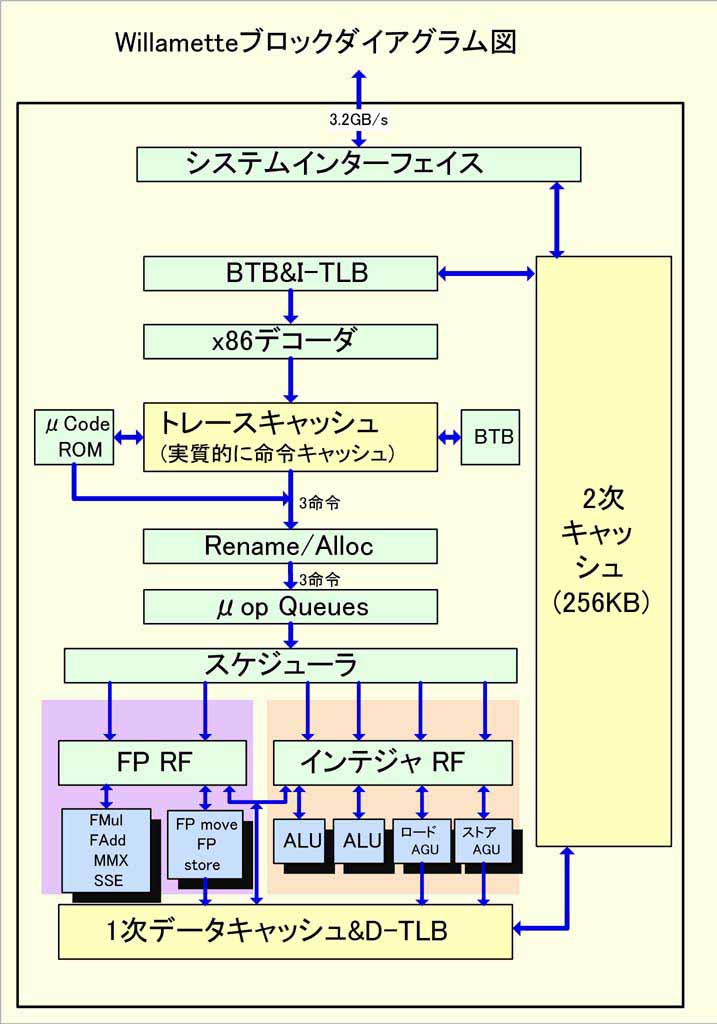 |
| (2) Willametteのブロックダイアグラム |
(2)の図は、Willametteのブロックダイアグラムだ。この図からわかるのは、トレースキャッシュが実質的には1次命令キャッシュである点だ。つまり、従来のP6(Pentium Pro/II/III)コアでは、命令キャッシュからフェッチしたあとでx86命令をデコード(内部命令μopに変換)していたのを、Willametteコアでは、2次キャッシュから命令キャッシュに取り込む段階でデコードしてしまうというわけだ。資料がない段階の前回のコラムでは、トレースキャッシュを命令キャッシュとは別立ての3つ目のキャッシュのように書いてしまったが、むしろ、命令キャッシュのエンハンスメントと見るべきだ。
その下、実行ユニットは、意外とおとなしい。IDFのスライドでは、整数演算ユニット(インテジャALU)が2個、ロード用AGU(アドレス生成ユニット)が1個、ストア用AGUが1個、浮動小数点演算/マルチメディアユニットが2個の構成になっている。合計6個で、イシュー(発行)ポートも6の構成のようだ。構成が異なるので比較は難しいが、実行ユニット数はP6と比べて増えてはいない。ここからも、Willametteの主眼がクロックの向上にあったことがわかる。ただし、WillametteではP6コアのようなイシューポート共有の制約がない。全ユニットに同時発行が可能だと思われ、すっきりした構成になっている。
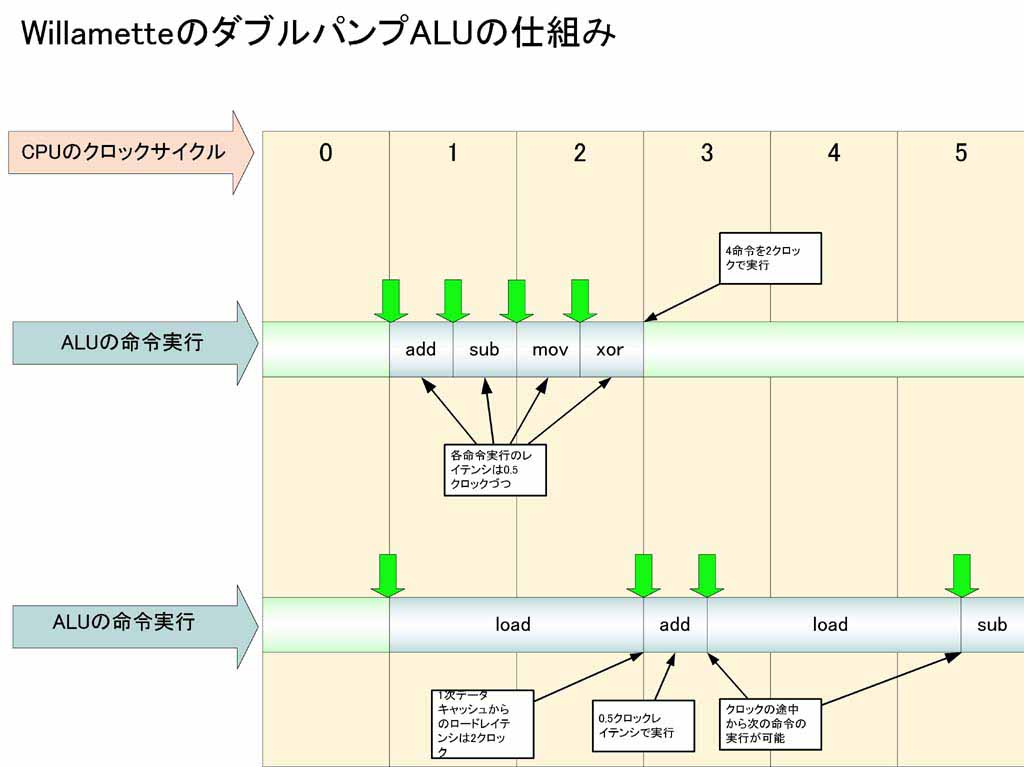 |
| (3) WillametteのダブルパンプALUの動作 |
(3)の図は、Willametteの演算ユニットの大きな特徴であるダブルパンプALUの動作を示した図だ。WillametteのALUは、単純な演算なら0.5クロックレイテンシで実行が可能で、おそらく命令のイシューも0.5クロックごとにできる構造になっている。図の例では、add、sub、mov、xorがそれぞれ0.5クロックレイテンシで、合計4命令を2クロックで実行している。つまり、Willametteはピークでは、1クロックで2命令づつ、2個のALUで合計4命令を1クロックで実行できるわけだ。そのため、Intelでは整数演算ユニット4個を備えた構成と同じ性能を発揮できるとしている。
また、ロード命令のような長レイテンシ(1次データキャッシュからのロードでは2クロック)の命令も、クロックサイクルの途中から実行に入ることができるという。つまり、(3)の図の下の例のように、クロックの途中から始まり途中で終わるといった実行が可能だ。
(2000年2月23日)
[Reported by 後藤 弘茂]