 |


■後藤弘茂のWeekly海外ニュース■GPUとの違いが際立つLarrabeeキャッシュアーキテクチャ |
●増えるプロセッシング能力に追いつかないメモリ
IntelのLarrabeeは、各CPUコアが256KBのL2キャッシュを持ち、そのメモリの中でタイルに分割したレンダリング処理を行なうコンセプトを取っている。IntelがLarrabeeの最大の特徴であるソフトウェアレンダラで、タイリングアーキテクチャを取った理由は、データの局所性(Locality)を最大限に利用するためだ。その背景には、コンピューティング要素を増大させることは簡単だが、データ帯域を増大させることは難しいという現在の半導体チップの問題がある。また、この構造は、内部バス構造を多様なアプリケーションに対応しやすい柔軟なリングバスにすることとも密接に絡んでいる。
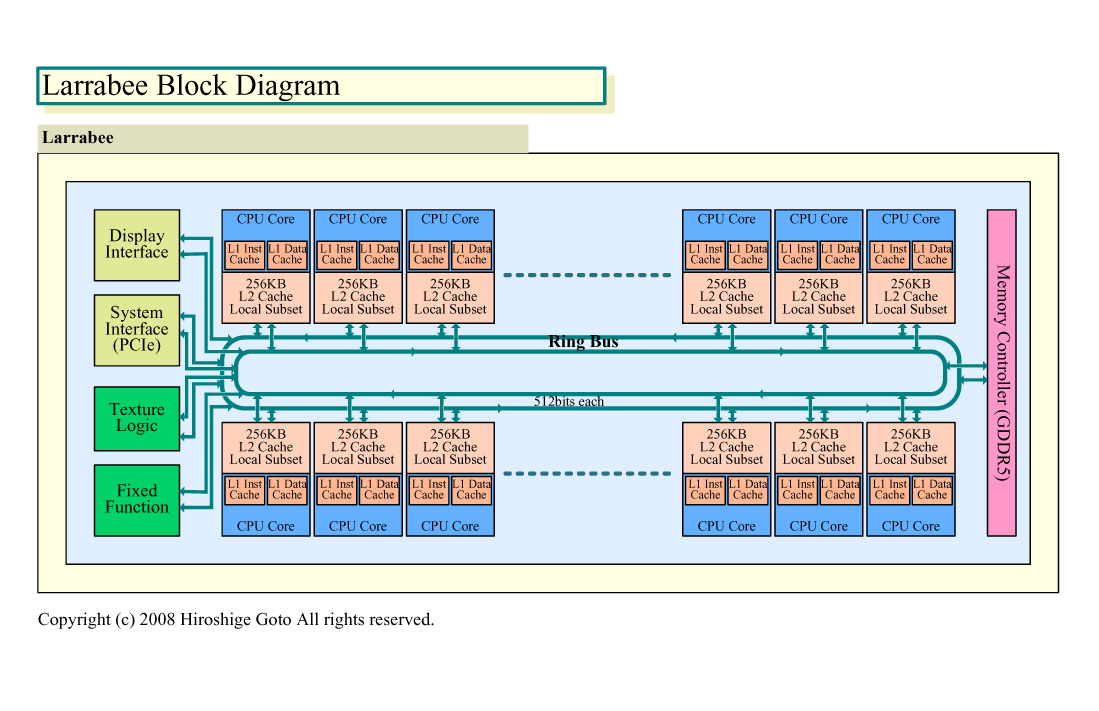 |
| Larrabeeのブロックダイアグラム ※別ウィンドウで開きます (PDF版はこちら) |
簡単に言えば、Intelは、Larrabeeを、ハイエンドGPUのように超広帯域メモリと特殊なデータパスに頼った構造にはしたくなかった。超広帯域メモリはGPUを巨大なダイ(半導体本体)と消費電力のモンスタチップにしている原因の1つであり、GPUの非対称なデータパスは多様なアプリケーションに対応する柔軟性を落としている。Intelは、外部メモリ帯域への依存がより低く、柔軟でスケーラブルなアーキテクチャを模索した結果、タイリングに行き着いた。
ちなみに、GPUが過去6年間、シェーダプロセッシングへと傾いて来たのも同じ理由だ。NVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist))は、以前、次のように説明していた。
「大きな制約としてDRAM側の技術のため、メモリ帯域が今後もそれほど急激に向上しないという枷がある。メモリ帯域によってGPUのデータフロースルーは限られてしまっている。ところが、GPUは毎世代、搭載するトランジスタが増える。すると、問題は、その増えた分のトランジスタをどう使うかという話になる。つまり、データフロースルーは増やせないが、プロセッシングパワーは増やすことができると。すると、論理的な帰結は、より多くのピクセルを処理するのではなく、よりよいピクセル処理に向かうことになるだろう。そして、それは今後、プログラマブルなプロセッシング能力を増やすことになる」
つまり、そもそもの大元に、プロセッシング能力は伸びるのに、メモリ帯域は伸びないというアンバランスがあった。そのために、GPUはプログラマブル化して、結果として汎用コンピューティングも視野に入れるようになった。そして、その延長に、Larrabeeがある。Larrabeeは、GPUよりさらにメモリ帯域あたりのプロセッシングの比率を上げて、同じメモリ帯域でより高い性能を発揮することを目指す。そのために、頻繁にアクセスするデータ部分を内部メモリに取り込んで、その上で処理を行なうことで外部メモリアクセスを減らそうとしている。
 |
| よりよいピクセル処理へ向かうトレンド |
●データ局所性の利用が電力当たりの性能向上のカギ
こうした「データの局所性」の利用は、もちろん、現在のGPUでも試みられている。それが性能を上げる道であることは、プロセッシングとメモリ帯域のバランス上で明らかだからだ。しかし、GPUでは、充分とは言えない。
例えば、NVIDIAもAMD(旧ATI)も、汎用コンピューティングではデータの局所性を利用できるように、SIMD(Single Instruction, Multiple Data)実行する各プロセッサクラスタ毎にスクラッチパッドタイプのメモリを搭載している(AMDはクラスタ間のメモリも搭載)。NVIDIAアーキテクチャの場合、GPUコンピューティング時にはこのメモリを、各スレッド間の共有メモリとして利用できる。いわゆる「プロデューサ-コンシューマ局所性(Producer-Consumer Locality)」の活用と「ローカルワークセットアップデイト(Local Working-set Update)」が可能になる。しかし、グラフィックス処理では、明示的にメモリにアクセスすることはできない(グラフィックスパイプで書き込みバッファなどに部分的に使っている)。
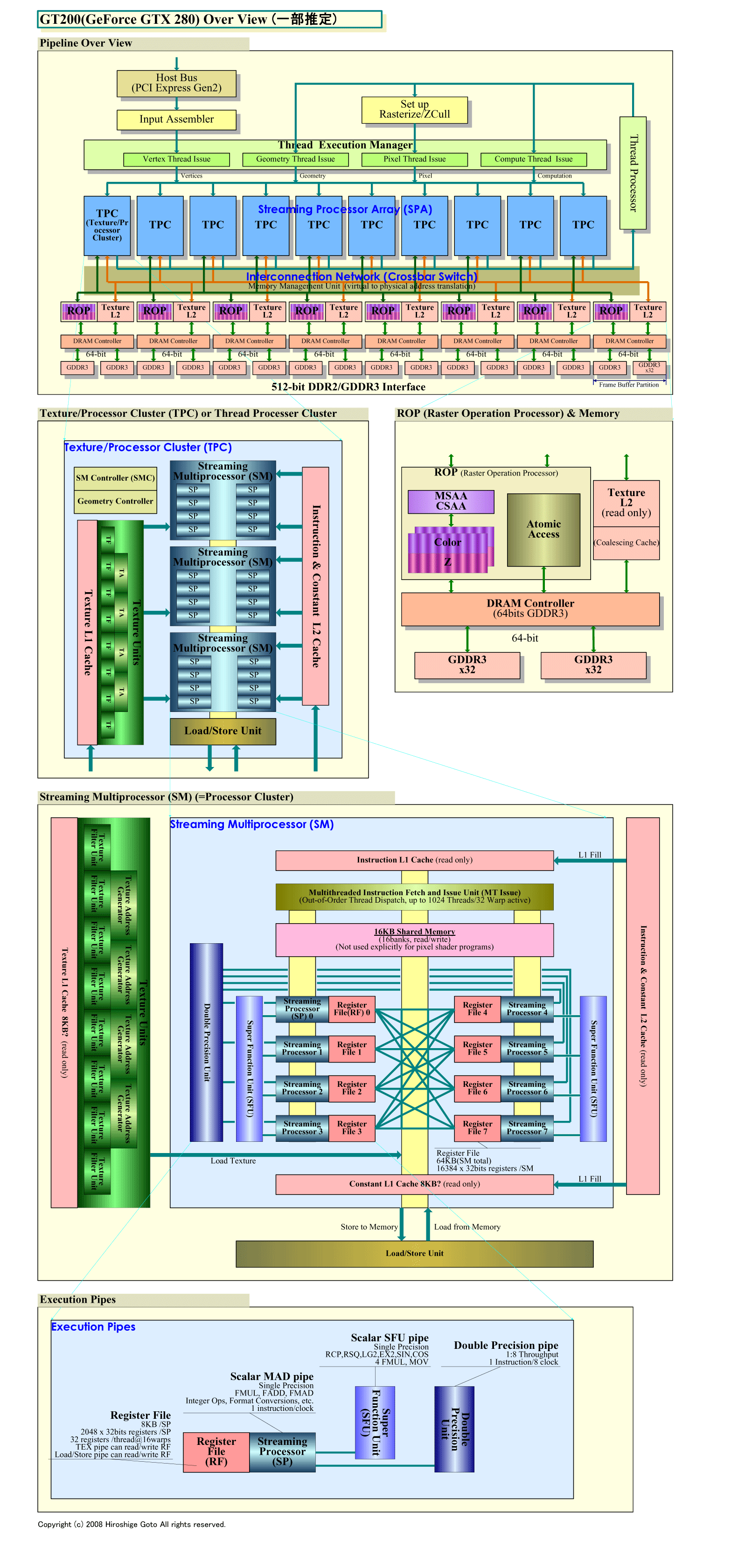 |
| GT200 Over View(一部推定) ※別ウィンドウで開きます (PDF版はこちら) |
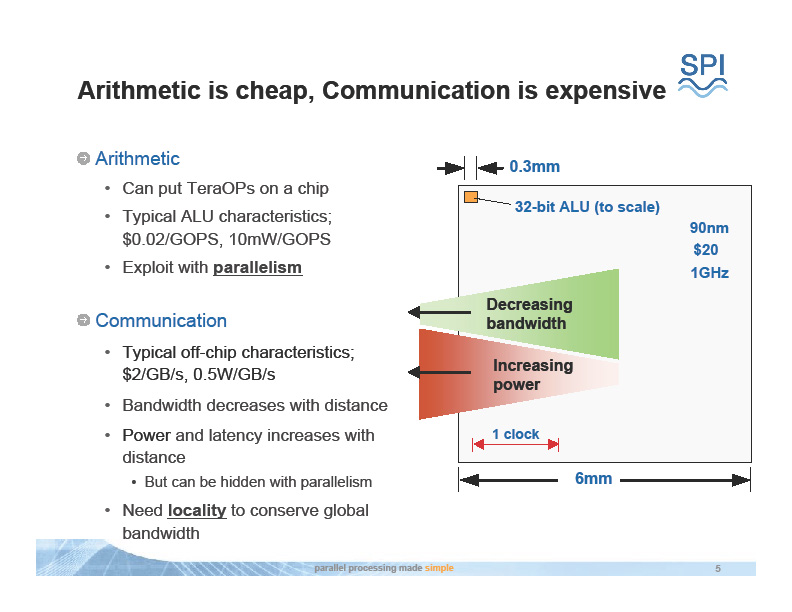
こうしてみると、データ局所性の利用は、伝統的なGPUが最も苦手とする部分であることがわかる。ストリームプロセッシングに特化したメニイコアプロセッサを開発したStream Processors, Inc.のBill Dally氏(Co-founder, Chairman and Chief Scientist, Stream Processors, Inc.)は、GPUの弱点はそこにあると指摘していた。同社のプロセッサは、局所性を活かすための階層化された内部メモリ構造を持つ。下のスライドは旧来のGPUとStream Processorsの比較をしたものだ。
 |
| Stream Processorと従来のGPUの比較 |
ちなみに、SPIは、Dally氏がスタンフォード大学で進めていたストリームプロセッサ研究をスピンアウトさせた企業だ。スタンフォードでのストリームプロセッサの研究には、現在、IntelのリサーチセンターでLarrabeeグラフィックスの研究を行なっているWilliam(Bill) R. Mark氏(Manager, Advanced Graphics Research Group, Intel)も関わっていた。つまり、Larrabeeも源流の1つは、スタンフォード大学での先端グラフィックス研究にある。CUDAの技術リードであるNVIDIAのIan Buck氏も、スタンフォード大学でのシェーディング言語のリーダーだった。各プロセッサの発想に共通項があるのは、同じ源流から来ているからだ。
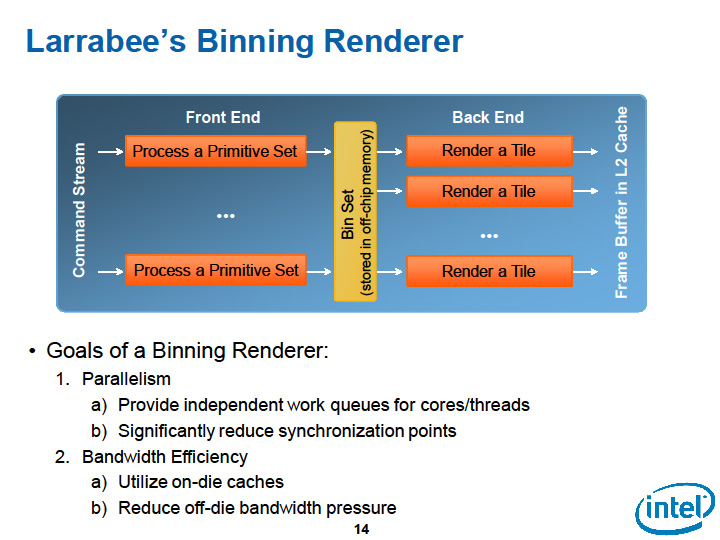
そして、Intelは、LarrabeeではCPU屋の技術を使うことで、よりアグレッシブにデータ局所性を活用して、GPUでは難しい帯域セーブを試みることにした。そして、そのために必要だったのが、レンダリング面を小さなタイルに分割するタイリングアーキテクチャだった。ここはトレードオフとなる。
●データ局所性の活用のためタイルアーキテクチャを取る
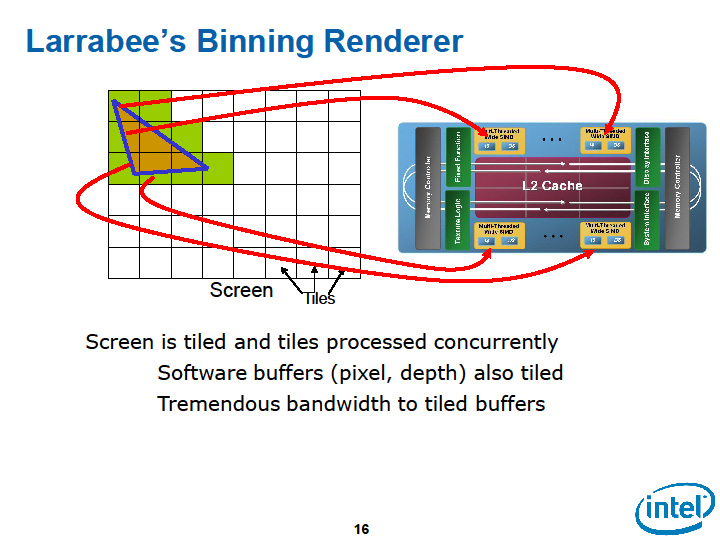
Larrabeeのソフトウェアレンダリングでのグラフィックス処理では、ピクセルデータは全てのレンダリングが終わるまで内部キャッシュメモリ上に留まる。キャッシュからメインメモリへと書き込まれるのは、全てのオーバーラップするプリミティブのレンダリングが終わり、ラスターオペレーションが終わってからとなる。何回も外部メモリにアクセスする代わりに、1回外部メモリから読み込めば、あとは最後に1回外部メモリに書き出すまで、オンチップメモリで処理が完了するようにした。
Larrabeeアーキテクチャの重要なポイントは、この、データ局所性を利用したメモリ帯域の削減にある。局所性の利用のために、Larrabeeでは、各CPUコアが分割された描画面の1タイルの処理を担当するタイリングアーキテクチャを取っている。128ピクセル×128ピクセルといったタイルの描画を各CPUコアが担当し、必要なメモリをキャッシュ上に確保する。カラーとZの書き込みと参照のトラフィックは、CPUコア-L2キャッシュ間に留まる。リングバス上には、原則的には最後のフレームバッファへの書き出しのトラフィックしか生じない。
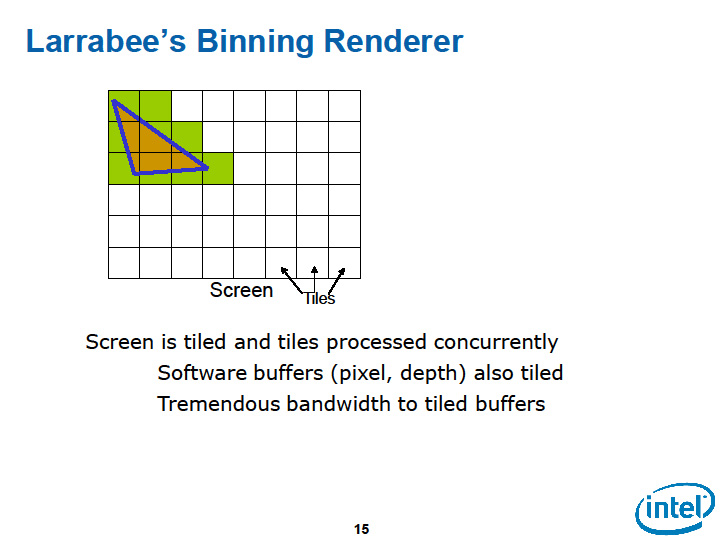 |
 |
 |
| Larrabeeのグラフィックス処理 | ||
タイルのトレードオフはオーバーヘッドだ。以前にこのコーナーで書いた記事には間違いがあって、Larrabeeのタイルもオーバーヘッドが生じる。ただし、Intelは現在のグラフィックスワークロードでは、オーバーヘッドとして増えるトライアングルプロセッシングは5%程度だと見積もっている。
タイルアーキテクチャのチャレンジには、もちろんL2キャッシュの256KBという狭さも含まれる。Intelは、32-bit depthと32-bit colorで128×128タイルなら、256KBのL2の半分しか占めないと説明している。ただし、レンダーターゲットが複数になった場合(MRT)などでは問題が発生する。実質的に複数タイル分のメモリが必要になるからだ。
グラフィックスの歴史では批判も多かったタイルアーキテクチャだが、Intelはデータ局所性を利用するためにはこの手段しかないと判断したようだ。
伝統的GPUは、上記のアクセスのほとんどは外部メモリに対して行なう。膨大なピクセルに対して処理を行なうためメモリレイテンシは隠蔽されるが、メモリ帯域は膨大に食う。Larrabeeの場合は、トラフィックの多くをオンチップに止めることで、帯域をセーブする。現在では、帯域のセーブはイコール消費電力のセーブでもある。そして、電力のセーブは、現在のプロセッサの最大の命題でもある。
 |
| Larrabeeのメモリ帯域問題の解消 |
Larrabeeの場合は、タイリングの制約を受け容れれば、メモリ帯域問題を軽減できる。つまり、CPUアーキテクチャ的な発想では、ソフトウェアさえ最適化すれば、メモリも電力も大幅にセーブできることになる。ここが、電力はある程度犠牲にしても、伝統的グラフィックスでの最高性能を求めるGPUメーカーとの発想の違いとなっている。
●タイルアーキテクチャに合わせたLarrabeeの内部構造
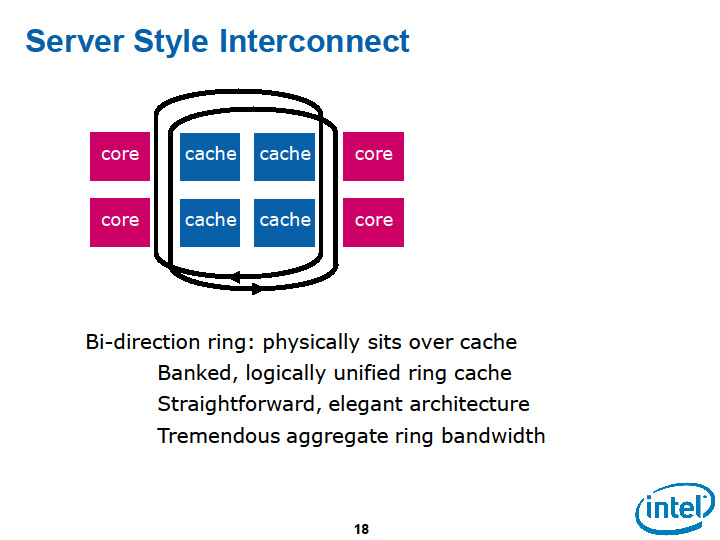
Larrabeeのグラフィックスパイプラインは完全なソフトウェア制御なので、タイリングでない方法を採ることもできる。しかし、IntelはLarrabeeの性能を活かす手法として、タイリングを基本に考えているようだ。と言うより、それがアイデアの出発点にあり、そこからアーキテクチャの開発が始まったと考えられる。それがわかるのは、Larrabeeの内部バスの設計で、アイデアの出発点だった下の図のサーバー型のインターコネクトを止めた理由が、タイリングにフィットしないためだったと説明しているからだ。
「(サーバー型インターコネクトの構成の場合は)タイルのアクセスがリングに行ってしまう。それぞれのタイル(のピクセルデータ)はL1キャッシュに載せきれないからだ。タイルで、リングに溢れないようにするためには、サーバー型の通常のインターコネクトは使うことができなかった」とLarrabeeアーキテクチャを担当するIntelのDoug Carmean氏(Larrabee Chief Architect, Intel)は説明する。
 |
 |
 |
| サーバー向けのLarrabeeのリングバス設計 | ||
タイルアーキテクチャのため、Larrabeeアーキテクチャでは、CPUコアと、タイルのピクセルデータを保持するキャッシュの間のトラフィックが膨大になる。ところが、IntelがLarrabeeで最初に考えたサーバー型のインターコネクトでは、CPUコアにはL1キャッシュだけが統合されており、L2キャッシュは分離されていた。CPUコアとL2キャッシュがリングバスで結ばれた構成の場合、タイルへの読み書きのトラフィックがリングバスを圧迫してしまう。
順番としては「メモリ帯域をセーブするためにデータの局所性を利用する→タイリングアーキテクチャを取る→内部バスの構造をタイリングにフィットしたものにする」と流れたことがわかる。つまり、データの局所性を利用することが、Larrabeeの根本アイデアだった。そして、それに合わせて内部バスやキャッシュの構造などが決まって行った。
●タイルがL2キャッシュにフィットするように改良
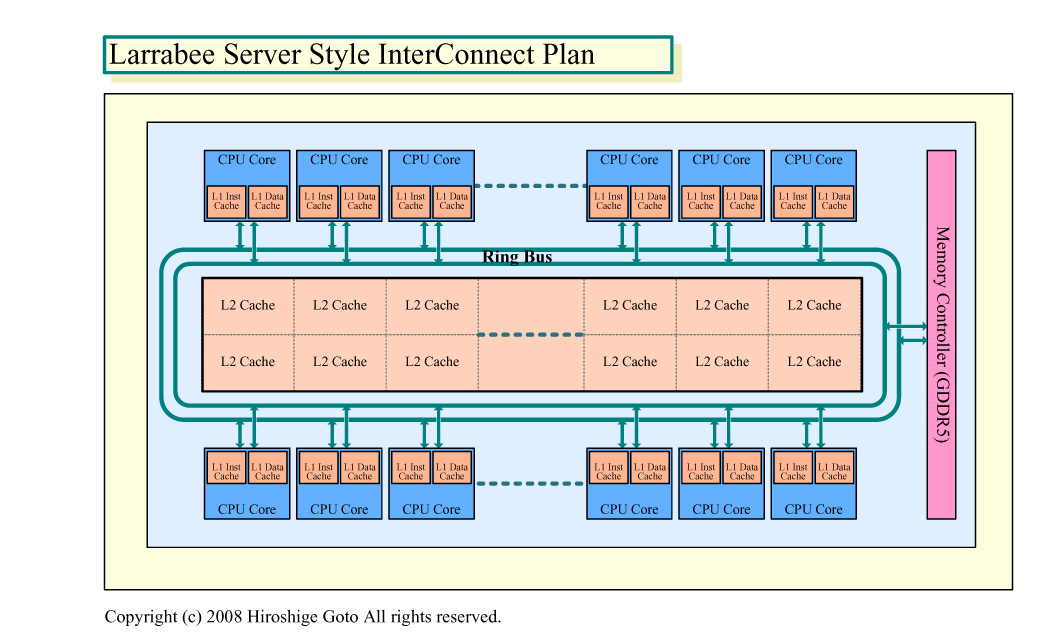
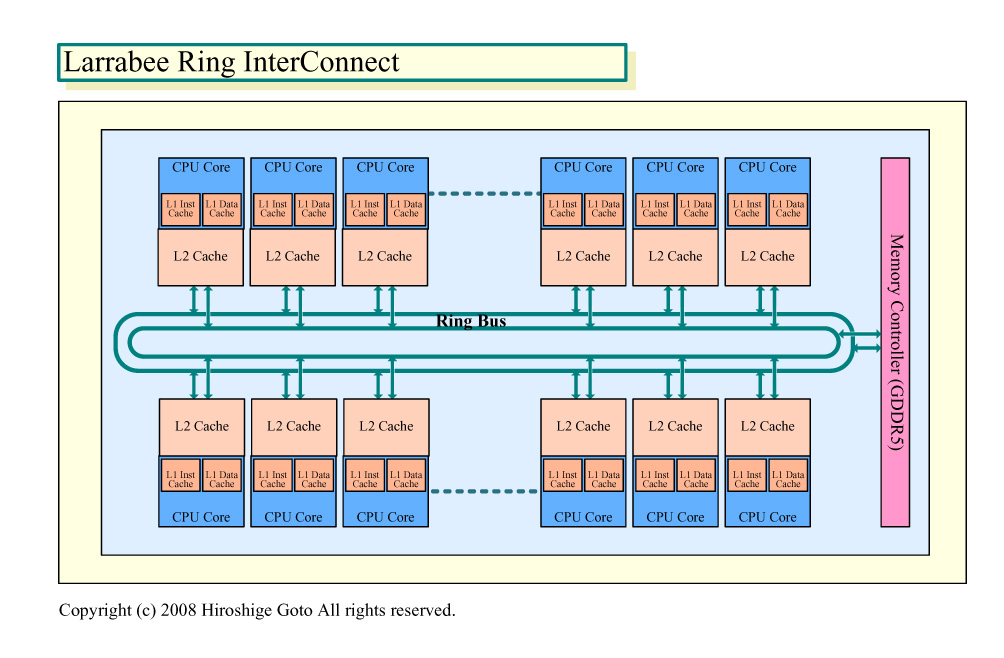
「タイルがL1にフィットしないため、我々はシンプルな修正を(Larrabeeのトポロジに)加えた。『OK、それならリングをキャッシュのもう片方のサイドに移動させよう』と。そうすると、タイルバッファへのアクセスはL2に行き、L2へのアクセスはリングバスには溢れない」とCarmean氏は語る。
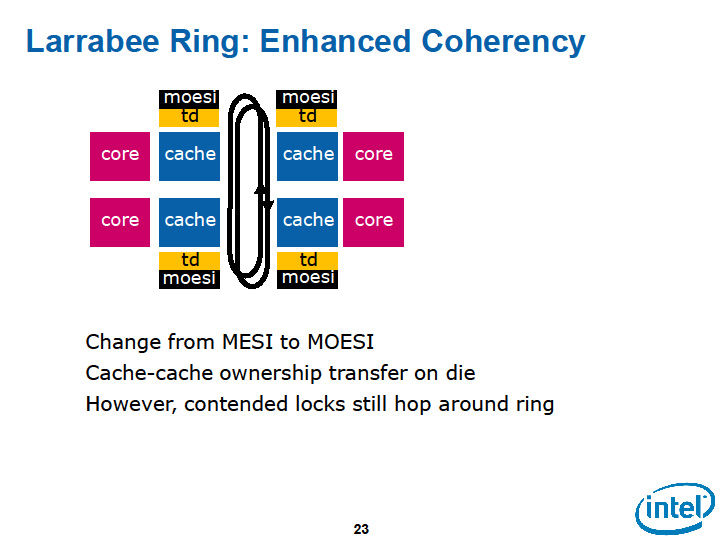
これが今のLarrabeeの基本構成だ。図では下のようになる。各CPUコアがそれぞれ占有するL2キャッシュに直結され、他のコア+L2とのアクセスにリングバスを使う。この方法なら、ピクセルアクセスでリングバスに溢れるトラフィックは最小になる。ただし、以前の単一L2キャッシュ構成にはなかった問題が生じる。それは、分断されたL2キャッシュのコヒーレンシコントロールだ。
 |
 |
| 現在のLarrabeeのリングバス設計 | |
「この構成は、メモリコヒーレンスを考えるまではうまく働く。(コヒーレンスのためには)同期ポイントで必要とされる(キャッシュラインの)オーナーシップを、コア間でどうやって転送するかを考えなくてはならない。(各コアからの)RFO(Read for Ownership)トランザクションにリングを横断させるか、グローバルオブザベーションポイントを加えるかをしなければならない」(Carmean氏)
最大の壁はここにある。キャッシュメモリを各コアに分散すると、コヒーレンシを取ることは難しくなる。CPUコア数が2個や4個の場合は簡単だが、10個を大きく越えるコア数で、さらにスケーラビリティを確保するとなると非常に難しい。コヒーレンシのためのトラフィックが内部バス帯域を食ってしまうと、CPUコア数を増やしても性能を出せなくなってしまうためだ。こうした問題を避けるため、GPUでは、コア間のメモリコヒーレントメカニズムは持たない。Cell Broadband Engine(Cell B.E.)も同様だ。NVIDIAのKirk氏は次のように説明する。
「マルチコアCPUでコア数が2や4なら、ブロードキャスティングやスヌーピングなどのテクニックでコヒーレントキャッシュはできる。しかし、より多くの(コア)数になると、スヌーピングのトラフィックはデータトラフィックを圧迫するようになる。だから、伝統的なCPUアーキテクチャのキャッシュコヒーレンシのアイデアは、GPUのような多くのコア数のプロセッサでは通用しない」
NVIDIAアーキテクチャでは、クラスタ間のメモリコヒーレンシは取られていない。クラスタ内で実行するスレッド間で、メモリ空間を共有できる仕組みとなっている。面倒なコア間のコヒーレンシメカニズムには手を付けなかったというのが実情だ。そして、それがデータ局所性の利用を限定する原因となっている。
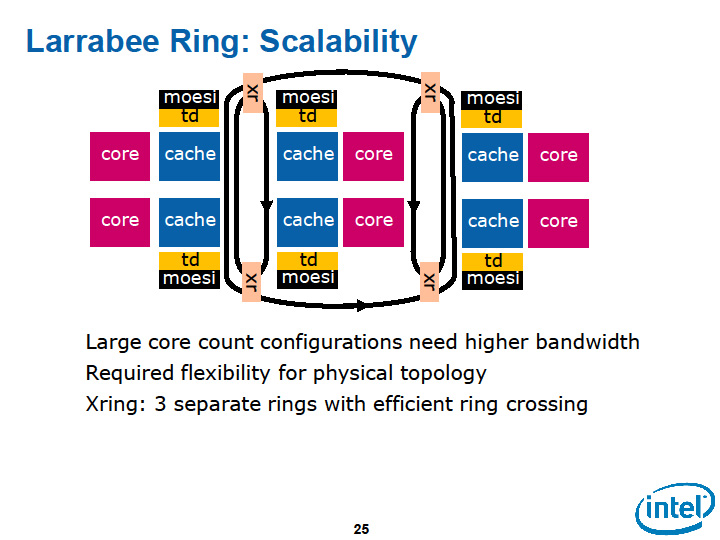
メモリコヒーレンスはメニイコアの最大の障壁の1つで、これをどう解決するかがアーキテクチャのカギであることは確かだ。そして、Larrabeeの大きなポイントの1つは、この問題を解決したことにある。そのカギは、タグディレクトリの構成で、それによってスケーラビリティも確保している。
 |
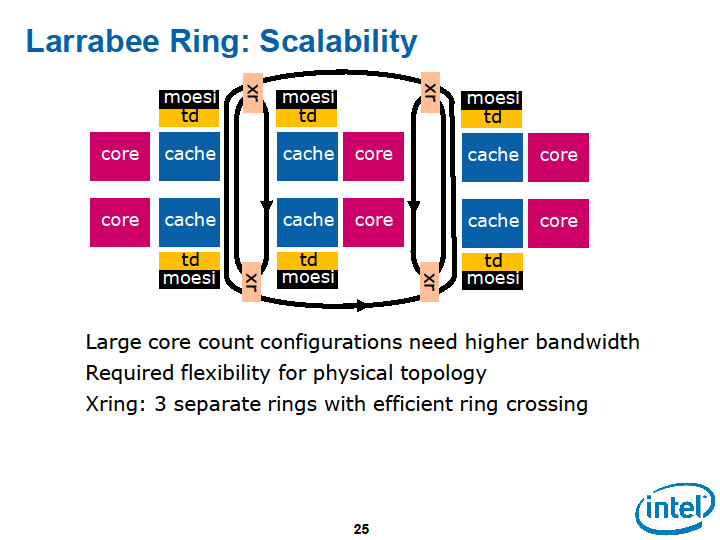 |
| スケーラービリティを確保した設計 | |
□関連記事
【11月11日】【海外】メモリ帯域をセーブするLarrabeeアーキテクチャ
http://pc.watch.impress.co.jp/docs/2008/1111/kaigai475.htm
(2008年11月25日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.