 |


■後藤弘茂のWeekly海外ニュース■NVIDIAのGT200とAMDのRV770のどちらが優れているのか |
●それぞれ利点があるGT200とRV770の両アーキテクチャ
NVIDIAの新フラッグシップGPU「GeForce GTX 200(GT200)」ファミリと、AMD(旧ATI)の新フラッグシップGPU「ATI Radeon HD 4800(RV770)」ファミリ。両GPUは、1TFLPOS前後のコンピューティングパフォーマンスを謳いながらも、そのアーキテクチャには大きな違いがある。部分的には、ほぼ対照的と言っていい設計思想の違いが見られる。
一言で言えば、GT200は汎用コンピューティングにも適したアーキテクチャを目指して、その結果として高いグラフィックスパフォーマンスも実現した。一方、RV770はグラフィックスに最適化した結果、汎用コンピューティングでも威力を発揮するコンピューティングパフォーマンスを得た。GT200は汎用コンピューティングでの高効率のトレードオフとして、制御系のユニットが増えてダイ(半導体本体)が肥大化した。RV770は制御系が極めてコンパクトな高効率のダイを得たトレードオフとして、汎用プログラムでのプロセッサの効率には弱点がある。
どちらのアーキテクチャが時代の流れに適しているのか、まだその解答は出ていない。また、NVIDIAアーキテクチャが、汎用コンピューティングに最適化したと言っても、それはあくまでも“GPUとしては”の話であって、元々汎用的な利用を前提としたプロセッサと較べると制約は多い。あくまでも、汎用とグラフィックスの間で、アーキテクチャのダイヤルを、どの程度振るかという話に過ぎない。
とはいえ、両GPUの違いは大きく、それが両社の方向性の違いも反映しているところが興味深い。そして、アーキテクチャを詳細に見ると、どちらのアプローチにも利点があることがわかる。今回の記事では、NVIDIAのプロセッサアーキテクチャの概要から説明したい。
●3段階の階層構造を持つNVIDIAアーキテクチャ
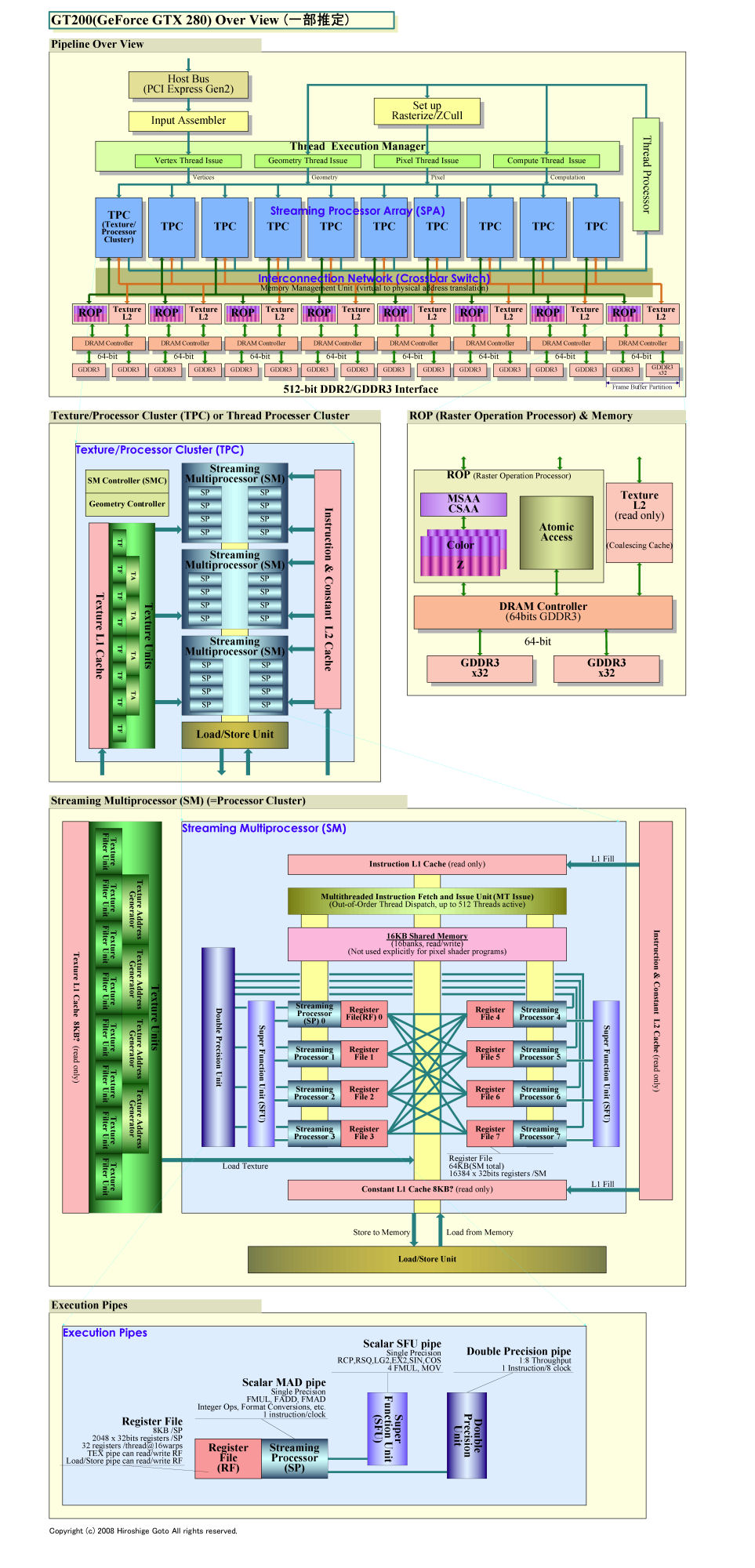
GT200の基本アーキテクチャは、GeForce 8800(G80)のそれを踏襲している。G80を機能的に拡張すると同時に、規模を増大させたのがGT200だ。
NVIDIAのG8x以降のGPUは、3段階の階層構造でプロセッサアレイを形成している。最小は、1スレッドを実行する小さなスカラプロセッサ「SP(Streaming Processor)」。SPを8個バインドしたマルチプロセッサクラスタが「SM(Streaming Multiprocessor)」。SMを複数個と1個のテクスチャユニット(Texture Unit)で構成するコンピューティングとテクスチャリングの統合クラスタが「TPC(Texture/Processor Cluster)」(Thread Processor Clusterと呼ぶ場合もあり)。3レベルだ。GPUによって搭載するTPCの数を変えることで、上位から下位までのGPUの差別化を行っている。
GT200では、単体のスカラプロセッサStreaming Processor(SP)自体は、G80系と較べてほとんど拡張されていない。しかし、SPを8個内蔵するバンドルであるStreaming Multiprocessor(SM)とTPCはかなり変更された。
従来のG80G90系は、各Streaming Multiprocessor(SM)につき、Streaming Processor(SP)が8個、Super Function Unit(SFU)が2個の構成だった。GT200では、これに倍精度の浮動小数点演算ユニット「Double Precision Unit」が1個加わった。さらにレジスタファイル(Register File)が倍増された。各Streaming Multiprocessor(SM)の構成は次のようになる。
・Streaming Processor(SP) 8個
・Super Function Unit(SFU) 2個
・Double Precision Unit 1個
・命令ユニット(Instruction Fetch and Issue) 1個
・32-bitレジスタファイル(Register File) 16,384本
・共有メモリ(Shared Memory) 16KB
・命令L1キャッシュ(Instruction L1 Cache)
・コンスタントL1キャッシュ(Constant L1 Cache)
2個のSuper Function Unit(SFU)は、それぞれ4個のStreaming Processor(SP)で共有され、1個の倍精度浮動小数点演算プロセッサは8個のStreaming Processor(SP)で共有される構成となっている。また、SM内部のレジスタ数は従来は8,192本の32-bitレジスタだったのが、GT200では16,384本の32-bitレジスタ構成へ倍増した。レジスタの倍増は、倍精度サポートのためと、マルチスレッド性能を上げる(メモリアクセスレイテンシを隠蔽する)ためだ。1個のStreaming Processor(SP)当たりのレジスタ本数は2,048本となる(1スレッド当たり32本のレジスタを割り当てた場合に16Warp)。
GPUのオンチップメモリは、キャッシュと言っても、伝統的にリードオンリ(またはライトオンリ)のバッファメモリとなっている。NVIDIAアーキテクチャでは、16KB 共有メモリ(Shared Memory)だけがプロセッサからリード&ライトの両方が可能だ。コンスタントL1キャッシュはリードオンリで、G80世代から拡張されていなければ8KBと推測される。
 |
| GT200の概要(一部推定)※クリックすると別ウィンドウで開きます PDF版はこちら |
 |
| CUDAの概要※クリックすると別ウィンドウで開きます PDF版はこちら |
●SPMDがGPUの特徴的なプログラミングモデル
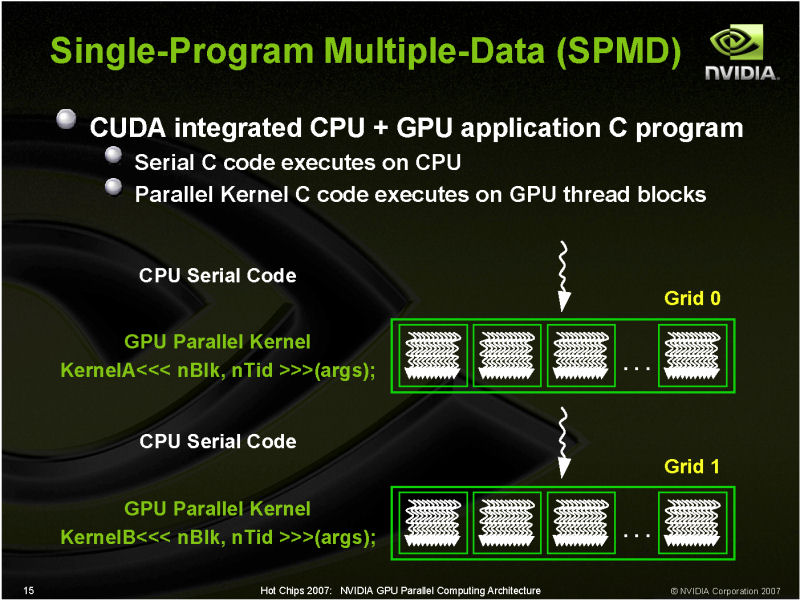
GPUの構造は、一般的なCPUとはずいぶん異なるが、それはGPUの命令実行の仕組みと密接に連動している。
GPUは、一般に「Single Program, Multiple Data(SPMD)」と呼ばれるプログラミングモデルを取っている。プログラマは1つのデータに対するプログラムを書くと、GPU上でプログラムが自動的に展開される。ラフに言えば、シングルスレッドプログラムを書くと、自動的にマルチスレッド実行される。
 |
| SPMDの概要※クリックすると別ウィンドウで開きます |
 |
| CUDAの概要※クリックすると別ウィンドウで開きます |
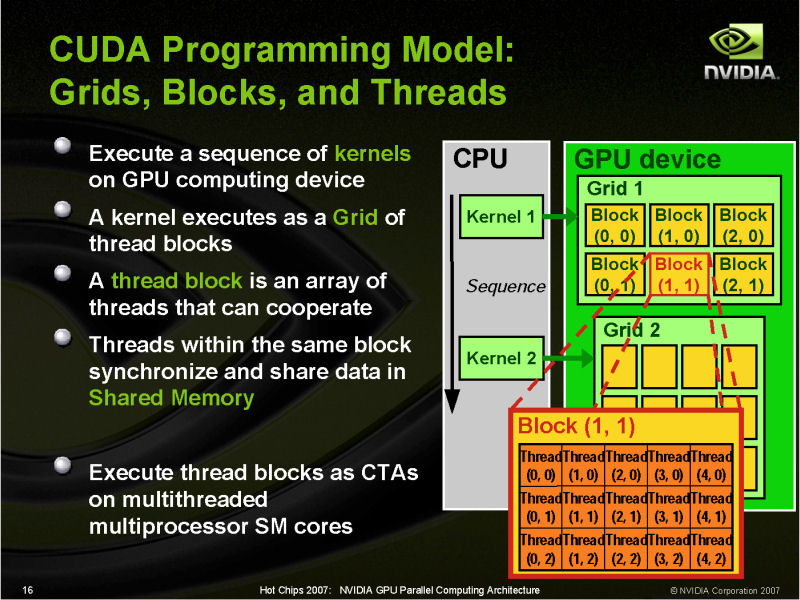
CUDAコードの中で並列実行プログラム部分「カーネル(Kernel)」が、GPU命令セットに変換されGPUにダウンロードされて、GPU上で多数のデータを同時に処理する。もっとも、実際にはグラフィックス処理ではVertex/Geometry/Pixelそれぞれ異なるカーネルプログラム(=シェーダプログラム)を同時に走らせるので「Single Program」ではなく「Single Sentence」だと指摘するGPU関係者もいる(汎用アプリケーションの場合は1個のカーネルのみ実行)。
GPUの場合、ハードウェア側は、SPMDに合わせたSIMD(Single Instruction, Multiple Data)構成となっている。多数のプロセッサが、それぞれのデータに対して、同じカーネルのスレッドプログラムの中の同じ命令を実行する。つまり、マルチコアCPUのように、それぞれのプロセッサが異なる命令を実行するのではなく、全てのプロセッサが原則として同じ命令を同時に実行する。この仕組みは、命令の制御機構やデータ移動機構などを簡略化する上で大きな効果がある。GPUがCPUより多くの演算ユニットを搭載できるのはそのためだ。
実際には、現在のGPUは、プロセッサをある程度の粒度でまとめたクラスタ(NVIDIAではSM)単位で制御している。各クラスタの中のプロセッサをSIMDとして制御して、同じスレッドプログラムの同じ命令を実行させる。各クラスタは、同じプログラムを実行するが、クラスタ同士は独立しているため、特定の1サイクルを取ると、それぞれのクラスタがプログラムの異なる部分を実行している。
 |
| CUDAのプログラミングモデル※クリックすると別ウィンドウで開きます |
●ベクタ長が露出しているかどうかがGPUと現在のCPUとの違い
こうしたGPUの構造のため、プログラマは、GPUの内部の並列化されたハードウェアは意識しないで済む。例えば、1個のピクセルに対するシェーダプログラムを書くと、GPUの中で自動的に何百万個というピクセルに対してプログラムが適用され、並列に実行される。ベクタ長(プロセッサエレメントのSIMD構成の幅)がプログラマから隠蔽されていることがGPUの大きな特徴だ。
これは、現在のCPUのSIMDとは大きく異なる。SSEのような、PC向けCPUのSIMDユニットの場合は、プログラマにベクタ長(例えば、SSEでは単精度で4way)が露出しており、明示的に扱う。GPUのSPMDモデルは、グラフィックスのようにスレッド間の依存性がないプログラムにとっては、楽にプログラムできる点で非常に優れている。問題は、SPMDが汎用的なプログラムに広く適しているかどうか。それが、今後の並列プロセッサのプログラミングの最大の論点の1つとなっている。
NVIDIAでは、GPUのSIMDの特性を、CPUのSIMDと区別するために、GT200からは「SIMT(Single Instruction, Multiple Thread)」と、一般的ではない呼び方を始めている。SIMTとは、SPMD(Single Program, Multiple Data)プログラミングモデルでのSIMDのことだ。NVIDIAがSIMDという単語をことさらに避けているのは、各プロセッサの中はスカラ(1命令/1サイクル)構造で、SSEなどのSIMD演算ユニットは備えていないからだ。
ちなみに、AMD(ATI)のスタッフはSPMDモデルでの自社のプロセッサアーキテクチャを「SIMI(Single Instruction, Multiple Instance)」と呼ぶことがある。SIMTとSIMIは、意味的にはほぼ同じだ。ただし、AMD(ATI)ではGPUの各プロセッサがVLIW(Very Long Instruction Word)型プロセッサとなっている。NVIDIA用語のSIMTを厳密に定義すると、SPMDでのスカラプロセッサのSIMDということになる。
 |
| CPUとGPUの命令実行の違い※クリックすると別ウィンドウで開きます PDF版はこちら |
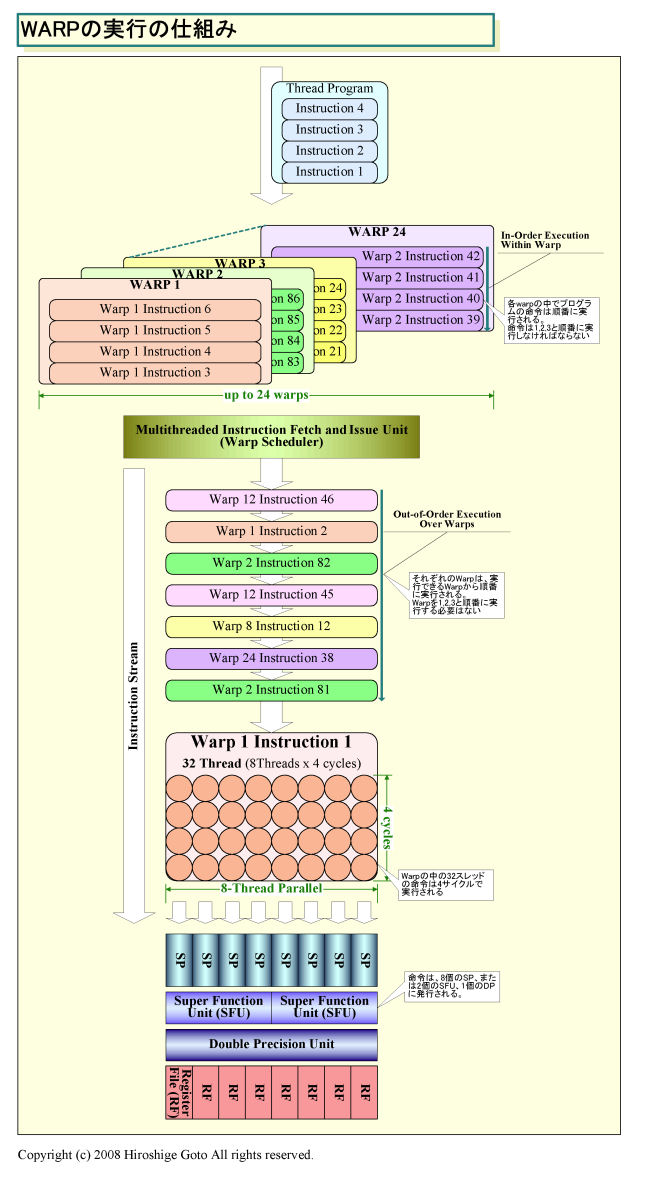
●G80/GT200ではスレッドバッチwarpをOut-of-Order実行
 |
| NVIDIAのJohn Nickolls氏 |
GPUの構造を理解する際にやっかいなのは、GPUベンダーによって各要素の呼称が異なることだ。NVIDIA用語では、ピクセルや頂点といった各データエレメントに対する実行単位をスレッドと呼んでいる。さらに、スレッドを32個束ねた「Warp(ワープ)」と呼ぶスレッドバッチで管理している。32個のスレッド(アーキテクチャ上は16個も可能とされているが有効にされていない)で構成されるWarpが、NVIDIA GPUの中のプロセッサでSIMD実行される仕組みだ。
1個のStreaming Multiprocessor(SM)の中には1個の命令ユニットがある。命令ユニットは、1つのwarp内の32スレッド全てに対して同じ命令を発行する。warp内のスレッドは、プログラムカウンタ(PC)を共有しており、1つのプログラムの中の同じ命令を同時に実行するとも言える。
もっとも、実際にはSM内のStreaming Processor(SP)は8個しかないため、8スレッドしか並列に実行できない。そのため、SMは4サイクルに渡って、1つのwarpの中のスレッドを1サイクル8スレッドづつ実行する。8スレッド×4サイクルで8プロセッサが32スレッドを実行する。
G80/GT200のGPUコンピューティングアーキテクトのJohn Nickolls氏(Director of Architecture)によると、G80以降の命令ユニットはマルチスレッド(マルチwarp)化されており、各warpをOut-of-Orderで実行することができるという。ひとつのwarpに対する命令ストリームはIn-Order実行だが、各warpの順番はOut-of-Order実行できる。最大24 warpをプールして、リソースがアベイラブルになったwarpの命令からOut-of-Orderに実行する。
 |
| Warpの実行の仕組み※クリックすると別ウィンドウで開きます PDF版はこちら |
これまでの通常のGPUは、1つのwarp(=スレッドバッチ)の命令をIn-Order実行し続け、ストールすると初めて他のwarpに切り替えていた。ひとつのwarpの命令を複数サイクルに渡って実行することで命令実行レイテンシを隠蔽し、warpの切り替えによってメモリレイテンシを隠蔽する仕組みだ。例えば、AMDのR600系は、NVIDIAのG80/GT200系と同様に1つのスレッドバッチを4サイクルに渡って実行するが、命令シーケンサを2つ用意する(物理的には同じ命令ユニット)ことで、2スレッドバッチを交互に実行。合計8サイクルで実行レイテンシを隠蔽。スレッドバッチの切り替えで、メモリレイテンシ(200サイクル以上かかる)を隠蔽していた。
それに対して、G80/GT200系のwarp実行のスケジューリングは、よりダイナミックだ。warpスケジューリングで、実行とメモリの両方のレイテンシを隠蔽する。よりフレキシブルなスケジューリング方式だ。G80/GT200系では、プロセッサコアの高クロック動作のために演算ユニットもより深くパイプライン化されているはずで、レイテンシを隠蔽するためにも、より積極的な仕組みが必要だったと推定される。アーキテクトのJohn Nickolls氏によると、実際にはwarpの中のスレッドもOut-of-Order実行できるが、行なっていないという。
 |
| SMによるSIMDマルチスレッド実行の工程※クリックすると別ウィンドウで開きます |
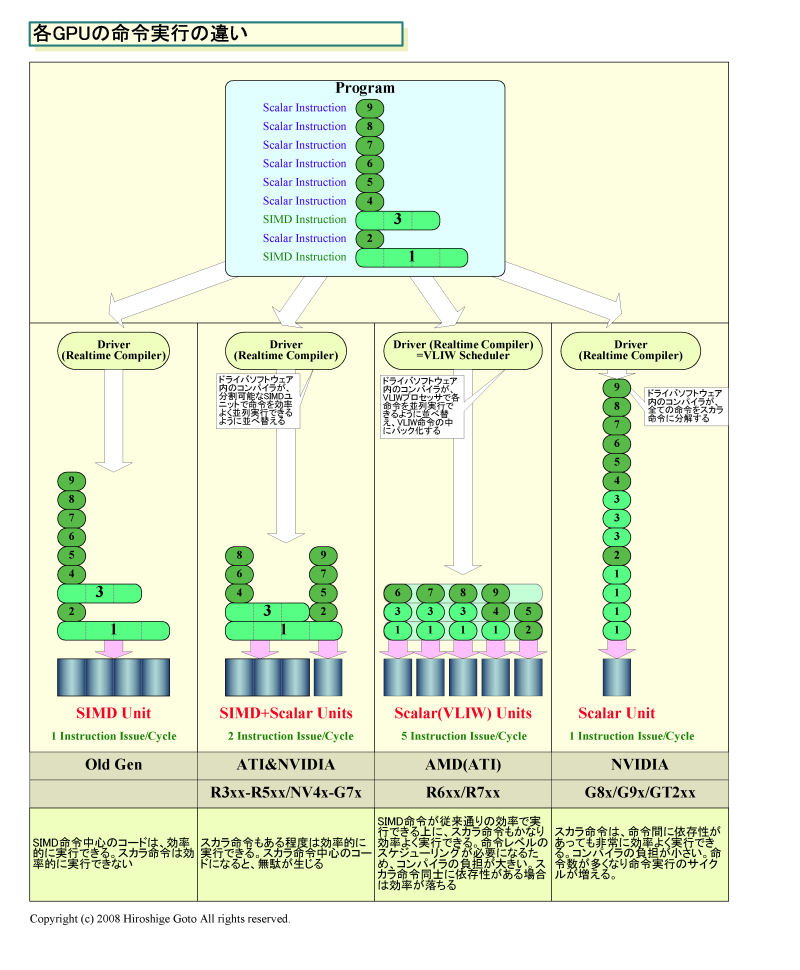
●フルにスカラ実行するNVIDIAアーキテクチャ
G80以降のプロセッサコアには、Out-of-Order型の動的なwarpスケジューリングに加え、特徴的な要素がもうひとつある。
一般的なGPUは、SIMD実行する各スレッドの中でもSIMDで命令を実行している。例えば、ピクセル処理なら、1ピクセルを構成する4コンポーネント「RGBA(Red, Green, Blue, Alpha)」を、1スレッドの中でSIMD処理する。SIMD制御されたプロセッサの中に、さらにSIMD型の演算ユニットを持つスタイルを取っていた。これは、グラフィックス処理では、頂点やピクセルなどが、いずれもSIMD処理に向いたデータ形式だったためだ。
しかし、NVIDIAアーキテクチャでは、SIMDを完全に分解してしまう。演算は全てスカラとなっている。例えば、DirectX API上でカラーデータRGBAのSIMD演算として表現されている場合も、GPU内部では各要素を分離して「R」「G」「B」「A」とデータエレメント毎にスカラプロセッサで順番に演算する。
GPUが、ベクタ型の演算ユニットで3または4コンポーネントのデータを演算するという常識は、もやは古い。今のGPUは、NVIDIAもAMD(ATI)も、単純なベクタ演算ユニットのプロセッサを持たない(テクスチャフィルタはベクタ演算ユニット)。ベクタを完全に崩したNVIDIAアーキテクチャの意図は明瞭だ。演算をスカラへと細粒化することで、どんなデータタイプに対しても高スループットを実現するアプローチだ。
対するAMD(ATI)のR600/RV770系アーキテクチャでは、プロセッサはVLIW(Very Long Instruction Word)型命令を使っている。5-wayのVLIWプロセッサに対して、コンパイル(ドライバソフトウェアで行なう)時に命令レベルの並列化を行なう。それによって、SIMDフォーマット以外の命令も比較的効率よく実行できるようにしている。RV770のプロセッサアーキテクチャの解説記事で説明するが、このアーキテクチャはグラフィックスでは効率がよく、NVIDIAよりピークパフォーマンス/トランジスタを高めることができる。
それに対して、NVIDIAは、完全にスカラにすることで、VLIWと較べるとリアルタイムコンパイル時の命令スケジューリングをずっと軽減し、リソースの競合による並列実行の非効率もなくした。AMD(ATI)アーキテクチャでは、プログラムで命令間に依存性がある場合は同じVLIW命令にパックできない。そのため、プログラムによっては、実行ユニットに無駄なアイドルが生じてしまう場合がある。しかし、NVIDIAアーキテクチャでは、命令間に依存性があってもスカラ実行なので実行ユニットをフルに働かせることができる(命令実行レイテンシはスレッディングで隠蔽する)。
 |
| 各GPUの命令実行の違い※クリックすると別ウィンドウで開きます PDF版はこちら |
 |
| RV770の概要(一部推定)※クリックすると別ウィンドウで開きます PDF版はこちら |
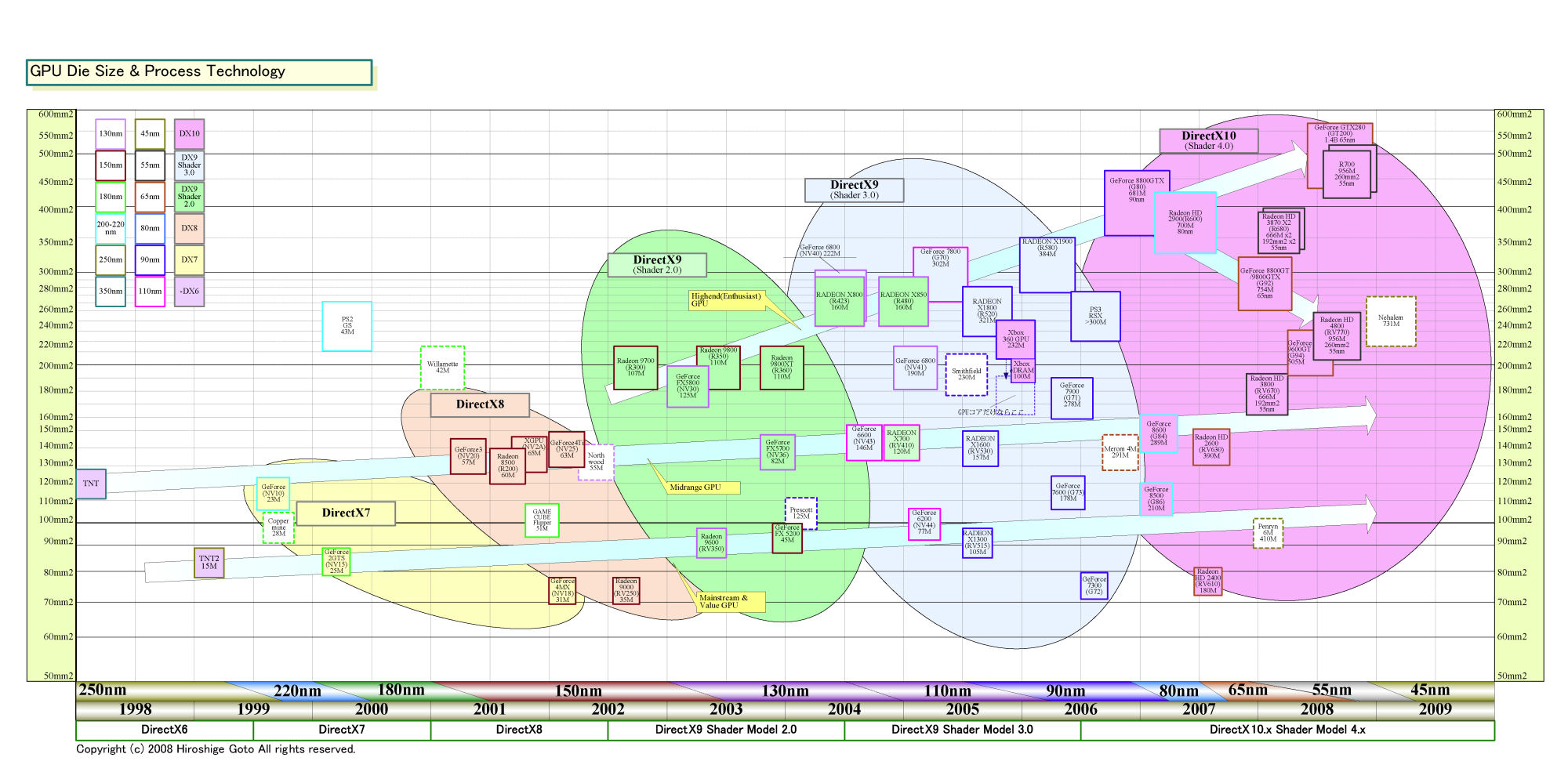
G80/GT200のトレードオフは、同じプログラムの実行サイクルがより長くなり、命令数が増えることだ。NVIDIAは、SIMT(=SPMD実行するSIMD)実行するクラスタStreaming Multiprocessor(SM)の数を増やして並列度を上げることでそれをカバーしている。そのためにクラスタであるSMの数が多くなり、その分、命令ユニットなどリソースが肥大化する。GT200の巨大ダイは、その結果だ。
こうしたプロセッサアーキテクチャの違いは、設計思想と密接に結びついている。非常にラフに言えば、NVIDIAアーキテクチャは非グラフィックスを含めた多様なアプリケーションの実行に最適化しており、AMDアーキテクチャはどちらかと言えばグラフィックスに寄っている。もちろん、アプリケーションによってこの分類は当てはまらない場合もありうるが、NVIDIAが、アーキテクチャ面からも非グラフィックスを強く意識していることは確かだ。これは、CPUを持たないためGPUを汎用コンピューティングに広げなければ活路がないNVIDIAと、CPUを持つためCPUとGPUの連携を重視するAMDの立場の違いを反映している。
 |
| GPUダイサイズとプロセス技術の変遷※クリックすると別ウィンドウで開きます PDF版はこちら |
□関連記事
【6月26日】【海外】Radeon HD 4800の高パフォーマンスの秘密
http://pc.watch.impress.co.jp/docs/2008/0626/kaigai450.htm
【6月20日】【海外】GeForce GTX 280の倍精度浮動小数点演算
http://pc.watch.impress.co.jp/docs/2008/0620/kaigai449.htm
【6月19日】【海外】GT200コアでHPCの世界を狙う「Tesla」
http://pc.watch.impress.co.jp/docs/2008/0619/kaigai448.htm
【6月17日】【海外】AMDが1TFLOPS GPU「Radeon HD 4800」ファミリをプレビュー
http://pc.watch.impress.co.jp/docs/2008/0617/kaigai447.htm
【6月17日】【海外】NVIDIAの1TFLOPS GPU「GeForce GTX 280」がついに登場
http://pc.watch.impress.co.jp/docs/2008/0617/kaigai446.htm
(2008年7月2日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.