 |


■後藤弘茂のWeekly海外ニュース■これが超低消費電力「Silverthorne」の正体だ |
●64-bitやVTもサポートするSilverthorne
Intelの、低消費電力x86 CPU「LPIA(Low Power Intel Architecture)」である「Silverthorne(シルバーソーン)」の正体が見えてきた。現在、米サンフランシスコで開催されている半導体カンファレンス「ISSCC(IEEE International Solid-State Circuits Conference) 2008」では、IntelがSilverthorneの概要について、初めての発表を行なった。
Silverthorneは、TDP(Thermal Design Power:熱設計消費電力)を2W以下に抑えることをターゲットとした、超低消費電力CPUとして設計された。電力は抑えながらも、PC向けCPUと同等の機能(命令)を備えた。Core 2 DuoのSSE3までの命令セットに互換で、64-bit拡張「Intel 64」やIntel Virtualization Technology(VT)もサポートする。また、パフォーマンスも1世代前のPC向けモバイルCPUのローエンドに匹敵する。
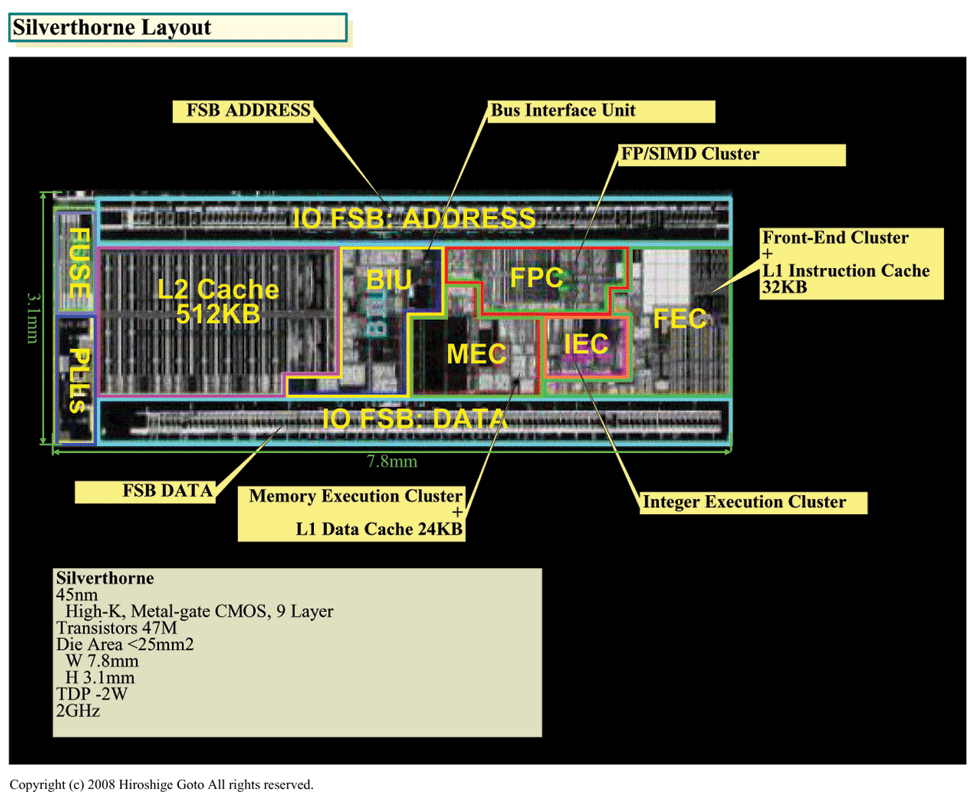 |
| Silverthorneレイアウト (※別ウィンドウで開きます) PDF版はこちら |
こうした性能と機能の目的のために、IntelはSilverthorneでは、2命令イシュー(発行)のインオーダ(In-Order)実行のパイプラインを選び、2スレッドのマルチスレッディング機能を実装した。
「アウトオブオーダ(out-of-order)実行をはじめ、さまざまな設計を分析した。その結果、インオーダ実行でマルチイシューマシン、マルチスレッドが、ベストのパワー/パフォーマンスを達成できることを発見した」とISSCCで発表を行なったIntelのGianfranco Gerosa氏は説明した。
Intelは、PCクラスの機能を持つモバイル機器やローコストPCをLPIA系CPUでカバーしようとしている。そのため、Silverthorneには、携帯機器向けのCPUとしては、いくつかユニークな実装が見える。Silverthorneのポイントは、トランジスタ数を削り小さなチップにしながらも、CPU自体を高クロックに回し、マルチスレッド性能も上げることでパフォーマンスを稼ぐことにある。
●2GHzクラスの高クロックをターゲット
SilverthorneのCPU自体のサイズは非常に小さい。7.8×3.1mm(横×縦)で、計算上のダイサイズ(半導体本体の面積)は約24平方mm台(発表では25平方mm以下となっている)。これはメインストリームPC向けCPUの約1/4のサイズだ。「CPUコア同士で比較しても、PC向けCPUの約1/4のサイズ」とGerosa氏は言う。トランジスタ数は47M(4,700万)で、45nm版Core 2 Duo(Penryn 6M:ペンリン)の410M(4億1,000万)の1/9程度だ。
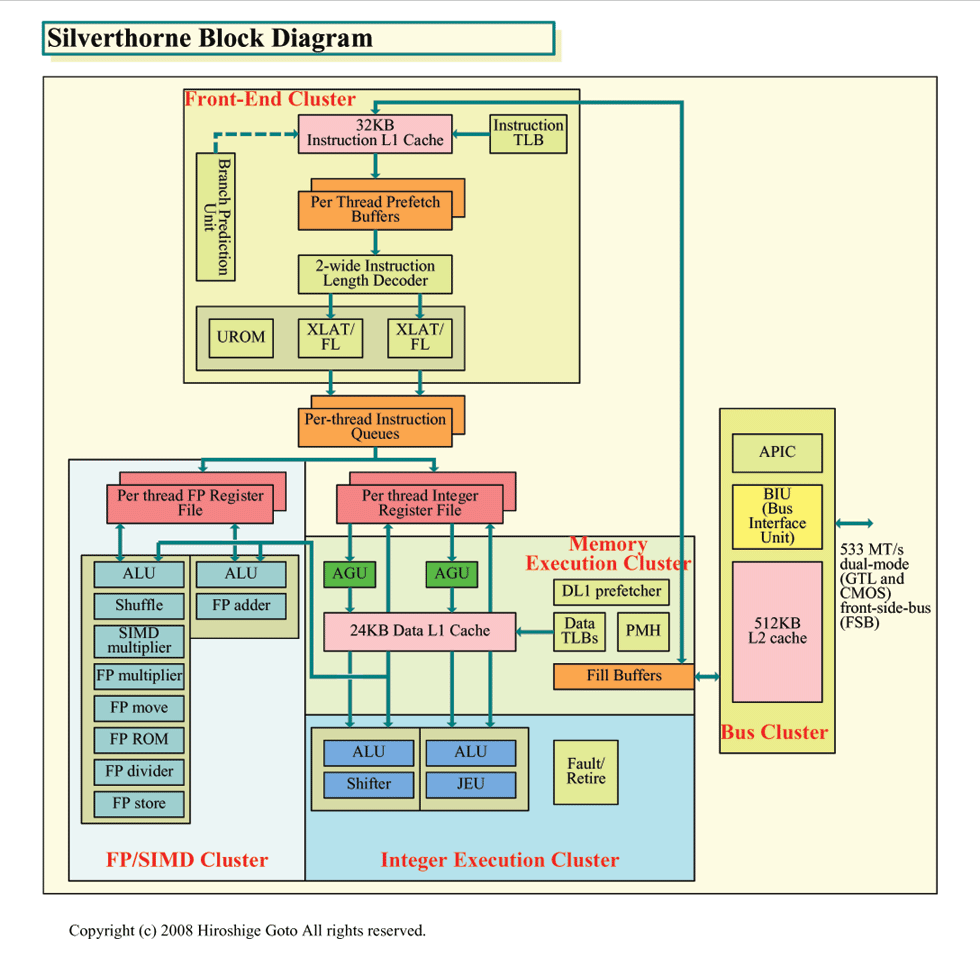 |
| Silverthorneブロックダイヤグラム (※別ウィンドウで開きます) PDF版はこちら |
省ダイサイズを実現するために、Silverthorneでは、インオーダ型の命令実行を取った。これは、PC向けCPUのほとんどがアウトオブオーダ型実行を採用しているのとは対照的だ。しかし、アウトオブオーダ型実行は、命令を並列に実行できるように並べ替えるため、命令スケジューリングに膨大なリソースが必要となる。そのため、PC向けCPUの肥大化と電力効率の悪化の主因となった。Silverthorneでは、アウトオブオーダを削ることで、かなりのトランジスタとダイ面積の節約を実現した。
また、それだけでなく、Silverthorneでは実行ユニット群もかなり節約している。例えば、SIMD整数乗算ユニットは、スカラの整数乗算の命令も実行する。兼用することで、ユニット数をミニマムに抑えている。徹底したケチケチ設計が、Silverthorneの特徴だ。
CPUを単純化することで、電力消費の源であるトランジスタ数を減らすことは、低消費電力CPUの基本的なアプローチだ。しかし、Silverthorneには低消費電力CPUとしてはユニークな点がある。通常、低消費電力CPUは、パイプライン段数は浅くして、動作周波数は低く抑える。パイプライン段数を深くすると、動作周波数を上げることができるが、ラッチ回路などが増えることで、電力消費が増えてしまうからだ。
ところが、Silverthorneは、パイプラインは16ステージとある程度の深さを持っており、低電力でも2GHz前後の周波数をターゲットにしている。下は、ISSCCで発表されたSilverthorneの周波数/電圧チャートを補足したものだ。もともとのチャートには、周波数の項目の数字が入っていなかった。右端の最高周波数が2.5GHz、真ん中のポイントが2GHzで1V、左端の最低周波数が1.25GHzと示されていた。そのため、2GHzから下が0.05GHz刻みになっていると判断して補足した。これを見てもわかる通り、Silverthorneは1V程度の電圧で、ラボでは2GHzをマークしており、0.8V以下でも1GHzを充分に超えている。
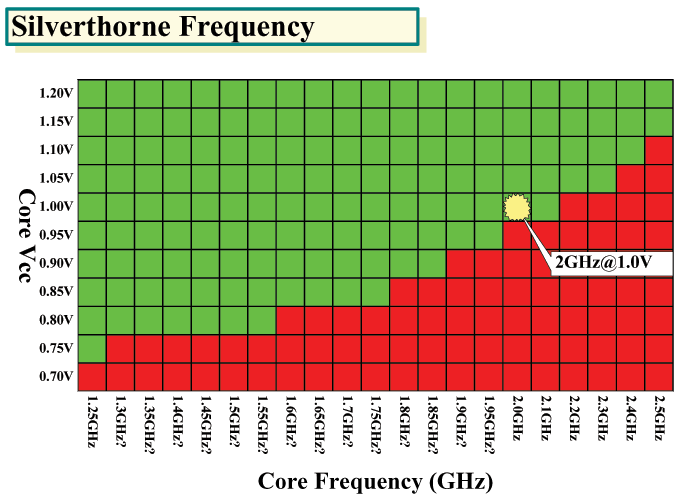 |
| Silverthorne動作周波数 (※別ウィンドウで開きます) PDF版はこちら |
●シングルサイクル実行で決まったパイプライン
ターゲットクロックを見ると、トランジスタ数の少ないCPUを、そこそこの高クロックで動かすことでパフォーマンスを稼ぐことがSilverthorneのコンセプトのように見える。その結果、トランジスタ数の多いPC向けCPUを、無理に低電圧で駆動して低周波数で動作させるより、優れたパフォーマンス/消費電力を得られると判断したと見られる。
Silverthorneの16ステージパイプラインは、NetBurstマイクロアーキテクチャの20~31ステージという深いパイプラインと比べると少ない。しかし、Core Microarchitecture(Core MA)の14ステージより深い。インオーダ実行のSilverthorneが、アウトオブオーダ実行のCore MAよりパイプラインの複雑度が少ないことを考えると、Silverthorneのパイプラインは深い。実際には、Silverthorneのパイプラインには、インオーダ実行での性能を上げるために、アドレス生成とL1データキャッシュアクセスの3ステージ分が付加されている。それを外せば13ステージだが、それでも、Core MAとほぼ同レベルとなる。
Gerosa氏によると、パイプライン段数はシングルサイクル実行のコンセプトで決まったという。
「この16ステージパイプラインは、我々がシングルサイクル実行を維持することを望んだことで決まった。『EX1』が実行ステージで、1サイクルに収まっている。シングルサイクル実行としたことで、1サイクル(ステージ)当たりのゲート数が決まる。それを受けて、我々はパイプラインを構築し、パフォーマンスを拡張するための仕様を加えた」
整数演算を1サイクルで実行する場合、整数演算パスのロジックの量で1ステージの最大のゲート数(=ディレイ)が決定する。後は、パイプラインの他の部分を、そのゲート数(=ディレイ)に収まるように切ったと推定される。今のCPUでは、じつは命令実行自体にはたいして時間がかからない。ゲート数を食っているのは、命令のデコードやスケジュール、レジスタアクセスといった、実行以外の部分だ。実行ステージに合わせて、他のステージのゲート数を規定すれば、シングルサイクル実行の範囲で、最大限の動作周波数を達成できることになる。
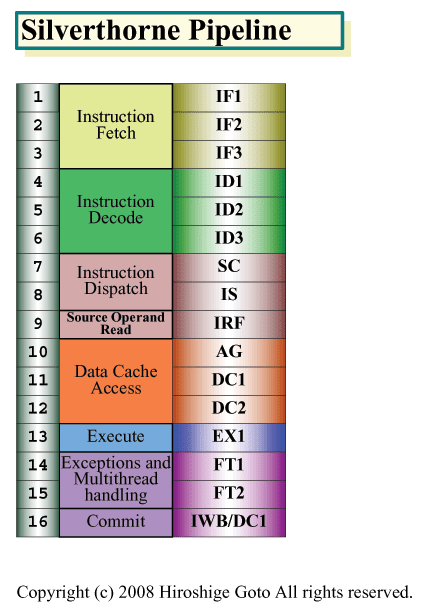 |
| Silverthorneパイプライン PDF版はこちら |
●命令フェッチとデコードのステージが深いSilverthorne
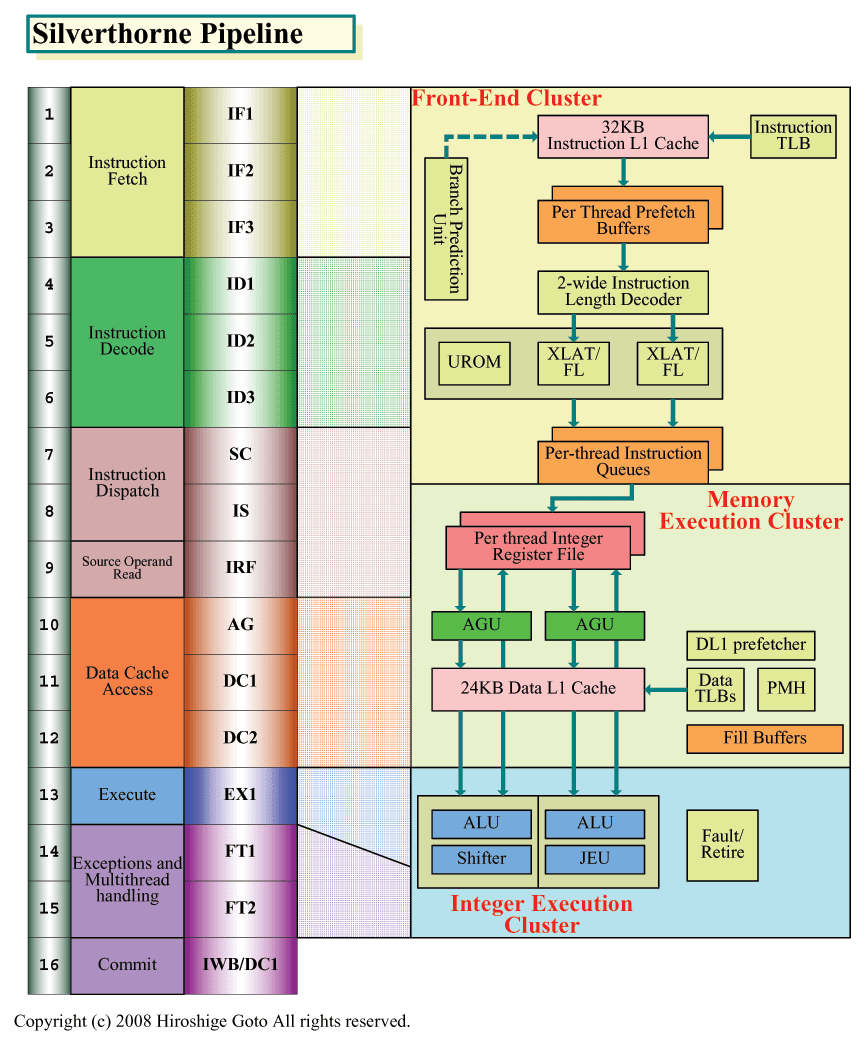
Silverthorneの16ステージのうち、最初の6ステージは、Intelが「Front-End Cluster」と呼ぶ、命令フェッチ&デコード部分で実行される。最初の3ステージとなるIF(Instruction Fetch)1~3が、命令をL1命令キャッシュから取り込む命令フェッチ部分。ここに、L1命令キャッシュアクセスのディレイも含まれると推定される。
次の3ステージは命令デコードで、ID(Instruction Decode)1~3で構成される。Silverthorneでは、PC&サーバー向けCPUのように、x86命令を完全に分解するわけではない。しかし、可変長のx86命令をキャッシュラインから切り出し、実行しやすいフォーマットにするために、3サイクルをかけている。命令デコードはx86系命令で最も難しい部分の1つで、そのためにステージ数が必要となると推定される。
パイプラインからは見えないが、実際には命令フェッチと命令デコードの間には、プリフェッチメカニズムで取り込んだ命令のバッファがある。Silverthorneは2スレッドのハードウェアマルチスレッディングであるため、命令プリフェッチバッファはスレッド毎に2系統のバッファとして構成されている。
命令デコードステージのデコーダは2命令幅で、IA-32命令を同時に2命令づつデコードできる。デコードされた命令はインストラクションキューに格納される。これもスレッド毎に用意されている。
次の命令ディスパッチは2ステージ構成だ。Silverthorneは、命令ディスパッチャから、同時に実行できる2命令を実行パイプラインに発行する、2イシューマシンとなっている。この部分では、実際にはスレッドスケジューリングを行なっている。発行する2命令を、1つのスレッドから選ぶことも、2つのスレッドから1命令づつ選ぶこともできるからだ。2つのスレッドの命令を1サイクルに混在させて実行できるSMT(Simultaneous Multithreading)になっている。サイクル単位でスレッドを切り替えるといった方式ではない。そのため、Silverthorneでは、実行パイプラインの空きを、2スレッドからの命令で埋めることができる。
命令発行の次はソースオペランドの読み込み。これは物理レジスタファイルが小さいので1ステージで終わる。次に、メモリアクセスのアドレス生成AG(Address Generation)ステージで、アクセスするメモリのアドレスをこのステージで生成する。AGが1ステージで、次の2サイクルがL1データキャッシュのDC(Data Cache)1~2となる。
データキャッシュアクセスを経て、オペランドが揃ったところで、実行ステージであるEX1となる。ここがシングルサイクル実行で、続く2ステージで、例外とマルチスレッディングのハンドリングを行なう。最後の16ステージ目で、コミットしてライトバックしパイプラインが終わる。次は、Silverthorneの省電力機能の詳細をレポートしたい。
 |
| Silverthorneパイプラインとブロック図 (※別ウィンドウで開きます) PDF版はこちら |
□ISSCCのホームページ(英文)
http://www.isscc.org/isscc/
□関連記事
【2月4日】【海外】IntelがいよいよSilverthorneとTukwilaの概要を発表へ
http://pc.watch.impress.co.jp/docs/2008/0204/kaigai415.htm
【2月4日】【ISSCC】低消費プロセッサと低コスト不揮発性メモリ
http://pc.watch.impress.co.jp/docs/2008/0204/isscc01.htm
【2007年5月10日】【海外】デスクトップCPUと同じ仕様を載せた「Silverthorne」
http://pc.watch.impress.co.jp/docs/2007/0510/kaigai357.htm
(2008年2月7日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.