 |


■後藤弘茂のWeekly海外ニュース■2010年のIntelアーキテクチャが見えてきた |
●一般名詞化しつつあるメニイコア
CPUコア自体のパフォーマンスアップは行き詰まりつつある。半導体のスケーリングの鈍化、命令レベルでの並列性「ILP(Instruction-Level Parallelism)」の向上の限界、CPU設計の複雑化といったことが原因となっている。これは、ほぼCPU業界の共通認識となっており、そのために、急激なマルチコアへのカーブが切られた。
 |
| CPUコア数の推移 |
そして、CPUは、マルチコアを超えた“メニイコア(Many-core)”へと向かっている。つまり、数10コアから、将来的には100コアをワンチップに載せようというビジョンが、研究開発ではテーマになりつつある。Intelは2004年あたりからメニイコアと言い始めていたが、もはやIntelだけの用語ではなく、一般名詞化しつつある。
IntelのJustin R. Rattner(ジャスティン・R・ラトナー)氏(Intel Senior Fellow, Director, Corporate Technology Group)は、8月に米スタンフォードで開催されたハイパフォーマンスチップのカンファレンス「HotChips 18」で、メニイコア時代に対するIntelの取り組みを説明した。
 |
| IntelのCPU構想 |
上はIntelの描くメニイコア時代のCPU構想「Tera-Scale Computing (Many-core)」のコンセプト図だ。Intelは、昨年(2005年)以来、この構想の研究開発について何度か説明してきたが、まだ“ワラ人形(Strawman)”状態で、明確な形にはなっていない。この図も、あくまでもコンセプトを示すだけのものだ。
しかし、コンセプト図からは、Intelがどのような方向性を持っているのかは、ある程度までは見えてくる。まず、Intelの構想するベーシックなメニイコアハードウェアは次のような姿となる。
●IntelアーキテクチャCPUコアのアレイ
IntelのTera-Scaleコンピューティングでは、CPUコアのアレイは、多数のIA(Intel Architecture) CPUコアを並べた構造が示されている。Rattner氏は、メニイコア時代のIAコアは、現在のIAコアのリッチなフィーチャをそのまま備えるといった説明を以前から行なっている。この構想は、現在も変わっていない。
 |
| IntelのJustin R. Rattner(ジャスティン・R・ラトナー)氏 |
しかし、CPUコアのマイクロアーキテクチャ(内部アーキテクチャ)をヘテロジニアス(Heterogeneous:異種混合)にするかどうかについては、ニュアンスが変わりつつある。1年前は、Rattner氏は、メニイコア世代では、命令セット(ISA)は均一に保ちながら、マイクロアーキテクチャ的には異なるコアを集積することを示唆していた。
「我々はホモジニアス(均質)な命令セットアーキテクチャ(ISA)にフォーカスしている。命令セット混在アーキテクチャは、すでに並列プログラム化のために複雑な状況になっているプログラム側に、さらに余計な複雑性を加えてしまうと考えている。ただし、ホモジニアス(ISA)フレームワークの中で、特殊化と最適化をして行く。おそらく、単一命令セットアーキテクチャの、ミクスド(異種混載)プロセッサコアになるだろう」
この時点では、Intelは、大型でシングルスレッド性能の高い汎用コアと、小型で効率の高いコアを混在させることを考えていたようだ。しかし、現在ではこうした説明はトーンダウンしており、あいまいになっている。IA CPUコアについては、均質のマイクロアーキテクチャになる可能性もある。
ただし、メニイコア時代のCPUコアは、同じ汎用コアであっても、シングルコア時代のCPUコアとは異なる。マルチコアに最適化したアーキテクチャを備えることで、多数のCPUコアでスケーラブルにパフォーマンスを伸ばすことができるようにして行くという。
「これら(メニイコアのコア)は今日のマルチコアアーキテクチャで見るのとは同じコアではない。数世代先のコアとなり、マルチスレッドオペレーションに真に最適化されたコアとなるだろう」とRattner氏は説明する。
●マルチコアに最適化したCPUアーキテクチャの拡張へ
Rattner氏は下の図で、CPUアーキテクチャの改良によって、スケーラブルにパフォーマンスが伸びることがシミュレートできたと説明した。
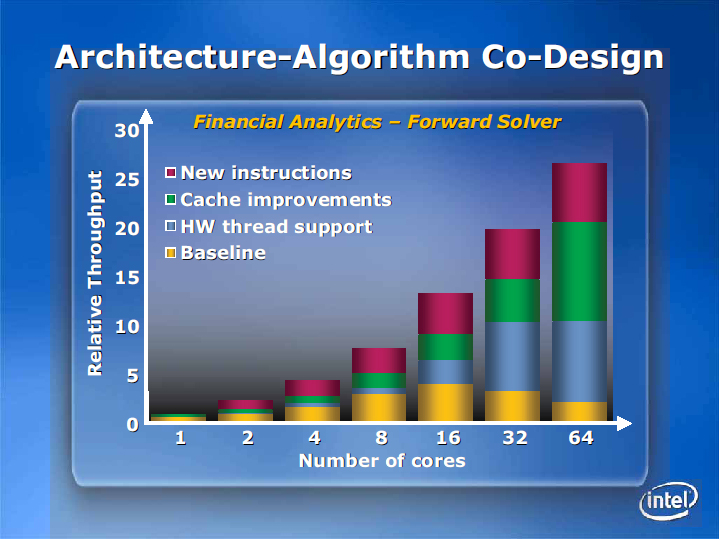 |
| コア数に伴なう性能向上の要因 |
図の最も下のイエローの柱が、マルチコアに最適化されていないCPUコアの場合。この場合は、シミュレーションした財務アナライズソフトでは、16コアをピークに、それ以上CPUコア数を増やしてもパフォーマンスは上がらない。それどころか、同期オーバーヘッドなどでパフォーマンスは逆に落ちてしまう。
ところが、ハードウェア側が明示的なスレッドのサポートを行ない、スレッドスケジューリングすると、ブルーの柱のように、32コアまではスケーラブルに性能が上がるようになるという。さらに、キャッシュのビヘイビアをアプリケーションに最適化できるように改良すると、64コアまでのスケーラビリティが得られる。そして、新たな命令セットを加えることで、スループットはさらに上がるとRattner氏は語った。
Intelは、マルチコア化へのCPUアーキテクチャの最適化の詳細は明らかにしなかったが、この図の示す方向性は明確だ。これまで、CPUアーキテクチャの拡張は、CPUコア単体のパフォーマンス向上に向けられてきた。しかし、今後は、CPUコア単体ではなく、マルチコアのパフォーマンスを向上させることができるアーキテクチャ開発が焦点になる。コアの塊であるCPU全体でパフォーマンスを上げるようなアーキテクチャを考案していくことになるだろう。
Intelが前回のIntel Developer Forum(IDF)で紹介したトランザクショナルメモリ(Transactional Memory)はその好例だ。Transactional Memoryでは、多数のCPUコアが共有メモリにアクセスする際に、効率的にアクセスできるようにする。複数のCPUコア上の異なるスレッドが同じメモリアドレスにアクセスすると、メモリの一貫性が保てなくなる可能性がある。そのため、従来は、処理が終わるまでロックして、他のスレッドからのアクセスを禁止していた。
しかし、このテクニックではスケーラブルに性能を伸ばすことができない。そこで、Transactional Memoryでは、必要なデータをいったんプールし、トランザクション単位で処理をまとめてメモリに渡す(Commit)ことで、並列に処理することを可能にする。トランザクション間のコンフリクトを検知して、衝突した場合にはトランザクションをリスタートさせる。
つまり、各スレッドは、従来のようにメモリアクセス待ちでアイドルしてしまうことなく、衝突するまで並列に動作できる。3月のIDFでは、8スレッドの処理ではTransactional Memoryが、ロック方式に対して圧倒的に有利になることがデモされた。衝突時のリスタートのオーバーヘッドはあるが、オーバーオールではスケーラブルに性能を伸ばすことができるというわけだ。
Intelは、IDF時にはソフトウェア実装によるTransactional Memoryのデモを行なったが、最終的なゴールはもちろんハードウェア実装にある。ソフトウェアTransactional Memoryでは40~100%のオーバーヘッドが生じてしまうからだ。Transactional MemoryはSun Microsystemsも研究しており、HotChipsではIntelとSunによってTransactional Memoryのチュートリアルが行なわれた。Transactional Memoryはメニイコア時代のトレンド技術となりそうだ。
●AMDのコプロセッサに似た固定機能ユニット
Intelは、メニイコア時代には、汎用CPUコアのアーキテクチャを、メニイコアに向けて最適化するだけでなく、さまざまな新アーキテクチャを加えて行く。Rattner氏は、現在見えているメニイコア時代のCPU設計の大きな課題として、次の4点を挙げた。
・Complex memory hierarchy
・Sophisticated on-die fabrics
・Explicit thread support
・Fixed function acceleration
 |
| CPU設計の4つの課題 |
ここで目を引くのは「固定機能ユニット群(Fixed Function Units)」と呼ぶ、汎用CPUコアとは異なるユニットの混載だ。固定機能ユニットは、特定の処理に特化したハードウェアロジックで、ここにコンピューティングタスクを振り分ける。「グラフィックス、メディア、セキュリティ、それから多分、ネットワークプロトコルプロセッシングの要素なども入ってくるだろう」とRattner氏は説明する。
固定機能ユニットは、AMDのコプロセッサ構想「Torrenza(トレンザ)」にかなり近いイメージだ。AMDも、メディアプロセッシング、グラフィックス、ネットワーク系、セキュリティなどのコプロセッサをTorrenza構想の中で挙げている。また、固定機能を載せる理由も、IntelとAMDともに共通している。それはパフォーマンス/消費電力効率の向上だ。
「我々は、特定の機能については、パフォーマンス/電力の面から考えると、ハードウェアで直接実行する実装が最も適していると気がついた」とRattner氏は6月のTera-Scale Computingのテレカンファレンスでは説明している。
一般に、プログラム性の高い汎用コアは、特定のワークロードに特化した固定機能ユニットよりも処理効率が悪い。だから、汎用CPUコアで効率の悪い処理は、専用ユニットで処理することで、CPU全体のパフォーマンス/消費電力を上げていこうという発想だ。
ただし、Rattner氏は6月の時点では、AMDは1~3年程度の、より近い期間について構想しており、それに対してIntelは5年以上先のより長期的なビジョンを描いていると説明していた。
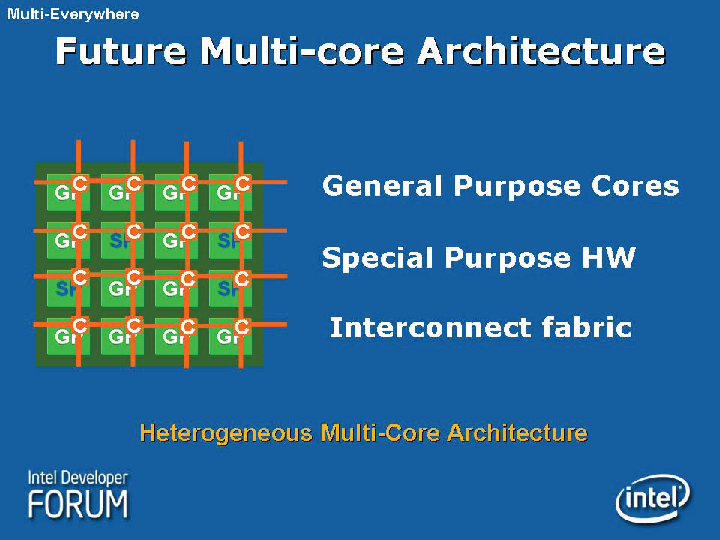 |
| 将来のマルチコアアーキテクチャ |
●パーティショニングと密接に絡むOn-Die Fabric
Intelのメニイコアに、周辺インターコネクトとソフトウェアコンテナ(Container)を加えたのが下のチャートとなる。
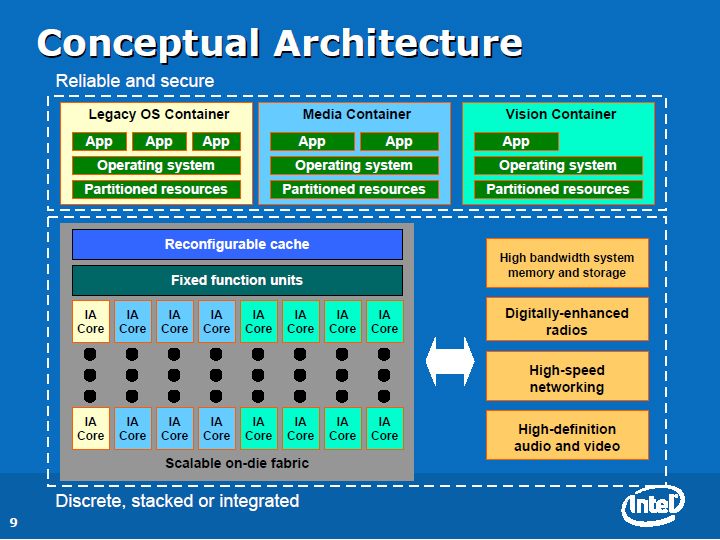 |
| コンテナ化したアーキテクチャ |
Intelはメニイコアを基本的にパーティショニングして使うことを考えており、ソフトウェア層もそれに対応してコンテナ化されることを構想している。言い換えれば、複数の仮想マシン(ソフトウェアパーティション)が、多数のコア群の上で走ることを前提としているわけだ。
現在の仮想マシンは、その下層のハードウェアと連携していない。しかし、メニイコア時代には、1個の仮想マシンを、1個あるいは複数個のCPUコア群で構成される、ハードウェアパーティションに明示的に割り当てられるようになるという。上のコンテナのソフトウェアが、同色のIAコア群の上で走るイメージだ。そして、コンテナ単位で、タスクを特殊化することをIntelは考えているようだ。
「この図では、いくつかのコアが、レガシーのOSとレガシーのアプリケーションを走らせるために割り当てられている。別なコンテナは、メディアプロセッシングに特化されるかもしれない。また、別なコンテナは、データのサーチとインデックスに特化されるかもしれない。図中のコンテナは3つだけだが、もっと多くのパーティションを作ることもできる」(Rattner氏)
パーティショニングは、メニイコアCPUの基本的なアーキテクチャに大きく関わっている。メニイコアのコンセプトでは、各IA CPUコアや固定機能ユニット、メモリインターフェイスなどは、コア間の高速インターコネクトである「On-Die Fabric (オンダイファブリック:ODF)」で結ばれる。このOn-Die Fabricが、パーティション化されたソフトウェアコンテナと連携すると見られる。
●キャッシュはリコンフィギュラブルに
Rattner氏は、以前、On-Die Fabricについて、コア同士を結ぶフレキシブルなオンダイネットワークになるといった説明をしていた。接続や切断を自由に行ない、コアをフレキシブルにネットワーク化できるといった意味だ。
例えば、コヒーレンシを取る必要があるコア群のブロックは、コヒーレントバスで結び、それ以外のコア群とアイソレート(隔離)するといった構成が自由にできるようになるという。これは、仮想マシンをCPUコア群に割り当て、メモリコヒーレンシの維持はその中に限定するといったコンフィギュレーションを想定しているためだ。
「今の仮想環境では、コヒーレンシの制限はできない。なぜなら、下層のハードウェアは、仮想マシンについて何も知らないからだ。しかし、将来は、仮想パーティションと物理パーティショニングの間で、ある種の連携が必要になると考えている。CPUコアをネットワーク化し、仮想パーティションに対応して、特定のCPUコア群を物理的にバウンドする。仮想パーティションの外側とはコヒーレンシを保つ必要がない。コヒーレンシの保持は、CPUコアネットワークの中で、バウンドされたコア群の中だけに止めることができる」とRattner氏は2004年のインタビューで語っていた。
Intelのメニイコア構想では、階層型のキャッシュメモリを想定している。6月の電話会議では、このキャッシュメモリはリコンフィギュラブルになると説明された。「キャッシュは、特定のキャッシュビヘイビアに使えるようにプログラムが可能となる。プログラムの特定のデータアクセスの手法に適合させることができるとも言える。例えば、伝統的なキャッシュを、非常に効率的なストリームバッファに変えることも可能となるだろう」
アプリケーションのタイプによって、有効なキャッシュの構成や管理方式も異なってくる。例えば、ストリーム型のデータ処理の場合には、伝統的な汎用CPUのキャッシュ階層は邪魔になる。単純なデータの先読みバッファが最も効果的となる。Rattner氏の発言は、キャッシュの管理テクニック自体をプログラマブルにして、ストリームタイプのアプリケーションなどにも最適化できるようにすることを示唆している。
●大がかりなIntelのTera-Scale構想
Intelのメニイコア、つまり、Tera-Scale Computing構想は、まだ大まかな輪郭の段階だが、方向性だけは見えてきている。汎用コアはマルチコアに最適化したアーキテクチャ拡張を行い、特定用途向けの固定機能ユニットを備え、各ユニットを自由にネットワーク化するOn-Die Fabricを載せ、リコンフィギュラブルに編成できるキャッシュを搭載する。かなり、大がかりなことをIntelは構想しているようだ。
これだけの機能を載せると、Intelのメニイコアはかなり大きくなってしまいそうだが、そうではないという。
「ダイサイズ(半導体本体の面積)は、(現在のCPUと)同じくらいになるだろう。我々は、とても大きなダイについて語っているのではなく、非常に慣れ親しんだサイズを考えている」とRattner氏は語る。
もちろん、これはIntelのメニイコアが、5年以上先を考えているからで、プロセス技術の微細化の恩恵で、より多くのダイを載せられるようになる。つまり、Intelのメニイコアは、それだけ遠地点を見ている。対するAMDは、もっと近い時期にGPUコアの統合へと踏みだそうとしている。この違いがどう出るのか、まだ見えてこない。もちろん、Intelがメニイコアの前に、ラディカルなアーキテクチャをリリースする可能性もある。
□関連記事
【3月8日】【IDF】メインテーマは“新アーキテクチャ”
http://pc.watch.impress.co.jp/docs/2006/0308/idf02.htm
【2005年11月10日】【海外】見えてきたIntelの5~10年後のCPUアーキテクチャ
http://pc.watch.impress.co.jp/docs/2005/1110/kaigai222.htm
【2005年9月20日】【海外】ハードウェア仮想化とマルチコアCPUの関係
http://pc.watch.impress.co.jp/docs/2005/0920/kaigai213.htm
(2006年9月12日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.