 |


■後藤弘茂のWeekly海外ニュース■AMDがATIのGPUを選んだ理由 |
●汎用プロセッサよりもコプロセッサを選んだAMDの選択
 |
| Innovation:Aim to Transform Processing Technology in 2008 and Beyond |
ATI Technologiesを買収し、GPUコアをCPUの中に取り込もうとするAMD。AMDは、2008年以降に、AMD CPUコアとATI GPUコアをダイ(半導体本体)レベルでワンチップに統合したCPUを投入すると見られる。なぜ、AMDはCPUに統合するコアにGPUを選んだのだろう。
先週の記事でも指摘したように、AMDには半導体面から、GPUコアを統合する必然性がある。AMDコアは微細化とともに小型化して行き、45nm世代ではデュアルコアCPUは極めて小さなダイサイズ(半導体本体の面積)に収まるようになってしまうからだ。そのため、今までの汎用プロセッサコアが2個程度だと、AMD CPUのダイ(半導体本体)はがら空きになってしまう。
ここで、AMDはPC向けCPUで難しい選択に立たされた。(1)汎用プロセッサコアをもっと増やすか、(2)汎用プロセッサコアを強化して性能を上げるか、(3)それとも別な何かを載せるかという選択だ。何度かこのコーナーで説明したように、AMDの決断は(3)の別な何か--コプロセッサを搭載するというものだった。
AMDがコプロセッサの搭載へと舵を切ったのには次のような理由が考えられる。(a)サーバーと異なりPCソフトウェア環境では、プロセッサコアを大幅に増やしても大多数ユーザーにベネフィットをもたらすことができない。(b)汎用プロセッサコアを拡張しても効率的な性能向上は得られない。(c)その一方で、コンピューティングの効率化のために、アプリケーションに専用化したコプロセッサのニーズは高まっている。
CPUを効率的に進化させる道を考えた場合、汎用プロセッサコアと、ある程度専用化したコプロセッサの組み合わせが都合がよかったというわけだ。
そして、PC向けCPUでは、統合するコプロセッサの一番の候補は、明らかに32bit単精度浮動小数点ベクタ演算のコアだった。PCで増えつつあるコンピューティングパフォーマンスを必要とするタスクの多くは、単精度浮動小数点ベクタプロセッサで処理が可能だからだ。フィジックス(物理)シミュレーションがいい例で、ゲーム向けの“軽い”フィジックスでは32bitのSIMD型演算が適している。
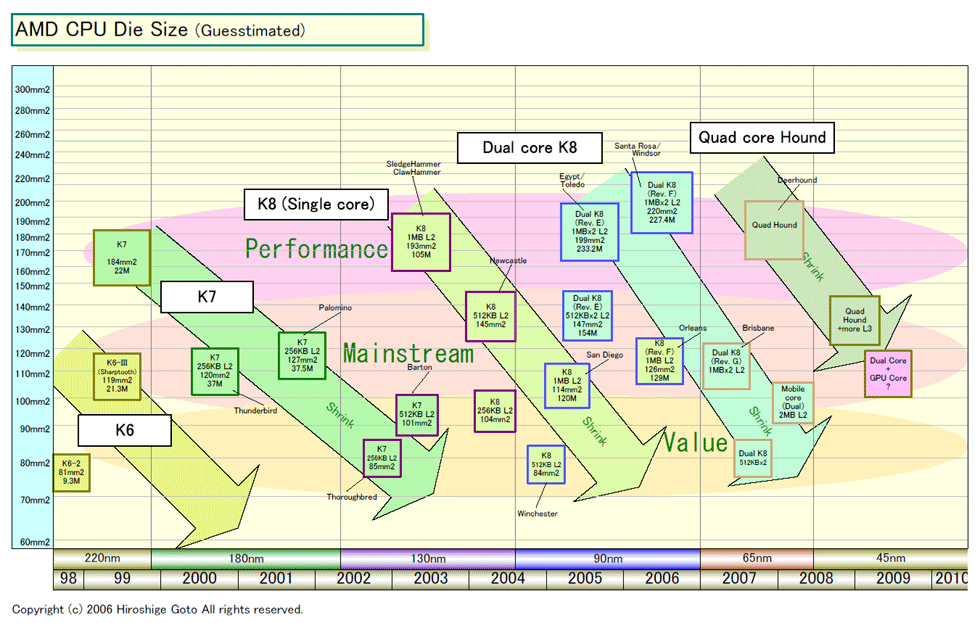 |
| AMD CPU Die Size(Guesstimated) (※別ウィンドウで開きます) PDF版はこちら |
●CPUに統合するのにぴったりの特徴を持つGPU
では、なぜAMDは、CPUに統合するコプロセッサにGPUを選んだのか。
それも明確だ。GPUの演算コアであるProgramable Shaderが進化して、多用途にも利用できるベクタプロセッシングエンジンになりつつあるからだ。
設計的には、GPU Shaderはグラフィックスで最高性能を発揮できるように設計されている。しかし、Shaderのプログラム性を急速に高めつつあり、そのために汎用コンピューティングをGPU上で実現する“GPGPU(General-Purpose GPU)”に応用が広がりつつある。そして、GPUのベクタエンジンは、汎用プロセッサに取り込んだベクタエンジンより、設計上、効率化がしやすい。また、並列性の高いアプリケーションの性格上、複数コアでの分散型の処理もしやすい。
この状況をよく考えると、GPUコアはPC向けCPUにとって統合するのにうってつけの対象だ。(1)PCで確実に必要とされるアプリケーション分野としてグラフィックスが存在しており、(2)より広汎なコンピューティング分野への適用が可能で、(3)汎用プロセッサコアの拡張では得られない性能ベネフィットがあり、(4)よりスケーラブルに拡張しやすいからだ。AMDにとって、GPU以外にPC向けCPUに統合する選択肢はなかったと言ってもいい。
(1)のアプリケーションの必要性は、CPUコアへの統合では非常に重要だ。ユーザーの誰もが必要とするコアを統合しないと、統合化の有効性を訴えにくいからだ。
 |
| AMDのPhil Hester(フィル・へスター)氏 |
「コプロセッサをCPUに統合することには、利点と不利がある。統合してしまえば、その機能を最低の追加コストで得られるようになる。しかし、不利な点もある。それは、(CPUを買うユーザー)誰もがその機能に対してコストを払わなければならない点だ」とAMDのPhil Hester(フィル・へスター)氏(Senior Vice President & Chief Technology Officer)は以前、語っていた。
PCエリアでは、GPUは必須で、特にWindows Vista以降は高い3Dグラフィックス性能のGPUコアが重要となる。Windows Vistaでは、CPUよりGPUの方がより重要になると言っていいかもしれない。そのため、CPUに統合されたGPUコアは、必ず有効に利用される。メインストリーム&バリューPCでは、PC上から1チップ少なくなるという利点がある。
しかし、もし、AMDがグラフィックス処理に最適化されていないベクタプロセッサを統合すると、話は違ってくる。AMDは、CPU外部に別個にGPUが必要となる。ソフトウェア側はGPUを必要とするが、CPU内部のベクタプロセッサは使うとは限らない。そのため、CPU内のベクタプロセッサの有用性は薄くなってしまう。
そう考えると、GPUでベクタプロセッサを包括できるのなら、GPUを統合してしまうのが理にかなった選択となる。
●ATI型アーキテクチャのGPUならより広い適用が可能に
(2)より広汎なコンピューティング分野への適用は、GPUのトレンドだ。特に、ATIが開発しているような、Unified-Shader型実装のDirectX 10世代GPUは、CPUへの統合に向いている。
Unified-Shader型では、GPUのShaderは、用途毎に専用化されたものではなく、汎用の一種類の実装形態のShaderとなる。そのため、全てのShaderを均一に利用することで、グラフィックス以外の処理を効率的に処理することができる。一例を挙げると、現在のGPUでは、Pixel Shaderだけでフィジックスを処理しているが、Unified-Shader型になると全てのShaderでフィジックスを処理できる。
GPUのShaderは、CPUのような汎用コンピューティングには向いていないが、メディアプロセッシングのように、デマンドが増している新コンピューティング分野には向いている。
 |
| ATIのDavid E. Orton(デビッド・E・オートン)社長兼CEO |
「我々のゴールは、マイクロプロセッサと競争することではない。より大きく広がり、かつ分割されつつある(コンピューティング)市場に対して、問題を解決する新しい手段を提供することだ。DirectX 10では、フロントエンド(ジオメトリ)とバックエンド(ピクセル)の両方に(同レベルの)浮動小数点演算プロセッシングをもたらす。我々は、その上で、フィジックスエンジンが非常に効率的に動くことをデモできるだろう。しかし、フィジックスは1つの例に過ぎない。他にもパフォーマンスを発揮できるアプリケーションが色々ある」とATIのDavid E. Orton(デビッド・E・オートン)社長兼CEOは6月のCOMPUTEX時に語っていた。
つまり、コンピューティングの分野が、より広がるのと同時に多様化しつつあり、GPUはそれに対するソリューションを提供できるというわけだ。
●汎用プロセッサよりも効率的に演算パフォーマンスを上げられる
(3)もっとも、CPUメーカーには汎用プロセッサコアの中で、ベクタプロセッシングエンジンを拡張する選択肢もある。実際、これまでIntelとAMDは、x86アーキテクチャを拡張する形でSIMD演算を追加してきた。しかし、この方式を発展させても、GPUのような専用ベクタプロセッサほどの性能ベネフィットは得にくい。
例えば、汎用プロセッサコアでは、CPUの演算ユニット以外の部分、命令の制御やキャッシュなどに膨大なトランジスタをつぎ込んでいる。それに対して、GPUは複雑な命令スケジューリング機構を持たず、演算に必要なユニットに集中してトランジスタを投入している。そのため、ダイ(半導体本体)面積当たりと消費電力当たりの演算パフォーマンスは、汎用プロセッサコアよりもずっと高い。AMDは、GPUコアを統合すれば、簡単に数100GFLOPSの演算性能を得ることができるが、汎用プロセッサではハードルが高い。
また、汎用コンピューティングと、グラフィックスに代表されるベクタプロセッシングでは、プログラムのビヘイビアに大きな違いがあり、そのため、最適なプロセッサアーキテクチャが異なってくる。例えば、グラフィックスでは汎用プロセッサのような大容量で深いキャッシュメモリ階層は向かない。そもそも、キャッシュに載りやすいデータとそうでないデータがあり、ストリーム型処理では、キャッシュ自体が邪魔になるケースが多い。
汎用プロセッサにはさまざまなレガシーがあり、それもアーキテクチャを制約している。例えば、x86系の命令ストリームに、さらにコプロセッサ向けの命令をインサートしようとすると、命令セットはますます複雑となり、非効率になってしまう。そもそも、GPUは命令セットを隠蔽し、APIでラップしている。GPUネイティブのISA(命令セットアーキテクチャ)は露出しないため、互換性を保ちながらISAをGPU世代毎に切り替えることでラディカルなアーキテクチャチェンジを可能としてきた。ソフトウェアのモデル自体が、汎用CPUとは異なる。
GPUは、特化しているため、汎用プロセッサコアを拡張するよりも、ずっと効率的にベクタプロセッシングができることになる。
●スケーラブルにコンフィギュレーションを拡張しやすいGPU
(4)同じアーキテクチャで、よりスケーラブルに拡張しやすい点も魅力だ。AMDがATI GPUをCPUに統合した場合、外付けのGPUとも、シームレスに処理を分散化できる。すでに外付けのグラフィックスカードというソリューションが普遍的なので、簡単に低コストに拡張ができる点が魅力だ。ダイサイズ(半導体本体の面積)とメモリ帯域の関係上、外付けGPUの方が内蔵GPUよりハイパフォーマンスになるはずなので、さまざまなコンフィギュレーションが考えられる。
例えば、メインストリーム&バリューPCでは、CPUに統合したGPUコアで必要な処理は全てまかなう。よりグラフィックスパフォーマンスが必要な、例えばゲーム向けハイエンドPCの場合は、外付けした1個または多数のGPUに、グラフィックス処理は実行させて、CPU内部のGPUコアには、フィジックスなど別な処理を行なわせる。あるいは、全てのGPUコアをグラフィックスに振り向けてもいい。
あるいは、その逆も可能となる。例えば、膨大な量のデータプロセッシングが必要な場合、グラフィックスはCPU内部のCPUコアで処理し、データ処理は外部のGPUに出すことも可能となる。例えば、H.264のエンコードをアクセラレートしたいといった場合、外側のグラフィックスカードにビデオ処理を投げて、グラフィックス表示は内蔵GPUで行なうといったことも可能だろう。
また、GPUを内蔵しないCPUのコンフィギュレーションを混ぜることも可能だ。AMDのHound系はクアッドコアで、サーバーと兼用で汎用プロセッサコアを4ユニット搭載する。こちらの系統のコアが、早期にGPUコア統合へと向かうとは思えない。サーバーエリアでは、異なるコプロセッサの方が重要だからだ。しかし、その場合も、Houndコアは外付けのGPUを使うことができる。
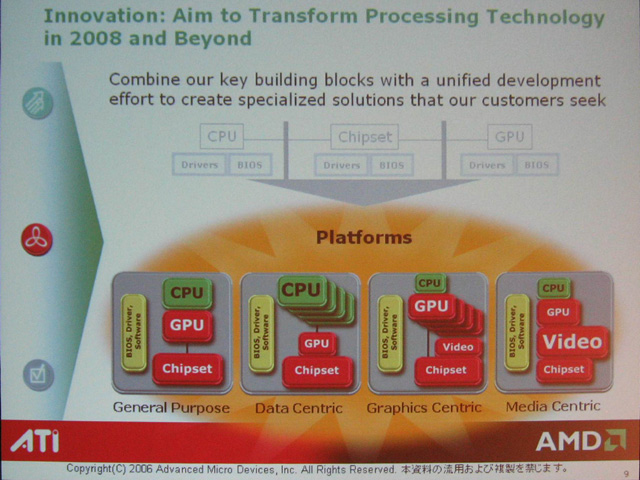
AMDとATIは、買収発表時に下のようなスライドで、「General Purpose」、「Data Centric」、「Graphics Centric」、「Media Centric」といった構成を挙げた。これらの例は、上で説明したコンフィギュレーションで説明できる。
(1)General Purposeは2個程度の汎用プロセッサコアとGPUコアを統合したCPUに、I/O機能のみのチップセットを組み合わせた例だと考えられる。(2)Data Centricは、汎用プロセッサコアを4または8個搭載したサーバー向け兼用のCPUに、外付けのGPUを組み合わせた例と推測される。(3)Graphics Centricは、CPU内部のGPUコアと、外付けのGPUを全てグラフィックスやビデオ処理に回した例だろう。(4)Media Centricは、CPU内蔵のGPUコアにグラフィックス処理を、外付けのGPUにビデオ処理を振り分けた例だと推定される。
すでに、PCの中で確立しているGPUを統合することで、AMDはこれだけのスケーラビリティを得ることができる。それを考えると、PC向けCPUではGPU統合が最も理にかなった選択と納得ができる。
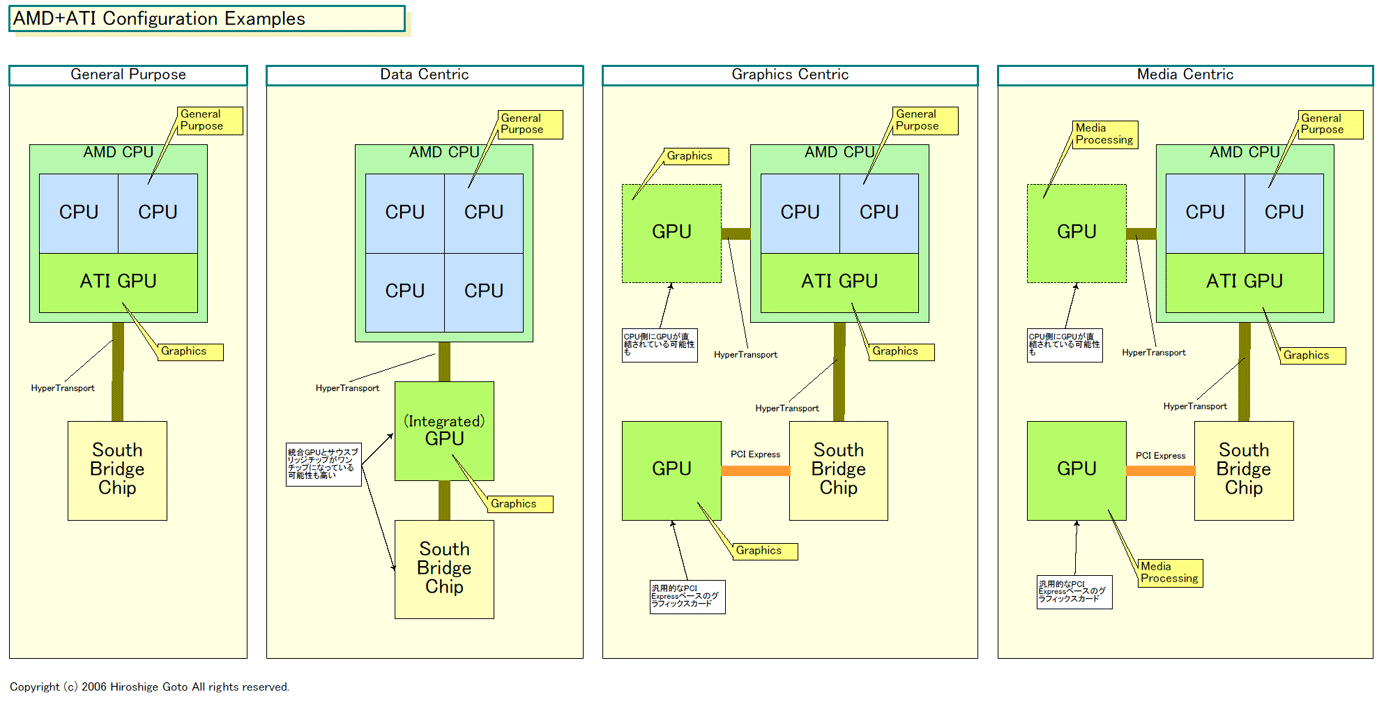 |
| AMD+ATI Configuration Examples (※別ウィンドウで開きます) PDF版はこちら |
□関連記事
【7月27日】【海外】正反対の方法論で対決するATIとNVIDIA
http://pc.watch.impress.co.jp/docs/2006/0727/kaigai291.htm
【7月25日】【海外】AMDとATIのプロセッサは1つに融合する
http://pc.watch.impress.co.jp/docs/2006/0725/kaigai290.htm
【7月21日】【海外】コプロセッサへの分散が進むAMDの次世代CPU
http://pc.watch.impress.co.jp/docs/2006/0721/kaigai289.htm
(2006年8月2日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.