 |


■後藤弘茂のWeekly海外ニュース■R580とG71で衝突するATIとNVIDIA |
●位置づけが不思議なハイエンドGPU
ハイエンドGPUは、奇妙なシロモノだ。誤解を恐れず言ってしまえば、大多数のエンドユーザーにとって、性能面のありがたみが薄い製品なのに、激しい技術競争が続いている。半年毎に、モンスターチップが登場し、パフォーマンスと消費電力のバーをさらに押し上げる。その割に、3Dグラフィックスフィーチャのほとんどは、現状ではほとんどゲームでしか使われない。ゲーマーかCADユーザーでないなら、3Dパフォーマンスはオーバーキルだ。ユーザーの関心が続くのが不思議に思えるほどだ。
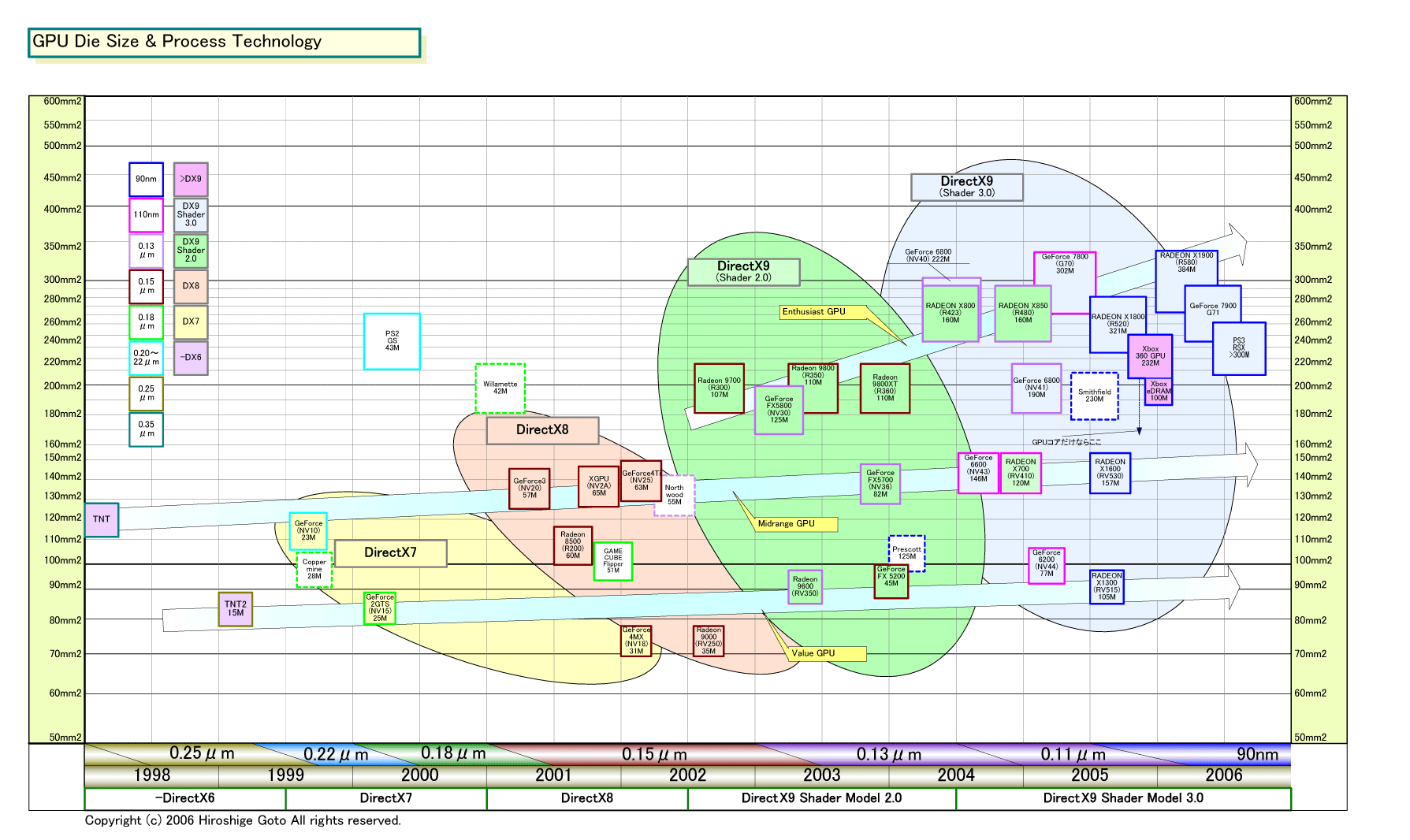 |
| GPU Die Size & Process Technology(別ウィンドウで開きます) PDF版はこちら |
また、GPUメーカーにとっても、ハイエンドGPUは特殊な位置づけの製品だ。まず、ダイサイズが大きいため、製造コストを考えると利益を出しにくい。利益がないわけではないが、コンシューマ向けでは、儲け頭には決してならない。ワークステーション用は利幅が厚いが、市場が限られている。
GPUベンダーにとって、今のフラッグシップGPUは、売れるから作りたいというシロモノでは決してない。その証拠に、トップで競る2社以外は、もはやこのクラスのGPUは作らない(3Dlabsを除く)。以前、あるGPUベンダーの関係者は、NVIDIAやATI Technologiesのハイエンドと同じクラスのGPUを作っても、コストを考えると全くビジネスにならないと語っていた。
では、なぜGPUベンダーは、利益も薄くユーザーも少ないハイエンドGPUを作るのだろう。その理由は、3Dグラフィックス市場のトレンドを引っ張ったGPUメーカーが、その下の市場でも成功を収めるという図式が過去5~6年でできあがって来たからだ。そのため、トップGPUベンダーは、市場を取るためには、ハイエンドGPUで勝利を収めなければならないという雰囲気がある。
ハイエンドGPUが、その性能とフィーチャでソフトウェア(主にゲーム)ベンダーの支持を受けると、ソフトウェアがGPUに最適化される。すると、GPUベンダーは、ゲームユーザーに支持され、ハイエンド市場を征することができる。ハイエンド市場を握ると、高パフォーマンスイメージがその下の市場やユーザーへも波及してゆく。すると、PCベンダーやボードベンダーが、メインストリーム&バリューでもそのメーカーのGPUを採用するようになる。PCベンダーが採用するGPUは、サポートも考慮すると1~2社のアーキテクチャに限られるため、ハイエンドを握ったベンダー以外はニッチに押し込まれることになる。そのため、ウイナーテイクオールの市場支配が可能になる。
ラフに言えば、こうした図式だ。そして、この図式で最も成功したベンダーがNVIDIAだった。だから、NVIDIAは、常にパフォーマンストップを狙い、アーキテクチャで先行することに執着していたわけだ。
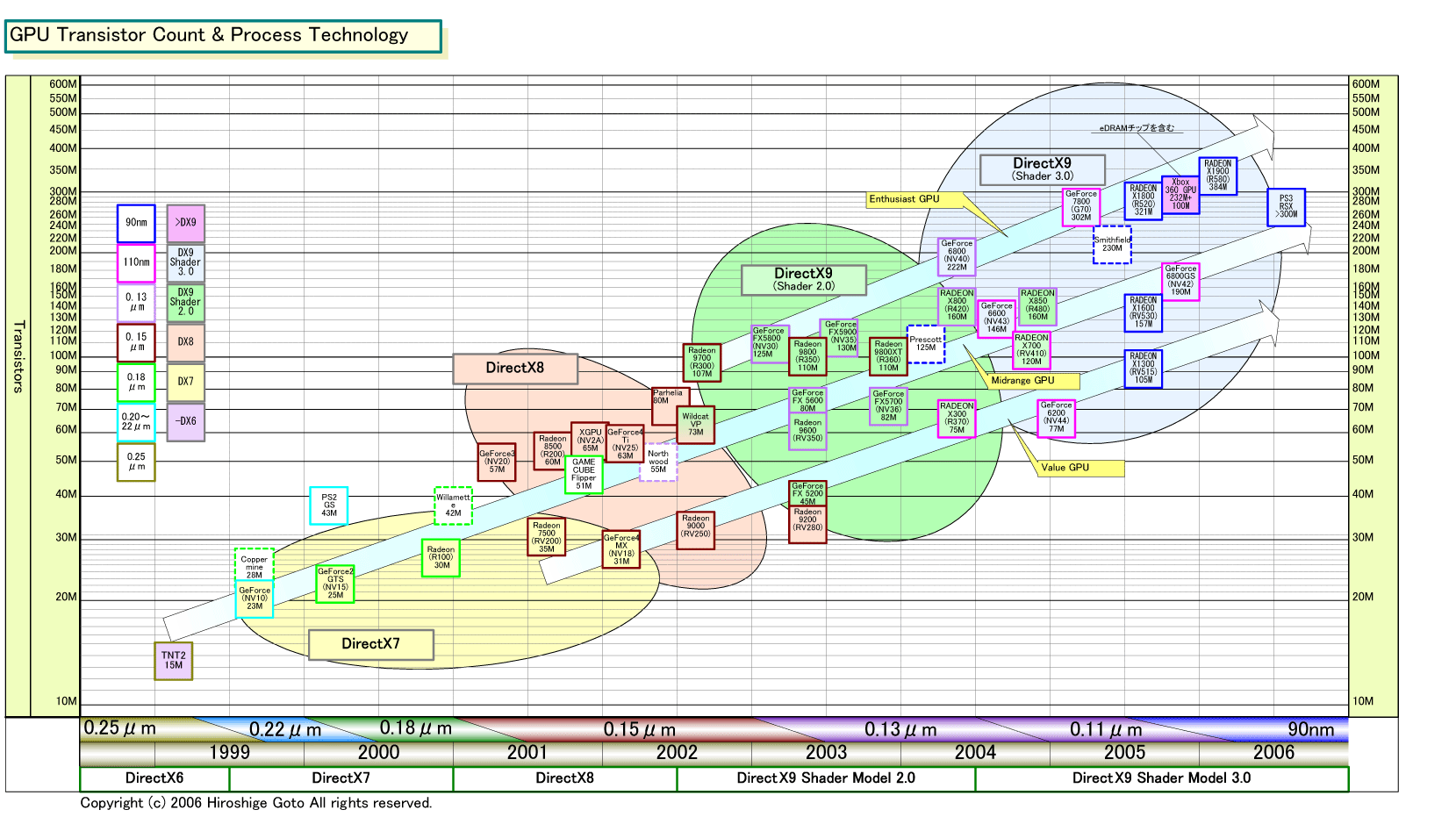 |
| GPU Transistor Count & Process Technology(別ウィンドウで開きます) PDF版はこちら |
●Windows VistaがGPUベンダーの競争を激化させる
ATIも、「Radeon X1900(R580)」ようなモンスターをハイエンドに持って来ることは、NVIDIA型の戦略を狙っていることを示している。ハイエンドを征することで、ソフトウェア側の支持を得て、市場全体を取ろうという戦略だ。
ATIは、Radeon 9700(R300)までは、3Dグラフィックスではほとんど常にNVIDIAの後を追っていた。新プロセス技術も新アーキテクチャも、実装はNVIDIAが先で、ATIがその後に回るパターンだった。その反面、ATIの方がGPUのダイサイズが小さく、製造コストが低く、より利益を出しやすい構造を守っていた。つまり、NVIDIAがリスクテイカーであるのに対して、ATIは利幅重視の慎重派だったわけだ。
こうしたATIの姿勢は、ATIの過去の戦略とも関連する。ATIは、以前は自社でチップとボードの両方を作って売るというビジネスモデルを取っていた。その時代は、他のGPUベンダーと同列に比較されることのない、言ってみれば閉じた世界でいた。そのモデルでは、慎重に利幅を重視する方が有効だった。
だが、ATIも市場の変化に対応してチップ外販に戦略を変更して以来、競争を力づくで勝ち抜く必要が出てきた。ATIは、徐々にそうした状況に適応を進め、GPU開発体制を整え(開発チームを2本化した)て、DirectX 9世代からはNVIDIAとハイエンドで競う戦略に出た。
ところが、DirectX 9世代GPUでは、ライバルNVIDIAが出だしでつまづいてしまった。GeForce FX 5800(NV30)で大きく出遅れ、さらに、NV30の凝ったアーキテクチャで失敗をした。そのため、NVIDIAと競るつもりだったATIは、いきなり単独でトップランナーに躍り出てしまった。ATIの戦略が明瞭に変わったのはここからで、それ以降は、常にNVIDIAと正面対決して来た。
この競争を勝ち抜くためには、GPUベンダーは、常にソフトウェアデベロッパの支持を得られるフラッグシップGPUを出し続けなければならない。デベロッパを驚かせて、これならソフトウェアを書きたいと思わせれば、競争を有利に導けるからだ。ATIが、今回、さらにダイを大きくしてアーキテクチャを強化したのは、こうした背景がある。
GPUメーカーの競争に、さらに拍車をかけているのは、Windows Vista(Longhorn:ロングホーン)の存在だ。Windows Vistaの新しいユーザーエフェクト「Aero Glass」は、3Dグラフィックスハードを使うため、GPU性能がエンドユーザーの快適さに直結する。つまり、いったんWindows Vistaが出れば、今度は普通のエンドユーザーがGPUの3Dグラフィックス性能に強い関心を持つようになると期待できる。
すると、その時までに、ブランドイメージを固めておかないと、GPUの歴史上、最大のビジネスチャンスを逃すことになってしまう。Windows Vista後は、ハイエンドGPUを征するものが、全体市場を征するという図式が、さらに固定化されるかもしれない。そのため、ATIとNVIDIAの両社は、最後のデッドヒートを繰り広げているというわけだ。
●20%のトランジスタ数増加で100%の演算能力アップ
ATIの新ハイエンドRadeon X1900(R580)がいかにモンスターであるかは、そのチップ規模を見ればわかる。R580のトランジスタは384M(3億8,400万)で、昨秋発表した「Radeon X1800(R520)」の321M(3億2,100万)を20%上回る。ダイサイズ(半導体本体の面積)は公表されていないが、概算ではR520の280平方mmクラスから、さらに20%ほど増えて350平方mm程度に膨れあがっている。トランジスタ数ではGPUで過去最高、CPUと比較すると「Pentium D(Smithfield:スミスフィールド)」の230Mの約1.5倍のチップだ。消費電力は、条件によって大きく異なるが、ストレス時で150W程度(カード)とATIは説明する。これもPentium Dを上回る。
かなりのモンスターだが、それでもATIは、トレードオフとしては悪くないと見ているようだ。R520からR580で、トランジスタ数とダイサイズを20%増やしただけで、Pixel Shaderの数を3倍の48個にし、GPU全体のプログラマブル演算ユニット(ALU)数を2倍以上に増やしたからだ。理論上の演算能力では、R580はR520の2倍の性能を持つことになる。
ALUが倍になっても、トランジスタが20%しか増えないのは、マジックでも何でもない。最新GPUの中では、ALU部分が占めている割合が、比較的小さいからだ。「Shader ALUは、テクスチャユニットなどと比較すると、実装コストが安い」とATIのAndrew B. Thompson氏(Director, Advanced Technology Marketing)は昨秋のインタビューで語っていた。つまり、ALUだけを増やすなら、ダイサイズをある程度抑えながら演算性能を伸ばすことが可能というわけだ。
また、この拡張は、NVIDIAを横目で見ながらという雰囲気も漂う。NVIDIAの「GeForce 7800 GTX(G70)」のダイサイズは338平方mm。今回、ATIはほぼこれと同列のサイズにGPUを肥大化させた。「NVIDIAがこのサイズのGPUを作るなら、うちだって同レベルのダイのGPUを出してやる」というATIの対抗心が聞こえて来そうだ。同サイズのGPUを設計するなら、どうできるかを計算したら、Pixel Shader ALUを増やすアーキテクチャになったのかもしれない。
●Pixel Shaderプロセッシング性能にフォーカス
もっとも、前回も書いたが、Pixel Shaderのプロセッシング能力の向上にフォーカスするというのは、3Dグラフィックス業界全体の長期的なトレンドだ。3~4年ほど前から、GPUベンダーはこうした主張を繰り返している。例えば、ATIのライバルNVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)は、4年前に「データフローは増やせないが、GPUのプロセッシングパワーは増やせる。すると、論理的な帰結は、より多くのピクセルを処理するのではなく、より良いピクセル処理に向かうことになる」と語っていた。
ラフに言うと、ジオメトリ性能はホストバスとホストプロセッサに制約され、ピクセル性能は画面解像度とビデオメモリの帯域に制約される。以前のGPUは、1クロック当たりに処理できるピクセル数を増やすことにフォーカスしてきた。しかし、ピクセル性能は、画面解像度がリニアに上がらないためそれほど上げる必要がないし、DRAMメモリの転送レートはムーアの法則ほどのペースで上がらない。まだアンチエイリアシングで上げる必要はあるものの、それでも、いつかは飽和する。
それに対して、GPU内部の処理能力の方は、ムーアの法則を上回るペースで連綿と伸び続けている。ハイエンドGPUはダイサイズも増やすことで、2年で2倍以上のペースで搭載トランジスタ数を増やしている。結果として、余った部分(トランジスタ)は、シェーダの演算能力をアップさせる方向へと振り向けるしかないわけだ。1つのピクセルを何度も演算することで、より良い絵を得る方向へ行く。外部とのバランスを考えると、それが最も適切な使い方となる。また、より長くて複雑なシェーダ(プログラム)を書きたいソフトウェアデベロッパのニーズとも合っている。
そのため、GPUベンダーは、シェーダプロセッシング能力を伸ばした派生アーキテクチャへと伸ばす方向にある。
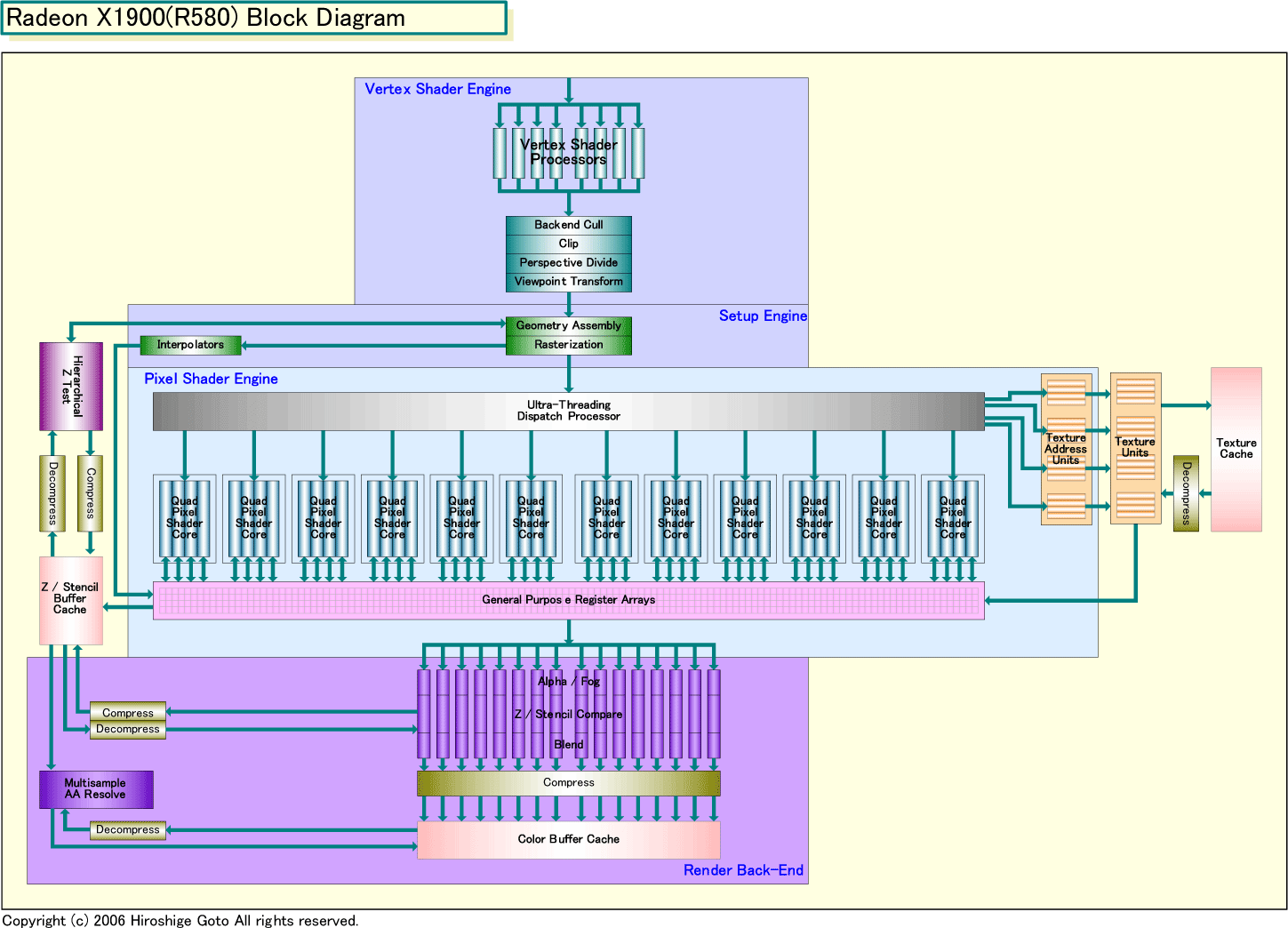 |
| Radeon X1900(R580) Block Diagram(別ウィンドウで開きます) PDF版はこちら |
ATIのR500(X1000)ファミリ全体を眺めると、この傾向がもっとよくわかる。というのは、ハイエンドのR580とR520の関係は、ミッドレンジのRadeon X1600(RV530)とメインストリーム&バリューのRadeon X1300(RV515)の関係とよく似ているからだ。RV530のテクスチャユニットやレンダバックエンドの構成は、下位のRV515とかなり似ている。テクスチャユニットは4、レンダバックエンドのうち「ROP(Rasterizing OPeration)」ユニットは4と、ここまでは両GPUは同じ。しかし、RV530のPixel Shader ALUは12ユニットで、RV515の4ユニットの3倍。RV530の場合は、Vertex ShaderとZコンペアもRV515より強化されているが、拡張の主眼がピクセルプロセッシングにあることは疑いもない。
この発想は、R520の基本構成の中の、Pixel Shader ALUにフォーカスして強化したR580と共通している。つまり、この派生のさせ方は、技術トレンドだということだ。
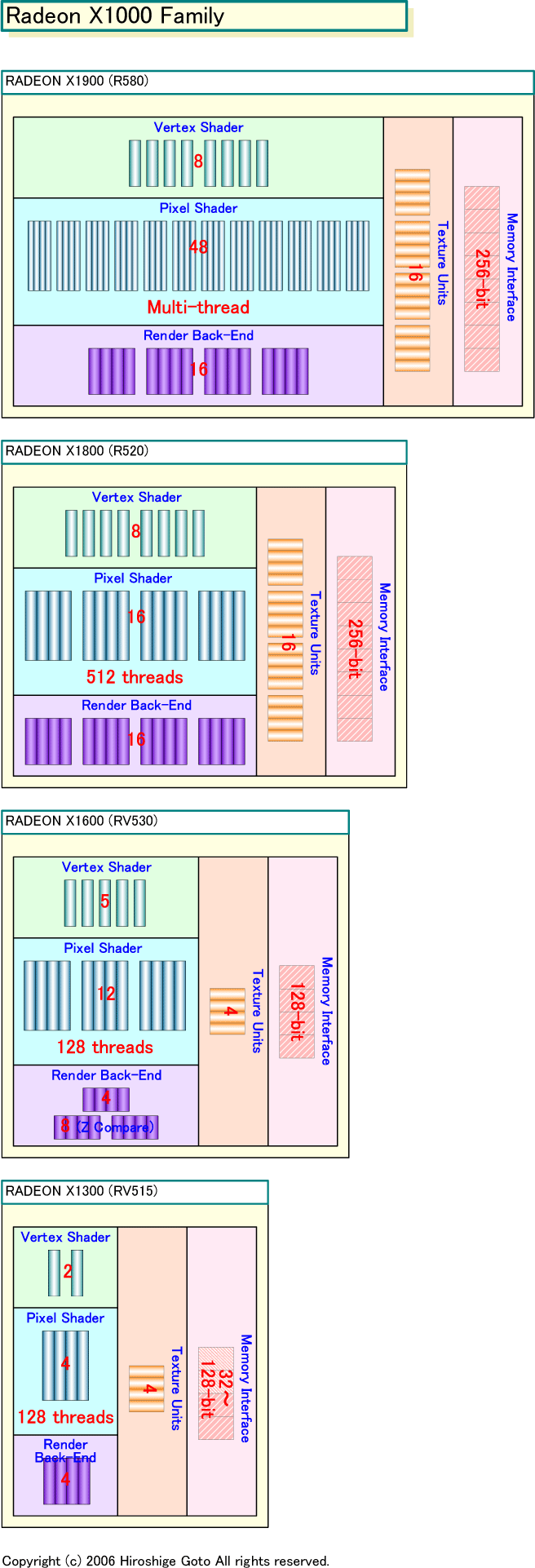 |
| Radeon X1000 Family(別ウィンドウで開きます) PDF版はこちら |
●NVIDIAはどう対抗するのか
R580を投入してのATIの挑戦に対して、NVIDIAはどう対抗するのだろう。
現時点で、対抗する弾をまだ発表していないNVIDIAは、まずR580のアーキテクチャ上の効率性に疑問をぶつけてきた。同社によると、R580とGeForce 7800 GTX(G70)を比べた場合、G70の方がダイサイズと消費電力当たりのパフォーマンスが高いと言う。つまり、G70系の方が、パフォーマンス/ダイサイズ&ワットの高い、効率のよいアーキテクチャだと言っているわけだ。
NVIDIAの現在のG70のダイサイズは338平方mmと大きいが、これは110nmプロセスで製造しているため。NVIDIAによると、G70アーキテクチャそのままで90nmに微細化すると計算上226平方mmになるという。90nmのR580のダイは350平方mm程度なので、同等プロセスで試算するとR580はG70の1.5倍のダイサイズになるというのがNVIDIAの指摘だ。また、消費電力はG70が120Wなのに対して、同等条件ではR580は180WになるとNVIDIAは試算する。
NVIDIA側の見積もりでは、両GPUのパフォーマンスレベルはほぼ同等なので、G70アーキテクチャの方が効率がいいという主張だ。同性能なのに、1.5倍もダイが大きくて製造コストが高く、消費電力も50%多くて排熱がやっかいなGPUと非難しているわけだ。
この手の主張自体は、いずれも自社に有利にバイアスをかけるため、そのまま受け止めるわけにはいかない。ATI側にも、突っ込みたいポイントはいくつもあるだろう。
しかし、重要な点はそこにはない。もっとも重要なことは、NVIDIAがここでGPUの効率性に注目し、同じ90nm世代で比較するところへ力点を持ってきたことだ。裏返せば、NVIDIAは、同じ90nmプロセスで比較するなら、より効率性が高い(そのためにパフォーマンスの高い)GPUを同社が提供できると言っているわけだ。
●NVIDIAもPixel Shader強化の方向へ?
NVIDIAも、同社のGPUを90nmプロセスへと移行させつつある。NVIDIAは、新しいShader Modelアーキテクチャの採用ではATIに先行したが、新プロセス技術に関しては、現在はATIの後を追っている。ATIがR500系を90nmプロセスで製造しているのに対して、NVIDIAのGeForce 7800 GTX(G70)は110nmプロセスだった。
しかし、NVIDIAも、1月には同社初の90nmプロセス(TSMC)のGPU「GeForce 7300 GS(G72)」を発表した。さらに、ハイエンドGPUもそう遠くないうちに90nm世代の「G71」へと移行が始まると見られる。このG71が、R580への対抗馬となる。
現在のG70をそのまま、90nmに微細化すると計算上ダイは226平方mmになる。しかし、NVIDIAがハイエンドGPUのダイサイズをほぼ同等(340平方mm前後)に維持するつもりなら、同社は最大50%トランジスタを増やすことができる計算になる(実際にはリニアにシュリンクしない部分も多いため50%にはならない)。その分、機能とパフォーマンスを伸ばすことができるわけだ。ATIと角突き合わせるNVIDIAが、限界のダイサイズまで、機能を詰め込まないはずはないだろう。
NVIDIAが90nmプロセスで、ATIに次の戦いを挑むにあたって、ポイントを効率性に持って来たことは示唆的だ。Pixel Shaderの単純な数では、ATIに負ける(または同等)かもしれないが、効率性がずっと高いので性能が高いと主張する下地を作っているように見える。
NVIDIAはATIの48個のPixel Shaderに対して、バランスが悪いといった指摘は今のところしていない。これは、NVIDIAもまた、次の世代でPixel Shaderを増やすことを示唆している。しかし、ユニットの並列性でATIを超えるといった豪語も聞こえない。このことは、見かけ上の並列度ではATIの方が上回っていることを示唆している。これは、G71のPixel Shaderが32ユニットという情報とも合致する。
そもそも、Pixel Shaderのアーキテクチャは、NVIDIAとATIで大きく異なるため、単純に比較できないし、シェーダ(プログラム)の実行効率もおそらく異なる。
ATIはR5xx系アーキテクチャでは、Pixel Shader ALUとテクスチャユニットを分離した。それに対して、NVIDIAアーキテクチャの場合は、Pixel Shader ALUとテクスチャユニットは密接に結合している。これは、GeForce 6800(NV40)以降のアーキテクチャでは、テクスチャユニットのプログラマブル演算コアを、Shader ALUとしても使えるようにして、Shader内部の並列性を上げているからだ。
そのため、NVIDIA GPUは、Pixel Shader内部での命令レベルの並列性は高いが、Pixel Shaderユニットの規模は、原理的にATIより大きい。つまり、NVIDIAがPixel Shaderを増やす場合には、ATIよりもユニット当たりの実装コストが高くつき(=より多くのトランジスタとダイエリアが必要)、ATIのように、Shader ALU部分だけを単純に増やすことができないと推測される。
いずれにせよ、今後のGPUの発展のポイントが、Pixel Shaderのプロセッシング能力になってきたことは確実だ。そして、それは、おそらくWindows VistaのUIにとっても、プラスに働く。Windows VistaのUIも、アプリケーションが活用し始めると、Pixel Shaderプロセッシングに負担がかかるだろうからだ。
□関連記事 (2006年1月27日) [Reported by 後藤 弘茂(Hiroshige Goto)]
【1月25日】【海外】Pixel Shaderを3倍にしたモンスターGPU「Radeon X1900」
http://pc.watch.impress.co.jp/docs/2006/0125/kaigai235.htm
【1月25日】ATI、シェーダーパフォーマンスが向上した「Radeon X1900」
http://pc.watch.impress.co.jp/docs/2006/0125/ati.htm
【1月25日】【多和田】早くもトップ交代、ATI「Radeon X1900 XT」
http://pc.watch.impress.co.jp/docs/2006/0125/tawada67.htm
【PC Watchホームページ】
PC Watch編集部
pc-watch-info@impress.co.jp
ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.