
|
Spring Processor Forum 2005レポート
~Sun Niagaraともう1つのメニイコア
カンファレンス会期:5月17日~18日(現地時間)
会場:米カリフォルニア州サンノゼ
DoubleTree Hotel
SPFレポートの最後は、2種類のメニイコアについてご紹介したいと思う。
●Sun Niagara
 |
| Sun Microsystems, Distinguished EngineerのWilliam Bryg氏 |
最初はSun Microsystemsの「Niagara」である。後藤氏のレポートでもしばしば引き合いに出されているので、聞き覚えのある読者も多いだろう。今回はSPFでこのNiagaraが公式に発表されたので、ちょっとまとめておきたいと思う。
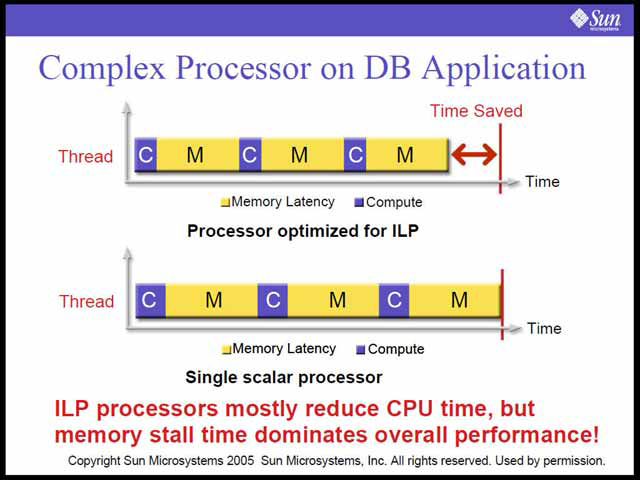
まずNiagaraの基本的な発想は、サーバー上で動くアプリケーションの多くは、ILP(Instruction Level Parallelism:命令レベルの並列性)を向上させるといっても限界があり、それよりはTLP(Thread Level Parallelism:スレッドレベルの並列性)を高めたほうが効果的だ、というところから来る。
 |
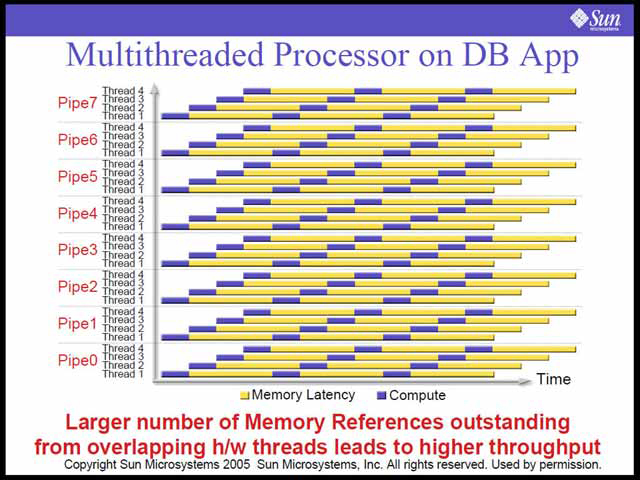 |
| 例えばデータベースの場合、処理のほとんどがメモリ待ちになるので、ILPを追求しても効果はごくわずか | TLPを向上させることで、メモリ待ちを遮蔽することが可能になり、結果として大幅な性能アップが可能になる、という模式図 |
これを推し進めた結果、NiagaraはきわめてTLPに富んだCPUコアを、広帯域のキャッシュとメモリシステムで支えるという、かつてMPF'99で(当時の)Compaqが発表した「Alpha EV8」プロセッサを彷彿とさせる構成になっている。CPUコア自体は決して複雑ではない。TLPを追求するためには、個別のコアを複雑化してIPCを追求しても効果は薄いので、むしろシンプルなコアにしたほうが性能/消費電力比を高く取ることができる。
その分、これを支えるキャッシュとメモリのメカニズムは強烈だ。各々のCPUコアは16KB/8KBの命令/データキャッシュを持つが、このコアを8つ集約し、これを専用のクロスバースイッチで3MBのL2キャッシュと接続、更にその先に複数のDDR2メモリを接続できるメモリコントローラがあるという重厚な構成である。そのメモリコントローラも、複数トランザクションをアウトオブオーダで発行できるというもので、普通のメモリコントローラと一線を画したものである。
 |
 |
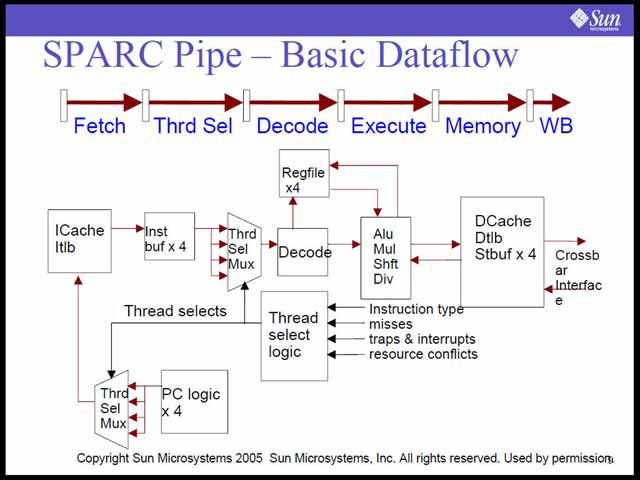
| もともとSPARCのパイプライン構成は、それほど複雑ではない。現在のUltraSPARC III/IV/IV+はいずれも比較的単純なパイプライン構成であり、これを4wayのSMT化した形だ | クロスバースイッチがほとんどL2キャッシュ専用になっていることに注意。ちなみにSun Microsystemsは早くから密結合マルチプロセッサの接続に広帯域のクロスバースイッチを利用していたメーカーの1つであり、これが今回の設計にも活かされたであろうことは容易に想像できる |
今回は、実際のダイレイアウトと共に、動作サンプルがあることが示されたが、具体的な動作周波数や性能、消費電力などに関しては「今の時点で公表できる数字はない」(Q&Aセッションで)ということで未公開だった。したがってメニイコアのアーキテクチャがどの位有効かという議論はもう少し後にならないと始められないわけだ。
 |
 |
 |
| PC用チップセットのメモリコントローラは、デュアルチャネルであってもインオーダアクセスしかサポートしておらず、ごく一部のメーカーがマルチバンクスイッチを採用しているものの、アウトオブオーダまでは行なっていない。大体メモリアクセスをアウトオブオーダで制御できるほど高速なメモリコントローラはあまりお目にかかる機会はなく、その点でもこれが驚異的であることがわかる | コア内部。4列×2段に配置されたCPUコアの周囲に4分割された形でL2キャッシュが配置され、中央にクロスバースイッチが置かれる構造 | Niagaraのプロトタイプ。明確にはされていないが、恐らく4chのDDR2メモリを搭載するものと考えられる |
●RMI XLR
 |
| Raza Microelectronics, Principal ArchitectのDave Hass氏 |
もう1つのメニイコアのサンプルはRMI(Raza Microelectronics, Inc.)のXLRプロセッサである。RMIはネットワークプロセッサを製造するファブレス企業で、XL/Pegasas/Orionという製品ラインを持ち、エッジルーターからコアルーターに至るマーケットをターゲットにしている。ところが昨今の場合、
・単なるネットワークスループットではなく、アプリケーション性能が求められる
・さまざまなアプリケーションを同時に動かす必要がある
・セキュリティに対する要望が高まっている
・ネットワークセンターではクラスタ化がトレンドになっており、よりインテリジェンスな製品が求められる
という動きがあるという。ここで言うアプリケーションはWebサーバなどではなく、例えばファイアウォールソフトだったりウィルススキャンだったり、あるいはQoSだったりある種のパケットスニファリングだったりとさまざまだが、こうしたものがルータ上で多く稼動するようになり、より高いパフォーマンスが必要とされているという話だ。
ここで面白いのは、例えばファイアウォールとQoSは当然同時に動くので、これはマルチスレッドとして扱えることになる。あるいはファイアウォールを取っても、パケットをパースするところはシリアルだとしても、その先でSPI(Stateful Packet Inspection)を実施するところは当然セッション別の処理になるから、これまたマルチスレッド化させやすい。要するにネットワークプロセッサに求められるのは、高ILPではなく高TLPということになる。
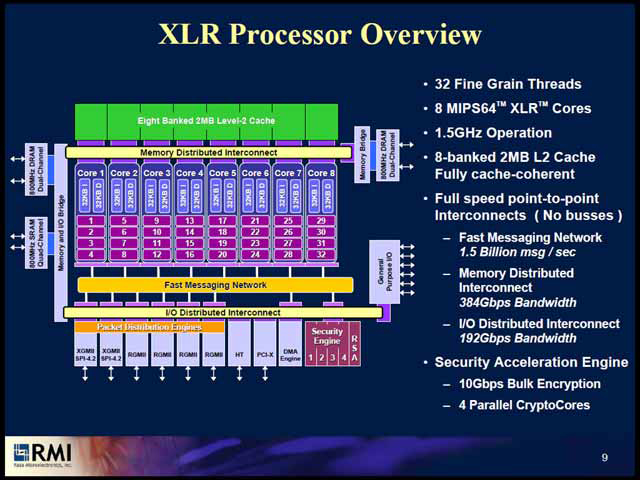
この結果としてXLRは、MIPS64コアをマルチスレッド化した上で、それを8コア並べるという、まるっきりNiagaraと同じ構成になってしまった。ちなみに本来のMIPS64自体はマルチスレッドに未対応である。
2003年のEPF2003レポートで少し触れた通り、MIPSはSMTをサポートする計画はあるものの、それはMIPS32をベースとしたもので、現時点ではまだ製品は存在しない。従ってこのSMT化は、RMIが独自に行なったものと考えられる。実際RMIはMIPS64のアーキテクチャライセンスを取得しており、独自にアーキテクチャを改変することに問題はない。
ではなぜ4Wayにしたか、という話だが、4wayあたりまではそれなりに性能向上が見られるが、それ以上は性能が上がらない割に複雑になるため、4wayがちょうどバランスの良いポジションだ、という説明があった。
 |
 |
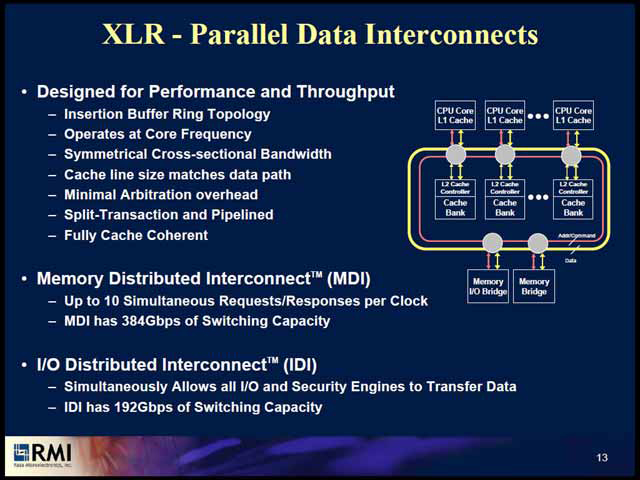
| 各コアは1.5GHzで動作し、これをInterconnect(これは後述)経由で2MBのL2キャッシュと接続する構造。このInterconnectにはメモリも接続され、Interconnectのピークバンド幅は384Gbps(48GB/sec)というかなり広帯域なものである | もっともこのあたりは、アプリケーションによって当然変わってくるから一概には言えない。ただ多くのアーキテクチャがこの4wayマルチスレッドを採用しているところを見ると、このあたりがちょうどバランス的に好ましいのだろう |
ただ、こうしたマルチスレッドがその性能を発揮するためには、とにかくメモリ帯域が必要ということになる。これを実現するための手法がユニークで、高速なリング形状でInterconnectを構成している。このリング形状はメモリ側のみならずI/O側にも適用されており、リング速度は1.5GHzまで上げられるため、I/Oスループットにも不足はないと考えられる。メモリブリッジは、最大で800MHz(つまりDDR2-800までサポート)し、これを4ch搭載するから最大帯域は25.6GB/secに達している。
これだけ複雑ならさぞ規模も大きかろうと思うが、確かにトランジスタ数は3億3,300万個に達するが、TSMCの90nmプロセスでダイサイズは226.4平方mm程度。規模を考えると、かなり小ぶりと言っても良い。
本質的な問題として、ネットワークプロセッサのマーケットが(ルーターメーカーの集約化や独自アーキテクチャの利用が進みつつあるという理由で)あまり大きく広がっていない状況で、XLRがどの程度のパイをつかめるのか、という話ではあるが、アーキテクチャ的には非常に面白い実装である。
 |
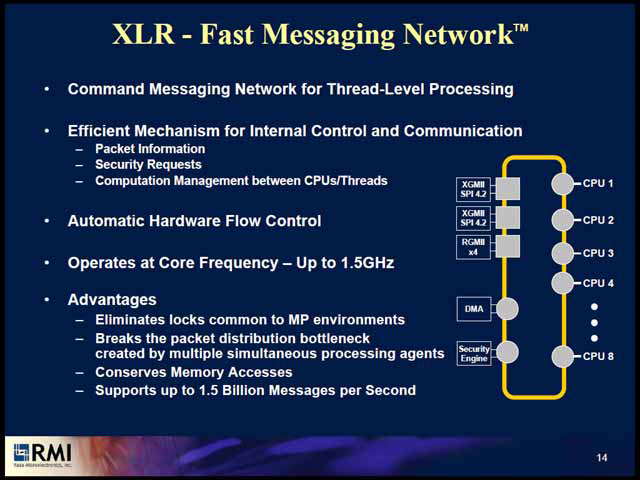 |
| アドレス/コマンドとデータを分離した上で、リング状に繋ぐというのはあまり例がない。このリングの詳細は語られなかったが、双方向リングというわけではなさそうである。ただ、メッシュあるいはツリー構造だと、ノード数が増えるとレイテンシがどんどん増えてゆくので、これを嫌ってなのかもしれないが | メモリ側は1.5GHz動作で48GB/secだから、データ幅は32bitということになる。一方I/O側は最大1.5Billion Messagesとなっており、このMessageのサイズが良くわからないが、今時8bitのMessageは考えにくいわけで、最低でも16bit幅、ひょっとすると32bit幅の可能性もあるだろう。16bitでも24GB/secに達するので、大抵のネットワークは十分まかなえる帯域である |
 |
 |
| ネットワークプロセッサらしく、DDR1/2のほかにRLDRAM(Reduced Latency DRAM)をサポートしている。RLD2とはRLDRAM2の略で、例えばMicronの「MT49H32M9」(32M×9bit)の場合、400MHz動作でもほぼ1clockでアクセスが可能となっている | トランジスタは5割ほど多いが、大体IntelのSmithfieldと同程度のサイズということになる。ただ動作周波数は1.5GHz止まりだから、消費電力はもっと少ないだろう。それよりも問題は価格であって、Smithfieldは例えばPentium D 820なら241ドルだから、これよりちょっと高い300ドルでも元は取れることになる。まぁ生産量が桁違いだから、もっと開発コストやマスクコストを上乗せする必要があるにせよ、この手のハイエンドネットワークプロセッサとしてはかなり安く上がることが想像される |
●メニイコアの問題点
とりあえず2つのメニイコアの実装を見ていえることは、性能を確保するためには広帯域なキャッシュ/メモリが必要とされるということである。思うに、NetBurstアーキテクチャが2スレッド止まりなのは、単に演算ユニットの数がそれほど多くないとか言う以上に、根本的にキャッシュ/メモリ帯域が不足していて3スレッド以上動かしても効果が無い、という話ではないかという気がしてくる。
これを解決するためには、単にキャッシュを増やすというだけでは不十分で、メモリ帯域を増やす必要がある。そのためにはFSBの広帯域化は避けがたいが、バス幅/速度ともに限界というのが現状ではなかろうか? これはPC向けのメニイコアプロセッサが登場するときには、当然同じ問題が再び出てくることになる。
根本的な解決はNiagara/XLR、あるいはK8コアのようにメモリコントローラをCPU側に取り込む必要があり、その上でチャネル数を増やすか高速化する(XDR DRAMがその最右翼だろう)必要性があるように見える。このあたりに制約があるPC向けプロセッサでメニイコアはその性能を確保できるのか? ということを考えさせられた発表であった。
□SPF2005のホームページ(英文)
http://www.instat.com/spf/05/
□関連記事
【5月18日】Spring Processor Forum 2005前日レポート
http://pc.watch.impress.co.jp/docs/2005/0518/spf01.htm
【2004年12月28日】【海外】マルチコア/メニイコア時代のCPUアーキテクチャ
http://pc.watch.impress.co.jp/docs/2004/1228/kaigai146.htm
【2003年6月20日】大原雄介のEmbedded Processor Forum 2003レポート
MIPSが、新32bitコアMIPS32 24Kを発表
http://pc.watch.impress.co.jp/docs/2003/0620/epf02.htm
(2005年5月31日)
[Reported by 大原雄介]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp お問い合わせに対して、個別にご回答はいたしません。
Copyright (c) 2005 Impress Corporation, an Impress Group company.All rights reserved.