 |


■後藤弘茂のWeekly海外ニュース■ベールを脱いだPlayStation 3の姿 |
●Cellの周波数を3.2GHzに抑える
ロサンゼルスで開催されているE3(Electronic Entertainment Expo)でのカンファレンスで、ソニー・コンピューターエンタテインメント(SCE)の次世代ゲームコンソール「PlayStation 3(PS3)」の概要が明らかになった。
まず、基本構成はCPUである「Cellプロセッサ」とメディアプロセッサである「NVIDIA RSX」、それにサウスブリッジチップの3チップ構成。Cellは3.2GHz、RSXは550MHz。CellとRSXのそれぞれに外付けメモリが256MBずつ接続されている、分離型のメモリ構成だ。メモリ帯域は合計で48GB/sec。CPUのプロセッシングパフォーマンスは、浮動小数点演算で218GFLOPSとなる。
 |
CPUでは消費電力と動作周波数とイールド(歩留まり)はトレードオフの関係にある。消費電力を下げようとすると、周波数か電圧を下げる必要がある。周波数を一定に止めて消費電力を抑えるためには電圧を下げるが、電圧を下げるとスピードイールド(クロックごとの歩留まり)が落ちる。ある電圧で3.2GHzで動作しているチップが、電圧を下げると2.8GHzでしか動作しなくなってしまうからだ。Cellはパフォーマンス/消費電力が高いものの、実際に消費する電力自体も大きい。そのため、熱設計はかなりやっかいなものとなる。
Cellはアプリケーション実行用のCPUコア「SPE(Synergistic Processor Element)」を8ユニットを搭載するが、PS3では7ユニットしか稼働させない。SCEによると、これは歩留まり向上のためだという。つまり、SPE部分にダイの不良があって、SPEが1個使えなくなったCellも、製品として使えるようにするためだ。
Cellが任意のSPEをディセーブルにできるとすると、8個のSPEが占めるダイエリアは、チップの歩留まりに影響しないエリアということになる。SPE部分はCellのダイの半分を占める。つまり、SPEを7個にしたことにより、Cellの歩留まりは、半分の約100平方mmクラスのダイサイズ(半導体本体の面積)のチップと同等になったことになる。ダイが1/2になると歩留まりは2倍以上になる。歩留まりは劇的に向上し、製造コストは大幅に下がる。
これは一般的な手法で、例えば、CPUのキャッシュSRAMでも使われることがある。SRAMに冗長性を持たせて、不良箇所がある場合には、そのブロックをディセーブルにして出荷するといった方法だ。
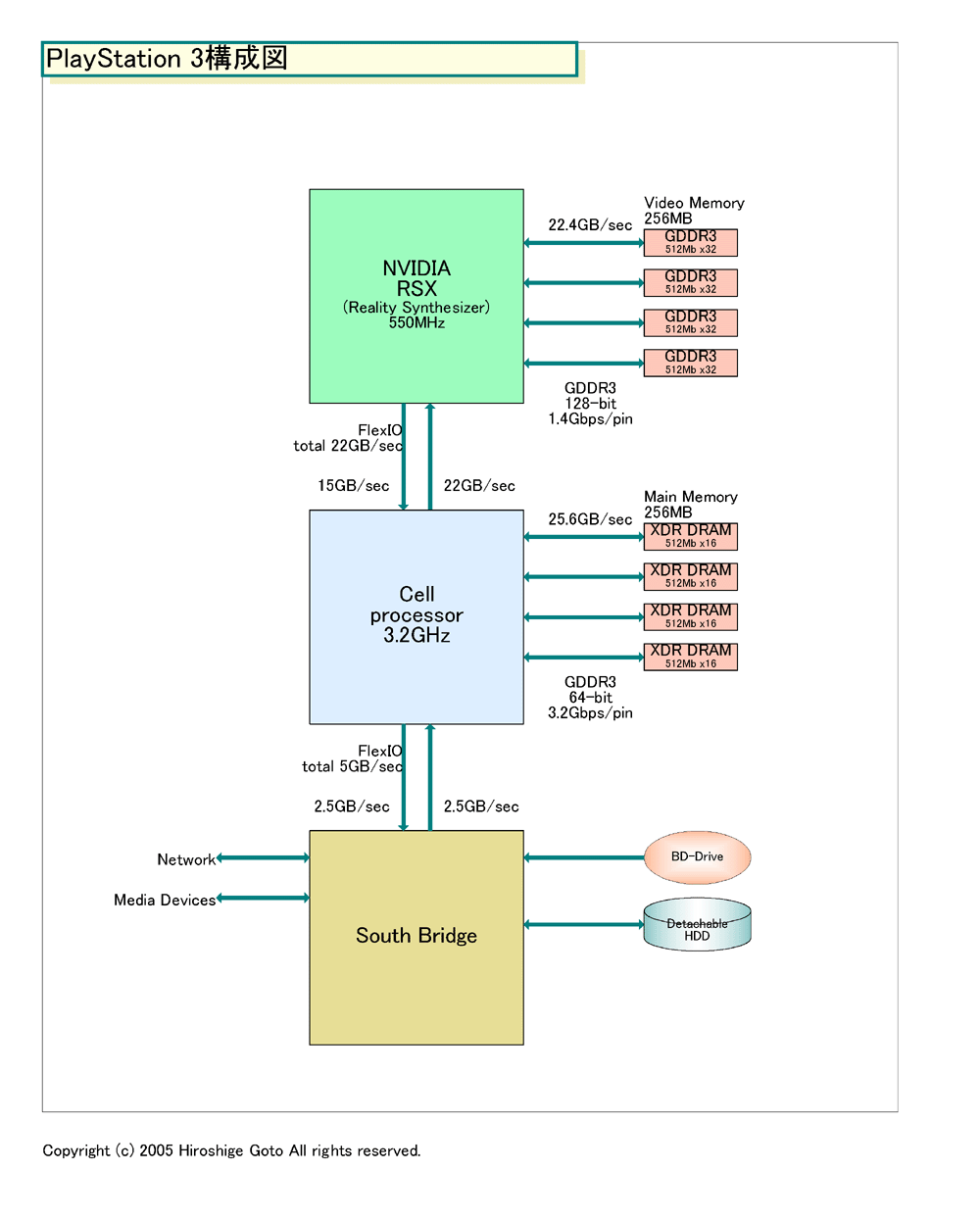 |
| PlayStation 3の構成 PDF版はこちら |
●CPU性能はXenonの2倍の218GFLOPS
浮動小数点演算性能は218GFLOPS。SPEが7ユニットで、各SPEが1個の4way SIMD(Single Instruction, Multiple Data)演算ユニットを備える。各ユニットが1サイクルスループットで積和算が可能なので、SPEの演算性能は4way×2oparations×7unitsで合計179.2GFLOPSとなる。
 |
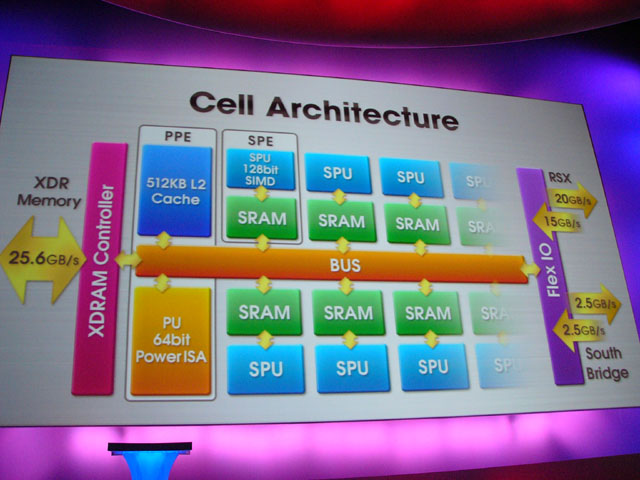 |
| 浮動小数点演算性能は218GFLOPS | Cellのアーキテクチャ |
一方、汎用CPUコアであるPPE(Power Processor Element)はベクタ演算のVMXと通常の浮動小数点演算のFPUの2つの浮動小数点ユニットを備える。PPEのブロックダイアグラムは以下の通りで、VMXとFPUへは同時に発行が可能となっている。つまり、PPEではピークでVMXによる4wayの単精度SIMD演算と、FPUによるスカラの倍精度演算が並列に可能ということになる。ただし、これだと計算上211GFLOPSとなり、カンファレンスで示された218GFLOPSのスペックに足りない。計算上は、FPU部分が2wayでないと合わないので、PPEのFPUが拡張されている可能性もある。
SIMDとFPUを合わせた演算性能では、同クロック時にCellがXenonの2倍のピーク性能ということになる。性能差は大きいが、それでも、理論上の予測より、CellとXenonの性能差は縮まっている。これは、CellがSPEを1個ディセーブルにしていることと周波数を落としていること、XenonがFPUを強化していると見られることなどのためだ。
ちなみに、カンファレンスでは参照値としてスパコンの性能も示された。ただし、こちらは倍精度演算性能で、Cellは単精度演算性能という違いがある。Cellの場合は倍精度になると、4GHz時に26GFLOPSと大幅に性能が落ちる。
 |
| PPEの仕組み PDF版はこちら |
●アーキテクチャはいたって普通のNVIDIA RSX
PS3のGPUであるNVIDIAのRSXは、現在わかっているスペックでは驚くほど普通のGPUだ。想定されたようなeDRAMもなく、外付けしているメモリもGDDR3となっている。これでホストバスがFlexIO(Redwood:レッドウッド)でなければ、PC向けとしてそのまま使えそうだ。また、マイクロアーキテクチャも、ATIのXenon GPUのようなUnified-Shader型のラディカルなアーキテクチャは取っていない。
動作周波数は550MHz。あまり上昇していないように思えるかもしれないが、GPUの場合もCPUと同様に、ゲームコンソールでは、スピードイールドでの歩留まりをぎりぎりまで上げる必要がある。そのため、550MHzはトップビン(最上級)の周波数ではなく、低クロック品の周波数で、実際にはチップとしてはもっと高速で動作できるものを含んでいる。それを考えると、90nm世代のGPUとしてはごく普通の周波数だ。
RSXはインディペンデントVertex/Pixel Shader型アーキテクチャを取るという。Vertex ShaderとPixel Shaderに物理的に分かれた現行型のアーキテクチャを取るようだ。それに対して、ATIのXenon GPUは、このコーナーで解説してきたWGF2.0世代GPUのような、物理的に統合化されたUnified-Shaderアーキテクチャを取る。
このことは、NVIDIAの次期GPUアーキテクチャも、同様に物理的に2種類に分かれたShaderになっている可能性があることを示唆している。両社の設計思想が分かれた理由は、今のところ不明だ。ただし、ATIは以前からUnified-Shaderを積極推進する姿勢を明らかにしており、NVIDIAは逆に物理的にShaderを統合することの効率性については、実装コストの面から疑問符をつけていた。そのあたりと関係しているかもしれない。
Shaderの物理的な構成はわからない。現在明らかにされているのは次のスペックだ。
| 136 Shader Operations/cycle |
| 100 G Shader Operations/sec |
| 51 G Dot Products/sec |
| 1.8 TFLOPS(システム全体の演算性能) |
| 3億トランジスタ |
単純に4wayのSIMDと考えれば4で割って34個のShaderということになるが、まだ明確ではない。この手のスペックには、標準的な書き方がなく、現状ではかなり混乱がある。実際、Xenonのケースでは、前回のレポートで、Microsoftの出したXenonのShaderオペレーション性能の数字から逆算したXenon GPUのShader個数は間違っていた。
●RSXのトランジスタ数はNV40の1.5倍
ただし、トランジスタ数からは、ある程度規模が類推できる。現在のハイエンドGPUはNVIDIAのGeForce 6800(NV40)で2億2,000万トランジスタ。このトランジスタ数で、Shader構成はVertex Shaderが6、Pixel Shaderが16の合計22個。とすれば、その1.5倍の規模のRSXのShader個数も、大体予想がつく。また、NV40が0.13μmで約300平方mmのダイ(半導体本体)だったことを考えると、90nmで3億トランジスタのGPUは約200平方mmのダイということになる。だとしたら、ほぼCellと同クラスのダイサイズだ。
ちなみに、Xenon GPUのShader個数は48で、それぞれのShaderが1基の4way ベクタFPUと1基のスカラFPUを備えShader性能は500MHz時に216GFLOPSとなる。おそらく、Xenon GPUの方がShaderパフォーマンスは上になると推定される。
RSXの演算性能は、SCEのスペック表では1.8 TFLOPSとなっている。しかし、Shader性能だけでなく、固定機能ユニットの演算性能も含んでいると見られる。固定ユニットは、個々のロジック毎に用意された単機能の演算ユニットの集合なので、必然的に演算性能として単純にカウントすると膨大な数になる。しかし、プログラマブルな演算性能と同列に扱うことはできないため、それほど意味は持たない。これは、単純に、同様の数え方で1TFLOPSを打ち出してきたMicrosoftに対抗するための数字に過ぎないだろう。
最大2K×1KのHD解像度で2画面出力という仕様は、ホームサーバー用途も意識している可能性もある。ホームサーバーに2台のTVを接続、1台のTVでゲームをしている最中に、別なTVでビデオを観るといった使い方だ。Cellは、バーチャルマシン支援機能を備えているため、バーチャルマシンで複数OSを効率的に使用できる。もし、RSXがそれに対応したバーチャライゼーション機能を備えているなら、内部リソースと出力を仮想的に2つのバーチャルマシンに割り当てるといった対応が可能になる。
 |
 |
| トランジスタ数は3億 | 2ポートのHDMIを搭載し、2画面同時表示が可能 |
●意外なPS3のメモリ構成
SCEのメモリアーキテクチャは毎回驚かされるが、今回もまた意外だった。PS3のメモリのポイントは、(1)CPUとGPUがそれぞれ外付けメモリを持つ点、(2)両メモリのアーキテクチャが異なる点、(3)eDRAMを使わなかった点。
RSXに外付けされているメモリはGDDR3で、メインメモリに採用したXDR DRAMとは異なる。メモリ帯域は22.4GB/sec。GDDR3はベースクロック700MHzのDDR駆動で、転送レートは1.4Gbits/sec。逆算するとメモリインターフェイス幅は128bitということになる。メモリ量は256MB。そのため、DRAMチップはx32 512Mbit品が4個の構成だと推定される。
RSXのメモリがXDR DRAMではなく、GDDR3だった理由は、まだ明確ではない。NVIDIAが慣れていて性能を出しやすいメモリアーキテクチャを選んだのか、XDR DRAMに不安材料があると考えたのか。NVIDIAは以前、PC向けGPUに新メモリ技術を採用しないのは、DDR系の方が技術の蓄積があって性能を引き出しやすいからだと説明していた。
ゲームコンソールにユニファイドメモリが多いのは、その方がメインメモリ→ビデオメモリのデータ転送のロスがないため効率的だからだ。だが、PS3ではユニファイド型ではなくインディペンデント型のメモリアーキテクチャを採った。そのため、Cell側からはビデオメモリに直接アクセスができず、Cellをグラフィックス用途に多用することはないと見られる。
もっとも、GPUであるRSX側からはCellのメインメモリも、GARTのような仕組みで共有できる可能性もある。NVIDIAのプレゼンテーションに512MBのレンダーメモリとあるからだ。ビデオメモリは256MBなので、最大512MBをレンダーするにはCell側に接続された256MBのメモリにもアクセスできなければならない。もっとも、Cellの場合、XDR DRAMインターフェイスとFlexIOインターフェイスはチップの両端にあるため、構造上、外部デバイスがメモリにアクセスすると内部のリングバスのレイテンシが一番大きい。
RSXがeDRAMを使わなかった理由だけは明瞭だ。最大2K×1KのHD解像度で2画面を出すとなったら、eDRAMにフレームバッファを取るという選択肢はありえない。ダブルバッファも考えると、途方もないeDRAM容量が必要になってしまうからだ。RSXを製造するソニー/東芝系のFabの売り物はeDRAMだが、その特色は今回は活かされない。
eDRAMではなく外付けGDDR3にしたことによる問題点はメモリ帯域だ。eDRAMなら数百GB/secの帯域が確保できるところが、GDDR3 128bit幅で22.4GB/secと次世代ミッドレンジGPUクラスのメモリ帯域となっている。ただし、システム全体で見るとメモリ帯域は48GB/secとなる。
PS3のメモリアーキテクチャのもうひとつの問題点はコストだ。DRAMチップは合計8個と、PS2からは一気に4倍に増えた。しかも、インターフェイス幅に対する粒度があるため、将来メモリ個数を減らすことも難しい。簡単に言えば、PS3はPS2よりも、メモリだけを見てもかなり高コストだ。それに対して、同じ8個のDRAMを搭載するXenonは、将来的には4個にDRAMチップ数を減らすことができる。PS2対XboxではXboxの方がメモリコストと帯域は不利だったが、PS3対Xenonでは逆になる。
I/Oチップについては、今回は詳細は明らかにされていない。しかし、PS2との互換を取ることから、I/OプロセッサにPS2のメインチップセットを利用する可能性はあると思われる。オーディオは、Cellによるソフトウェアベースに移行する。これは、Microsoftも同様で、Xenonも一部の処理以外はソフトウェアで実現する。余ったプロセッシングパワーを有効使って、非プログラマブルな機能を削減して、機能に柔軟性を持たせるという方向はトレンドだ。
□関連記事
【5月17日】SCEI、「プレイステーション 3」を発表(GAME)
http://www.watch.impress.co.jp/game/docs/20050517/sce.htm
【5月12日】【海外】次世代ゲーム機ウィークにいよいよ突入
http://pc.watch.impress.co.jp/docs/2005/0512/kaigai177.htm
(2005年5月18日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2005 Impress Corporation, an Impress Group company. All rights reserved.