 |


■後藤弘茂のWeekly海外ニュース■コンテンツ保護機能を備えたCellのCPUコア |
●Local Store
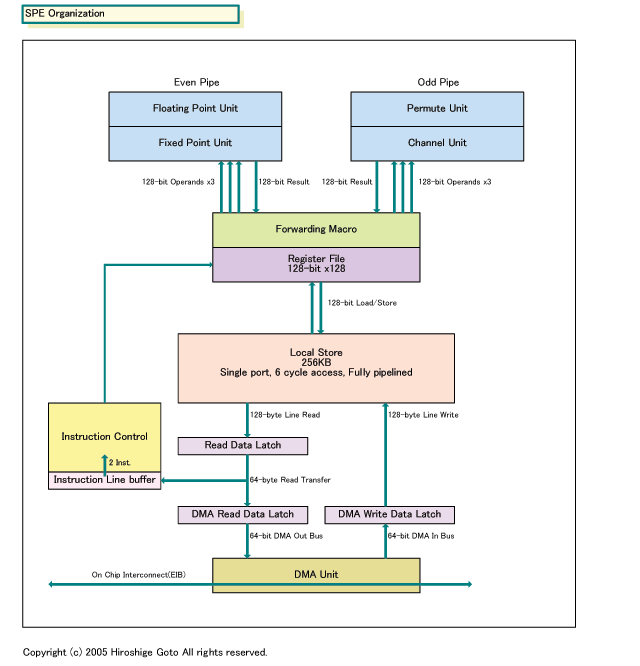
Cellプロセッサは、9個のCPUコアを搭載したマルチコアCPUだ。なかでも重要なのは、演算処理を担当する8個の「SPE(Synergistic Processor Element)」と呼ばれるプロセッサ群だ。SPEは、1命令で複数データに対する処理を行なうことができる「SIMD(Single Instruction, Multiple Data)」型のプロセッサで、ストリーム型の処理で強力な性能を発揮する。
各SPEにはLocal Storeと呼ばれる256KBのメモリがある。これはL2キャッシュではなく、いわゆるスクラッチパッド的に、プログラマ側が明示的に自由に使うことができるメモリだ。Local Storeのメモリ空間は、SPE占有のローカルメモリ空間となっている。SPEのロード/ストア命令は、このローカルアドレススペースの中で実行され、SPEが、システムメモリにアクセスする場合にはDMAを経由する。
SPEでのプログラム実行は、DMAでLocal Storeにデータ&プログラムを転送して行なう形となる。元々、Cellの基本的な考え方は、プログラムをソフトウェアCellと呼ばれる、プログラムピースとデータを格納したオブジェクト形状にして扱う。そのため、256KBに収まる程度のプログラムが始めから想定されていると見られる。
Local Storeでは、キャッシュと異なりコヒーレントを取らない。そのため、Cellではチップ全体に渡って、キャッシュコヒーレンシを常に保つ必要がない。これも、マルチコアのオーバーヘッドを減らす重要な要素だ。
Cellでは、各要素はElement Interconnect Bus(EIB)と呼ばれる広帯域のリング型バスで接続されている。SPEはDMA転送でEIBを経由して、システムメモリなどにアクセスする。DMAリクエストは、最大で16トランスファをオンザフライで発行することができる。
 |
| SPE 構成図 PDF版はこちら |
●コンテンツを保護する特殊モードを装備
SPEは、特殊なセキュリティ機能として「isolated mode」と呼ぶモードを備えている。
「SPEは、基本的に保護メカニズムを備えている。これはisolated modeと呼ぶもので、SPEがこのモードに入ると、Local Storeメモリは完全にロックされる。Cell上の他の要素も含め、SPE外部からの全てのアクセスから守られる。OSでさえ、LSの中のコンテンツを見ることはできない。
もちろん、これは非常に危険で、例えば、このモードで保護されているSPEで走るプログラムにバグがありストップしてしまう場合も考えられる。ただし、その場合も、PPE(Power Processor Element)がリセット信号を送ると、SPEはメモリ内容を完全にクリーンアップして、それから死ぬ。トリッキーに見えるかもしれないが、コンテンツの確実な保護は、コンテンツプロバイダに素晴らしいコンテンツを提供してもらうために非常に重要だと考えている」とSCEIの鈴置雅一氏(Vice President of Microprocessor Development Department, SCEI)は言う。
isolated modeで保護されたSPEには、認証されたプログラムしかアクセスできない。そのため、コンテンツ再生などの場合には、物理的に隔離されたメモリ空間でコンテンツが保護されることになる。つまり、Cellはコンテンツを高度に保護できる仕組みを、ハードウェア的に備えているわけだ。
これは、ソフトウェアベースのコンテンツ保護しかまだ備えていない現在のPCとは大きく異なる。また、Cellの場合は、独立したCPUコアとメモリを備えるSPEを完全に保護してしまう。今後のPC向けCPUも、CPU内にハードウェアで仮想的にパーティションを作る保護機能を備えるようになるが、Cellの保護はさらに強力だ。これは、コンテンツ保護が重要なエンターテイメント機器への搭載を考えた場合には、重要な機能だろう。
●SPEのパイプラインと高クロックの秘密
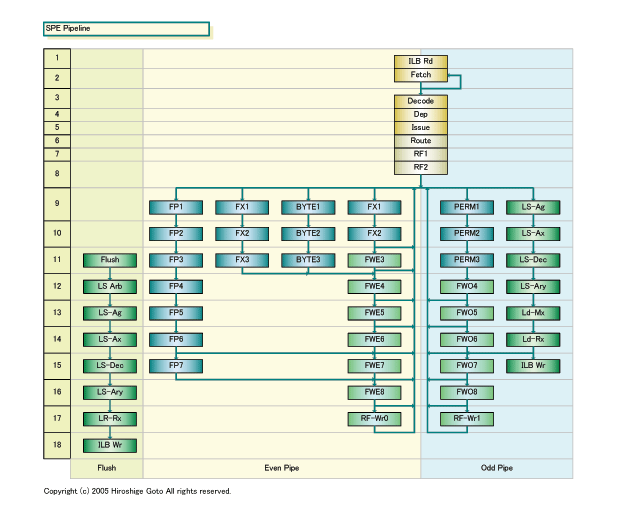
SPEのパイプラインは比較的深いものの、異常なほどではない。特に、インオーダ発行で複雑な命令スケジューリングをハードウェアで行なわないため、パイプラインの前半は非常にシンプルだ。命令デコードも基本的に1ステージで、間に詳細がわからないステージが入るが命令発行までで5ステージ。レジスタファイルアクセスに2ステージ取るのはレジスタファイルが128本と大きいためだと推測される。
ちなみに、SPEは、分岐関係のコントロール機能も省いている。例えば、分岐履歴を保存するハードウェア機構は持たない。分岐ミス時のペナルティは18サイクルと比較的大きいため、ソフトウェア上の技法によって分岐ペナルティを軽減するという。
例えば、分岐する2つのパスを両方とも実行しておき、分岐が成立した時点でselect命令でパスを選択する。branch hint命令を挿入することで静的に分岐予測を行なう。分岐が成立した場合のロードターゲットを分岐ターゲットバッファにロードしておく。といった技法だ。これらは、コンパイラレベルでサポートされるものと見られる。
パイプラインのエグゼキューション部分では最短のSimple Fixed命令系が2ステージ。単精度浮動小数点演算で6ステージ、ロードストアが6ステージとなっている。最も長いのは整数SIMDの積算の7ステージだ。もしかすると、SPEは浮動小数点SIMDユニットしか備えておらず、その演算器で整数演算も行なっているためレイテンシが長いのかもしれない。
全体的に言えるのはSPEのパイプはショートデコード型で、元々のRISC系プロセッサのパイプラインを思わせる。X86系CPUのようなロングデコード&スケジューリングのパイプラインではない。PowerPC 970も、パイプラインの前半が比較的長く、SPEとは大きく異なっている。
ISSCCでは、SPEは高周波数を重視しているにもかかわらず、パイプラインの深さは、パイプラインのステージ遅延が20 F04のプロセッサと同程度だと説明された。しかし、Cellは、“11 FO4”と、パイプラインのステージ遅延が極めて短い。また、通常の高速CPUは、遅延の短縮のために高速だがリーク(漏れ)電流の多いLow-Vtトランジスタをクリティカルパスに使う。しかし、Cellはリーク電流を抑えるために、Low-Vtトランジスタも一切使わなかったという。
ISSCCでは、SPEの11 FO4への遅延短縮は、回路設計と効率的なレイアウト、ロジックの簡素化で実現したとISSCCでは説明された。例として挙げられたのは、高速なダイナミック回路(Dynamic circuit)の要所への採用、ラッチオプションの多用、高密度レイアウトや注意深いフロアプラニングや配線による配線遅延の短縮など。
つまり、パイプラインの細分化や高速なトランジスタを使うのではなく、Cellでは設計技術によって高速化を図ったことになる。同じ90nmプロセッサでも、パイプラインをより細分化し、Low-Vtトランジスタを使う、Intelの90nm版Pentium 4(Prescott:プレスコット)とは正反対のアプローチに見える。その結果、Cellでは、4GHz以上という高速動作が可能になった。
 |
| SPEパイプライン構成図 PDF版はこちら |
●シンプルなプロセッサアーキテクチャが高クロック設計を容易に
Cellの場合は、プロセッサの構造のシンプル化も高クロック化に寄与している。制御系のタスクを担当するPPE(Power Processor Element)とSPEのどちらのプロセッサも、比較的シンプルな構造になっている。この点について、以前の記事の説明が足りなかったので、補足しておきたい。
あるCell関係者によると、例えば、レジスタリネーミングを行なっていると、パイプラインを細分化するにつれて物理レジスタ数を増やさないと性能が上がりにくくなるという。そのため、高速化につれて、レジスタファイルやリネーミング機構などの回路規模が次第に増える。他にもさまざまなコントロールメカニズムによって、これまでの先端CPUは、コントロール機構の規模が大きくなりCPUの複雑性がどんどん増す傾向にあった。
問題は、ある程度以上にCPUの複雑性が増すと、CPU設計の段階で高速化が難しくなることだという。例えば、あるクリティカルパスをつぶすと、別な箇所に問題が発生するといった、いたちごっこ状態にしばしばなると言う。その結果、高速CPUでは設計に膨大な労力が必要となり、周波数の向上が難しくなる。つまり、モダンCPUは複雑になりすぎた結果、単純にパイプラインを細分化すればクロックが上がるという公式が、単純には通用しなくなりつつあるという。
こうした問題は、IntelでPentium III/4などのアーキテクトを務めたBob Colwell(ボブ・コールウエル)氏が、2004年2月、米スタンフォード大学で行なった講演
「Things CPU Architects Need To Think About」でも指摘されている。同氏は、IA-32のパフォーマンス向上を、「ゾウを急坂に押し上げるようなもの」と形容。無理な高速化により、アーキテクチャ上の脆弱性が増していると説明している。
例えば、現在のCPU設計では、正確なパフォーマンス分析ができる段階になって(性能上の)問題が発見されても、設計が進みすぎていて本質的な修正ができない。そのため、ボロ隠しのような小手先の修正を加えることになり、複雑さの上に複雑さを重ねることになり、別な問題を招いてしまうという。これは、実際にIA-32 CPUを設計していたアーキテクトの言葉だけに、重みがある。
肥大化した現在の先端CPUは、このように苦しみながら周波数を上げている状態にあるようだ。しかし、シンプルな構造のプロセッサなら、そうした問題は発生しにくい。比較的容易に問題をフィックスして、周波数の向上を図ることができる。そのため、シンプルなプロセッサコアを複数組み合わせた方が、高速化の面では有利になるという。
Cellの場合、PPEとSPEともに、これまでのCPUと比べると極めてシンプルな構造になっている。こうした構造のシンプル化は、泥沼のような設計地獄を避けることができるため、高速化を図りやすい。それに対して、Pentium 4に代表される複雑なCPUは、いくら回路遅延を短くしても、CPUの設計段階で高速化が難しくなりつつある。少なくとも、高速化に膨大な労力が必要となっている。
ちなみに、CellのCPUコアのシンプルさは、コアの規模でよくわかる。Cellチップ上で1個のSPEが占めるサイズは2.5mm×5.8mm、面積は14.5平方mm。本当にツメの先程度のサイズだ。トランジスタ数は2,100万トランジスタだが、このうち1,400万がSRAMで、ロジック回路は700万トランジスタに過ぎない。トランジスタ数で見ると、世代的にはPentium IIIクラスの規模ということになる。規模的には、CellはPentium IIIクラスの規模のCPUコアを8個搭載していると考えればわかりやすい。
□「Things CPU Architects Need To Think About」
http://ee380.stanford.edu
□関連記事
【2月12日】【海外】Cellのパワーの源「SPE」の正体
http://pc.watch.impress.co.jp/docs/2005/0212/kaigai156.htm
【2月11日】【海外】PCを遙かに超える、Cellのメモリ/IO帯域
http://pc.watch.impress.co.jp/docs/2005/0211/kaigai155.htm
【2月9日】【海外】PlayStation 3に搭載されるCellの性能
http://pc.watch.impress.co.jp/docs/2005/0209/kaigai154.htm
(2005年2月12日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] 個別にご回答することはいたしかねます。
Copyright ©2005 Impress Corporation, an Impress Group company. All rights reserved.