 |
■大原雄介のEmbedded Processor Forum 2004レポート■ちょっと変わった参加者たち |
●Freescale:ColdFire V4e
失礼だが、「まだやるのか!」というのが筆者の正直な感想だった。
 |
| 発表を行なったEd Nuckolls氏(Design Manager on mid-range SoC Products and fellow on technical staff for Motorola's 32bit embedded controller division in transportation & standard products group) |
ちょっと説明しておくと、ColdFireはMotorolaのリリースするRISCのCPUコアである。で、MotorolaはColdFire以外にも実に多くの種類のプロセッサを手がけている。
とりあえずディスコンになっていない分に限っていっても、MC68000/20/30/40という、いわゆる68KのCISCコアがある。更に、68000をベースとしたSoCとしてDragonBallというシリーズがあり、DragonBall EZ/VZ/SZという発展型がPalmで使われていたのでご存知の方も多いだろう。
加えて、やはり68000をベースに通信関係の回路を集積したSoCにQUICC(Quad Integrated Communication Controller)というシリーズがある。加えて言えば、PowerPC系の開発も行なっており、G4プロセッサことMC7400シリーズは未だに利用されている。
で、その後DragonBallはCPUコアをARM9コアに置き換えたDragonBall MXに、QUICCはPowerPCコアを利用したPowerQUICCシリーズにそれぞれ発展している。
ではColdFireは何かというと、68Kの命令のサブセット(良く利用される命令だけをカバー)を利用できるRISCエンジンである。最初のColdFireは最終的に製品化されず、ColdFire V2から始まってパイプライン構造を拡張したColdFire V3、限定的なスーパースケーラを搭載したColdFire V4までがリリースされ、さらにColdFire V5では完全なスーパースケーラが、ColdFire V6ではスーパーパイプラインが導入されることが発表されている。
ところがColdFire V5は発表こそされたものの製品はまだで、またColdFire V4はディスクリート製品はリリースごくわずかで、もっぱらASIC用のIPコア部品として提供されているのが現状である。結局ColdFire系列の製品はほとんどがColdFire V2ベースといった状態である。
実のところ、DragonBall SZの後継としてColdFireコアが利用されるという観測が一部にはあった。ソフトウェアの互換性を考えれば自然な流れであるからだ。にもかかわらず最終的にPalmとMotorolaはARM9コアに移行することを決定してしまい、この時点で68Kの(最後の)大きなマーケットが無くなることが事実上決まってしまった。一時期はEmbedded用途に大きなシェアを持っていた68Kであるが、もう現状では「過去の資産を生かせる」という程に有用な過去の資産は無い(ほとんどの資産はPowerPC系に移行してしまった)状況で、従ってColdFireも縮小傾向にあると見られていた。
こうした状況を前提にすると、Freescale(Motorolaの半導体部門がスピンアウトした子会社)が、新たなColdFireコアをリリースするというのは、かなり驚くべき事といわざるを得ない。
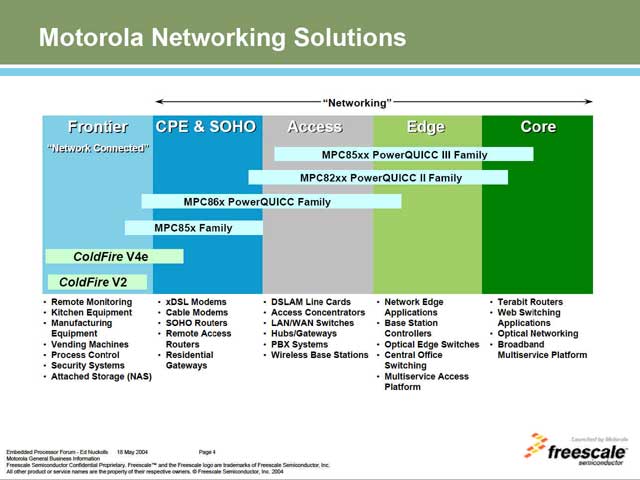
その新しいコアは、ColdFire V4にセキュリティ機能を拡張した形のものである。図2はネットワーク関連製品のロードマップだが、基本的にはレジデンシャルゲートウェイからコアルーターまでの領域は、PowerPC+ネットワーク系周辺機器のSoCであるPowerQUICCファミリーで完全にカバーする形になる。
ではColdFireはというと、“Frontier”、つまり現状確たるマーケットが無い/Motorolaがそれほどのシェアを握っていないマーケット向けの製品という、非常に微妙な扱いとなっている。
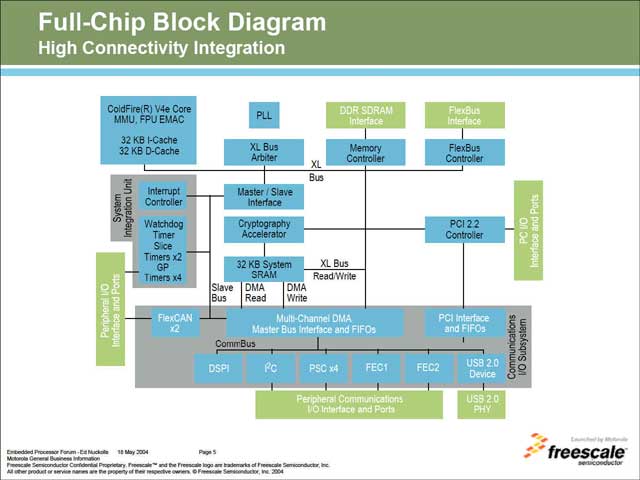
図3はこのColdFire V4eを利用したSoCチップの概略を示したものだが、既存のColdFire V4との最大の違いは、中央にあるCryptogyraphy Acceleratorである。この暗号化アクセラレーラにより、通信の暗号化が求められる用途向けに低価格・高スループットのソリューションを提供しようというものだ。
CPUコア自体は、既存のColdFire V4と大きな違いはない。この結果、性能という意味では266MHzで410MIPSなので、ARM V9とかよりは効率が良いが、動作クロックが266MHzと低めなので、ピーク性能はたいしたことはない。ただ、コア自体は0.13μmプロセスで3.3平方mmと極めて小さいため、SoC用のコアとしては最適である。
 |
 |
 |
| 【図2】MPC85xもPowerQUICCに属する(MPC86xの低コスト版がMPC85x) | 【図3】これはあくまで最終的な製品構成である | 【図4】ColdFire v4は、一部の命令のみ2命令同時発行が可能だが、基本的には1命令の処理のみとなる"Limited SuperScalar"構成。完全スーパースカラとなるのはColdFire V5以降である |
発表はこの後、いかに暗号化/復号化が高速に行なえるかについて詳細な結果が示されたが、ここではその話は割愛する。
このColdFire V4eをどう扱うか、に関してだが一例として示されたのは、例えばクロスバースイッチ経由で通信インターフェースと接続するとか、AHB/APBと接続するといった形で、通信用途に積極的に利用することを前提にしているようだ。講演の中では、実際に製造したダイの写真も公開され、既に実用の域に達している事をアピールしていた。
問題はこの扱いである。266MHz動作でも410MIPS程度の性能だから、ルーター向けとするにはそれほど高いルーティング性能を持たせるのは難しいし、既存のPowerQUICCとマーケットがぶつかるから得策ではない。結果としてまさしく“Frontier”に切り込まなければならないわけだが、ここでの武器は唯一価格のみである。
先にも書いたとおり、もう68Kの資産はほとんどない(ましてやFrontierの分野では更に)わけで、その割に17~27ドルというのはそれほど劇的に安いというわけではない。
例えば最近の日本の自動販売機の場合、Windows CEあたりを使ってシステムを作る事が相対的に多くなってきたが、こうしたOSのサポートが無いColdFireで、新たにマーケットを作ってゆくのは大変に難しいように思える。このあたりの明快な説明は今回は無いままで、むしろColdFireを延命させるために、むりやりマーケットを当てはめたという感じがしなくもないほどだ。あらためて「Motorola(というかfreescale)はいつまでColdFireを維持するのか、疑問が深まる結果となった。
 |
 |
 |
| 【図5】V4eといっても、このあたりはほとんどV4と変わりが無い。暗号化に関する部分は全てCryptogyraphy Acceleratorに任せている感じだ | 【図6】図3ではXLBusをベースとした構成を示していたが、もっと転送速度を必要とするならばこういった構成もある、という例である | 【図7】現時点で製品化されているのはMCF5470とMCF547、MCF5472、MCF5473、MCF5474、MCF5475、MCF5480、MCF5481、MCF5482、MCF5483、MCF5484、MCF5485の12製品。ただ主な違いは、動作クロック(166/200/266MHz)、暗号化アクセラレータの有無、Ethernet/USBコントローラ/CANコントローラの有無といった程度の違いでしかない |
●UD3000 : 力技ビデオプロセッサその1
昨年の記事で、「MPF/EPFの『暗黙のルール』(初日午前はまともなもの。2日目午前もまぁまともなもの。初日午後はやや変なもの。2日目午後はすごく変なもの)」という話をしたが、今年はその「すごく変なもの」が2日目の午前中に来た。今回のEPFは5部構成になっており、
1日目午前:High-Performance Embedded Processing
1日目午後(前半):Software Tools for Embedded Systems
1日目午後(後半):Embedded Signal Processing
2日目午前:Processors for Video Applications
2日目午後:Low-Power Embedded
といった具合になったわけだが、このProcessors for Video Applicationsに変なものが集中した感じだ。
そもそもこのProcessors for Video Applicationsは何かというと、MPEG-4やH.264を如何にハンドリングするかというところから話が始まっている。
そもそもMPEG系のデコードは割とCPU負荷が高い傾向にあるのだが、特にH.264では画質を保ちながらデータ量を最小化するために、MPEGをベースに考えられる限りの予測機能や補完機能を突っ込んだ結果、同じ条件でのMPEG-2に比べてデコードで数倍、エンコードでは1桁以上処理の負荷が重いものになっている。
また、画像もVGAサイズ程度ならたいしたデータ量ではないが、HDTVクラスになると馬鹿にならないサイズとなり、このハンドリングも状況を難しくしている。汎用のプロセッサでもやってやれない事はないのだが、Embedded向けとしては消費電力や発熱量、性能の点から見てこれは賢明な案とは言えない。
そういうわけで、昨年くらいからこうしたVideo Processingに特化した専用プロセッサの話がぼちぼち出始めている。今回“Processors for Video Applications”では3つの専用プロセッサが登場したが、いずれもこうしたビデオのエンコード/デコードに特化したものである。
 |
| Ultra data Corpの創立者の1人にしてPrincipal Design EngineerのJonah Probell氏 |
さて、まずご紹介するUD3000はUltra data CorporationがリリースするHDTVのデコードをターゲットとしたビデオプロセッサだ。同社は2003年に設立されたベンチャーで、このUD3000が最初の製品となる。
さて、UD3000のキーターゲットは、HDTVレベルまでのビデオデコーディングである。このレベルなら、例えば全ての処理をDSP+ハードワイヤードロジックで処理することも不可能ではないが、ファイルフォーマットが多様な現状ではこうしたハードワイヤードロジックはむしろ不利であり、プログラマブルプロセッサの形で処理を行なったほうが有利という判断がある。
これを実現するために、UD3000ではマルチプロセッサのスキームを使いながら、ILP(Inner Loop Processor)とOLP(Outer Loop Processor)の2種類のプロセッサを内蔵し、ILPではゴリゴリとデコード処理を行ない、OLPはプロトコルの解釈やILPの制御を行なうという仕組みを提供した。
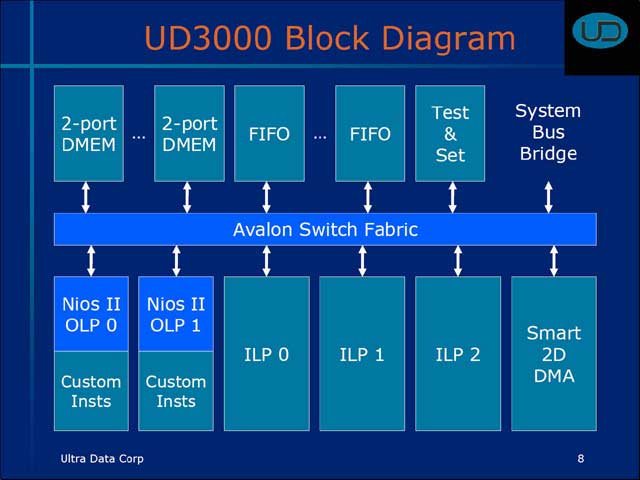
実際の構造はというと、図10の様な仕組み。OLPにはAlteraのNios IIを利用し、ILPは3個あり、これに複数のFIFOとデュアルポートのデータメモリを装備する形だ。InterconnectとしてはやはりAlteraのAvalon Switch Fabricを利用している。
さて肝心なのはILPの構造であるが、32bitのCU(Control Unit)64bitのVUが並行に動く、全体を通して言えばMIMD(Multi-Instruction, Multi-Data)の構成。命令はどちらも32bit長に統一されているが、両方の命令を並行して投入するというあまり類の無い構造になっている。
 |
 |
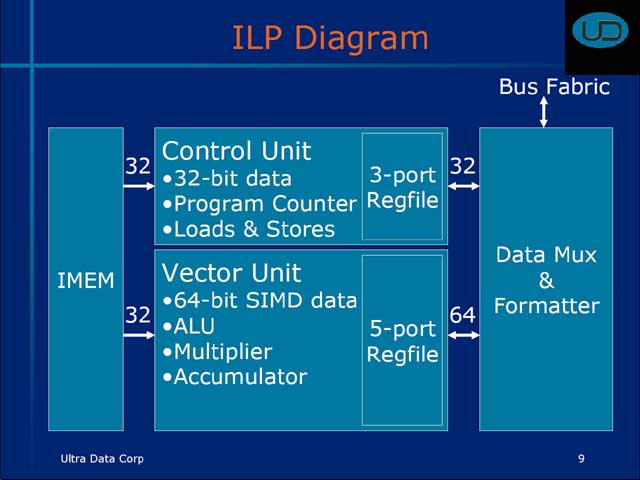 |
| 【図9】特にILPでは、演算の中心となるのは64bitのVU(Vector Unit)である。2D DMA controllerなどについては後述 | 【図10】Nios IIは、やはり今回のEPFでAlteraが発表したばかりの、FPGA上で実現できるCPU。構成(Fast/Standard/Economy)に応じてパイプライン無し/5ステージ/6ステージ、分岐予測有り/無し、キャッシュ有り/無しを選べる。性能は、Fastの構成で180MHz動作、200 MIPS(Dhrystone 2.1)に達する | 【図11】VUは64bitといってもSIMDなので、データサイズは8/16/32bitの模様。もっとも、ビデオのデコードに限って言えば、ほとんどの場合8/16bitで済む。32bitが必要なのは、よほど画質を高めたい場合に限られるだろう |
 |
 |
| 【図12】ILPへの命令のサンプル。今回プログラミング環境の話は出なかったのだが、これをアセンブラレベルで構築するのは結構大変そうな予感がする。賢いコンパイラがあるといいのだが | 【図13】Nios IIやAvalonを使うことで判るとおり、UD3000はAlteraのFPGA用のIPコアとして提供される。従って、複雑な機構を省くことで、FPGA自体を高速動作させることが可能になり、結果として処理性能が上がるというわけだ |
さて、面白いのはこのILPの性能向上の方式。FPUやMMUが無いのはまぁ理解できる(汎用プロセッサではないのだから)が、キャッシュも無いからTagの比較が要らないとか、分岐/ロードのディレイを2クロックに収めているので、分岐予測も要らなければキャッシュも要らない、というのはさすがにこの手のプロセッサらしい割り切りである。
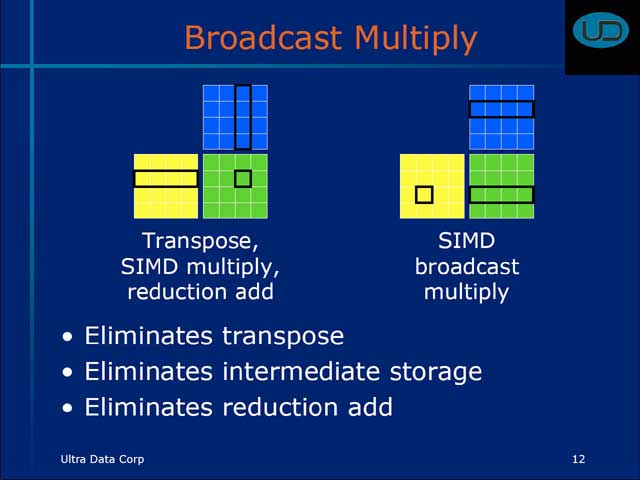
ただ分岐予測はともかく、キャッシュまで省くとメモリアクセスのレイテンシがちょっと気になるところだが、そこで威力を発揮するのが2D DMAなるもの。
例えばIDCT/IQuantizeといった処理では、ブロック/マクロブロック単位で縦横にデータを舐めながら演算を行なうわけだが、従来だとメモリはColumn方向のみのシーケンシャルアクセスだからRow方向のアクセスは非常に遅く、これを補うためにブロック/マクロブロック全体をまずキャッシュに格納して、ついでランダムアクセスをしていた訳だ。ところが2D DMAではRow/Columnを別々にアクセスできるので、キャッシュが無くてもレイテンシが最小限に抑えられるというわけだ。
ちなみに、UD3000を使ってブロック単位のデコードを行なう際の動作シーケンスを示したのが図16である。OLP0→ILP0→ILP1→OLP1→ILP2という形で、各々の処理を完全に分割する形で並行して動作させることで、スムーズに処理が出来るという仕組みである。
性能として今回示されたのは、0.13μmプロセスで400MHz動作を補償し、この時点でH.264 Main Profile Level 4.1(最大2,048×1,024@30fps、720×480の525 SDなら172fps!)のデコードを可能にするというから、大抵のデジタル家電で十分利用できる範囲の性能である。
全体的に力技というか、特にILPに関する割り切り方が強烈な構成であるし、これの開発をさせられるソフトウェアエンジニアは苦悶しそう(ソフトウェアの作り方いかんで強烈に性能が変わりそうだから)ではあるが、傍から見ている分には非常に面白いプロセッサであった。
 |
 |
 |
| 【図14】ただ、同一メモリブロックをRow/Columnで同時にアクセスというわけには行かないようで、それがデータメモリエリアを複数持つ理由になっている。この方式の場合、データメモリエリアを効率的に使うためには、データの持ち方を相当考えねばならず、これが更にプログラミングの難易度を高めている気がする | 【図15】一応最後に「The cost:software overhead」と追記してある通り、プログラミングが面倒くさくなることは理解しているようだが、具体的なツールは出てくるのだろうか | 【図16】iQuantizeはどこに? という感じだが、処理は面倒ではないのであるいはiDCTとまとめているのかもしれない |
●MDSP : 力技ビデオプロセッサその2
 |
| CRADLE TechnologiesのCEO兼CTOであるArthur Chang氏 |
さて今回のハイライトは、Ultra data CorporationのUD3000に続いて発表された、CRADLE TechnologiesのMDSP(Multiprocessing DSP)である。
一般論として、ビデオのエンコード/デコードの処理の大半は、繰り返し処理となる。つまり画面をマクロブロック/ブロックに分割した上で、各々のブロック単位でME→Quantize→DCT→IDCT→IQuantize→MC→bitstream化といった処理を行なう事になる。
従って通常のプロセッサよりSIMD演算の方が向いているし、もっと言えばDSPの方が更に向いている。SIMDだと1つの命令で4~8個のデータしか処理できず、例えば8x8のデータを処理するためには8~16回命令の解釈→実行が必要になる。ましてや全ブロック分となると、かなりの回数命令の解釈→実行を要する。
どうせ同じ処理なのに、毎回解釈→実行を繰り返すのは効率が悪い。こうした点ではDSPの方が圧倒的に処理効率が良いからだ。
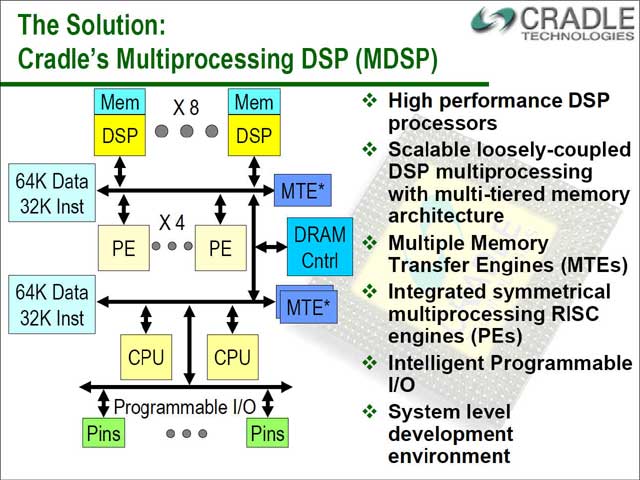
特にDSPの場合、(データの性質が性質だけに)マルチプロセッサ(というかマルチDSP)にすると、それに応じて処理性能がリニアに上がる傾向がある。では、とばかりにDSPを複数集積してしまったのがこのMDSPである。
ここで面白いのが、各DSPが粗結合(Loosely-Coupled)になっていること。つまり各DPSはローカルにメモリを持ち、これを共有していないことだ。また、キャッシュがあちこちに分散しておかれているのも面白く、おまけにMTE(Memory Transfer Engine)が複数用意されるという、力技の極致の構造となっている。
まずDSP自体の性能であるが、例えば8bit×8bitのMACオペレーションが1クロックあたり16個(8つで合計128個)となっており、16bit×16bitでも7.25GMACsという高い性能を持っている。
面白いのはこれをなぜ粗結合としたかであるが、このDSPコアはSIMD、つまり複数の処理を同時に行なうのは難しい事と関係ある。これがSISD/VLIW系のDSPのコアなら、例えば1本目のパスでブロックのQuantizeを行ない、その出力をそのまま2本目のパスに回してDCTを掛けるなんて事も出来るが、今回はDSP1でQuantize、DSP2でDCT…….という使い方になる。
そうであれば、必ずしもメモリを共有できる必要はないわけで、例えばマクロブロックの処理が1回終わるたびに、DSP1→DSP2に結果を転送するだけでよい。勿論メモリを全部共有で持つという案もあるが(これだと転送が要らない)、その代わりDSPコアがローカルメモリに書き込みを行なうたびに、メモリのスヌーピングが発生するわけで、結局メモリアクセスが遅くなり、しいては全体のパフォーマンス低下に繋がる。疎結合マルチDSPが、パフォーマンスを上げる鍵になるわけだ。
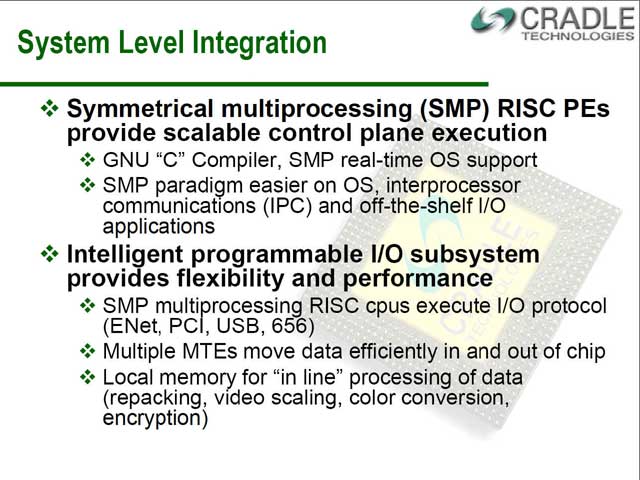
ただ、DSPだけで全ての処理が済むかというと、必ずしもそうではない。特にエンコード処理の場合、様々な予測オプションを実施するためには、DSPだけでは追いつかないためどうしても汎用プロセッサの助けも必要となる。これを処理するため、SMP構成のRISCプロセッサが搭載されているわけだ。
 |
 |
 |
| 【図18】DSPが8つ、DSPと連動するPE(Processor Element)が4つ、全体を管理するCPUが2つという、ものすごい装備 | 【図19】SIMD演算風の構造となるので、例えば1つのDPSの内部で複数の処理を並行して行なうというのは無理っぽい。その分、性能は高めにしているという事だろう | 【図20】勿論DSP間のローカルメモリ転送が遅ければ、やっぱりDSPが遊んでしまう。そこでInterconnectは、全DSPがアクセスする帯域の倍のスピードを確保してあるという |
ではどんな形で全体が動くか? という例を示したの図22である。4つのPEがそれぞれエンコードの各パートを担い、その下でDSP0~7が各々の役割分担に従って処理を行なう図である。図18で一番下に位置するCPU部は、純粋に高レベルなI/Oインターフェースを担っており、エンコード処理はPEとDSPで完全に完結している形である。
この力ずくのソリューションの性能は? ということで示されたのが図23である。流石にH.264で1,280×720@30fpsとかになると全然間に合っていないが、CIF(352×288)@30fpsとかだと余裕でエンコード/デコードが可能になっている。230MHz駆動の製品でこれだけのパフォーマンスなのだから、これはなかなか画期的なアプローチであることは事実だ。
例えばこれでまだ足りなければ、DSPを16個、PEを8個という事にすれば、ほぼ倍に近いエンコード性能が得られる事になる。まぁ無限に増やして行けるわけではないにせよ(段々メモリ転送がボトルネックになってゆく。またDSPはともかく、PEはそこまでスケーラブルに性能が上がるわけではない)、非常に面白い製品である事は事実だ。
CRADLE TechnologiesではMDSP用の開発キットも用意しており、DSPのプログラミングもCで記述できる(というか、PE用のプログラムの中にDSPへの命令をC言語風に記述できる)上、統合開発環境まで用意されており、(少なくともUD3000よりは)プログラミングは容易そうだ。とはいえ、ここまで無理やりDSPとCPUを詰め込んだ例はあまり見ないだけに、やはりキワモノ扱いされても仕方ない気がする。
 |
 |
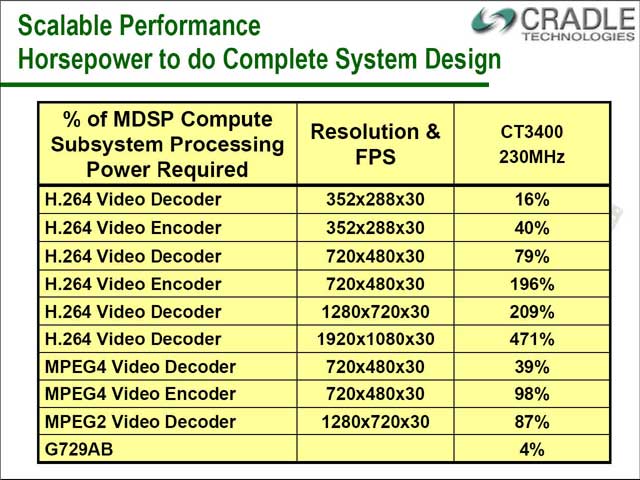 |
| 【図21】こちらはプログラミングを容易にするためか、SMP構成となっている。PEの詳細は公開されていない | 【図22】Audioで1つ、Video DecodeでDSP3つ、Video EncodeでDSPが4つ使われる勘定。Motion EstimationとInterpolationが1つのDSPで済んでいるあたり、広範囲のMotion Estimationはオプションに入っていないと思われる | 【図23】各々の処理を行なうのに、どの程度のパワーが必要かという数値。例えばH.264で720×480×30だと196%となっており、つまりこの解像度だとエンコード性能は15fpsがやっとということ。同様に1,920×1,080×30だと、30÷4.71≒6.3fps前後がリアルタイムでの処理性能ということになる |
●x86勢の進出で来年はIntelも参入か
 |
| MPF/EPF恒例、ARMスポンサードのカフェのお品書き |
ということで、EPF 2004のレポートを5本ほどお届けした。MPFに比べるとややこじんまりした傾向もあるし、経費削減のためか色々省略されていた(特に恒例のChip Portfolioが無くなったのはちょっと残念)といった部分はあるにせよ、色々と面白い発表があったのは楽しかった。
また、AMDやVIAがわざわざ発表を行なうあたりも、両社がこのマーケットを重視している証拠であり、来年あたりはIntelも登場しそうな予感がするところだ。
□Embedded Processor Forum 2004のホームページ(英文)
http://www.mdronline.com/epf04/index.html
□Freescaleのホームページ(英文)
http://www.freescale.com/
□ULTRADATAのホームページ(英文)
http://www.ultradata.com/
□Cradle Technologiesのホームページ(英文)
http://www.cradle.com/
(2004年5月28日)
[Reported by 大原雄介]
【PC Watchホームページ】
PC Watch編集部 [email protected] 個別にご回答することはいたしかねます。
Copyright (c) 2004 Impress Corporation All rights reserved.