 |


■後藤弘茂のWeekly海外ニュース■統合Shaderが次々世代のGPUアーキテクチャの鍵 |
●統合Shaderへ向かうGPUアーキテクチャ
「グラフィックスエンジンは、汎用の並列化されたベクトル型の浮動小数点エンジンになりつつある」と語るのはATI TechnologiesのDavid E. Orton(デビッド・E・オートン)社長兼COO。そして、そのゴールにあるのは、おそらく統合Shaderだ。
Microsoftは将来のShaderの方向性として「統合Shader」という概念を示唆している。実際、次のDirectXでは、Programmable Shaderのアーキテクチャが、Vertex ShaderとPixel Shaderでほぼ統一されるらしい。
さらに、GPUベンダーによると、物理的にも統合されたShaderに持ってゆくことがゴールだという。つまり、GPUの3Dグラフィックスパイプラインを解体、最終的にはVertex ShaderとPixel Shaderを、統合的な機能を持つShaderに置き換えてしまうようだ。一種類のShaderが、場合によっては頂点処理を行なうVertex Shaderになったり、ピクセル処理を行なうPixel Shaderになるらしい。
もちろん、頂点データをピクセルデータに転換するラスタライザなどは固定ハードウェアとして残る。しかし、これは現在のVertex ShaderとPixel Shaderの間ではなく、Shaderからアクセス可能な処理ユニットにまとめられるようだ。つまり、現在のGPUのジオメトリ処理→ラスタライズ→レンダリングという流れに沿ったハード構成を、次々世代のGPUではいったん崩して、Shaderアレイが柔軟に必要な処理を行なう構成に変わると見られる。
GPU業界関係者によると、Shaderアーキテクチャが統合Shaderへ向かうのは、まず将来のグラフィックス処理で利点があるからだという。
「将来は、ボトルネックをなくすアーキテクチャを作る必要があるからだ。例えば、T&Lとシェーディングの間のフローにボトルネックがあるとしよう。(GPUが)汎用目的のPixel/Vertexプロセッサのアレイになるなら、アーキテクチャ上、フローはもっとスムーズにできる。プロセッサ間のフローのバランスを取って、フローのボトルネックをなくすことができる。私は、これが今起こりつつある大きなトレンドだと考えている」とATIのOrton社長は、2002年春に語っていた。
現在のGPUハードの場合には、ジオメトリ処理とピクセル処理に別れ、それぞれのプロセッシングパワーが固定されている。そのため、ジオメトリ処理量は膨大だがピクセル処理は軽いソフトの場合には、ピクセル処理のパワーが無駄になり、その逆の場合にはジオメトリ処理パワーが無駄になるという問題を抱えている。そのため、ソフトウェア側は、どうしてもGPU側のジオメトリとピクセルのそれぞれの処理能力の枠に合わせて開発しなければならなかった。
しかし、統合Shaderが場合によって頂点とピクセルの処理を切り替えられるのなら、こうした問題は起きない。頂点処理とピクセル処理のそれぞれに最適な数のShaderを振り分ければすむからだ。Shaderを最適化し、Shader間でバランスよくデータを受け渡しすれば、ボトルネックを最小化できる。
●統合Shaderにより並列化が容易に
グラフィックスパイプを崩し、統合Shader化すると、GPUはますます並列化がしやすくなる。
「グラフィックスアーキテクチャがこうした(統合Shaderの)方向性へ向かう理由の第1は、スケーラビリティを拡張することにある。限られた数のエンジンを高速に動かすのではなく、より並列化されたエンジンにすることが、(GPUの性能向上にとって)現実的なソリューションだからだ」とOrton氏は指摘する。
統合Shaderにすれば、増やしたShaderをジオメトリとピクセルのどちらの処理にも使えるため、効率的にエンジンの並列化を図ることができるというわけだ。これは、今後、GPUが実装コストの高いShaderを多数並列に備えようとする場合には、非常に重要となる。
また、従来の3Dパイプのパフォーマンスの制約を離れ、これまでとは異なるタイプのグラフィックスアプリケーションをGPU上で利用しやすくもなる。3DlabsのBob Sharp氏(Business Manager, Asia-Pacific & Japan)は、次のように指摘する。
「伝統的なリアルタイム3Dグラフィックス以外の用途に広げるには、新ハードが必要になる。例えば、医療イメージではボリューメトリックを多用する。その場合には、ジオメトリもテクスチャも関係がない、膨大なデータ量を処理するピクセルプロセッシング能力だけが必要になる。ジオメトリとテクスチャの部分は使われないので、自由度がないパイプラインだと、チップの60~70%が使われなくなってしまう。しかし、チップに自由度があれば、ボリューメトリックレンダリングのような処理でも100%の能力で高速化できる」
つまり、Shaderの構成を自由に変えられるなら、ボリューメトリックレンダリングのようにピクセルプロセッシング能力しか使わない場合にも、GPUのフル演算能力を引き出すことができるわけだ。
こうしたGPUの方向は、かつてのメディアプロセッサやフルプログラマブルなグラフィックスシステム「PixelFlow」などの似ている。しかし、違いもある。それは、グラフィックス向けの専用アーキテクチャを保持して、性能をできるかぎり保ちながら段階的にプログラマブル化を進めようとしていることだ。
「例えばボリューメトリックレンダリンングの場合は、CPUなら全てをレンダーしなければならない。しかし、GPUの場合にはスクリーンに見える部分だけをレンダーすることで、ずっと高速化することができる。グラフィックスでは、GPUには明確な利点がある」とSGIのShawn Underwood氏(Director, Visual Computing Product Management)は言う。
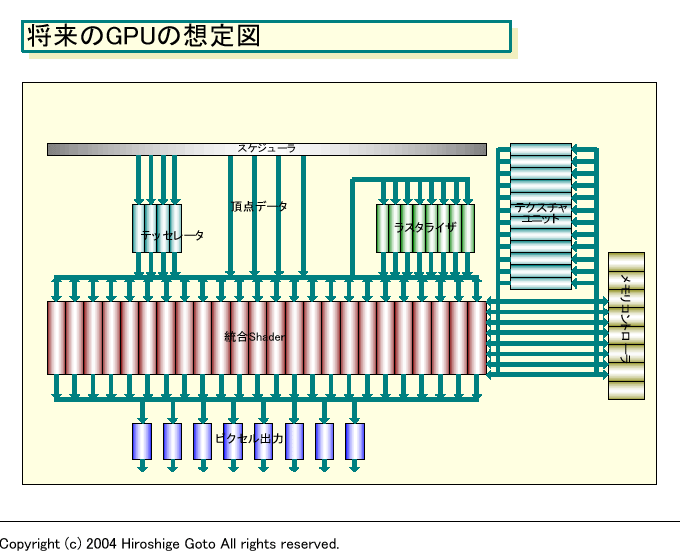 |
| 将来のGPUの想定図 PDF版はこちら |
●統合Shader化によって汎用化も進む
そして、統合ShaderはGPUが汎用プロセッサに向かう道程も、決定的に加速する。Shader 3.0までのGPUでは、Vertex ShaderとPixel Shaderでアーキテクチャが異なるが、統合Shaderになると同じプログラムが全てのShaderで走るようになる。自由にShaderユニットをフル稼働させることができるようになり、GPUハードのパフォーマンスを引き出すことが容易になる。
また、統合Shader化の過程で、その他の様々なGPU内部アーキテクチャ上の制約も解消されると推定される。グラフィックス用途に特化したGPUには、見えない部分にCPUとは異なる様々な制約がある。例えば、Shaderプログラムのスケジューリングとユニットの制御は、CPUのユニットの制御よりも一般的に柔軟性がない。
例を挙げると、ATIのRADEON 9700アーキテクチャは8個のPixel Shaderを備えているが、8個のユニットを個別に制御するのではなく、実際には4個のPixel Shaderを1グループ(クアッド)にまとめ、2グループのクアッド毎にシェーダ(プログラム)の実行を管理している。これは、Shaderでは各ピクセル毎の処理にそれほど大きな処理時間の違いが発生しないことを前提としているようだ。このあたりは、各ユニットがインフライトで個別に処理を進められるCPUとはかなり異なる。汎用処理のためには、こうしたユニットの制御機構も大きく進化させる必要がある。
もっとも、GPUはCPUとは異なり、並列性の高い処理を行なうことに特化している。非グラフィックス処理であっても、担当するのは並列性の高いアプリケーションとなる。そのため、CPUのようにひとつのスレッドの中で複雑なスケジューリングを行なう必要はない。また、Shaderユニットの並列性も容易に高めることができる。NVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)は、その理由を説明する。
「GPUとCPUとの一番大きな違いは並列性だ。グラフィックス処理では、極度に並列にプログラムを走らせることができる。
一方、CPUはそうはいかない。CPUは基本的にシングルパスを処理するためのプロセシングユニットで、そのユニットがメモリにひとつのデータパスでアクセスする。そのため、シングルパスの処理を効率的にするため、チップの面積の大半はキャッシュメモリに使われている。つまり、増えたトランジスタを、プロセシング能力を増やすのに使うことができなず、無駄が生じている。
それに対して、GPUではずっと並列性が高く、GPU内部の多数のストリームプロセッサが、それぞれが専用の入力と出力を持ち、並列に処理を行なう。トランジスタは、プロセッシング能力を増やすことだけに使うことができる。実際、NV30の大半は浮動小数点演算の論理回路で占められている」
つまり、CPUはシングルパスの高速化に向けて進化したプロセッサで、並列性の高いプログラムに特化したGPUとは違う道を進んでいるというわけだ。その意味では、CPUとGPUは、プロセッサとして棲み分けることになる。
●ベクトルプロセッサの逆襲
「GPUはどんどんプログラマブルプロセッサになっている。CPUとGPUの差は、最終的にスカラ型プロセッサかベクトル型プロセッサかの違いに過ぎなくなるだろう」
GPUの未来について、あるCPUメーカーの元技術者はこのように形容する。x86 CPUなどは1命令で1データを操作するスカラ型で、GPUは1命令で複数データを操作するデータレベルの並列化を行なうベクトル型だというわけだ。
実際には、GPUのSIMD演算ユニットとスーパーコンピュータのベクトル演算ユニットでは、同じSIMD型処理ユニットといっても大きな違いがあるし、x86 CPUもSIMD型ユニット(MMX/SSE/SSE2ユニット)を持つようになっているので明確な区分とも言えない。だが、データ処理の方向性としては、両者に違いがある。GPUはデータレベルの並列化に特化したプロセッサということだ。
面白いのは、同じような話がゲーム機ハードからも聞こえてくることだ。ソニー・コンピューターエンタテインメント(SCEI)は、次世代PlayStation(PlayStation 3?)では、多数のSIMD型の演算ユニット群で構成したCellプロセッサを搭載すると見られる。単純に演算ユニットの性格だけで区分するなら、Cellと数年後のGPUは同じようにSIMD型ユニットのアレイになるだろう。実際には両者には様々な違いがあるが、データレベルの並列化を追求するという方向は共通する。
そして、この流れは、ベクトル型スーパーコンピュータの逆襲とも考えることができるかもしれない。現在のSIMD型ユニットが、ベクトル型のスーパーコンピュータの流れをくむと考えるならの話だが。スーパーコンピュータの世界では、ベクトル型は劣勢になっているが、最高峰の地球シミュレータはベクトル型だ。しかし、SIMDのコンセプト自体は、むしろ広がりつつある。
実際、Cellプロセッサはワンチップスーパーコンピュータと例えられる。そもそも、SCEが出願したCellと見られるプロセッサ関連の特許には、ベクトルスーパーコンピュータメーカーの元技術者だった人物が名を連ねている。Cellの基本的な発想には、スーパーコンピュータの設計が影響している可能性が高い。
そして、スカラ型プロセッサも、現在の流れはSIMD型のデータレベルの並列化の強化へと向かっている。今後の性能拡張の大きな部分は、SIMD型の部分になっていくだろう。というのは、CPUの性能が必要とされているのは、データレベルの並列化が有効なマルチメディア処理だからだ。つまり、PCやゲーム機のような小型のコンピュータでも、処理の対象がメディアに移って来たために、スーパーコンピュータと同じような構造が必要になって来たと考えることができる。
そう考えると、データレベルの並列化に特化したプロセッサをメインCPUとして搭載しようというPlayStation 3の発想もよくわかる。こうしたプロセッサに、非定型のスカラ型の処理をやらせると効率が悪いが、処理のほとんどがデータレベルで並列化できるものになるなら、理にかなった設計となる。だとすると、データレベルの並列化に特化するのは、将来のプロセッサのトレンドになるかもしれない。例えば、組み込み向けプロセッサで、SIMD型ユニットだけで構成されたアーキテクチャが台頭して来るかもしれない。
つまり、重要なのは、将来のGPUの姿は、もしかすると将来のCPUの姿かもしれないということだ。
□関連記事
【1月14日】【海外】DirectX 11世代のGPUはShaderのアレイになる
http://pc.watch.impress.co.jp/docs/2004/0114/kaigai055.htm
【2002年9月4日】【海外】プロセッサ化へと向かうシェーダアクセラレータ時代のGPU
http://pc.watch.impress.co.jp/docs/2002/0904/kaigai01.htm
【2003年9月12日】【海外】ソニーのCellコンピューティング構想
http://pc.watch.impress.co.jp/docs/2003/0912/kaigai021.htm
(2004年1月15日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2004 Impress Corporation All rights reserved.