 |


■後藤弘茂のWeekly海外ニュース■まだまだ疑問が残るGeForce FX 5900のアーキテクチャ |
●寡黙なNVIDIAに饒舌なATI
昨年までのNVIDIAは、自社製品の先進アーキテクチャを大きく謳い、ある程度突っ込んだ技術内容まで喜んで語ってくれた。ところが、GeForce FX 5800(NV30)以降、NVIDIAは寡黙になり、製品の技術ディテールについて、あまり語りたがらなくなってしまった。
対するATI Technologiesは、昨夏以降、突然スタイルを変えて、アーキテクチャを詳細まで説明するようになった。インタビューでも、かなり突っ込んだ質問にもストレートに答えてくれる。
そのため、現在、NVIDIAとATIでは、情報量にかなりの差が出ている。そして、明らかに、その差はNVIDIAに不利に働いている。先週のGeForce FX 5900(NV35)の発表にしても、疑問符が多すぎるため、メッセージが明確に伝わってこない。
例えば、NV35の内部アーキテクチャについてNVIDIAに質問しても「詳細なマイクロアーキテクチャについては言えない」(NVIDIA、Stephen Sims氏、Senior Product Manager)の一点張りだ。詳細はChief ScientistのDavid B. Kirk(デヴィッド・カーク)氏に聞いてくれという説明を繰り返している。そのため、今回はE3でのKirk氏とのインタビューが流れてしまったこともあって、まだ、NV35の内部アーキテクチャはわかっていない。
●NVIDIAの開発サイクルとNV35
NVIDIAの開発サイクルでは、新アーキテクチャの“0”番台が登場、その6カ月後にプロセス技術を微細化したり機能を拡張した“5”番台が登場するのが通例となっている。
例えば、GeForce(NV10)からGeForce 2GTS(NV15)ではプロセスが0.18μmへと縮小し、微細化により動作周波数が向上。また、機能も拡張され、トランジスタ数は2,300万から2,500万へと約10%増えた。GeForce 3(NV20)からGeForce 4Ti(NV25)ではプロセスは同じ0.15μmだが、Vertex Shaderが2個に増えるなど機能が大きく拡張された。トランジスタ数も5,700万から6,300万へと約10%増えた。
このように、基本的に、0番台から5番台へは、基本設計を受け継ぐ形で開発している。マイクロアーキテクチャの根本には手をつけないが、性能のボトルネックを排除して効率的に性能アップする改良を加えるのが常だった。つまり、0番台は大規模な開発チームが担当し、5番台は相対的に小規模な開発チームが担当していると思われる。
では、今回はどうなのか。まず、プロセス技術は同じTSMCの0.13μm銅配線プロセスで、NVIDIAによると基本的には変わっていないという。動作周波数はGeForce FX 5900 Ultraが450MHzで、最初の発表時のGeForce FX 5800 Ultraの500MHzより低い。
しかし、500MHz品は実際にはスピードイールド(動作周波数による歩留まり)がかなり低かったと見られるため、現実的には半導体チップとしてのスピード派生は変わっていないか、逆に向上している可能性がある。少なくとも、NV35コアの方がスピードイールドが落ちる理由は見受けられない。NV35は1枚のウエーハから採れるチップの多くが450MHzで動作できると推測される。
トランジスタ数の増加は500万程度で、全体の5%程度に留まっている。これは、NV35の拡張が、過去の5番台よりも規模が小さいことを示唆している可能性が高い。ただし、トランジスタの比率が性能と完全に結びつくわけではないため、これはそんなに確実ではない。では、500万のトランジスタを使って、NV35では何を拡張したのか。
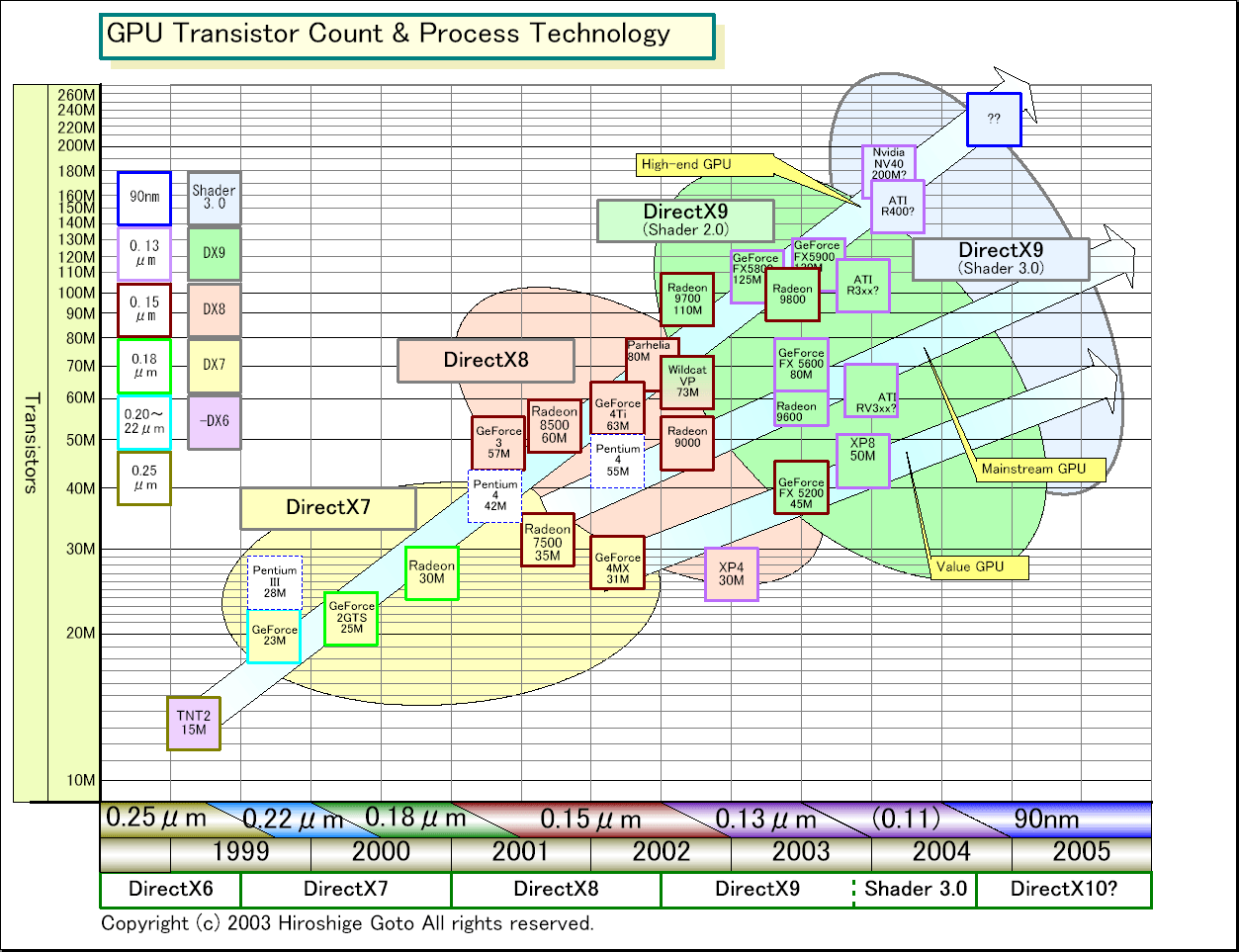 |
GPUのトランジスタ数とプロセス技術の変遷 |
●メモリ帯域は過剰なほど
NV35の機能拡張のポイントは、アーキテクチャ的に分けると3つになる。
(1) メモリインターフェイスの256bit拡張
(2) UltraShadow/Intellisample HCTの実装
(3) 浮動小数点Pixel Shader性能を2倍に拡張
まず、メモリインターフェイスは従来の128bit幅から256bit幅に拡張された。しかし、今回のボードコンフィギュレーションでは、GeForce FX 5800 UltraのDDR2(転送レート1GHz/バスクロック500MHz)は採用されず、最高で850MHz(バスクロック425MHz)のDDRとなった。
メモリインターフェイス幅を2倍にすると、メモリの粒度(Granularity:最小構成単位)は2倍になってしまう。しかし、GeForce FX 5800系も128Mbitチップ(x32)を使っていたため、粒度は128bit時に64MB、256bit時でも128MB。粒度だけを考えたらDDR2でも問題はない。そのため、DDRメモリにしたのは、単純にコスト(+もしかすると供給量)と発熱量のためだと推測される。
メモリインターフェイス幅を2倍にしたため、生メモリ帯域は27.2GB/sec(DDR 850MHz)となり、NV30の最高16.0GB/sec(DDR2 1GHz)の1.7倍になった。これは、現在のGPUでは最高だが、実際にはオーバーキルかもしれない。というのは、NVIDIAのDavid B. Kirk(デヴィッド・カーク)氏(Chief Scientist)は、NV30の発表時に「現状では、メモリ帯域がそんなにボトルネックだとは思わない。バランスとしては、拡張された(今の)メモリ帯域に合わせるには、もっとパワフルなパイプラインを作る必要がある」と語っていたからだ。
●ステンシルシャドウ処理を高速化
UltraShadowは、現在のゲームの影生成でポピュラーに使われているステンシルシャドウ処理を高速化する技術だ。ステンシルシャドウを多用すると、シャドウボリュームのジオメトリが非常に複雑になる。そこで、UltraShadowは、シャドウボリュームのZ値から、影が投射されないと判断できる部分の演算を省くことで高速化する。言ってみればシャドウのカーリング技術で、従来2パスを必要としていたシャドウボリュームをシングルパスレンダリングで処理できるようにする。
この手法は、原理的にDOOM系のようなステンシルシャドウを多用するソフトでは効果が高い。いわばDOOMアクセラレータだ。ただし、欠点もある。「この機能を使うには新しいAPIのコールが必要になる」(NVIDIA、Stephen Sims氏、Senior Product Manager)からだ。そのため、対応したソフト以外は高速にならない。
Intellisample HCT(高解像度テクスチャ圧縮)は、より高効率なテクスチャ圧縮とキャッシングの複合技術。こちらは、GPUの命題であるデータ圧縮を高める技術だ。
Intellisample HCTとUltraShadowは比較的わかりやすいソリューションだ。問題は残る、“2倍のPixel Shader性能”だ。じつは、この内容について、まだNVIDIAは、どうして2倍の効率になるのか、その理由を明かしていない。「シェーダユニットにもっとリソースを注ぎ込んだ結果、浮動小数点時のパワーが2倍になった」(Sims氏)といった程度の説明に留まっている。
●ポイントとなるPixel Shaderの構成
Pixel Shaderの処理性能は、DirectX 9世代GPUの最大のポイントだ。NV30はPixel Shaderの構成が他メーカーのハイエンドGPUとはちょっと違っている。NVIDIAは「GeForce FX 5800は、クロック当たり4つの浮動小数点(FP)32bit演算ができる」(NVIDIA、Geoff Ballew氏、Product Line Manager)と説明する。つまり、32bit浮動小数点Pixelの演算は、8並列ではなく、最大4並列に留まっていた(同時に4並列の整数ピクセル演算ができるため最大では8オペレーション並列となる)わけだ。
そのため、NV35では、32bit浮動小数点でのピクセルの全ての演算が8並列になったかどうかが最大の注目ポイントだった。これについては、今のところまだNVIDIAは明確に答えていない。演算ユニット数を増やしたかという質問に対しては、「もっと話は複雑だ。リソースを増やしたのは確かだが、詳細は言えない」(Sims氏)と説明している。
しかし、もしPixel Shaderの浮動小数点カラー&アルファ演算ユニットの数を2倍にしようとしたら、トランジスタ数としては数千万が必要になる。そのため、常識的に考えれば、その部分は大きく変わっていないと考えた方がよさそうだ。
ちなみに、ライバルのATIはPixel Shaderの内部精度を24bitに落とすことで常に8並列のピクセル処理をできるようにしている。しかし、NVIDIAは「NV35でも24bitの内部処理はしてない。24bit精度は中途半端で意味がないというスタンスは変わっていない」(Ballew氏)と説明する。
NV35の、Pixel Shaderのどの部分が2倍の処理性能になり、どんなテクニックで高速化を図っているかの詳細が明らかになるのは、まだ先になりそうだ。
もっとも、NVIDIAの情報公開には進歩もある。例えば、今回のGeForce FX 5900の資料で、NVIDIAはNV30/35系の「Color+Z」のピクセル出力がNV31と同じ4であることを明確にした。ステンシルシャドウやZ処理では8並列となっている。ある業界関係者は「Color+Zのノーマルピクセルでは4ピクセル並列、ステンシルシャドウなどの処理では8ピクセル並列になるのがNV35のアーキテクチャ」と説明する。
というわけで、総合するとNV35はNV30からは進歩しパフォーマンスを伸ばしたが、GPUの内部構造を大きく変えたGPUではない可能性が高い。だが、年末には早くも次世代の「NV40」が控えていることを考えれば、それも穏当な展開かもしれない。
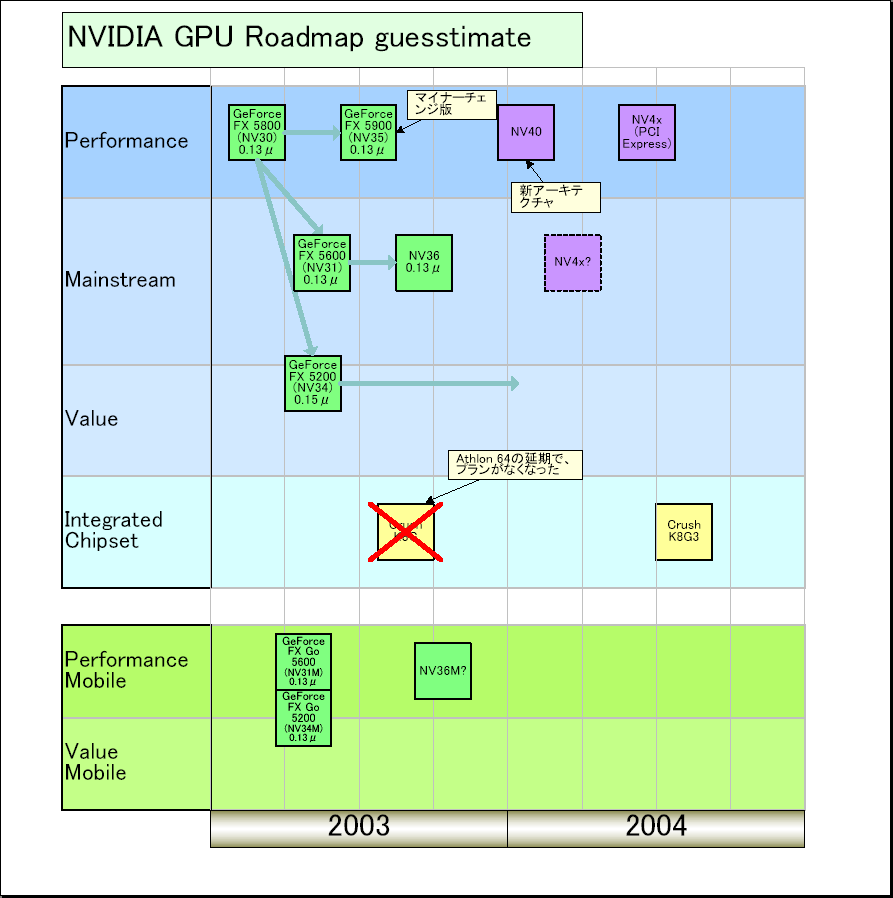 |
NVIDIA最新GPUロードマップ |
(2003年5月22日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2003 Impress Corporation All rights reserved.