 |


■後藤弘茂のWeekly海外ニュース■RADEON 9800とGeForce FX 5800、正しい道はどちら? |
●速いのはR350かNV30か
「本当に速いのはRADEON 9800(R350)なのか、GeForce FX 5800(NV30)なのか」
これが論争になっている。しかし、この比較は、じつは無意味だ。というのは、両GPUはその設計思想と方向性が大きく異なっているからだ。ほぼ同じ方向を向いてたDirectX 8世代までのGPUの比較とは話が異なる。だから、本当のポイントは『どちらが正しい』か、ではなく『どう違っているのか』にある。どちらの実装にも設計思想があり、そのため強みと弱みがある。それを象徴しているのが、(Pixel Shaderの精度が)32bitか24bitかという問題だ。
乱暴に言えば、NVIDIAは性能を犠牲にしても32bitフル精度にこだわり、ATI Technologiesは性能のために24bit精度に妥協した。その結果、GeForce FXは高精度だが低速な32bit処理と高速な16bit処理という実装になっている。一方、RADEON 9600/9700/9800はその中間の24bitで32bit処理はできないが常に高速だ。
NVIDIAが32bitを選んだ理由は前々回のこのコラム「なぜNVIDIAはGeForce FXでデータ精度を重視したのか」で説明した通り。では、なぜATIや他のGPUベンダー(S3 Graphicsなど)は24bitを選んだのか。また、API(DirectX 9)側の定義するデータタイプは16/32bitだ。そうすると、32bit浮動小数点ピクセルの処理ではデータをまるめてしまう24bit GPUのRADEON 9800は、“真のDirectX 9 GPU”と呼べるのだろうか?
この問題を把握するには、DirectX 9策定の時点に遡る必要がある。DirectX 9の策定では、まさに浮動小数点Pixel Shaderとその精度が議題の中心だったからだ。
「DirectX 8チップを設計した時は整数演算だけだったので話は簡単だった。しかし、DirectX 9では、16bit整数から32bit浮動小数点に移行することが重要なテーマとして、Microsoftと(GPUベンダー)の話し合われた。誰もが合意したのは『開発者のために浮動小数点に移行しよう。整数よりずっと利点がある』という点だった」とATIのAndrew B. Thompson氏(Director, Advanced Technology Marketing, ATI Research)は説明する。
●16/24/32bitで揺れたGPUメーカー
しかし、浮動小数点ピクセルのサポートは決まったものの、データ精度をどうするかはかなり議論があったらしい。それは、32bit精度の演算ユニットを実装するのが大変だったからだ。
「16bit整数から32bit浮動小数点に行くとなると、シリコン(チップ面積)と(メモリや内部パスの)帯域が必要になる。そのため、32bitの実装は非常に高価(ダイサイズが大きくなること)で遅くなってしまう」とThompson氏は指摘する。
ATIのJason L. Mitchell氏(Project Team Leader, 3D Application Research Group)もデータ精度が難題となったと言う。
「32bit浮動小数点の演算ユニットは、必要となるトランジスタ数が多すぎるため、実装が難しいと考えた。しかし、16bit浮動小数点では精度が明らかに低すぎる」
そのため、API側で調整するという案も浮上したという。Mitchell氏はその経緯を説明する。
「我々(GPUベンダーとMicrosoft)は、1年前に(DirectX 9の実装方法を)決めた段階で、16bit浮動小数点と32bit浮動小数点のトレードオフを把握していた。そのため、24bitのフォーマット(をDirectX 9で定義すること)も考えた。しかし、それは開発者にもAPIにも重荷になると考えてやめた。そう遠くないうちに、全てのチップが常に32bitで走るようになると考えたからだ」
つまり、現在のGPUの性能とトランジスタ数からすると、本当は24bit程度の演算精度が最も合っている。しかし、将来のGPUは高速に32bit演算をできるようになるため、24bitのAPIを定義しても、過渡期のものに終わってしまう。そのため、API側は32bitで、GPU側は24bit演算ユニット実装という流れになったらしい。つまり、MicrosoftもGPUベンダーも、承知の上でこうしたAPIとGPUの組み合わせにしたわけだ。
そのため、ATIだけでなく、ほとんどのGPUベンダーが最初の世代のDirectX 9 GPUでは24bit Pixel Shaderを実装してくるようだ。例えば、S3 Graphicsも「DeltaChrome」では「8パイプラインを実装し、どのパイプラインでも24bit内部精度の浮動小数点演算と整数演算の両方ができる」(Nadeem Mohammad氏,Marketing Product Manager)という。ATIと同じタイプの実装だ。
だから、GPUベンダーは、NVIDIAが32bit精度のPixel Shaderを実装すると聞いてかなり驚いたらしい。GeForce FX 5800(NV30)の4個の32bitPixel Shaderという構成の方が例外のようだ。
●24bitはいいトレードオフ
ATIのThompson氏は、同社の選択を「24bitは、確かに一種のカットオフだ」「しかし、今のところ24bitは、性能と精度のいいトレードオフ」と評価する。ATIのMitchell氏も「我々は、パイプライン内部では24bit浮動小数点で表現することにした。(16bitも32bitも)全ての処理が常に内部的には24bitで行なわれる。そのため、常に(GPUの)最高スピードで処理できる。これは、パフォーマンスと精度のいいバランスだと考えている。また、(GPUの)アーキテクチャもシンプルにできる」と言う。
ATIのアーキテクチャでは16bitデータも24bit演算ユニットで処理(処理精度は16bitのまま)される。また、32bitデータは24bitに落とされて処理される。32bit時には、データ精度は落ちるが、その代わり32bit時の処理性能も16bit処理時と同じになるわけだ。
実際、ATIのR3xx系(RADEON 9600/9700/9800)は両処理で、性能にほとんど差がない。GeForce FX系で16bitと32bitの処理で、大きな性能差が出るのと対照的だ。GeForce FX系の性能差は「GeForce FXのパフォーマンス疑惑」で説明したように、16bitと32bitで、パイプライン構成が変わるためと考えられている。
「異なるデータタイプと、それに対応した異なるピクセルパイプラインを備えることは、オーバーヘッドが大きい。不幸なことに、彼ら(NVIDIA)はこうした選択をした。これは、開発者にとっても重荷になり、開発者の対応を阻害すると思う」とMitchell氏は言う。
しかし、32bitを24bitに落として問題はないのだろうか。CPUだったら、こうした実装はあり得ない。
●16bitで足りないケースがある
「ゲームでも、RenderMan(映画のオフラインCG制作によく使われるレンダリングツール)コンテンツでも、どちらのレンダリングでも、よく使うオペレーションで必要とされる精度は、24bitで十分で満たせると考えている。実際に、RenderManの複雑なシェーダを24bitで実行してみたが、問題はなかった」とMitchell氏は言う。
ATIはこれを証明するために、RenderManのシェーダをRADEON 9800に移植して実行して見せた。オフラインCGでは32bit精度が必要になるケースがあるが、それも多くはないとThompson氏も説明する。
「32bit精度が必要になるのは、非常に長いシェーダで複数回のパス(のレンダリング)を行なう時だけだ。1回か2回のパスなら、24bitは十分以上だ。確かに、RenderManなどで数千命令長のシェーダを走らせると多数のパスになり、32bitが必要になるかもしれないが」
ではゲームなどリアルタイムCGではどうなのだろう。リアルタイムCGでは16bit精度で十分という意見もある。
「32bitは確かにゲーム制作には必要がないと思う。しかし、16bitでは明らかに不足だ。16bitだとうまくいかないケースが多々ある。一例を挙げると、ベクトルをリノーマライズする際だ。もし、この処理を16bitで行なったら、多くの問題が生じてしまう。例えば、ゲーム開発者にとっては、キューブマップで精度が低くなり品質が落ちるという問題が生じてしまう」とMitchell氏は指摘する。
つまり、DirectX 9で期待される品質を求めるなら、16bitだけでは問題があるという意見だ。
こうして見ると、ATIとNVIDIAの考え方の違いはよく見えてくる。ATIはゲームなどのリアルタイムCGでは24bit程度の精度が実用的だと考えた。また、オフラインCGでは、映画制作などでの数千命令に渡るシェーダ以外では、24bitで対応できると考えて妥協した。より、リアルタイムCGに傾いた格好だ。
それに対して、NVIDIAはオフラインCGの世界で受け入れられるには32bit精度が不可欠と考えた。対応できないケースがあってはいけないと考えたわけだ。その一方、リアルタイムCGでは、現状では16bit処理中心でも大丈夫だと考えたように見える。ATIより、オフラインCGの世界のシェーダを重視したようだ。
今回に関しては、NVIDIAの方が技術純粋主義で、ATIの方が実践主義のように見える。今の時点で、PCの上での比較では、ATIアーキテクチャの方が旗色がいいように見えるのは、そのためだ。
しかし、もう少し長いスパンで見ると、この32bit対24bit論争も消えて行く。というのは、どのGPUも32bitPixel Shaderへ向かうからだ。
ATIのThompson氏も「公式にはアナウンスしていないが、将来は32bitへと動いて行く。24bitはあくまでも過渡期」という。
●重い32bitPixel Shader
では、なぜ今の時点でPixel Shaderを32bit浮動小数点ユニットにするのがそんなに大変なのか。24bitにしたATIが8個の浮動小数点演算ユニットを搭載できたのに、32bitを取ったNVIDIAが4個の浮動小数点演算ユニットしか搭載できなかったのはなぜなのか。
それは、プロセス技術との絡みで考えるとよくわかる。
DirectX 8世代GPUは0.15μm、DirectX 9世代GPUの主流は0.13μmで製造される(RADEON 9700/9800系やGeForce FX 5200は例外で0.15μm)。0.15μm→0.13μmの移行での微細化率はリニアに85%程度、面積では70~75%程度となる。そうすると、0.15μm→0.13μmに移行しても同じサイズのチップに搭載できるトランジスタ数は1.4倍程度にしかならない。
ハイエンドGPUはダイサイズ(半導体本体の面積)を増やすこともできるが、メインストリームはそういかない。そうすると、計算上、GPUメーカーは40%増えたトランジスタをやりくりしてDirectX 9の機能を実装しないとならない。また、性能向上にもトランジスタを割く必要がある。その制約だと24bit化はできるが、32bit化するのは難しいというわけだ。
では、整数演算ユニットと浮動小数点演算ユニットでどれだけの差が出るのか。これは実装形態によって大きく異なるため一概には言えない。しかし、CPUを見ても、整数演算ユニットより浮動小数点演算ユニットの方が数倍も大きい。また、GPUの場合はSIMD演算ユニットなので、32bitは実際には4データをパックにした128bitSIMDの処理となる。だから、4ジオメトリ8ピクセルパイプのGPUを32bit精度で作ることは、ラフに言えばSSE2ユニットを12個搭載したCPUを作るのと同じことになる。ちなみに、Pentium 4の搭載するSSE2ユニットは1個だ。
GPUのダイを見てもこれはよくわかる。下がRADEON 9700のダイレイアウトだ。かなりラフな図なのであまり正確には測れないが、これを見るとPixel ShaderがVertex Shaderの約2倍の面積を占めていることがわかる。Pixel Shaderがコアの40%程度、Vertex Shaderが20%程度だ。
 |
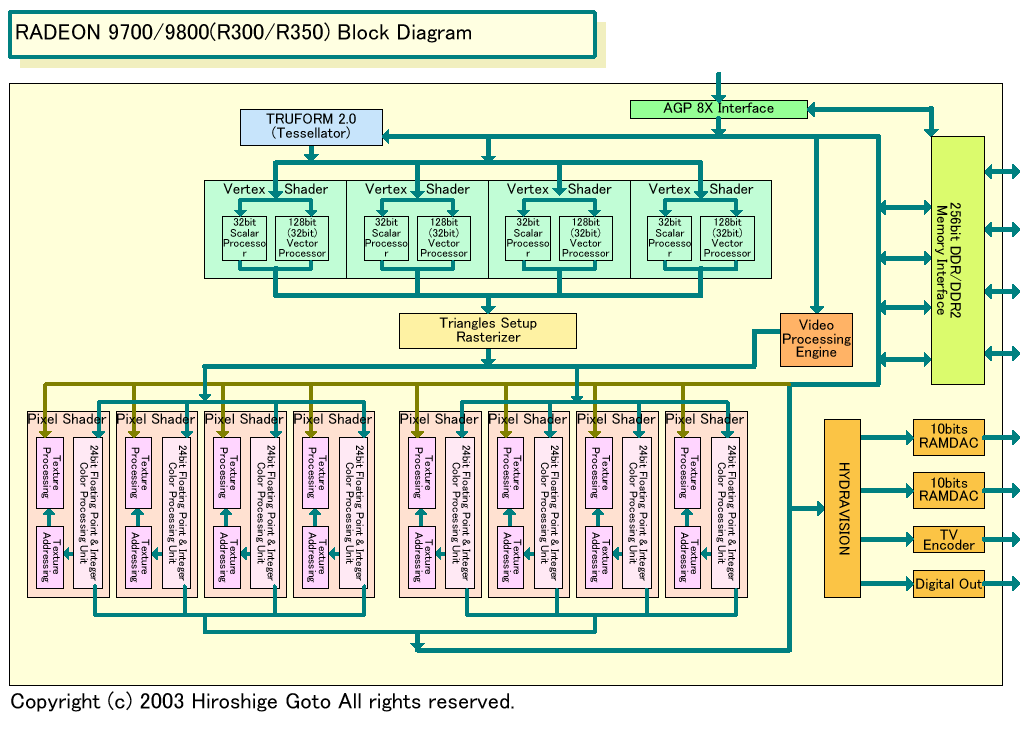 |
| RADEON 9700のダイレイアウト | RADEON 9700/9800ブロック図 |
これは、Pixel Shaderには、さらにテクスチャユニットやテクスチャキャッシュなどが随伴しているためと思われる。つまり、演算ユニット数自体が多い上に、付属するユニットやバッファがあるため、Vertex Shaderよりサイズが大きくなるわけだ。
だから、Pixel Shaderを32bit化して1.5倍のサイズにした場合には、RADEON 9700のダイサイズは現在の216平方mmから250平方mm以上のサイズにふくれてしまったろう。これはGeForce FX 5800についても同じだ。200平方mm弱のGeForce FX 5800が、もし8個の32bitユニットを備えたら、こちらも面積は250平方mmクラスになっていただろう。0.18μm版Pentium 4(Willamette:ウイラメット)ですら217平方mmだったのだから、それは不可能だ。もちろん、GPUをCPU並みの価格で売って、グラフィックスボードを1枚1,000ドルにするなら可能かもしれないが。
□関連記事
【4月22日】【海外】なぜNVIDIAはGeForce FXでデータ精度を重視したのか
http://pc.watch.impress.co.jp/docs/2003/0422/kaigai01.htm
【4月21日】【海外】GeForce FXのパフォーマンス疑惑
http://pc.watch.impress.co.jp/docs/2003/0421/kaigai01.htm
(2003年4月25日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] 個別にご回答することはいたしかねます。
Copyright (c) 2003 Impress Corporation All rights reserved.