 |


■後藤弘茂のWeekly海外ニュース■GeForce FXのパフォーマンス疑惑 |
●ドライバのバージョンで大きく変わるGeForce FXのパフォーマンス
 |
| リードテック「WinFast A300 Ultra TD MyVIVO」 |
あるライバルGPUメーカー業界関係者は、これを「ドライバマジック」と呼ぶ。彼によれば、「ドライバの最適化だけで、ここまで急に性能が向上するのは通常では考えられない」からだ。
ATIテクノロジーズジャパンもRADEON 9800/9600/9200ファミリの日本での発表会で、この問題を(名指しはしないものの)指摘していた。同社が指摘したのは、性能を重視したドライバでは、本来32bit浮動小数点精度で行なわれるべき処理が、16bit浮動小数点精度で行なわれているという点。同じシェーダの処理結果をRADEON 9600(RV350)とライバルGPUで比較。明確な描画のスムーズさの違いを見せ、内部24bit精度で処理するRV350に対して、ライバルGPUの処理は16bit精度で行なわれていることを示唆した。
実際、ドライバによっては、データ精度を犠牲にして性能を向上させているという同様の指摘は、過去1カ月ほどの間に、様々なレビューサイトにも上がっている。そのため、レビューサイトでは、2世代のドライバでのベンチマーク結果を掲載しているケースもある。また、あるGPU関係者は、高速なDetonator 43.45では、DirectX 9の規定に反しているため、MicrosoftのWHQLの認定は通らないはずだと指摘する。大論争になりつつあるわけだ。
●32bitだと低速で16bitだと高速なGeForce FX
実は、ドライバでの話題が出るよりもずっと前から、GeForce FX系アーキテクチャではデータ精度によって処理性能に大きな差が出ることは、知られていた。DOOMの開発者であるid SoftwareのJohn Carmack氏は、今年頭に「Plan John Carmack」でNV30とR300の性能について言及していたが、その中ですでにモードによる性能の違いを指摘している。
それによると、OpenGL ARB(Architecture Review Board)2のパスを使った場合にはNV30はR300(RADEON 9700 Pro)よりかなり遅いが、NV30に最適化したベンダースペシフィックなモードを使った場合にはずっと速くなるという。その理由は、R300は常に同じ精度で処理するが、NV30はパフォーマンスの異なる精度を内部的にサポートしているからだという。
つまり、R300系はどのデータ精度でも常に同じ速度だが、NV30は高精度(32bit)だと非常に遅くなり、低精度(16bit)だと高速になるというわけだ。
この件は、Carmack氏だけでなく、多くの業界関係者が指摘する。また、NVIDIA自身も、GeForce FXアーキテクチャでは「16bitの方が高速に走る」(Geoff Ballew氏,Product Line Manager)ことを認めている。3月に開催されたGDC(Game Developers Conference)でも、NVIDIAはパフォーマンス上の理由から、必要がない限り32bitではなく16bitを使うように推奨していた。
自分はレビューアーではないので、性能についての詳細はほかに譲るが、こうした情報は、実はアーキテクチャ面を考えると納得できる。推測上のGeForce FXアーキテクチャと符合するからだ。
●演算ユニットの精度での選択の違い
DirectX 9の最大の特徴の1つは、ピクセル処理が整数だけでなく、浮動小数点に拡張されたこと。つまり、サーフェイスフォーマット(=データタイプ)が拡張され、浮動小数点精度が加わった。DirectX 9の規定する浮動小数点データタイプは、各色16bitのABGR16f、各色32bitのABGR32fの2種類。いずれも4個ずつのデータを同時に処理するSIMD(Single Instruction, Multiple Data)なので、換算すると64bitと128bitになる。
つまり、DirectX 9世代GPUでは、16bit(64bit SIMD)と32bit(128bit SIMD)の浮動小数点演算をサポートする必要がある。これはOpenGL 2.0についても同じだ。
しかし、実際にはGPUは必ずしも32bit精度の処理をしていない。
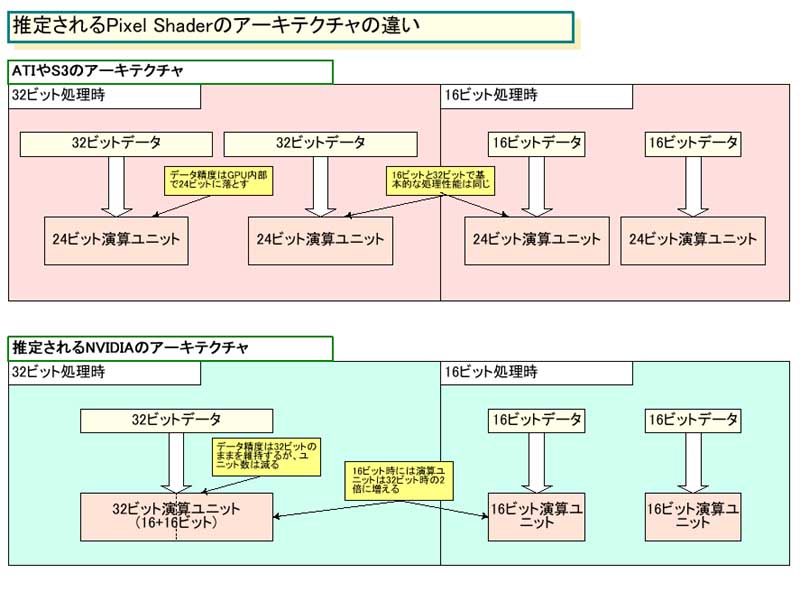
例えば、ATI TechnologiesとS3 Graphicsは、内部では24bitで処理している。ATIはフラッグシップのRADEON 9700/9800(R300/R350)のPixel Shaderに8個の24bit浮動小数点演算ユニットを実装した。S3 GraphicsのDeltaChromeも同様に8個の24bitユニットを持つ。
両社のアプローチはこの点では非常に似通っていて、APIとしては32bitもサポートするが、内部では精度を落とす。16bitフォーマットも32bitフォーマットも、全部24bitで実行される。16bitと32bitのどちらのデータも、同じ速度で演算ができるので、32bit時にもパフォーマンスロスがない。端折っていると思うかもしれないが、リアルタイムCGを中心に考えた場合にはこれで十分な精度だと言う。
それに対して、NVIDIAはまったく異なる方法を採った。GeForce FXファミリでは、32bit内部精度で処理を行なう。つまり、32bitから24bitへデータ精度を落とすことがない。いいことだが、これにはトレードオフがある。それはユニット数と処理速度だ。NV30では4個の32bit演算ユニットしか搭載していないとNVIDIAは説明する。つまり、Pixel Shaderの精度は高いがユニット数は他社のフラッグシップGPUの半分ということになる。
NVIDIAが演算ユニットを半分に減らしたのは、搭載できるトランジスタ数の制約からだと思われる。24bit(96bit SIMD)演算ユニットと32bit(128bit SIMD)演算ユニットでは、ユニットのコスト(トランジスタ数とダイサイズ)に大きな違いがあるからだ。
 |
| 推定されるPixel Shaderのアーキテクチャの違い |
●GeForce FXでは16bitユニット2個で32bit演算か?
では、なぜこのGeForce FXアーキテクチャの場合、精度を16bitに落とすと性能が高くなるのか。NVIDIAのGeoff Ballew氏(Product Line Manager)は「メモリ帯域、レジスタスペース、テンポラリストレージなどすべての点において16bit浮動小数点は(32bitより)少なくなる。だから、ずっと高速になる」と説明する。しかし、実際にはそうした差から推測されるよりも、ずっと大きな性能差が精度によって生じているように見える。
ここから考えられるのは、NVIDIAのPixel Shaderが、実は16bit(64bit SIMD)ユニット2個で32bit(128bit SIMD)演算を行なっている可能性だ。32bitユニットが、16bit演算を行なう2つのユニットに分割できると言い換えてもいい。こうした実装は、実は珍しいことではない。CPUの世界では昔から行なわれてきたことで、今でも多用されている。ごく普通の手法だ。
もし、GeForce FXファミリのPixel Shaderがこの実装方法を取っているとすると、16bit時には演算ユニット数は2倍に増えることになる。それなら、データ精度によって性能が大きく変わることも納得できる。
また、GPUの開発者サイドに立ってみれば、NVIDIAがこうした実装方法を取るのは当然だ。どころか、32bit化でこうした実装にしないなら、その方がおかしい。というのは、もし32bit処理しかできない演算ユニットを実装した場合には、16bit処理時にも、他社と比べてパフォーマンスが大きく落ちてしまうからだ。しかし、16bitユニット2個で32bitを処理させるなら、16bit処理時のスループットは少なくとも他社と遜色がないレベルになる。そして、32bit処理時には、他社が追従できないフルの高精度を実現できる。
こうして見ると、この件が、GeForce FXのドライバと性能という、近距離の視点以上の問題を含んでいることがわかる。それは、GPUに必要なデータ精度がいったいどれだけなのか。また、GPUはリアルタイムCGに焦点を合わせるべきか、オフラインCGに焦点を合わせるべきなのかという問題だ。
現在の情報からでは次のように推測される。ATIやS3は、リアルタイムCGでシェーダを速く動かすことが重要と考え、精度より性能を優先して24bitにした。逆を言えば、リアルタイムCGでも32bit APIでの24bit程度の精度は必要と考えたわけだ。
それに対してNVIDIAは、オフラインCGのシェーダでの精度に対する厳しい要求を重視して、処理が遅くなるのを覚悟の上で32bitを実装。その代わり、16bitでは高速になるようにしたと思われる。これは、速度が必要なリアルタイムCGは、現状では16bit中心でいいと割り切ったように見える。
問題は、どうしてNVIDIAだけがそんな選択をしたのか。そして、NVIDIAの選択は支持されているのかという点にある。今のところは、NVIDIAがこうしたGeForce FXアーキテクチャの説明を十分に行なっていないため、どんどん疑問が膨らんでいるように見える。
□関連記事
【4月18日】【HotHot】1スロット仕様のGeForce FX 5800 Ultra搭載カード登場!
~WinFast A300 Ultra TD MyVIVO徹底レビュー
http://pc.watch.impress.co.jp/docs/2003/0418/hotrev209.htm
(2003年4月21日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2003 Impress Corporation All rights reserved.