 |


■後藤弘茂のWeekly海外ニュース■違いは小さいが方向性が異なる
|
ATI Technologiesの新GPU「RADEON 9800」のもっとも大きな拡張ポイントは、アーキテクチャ面でのPixel Shaderの拡張だ。この拡張が重要なのは、(1)ATIがGeForce FXにアーキテクチャ面で対抗する姿勢を明確にした、(2)オフラインレンダリングCG制作市場の開拓に本腰を入れる姿勢を示した、からだ。
NVIDIAは、GeForce FXに搭載したCineFXアーキテクチャで、Pixel Shaderで2000以上の命令をサポートした。これは、映画などに使われる高品質のオフラインCG制作をターゲットにするためだった。それに対して、RADEON 9700ではPixel Shaderがサポートできる命令数が制限されているために、長大なオフラインCG向けシェーダは移植しにくい。だが、ATIもRADEON 9800では同じようにPixel Shaderを拡張してきた。NVIDIAに対する不利を減らしたわけだ。
このことは、今後の両社のハイエンドGPUが、リアルタイムCG性能だけでなく、オフラインCGのための機能も追求するようになることを示していると思われる。ATIで言うなら、これまでよりさらに「FIRE GL」系(プロ向けGPU)ブランドの重要性が増すということだ。もちろん、ATIやNVIDIAにとって通常のクライアント向けが最重要なのは変わらないが、比重はやや傾く。GPUの世界は、明らかに方向性が変わり始めている。
●Pixel Shaderの制約はシェーダプログラムのサイズ
GPUの現在のShaderには、1パスで処理できるシェーダ(プログラム)の命令数(命令スロット)に制約がある。RADEON 9700の準拠するDirectX9は、テクスチャ命令が最大32命令、カラー命令が最大64命令。つまり、96命令以上を含むシェーダ(プログラム)を書いても、GPUでは実行できない。大きなプログラムを実行するCPUとは異なり、細かなプログラムをストリーミングで実行するプロセッサなのだ。DirectX9のこの制約は、現在のGPUの性能でリアルタイム処理できるシェーダの規模を前提に、性能を重視するために決められたという。
「ハードウェアがシングルパスで実行できる命令数は決まって来る。これは伝統的にパフォーマンスの理由からだ。ゲームをインタラクティブなフレームレートで実行するのに十分な長さの命令数をハードウェアでサポートした」とATIのAndrew B. Thompson氏(Director, Advanced Technology Marketing, ATI Research)は説明する。
つまり、長いシェーダはリアルタイム処理では不要というわけだ。「もし、1,000命令をサポートしたとしても、そんなピクセルをリアルタイムにレンダリングできない」とATIのDavid E. Orton(デビッド・E・オートン)社長兼COOは指摘する。リアルタイムCGを考えた場合には、制約があっても問題がないわけだ。
しかし、映画などに使われるオフラインCGの制作では、話が違う。はるかに大規模なシェーダが書かれるからだ。つまり、シェーダはずっと長く、多くの命令を含んでいる。
NVIDIAはそこにフォーカスしたからこそ、GeForce FX系では最大でカラー命令とテクスチャ命令を各1,024命令をサポートできるようにPixel Shaderを拡張した。そして、ATIもRADEON 9800で同じように、Pixel Shaderのサポート命令数を拡張をしてきた。両社とも同じ方向を向いている。
●レンダーファームを視野に入れた技術
もっとも、NVIDIAとATIでは使っているテクニックが異なる。ATIではこの拡張を「F-buffer」と呼ばれる技術で実現している。F-bufferを使うと、CPUのように無制限に長いプログラムを実行できる。
「F-bufferテクニックは、ハリウッドスタイルの、プロフェッショナルなシネマティックムービーレンダリングを主な対象としている。リアルタイムのインタラクティブ性が必要なソフトはプライマリアプリケーションではない。200命令程度なら多分(今のGPUで)インタラクティブに実行できるだろう。我々がF-bufferが必要と考えているアプリケーションは、RenderMan(映画制作用によく使われるCGソフト)で映画用のシェーダを作るといった用途だ。そうしたシェーダは数1,000命令になり、F-bufferが適用される」とThompson氏は説明する。
つまり、F-bufferはゲームのようなリアルタイムCGを向上させるための技術ではなく(ある程度はその用途にも使えるが)、オフラインCGのレンダリングもGPUでサポートできるようにするための技術だ。オフラインCGの最終レンダリングは、現在はサーバーを多数用意したレンダーファームのCPUで行なわれている。F-bufferは、それをGPUに入れ替えることを可能にする。
「現在、SGIなどがシミュレーション市場向けにRADEON 9700/9800を買っている。彼らは、多くのチップを搭載したシステムで、高品質のシミュレーションを実現している。これが最初のステップとなる。
レンダーファームは、現在、IntelやSun MicrosystemsのCPUを使っている。これは、一種のブルートフォース(力業)的なアプローチだ。だから、我々はこれらのCPUをグラフィックスプロセッサで置き換え、もっと効率的にレンダリングすることができるだろう。もちろん、それがすぐにできるとは思わない。しかし、2~3年のうちには、必ずそれ(GPUを使ったレンダーファーム)を見ることができるだろう。
そのために重要なのは、高精度(ピクセル)と、F-bufferによる非常に長いシェーダ(プログラム)のサポートだ。それが提供されれば、人々はレンダーファームを(GPU)で作り始めることができる。これは、業界の明確な方向性だ」とThompson氏は言う。
以前にも書いたが、これは言ってみれば“GPU版サーバー市場”への進出を意味する。つまり、GPUをより高く売る道を開く。Intelが同じアーキテクチャのCPUを、PCとサーバーの両方に提供することで、膨大なCPU研究開発費を捻出しているのと同じことができるようになる。GPUが今後発展するには、必須の方向性ということになる。だから、“業界の明確な方向性”なのだ。
●仮想的に無制限Shaderを作るF-buffer技術
F-bufferは正式には「Fragment-stream buffer」と呼ばれる。ピクセル(=Fragment)のストリームを一時的にメモリに格納する技術だ。
「ハードウェア(GPU)ではワンパスでサポートできる命令数が限られている。しかし、テンポラリバッファに(処理途中の)データを保存。そのデータを、もう一度パイプラインのトップから入れることで、より長いシェーダ(プログラム)を実行できるようにする。もし、数百命令をワンパスで処理できるハードウェアなら、数千命令のシェーダを10回のパスで処理できる」とThompson氏は言う。
つまり、長いシェーダ(プログラム)を実行する場合、Shaderハードウェアが実行できる命令数を超えたら、データをいったんFIFOバッファに書き出す。そして、再びピクセルパイプの最初から、シェーダの続きを実行するというわけだ。もちろん、シェーダ側からはF-bufferは見えない。どんな長さのシェーダも実行できるGPUに仮想的に見えるというわけだ。
より大きなビューで見ると、F-bufferでやっているのはマルチパスレンダリングだ。複数パスのレンダリングによって、GPUのハードウェアの制約を回避するわけだ。しかし、従来のGPUとShader世代GPUでは、マルチパスレンダリング自体、大きく異なる。
「固定パイプ(のGPU)ではマルチパスは、パイプラインすべてを再度通さなければならなかった。だからペナルティが大きかった。しかし、Programable Shaderのマルチパスは小さなピースでできる。ずっと、やりやすくなった」とSGIのShawn Underwood氏(Director, Visual Computing Product Management)は、昨年のSIGGRAPH時に語っている。
つまり、Shader世代GPUでは、マルチパスレンダリングは、パイプライン全体ではなく、Shaderだけを回せばいいので、ずっとペナルティが少ない。そして、F-bufferは、Shader世代のマルチパスレンダリングをFIFOバッファ使って高速化すると同時に、仮想化して隠蔽してしまう。それによって、演算ユニットの制約をなくすわけだ。
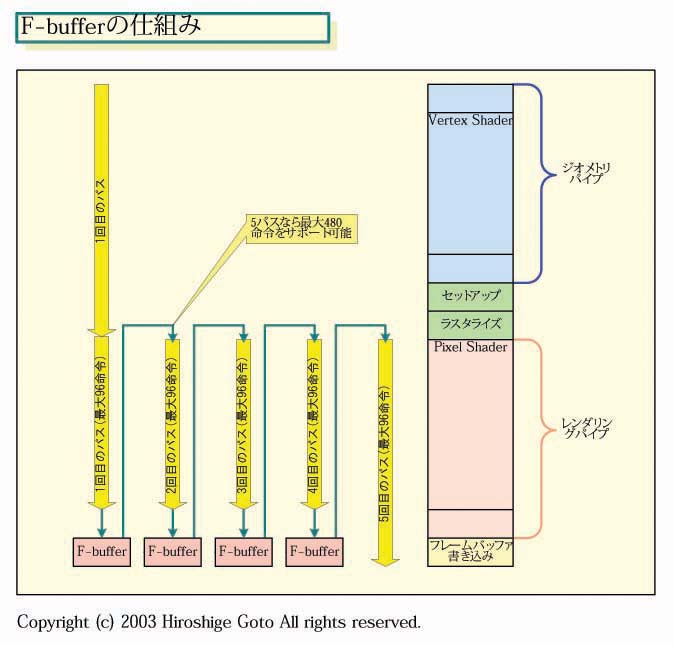 |
| F-bufferの仕組み |
●ライバルNVIDIAのアーキテクトの考えた技術
もっともトレードオフもある。
「F-bufferにはパフォーマンスペナルティがある。データをメモリに書き出すためだ。だから、インタラクティブなフレームレートには十分ではない。しかし、これで長いシェーダプログラムを効果的に実行できるようになる。また、(現在のように)CPUで実行するよりはずっと速い」(Thompson氏)
もっとも、ATIもこれをF-bufferを長期的なソリューションとは考えていない。あくまでもハードウェアの制約がある過渡期のためのものだ。「F-bufferは、今は素晴らしい解決策だが、将来はF-bufferは必要としなくなるだろう」とThompson氏は言う。また、今後、Pixel Shaderがフロー制御命令を含むようになり、ジャンプ命令などが使われるようになると、この手法はうまく働かなくなる。
ATIにとってF-bufferの実装は、コストが小さい(GPUのコスト上昇が少ない)。「RADEON 9700ですでにF-bufferに必要な要素はほとんど搭載していた。必要だったのは、非常にわずかなシリコン(トランジスタ)の追加だけだった。加えたのはテンポラリバッファをF-bufferにするためのロジック(回路)などだ」とThompson氏は説明する。
つまり、RADEON 9800では、テンポラリバッファを増量。そのバッファに対する書き込みのためのポートとロジックを加えたことで、F-bufferとして使えるようにしたと推測される。Shader自体のアーキテクチャ変更は必要がないため、複雑化を避けることができる。
ATIはこのアーキテクチャを以前から考えていたフシがある。というのは、ATIのOrton氏は昨年6月のインタビュー時に「Pixel Shaderレベルでは、数1000もの命令を、ハードウェアで(サポート)するか、仮想的なコンテクストスイッチで(サポート)するか...」と示唆していたからだ。今、こうして見てみると、これはF-bufferを指していたと想像される。残念なことに、当時は、意味がつかめなかった。
また、ATIはF-bufferを研究していた米スタンフォード大学の「real-time programmable shading project」のスポンサーにもなっていた。ちなみに、このプロジェクトの中心人物だったWilliam R. Mark氏は、現在NVIDIAでGeForce FXに合わせた言語「Cg」の開発を担当している。つまり、ライバル企業に行ったアーキテクトが考えたテクニックをATIが採用したというわけだ。
□関連記事【3月6日】ATI、コードネーム「R350」こと「RADEON 9800 PRO」を発表
http://pc.watch.impress.co.jp/docs/2003/0306/ati.htm
(2003年4月7日)
[Reported by 後藤 弘茂]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2003 Impress Corporation All rights reserved.