
|


●シェーダ中心に組み変わる次世代GPU
DirectX 9世代グラフィックスチップ(GPU)の姿が見えてきた。昨日のこのコラムでレポートした通り、GPUベンダーはこの夏から来年前半にかけて、相次いでDirectX 9世代のGPUをリリースする。各ベンダーの情報が集まってきたことで、DirectX 9世代のGPUについては、ほぼトレンドを推測できるようになった。
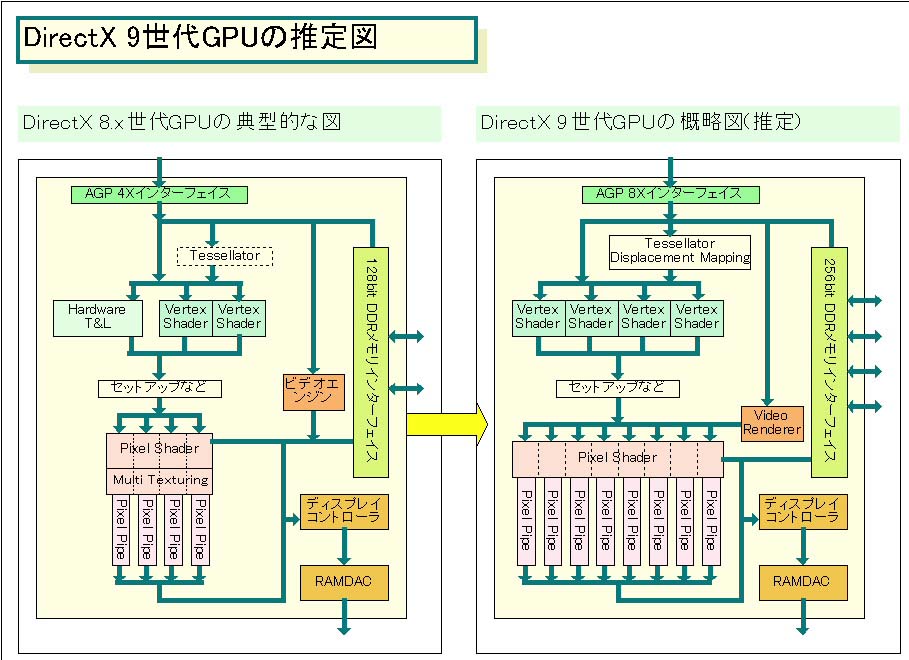
まず、DirectX 9世代GPUの構成はほぼ下の図のようになると思われる。図の右がDirectX 9時代のGPUの推定図、左が現在のDirectX 8.x世代のGeforce4 TiやRADEON 8500などのブロック図だ。比較して、目立つポイントは以下の通りだ。
・アダプティブテッセレータ(Tessellator:平面分割ユニット)を搭載
・ハードウェアT&Lを搭載しない
・バーテックスシェーダ(Vertex Shader:頂点処理ユニット)は4個(倍増)
・レンダリングパイプは8本(倍増)
・固定テクスチャユニットは1~2テクスチャ/1パイプ
・メモリインターフェイスは256bit DDR
・コアは300~400MHz/メモリは300MHz(DDR 600MHz)以上
・AGP 8Xインターフェイス
 |
| DirectX 9世代GPUの推定図 |
まず、GPUはプログラマブルなシェーダ中心に組み替えられ、GPU内部の固定機能(フィックスファンクション)は減ってゆく。そして、処理ユニットの数(シェーダ数やパイプ数など)は倍増、メモリとホストのインターフェイス幅も倍増する。これらの特徴はあくまで推測で、またGPUによってバリエーションはあると思われるが、主流はこうした構成になると思われる。それは、DirectX 9をサポートすると必然的に採らなければならない構成・アーキテクチャがあるからだ。
●ハードウェアT&Lはシェーダでのエミュレーションに
まず、アダプティブテッセレータ。これは、ポリゴン以外のジオメトリデータタイプである「ハイオーダーサーフェス(Higher Order Surfaces)」、例えばパッチテクノロジやディスプレイスメントマッピングのサポートで必要になる。DirectX 9互換のアダプティブテッセレータは、Matroxの「Parhelia-512」がすでに搭載している。「ハイオーダーサーフェスのサポートはDirectX 9で要求されている。DirectX 9互換とするなら、搭載しなければならない」(SiS、Thomas Tsui Director, Multimedia Product Division)ため、基本的には各社ともサポートしてくると見られる(持っていないGPUもあるという情報もある)。
また、隠面処理(Hidden Surface Removal)もこの部分で行なわれるらしい。「隠面処理はバーテックスシェーダの前に行く。処理のムダをできるだけ減らすためだ。もっとも、すでに似たようなメカニズムをインプリメントしているメーカーも多い」とSiSのTsui氏は言う。
一方で、DirectX 7時代からポリゴンの座標変換とライティング処理を担当してきたハードウェアT&Lは姿を消す。ハードウェアT&Lは、バーテックスシェーダ上でのエミュレーションとなる。DirectX 9世代GPUでは、レガシーのソフトのハードウェアT&Lへのコマンド(DirectX 9ソフトではバーテックスシェーダを直接叩く)は、バーテックスシェーダ(ソフトウェア側からはハードウェアT&Lに見える)で実行されるようになる。Parheliaがすでにこのアーキテクチャを採用しているが、ATIやSiSなど各社も次の世代はそうなることを認めている。ただし、これにはハードルもある。それは、性能だ。
「ハードウェアT&Lをバーテックスシェーダでインプリメントすること自体はそう難しくはない。ただし、それによってパフォーマンスがある程度削がれてしまう。というのは、ハードウェアT&Lなら1サイクルで実行できる処理が、バーテックスシェーダでは数サイクル必要になってしまうからだ。これは、プログラマビリティとのトレードオフだ」(SiS、Tsui氏)
つまり、DirectX 9世代での、既存ソフトのジオメトリ性能は、バーテックスシェーダのスループット×ユニット数にかかっている。DirectX 9世代GPUでは、バーテックスシェーダが4ユニットと、現在の1~2ユニットから倍増すると見られるが、その理由のひとつは、このハードウェアT&Lエミュレーションの性能のためだ。
「バーテックスシェーダは、確かに固定機能のハードウェアT&Lと比べると遅い。しかし、Parheliaではバーテックスシェーダは4個備えているので、十分な性能を達成できる」とMatroxのKamran Ahmed氏(Senoir Manager, Technical Marketing and Product Management)は説明する。逆を言えば、バーテックスシェーダで十分な性能を達成するためには、シェーダユニットが4個並列で必要だということだ。
●テッセレータがバーテックスシェーダの負担を増やす
バーテックスシェーダが4個になるもうひとつの理由はテッセレータだ。「一般論を言うと、テッセレータをインプリメントするためには、頂点(Vertex)処理を強化する必要がある。テッセレータによって、カーブサーフェス(曲線で構成されたサーフェス)がポリゴンに自動変換されると、データの爆発が起こる。今日の環境では、テッセレーションによって、膨大な数のポリゴンが生成されるからだ。これは、ジオメトリ処理部に負担をかける。バーテックスシェーダは膨大な頂点座標の変換とシェーディングをしなければならない。その数は、実に、数億頂点/秒にも達する」とATIのDavid E. Orton(デビッド・E・オートン)社長兼COOは説明する。
こうした事情から、DirectX 9世代GPUはバーテックスシェーダを4個装備するのが普通になると思われる。
また、DirectX 8.x世代までは、ハードウェアT&Lやバーテックスシェーダをインプリメントしないで、それらの機能はCPU上でのエミュレーションで実現するという方法もあった。だが、DirectX 9ではそれもなくなる。SiSのTui氏は、その理由を次のように説明する。
「我々は、DirectX 8.1世代のXabreでは、バーテックスシェーダをインプリメントしなかった。バーテックスシェーダはCPUにエミュレーションさせており、その方がスケーラブルに性能を伸ばすことができる。コストを考慮しながら、性能を最大限引き出すにはその方がいいと判断した。しかし、DirectX 9からは、このような分離したインプリメントはできなくなる。つまり、DirectX 9に対応しようとしたら、必ずバーテックスシェーダとピクセルシェーダ(Pixel Shader:ピクセル処理ユニット)の両方をインプリメントしなければならない。両シェーダが相互に連携して働くためで、マルチレンダリングで、時にはバーテックスシェーダに戻さなければならないケースも出る」
このため、DirectX 9世代GPUでは、ほとんどのチップが全フィーチャをインプリメントして来ると思われる。
●DirectX 9に最適化するとレンダリングパイプは8本に
DirectX 9世代ではレンダリングパイプは8本になると見られる。現行の最先端GPUは、ほとんどが4パイプなので、倍増することになる。次世代GPUが8本へとパイプが増えるというトレンドは、各メーカーともほぼ一致している。「DirectX 9世代のColumbiaでは、パイプは8本になる。4パイプという案もあったが、社内でシミュレーションなどを行ない検討した結果8パイプが適していると判断した」(日本エス・スリー・グラフィックス、太田仁彦マネージャー)、「レンダリングパイプは継続して増やす。ATIとNVIDIAの製品でも、パイプラインは4から8に増えるはずだ。そうしなければならないからだ」(SiS、Tsui氏)、「パイプは増やすが、6パイプを計画したことはない。……普通考えたら、倍々の方が簡単だろう? 2、4、8みたいな」(NVIDIA, David B. Kirk氏, Chief Scientist)
DirectX 9世代GPUで、パイプライン数が増えるのは、DirectX 9のフィロソフィがマルチレンダリングにあるからだ。「マルチレンダリングをしようとしたら、必ずパイプラインは増やさなければならない。そうしないと、レンダリングが遅くなってしまうからだ。2度3度レンダリングするとなると、パイプ数を増やして並列に処理するしかない」(SiS, Tui氏)
つまり、DirectX 9のフィーチャを活かそうとしたら、パイプは8本へ向かわざるをえないというわけだ。もちろん、パイプライン4本の構成もありうるが、その場合は、DirectX 9ベースのコードの性能は落ちる可能性が出る。
●レンダリングパイプが2倍になるならメモリインターフェイスも2倍に
そして、レンダリングパイプ数の増加とともにメモリ帯域も必要となる。ATIのOrton氏はその理由を次のように説明する。
「GPUのパイプラインとメモリチャネルの数には面白いバランス、つまり、相関関係がある。というのは、パイプライン本数は消費できるメモリ帯域にある意味で制約されるからだ。今日、GPU業界では4パイプが主流だ。しかし、これを継続して引き上げようとするなら、メモリチャネルもまた増やさなければならない。GPUに用意できるパイプライン数は、メモリ帯域とメモリアーキテクチャによって決まることになる。逆を言えば、メモリが速くなれば、(同じメモリインターフェイス幅でも)パイプラインの本数を増やすことができるようになる」
つまり、ピクセルパイプ数が倍になるなら、同じDDRメモリを使う限り、メモリインターフェイス幅も倍の256bitにしなければならないということだ。メモリインターフェイス幅を減らす方法は、メモリアーキテクチャを変えて、メモリを高速化することとなる。そのため、現在GPUメーカーはDDR IIメモリを第2世代のDirectX 9.x世代GPUのビデオメモリに採用することを真剣に検討しているらしい。
DirectX 9世代GPUでは、パイプライン数は増えるものの、1パイプ当たりの固定テクスチャマップ数は増えない。現在のGPUでは、固定テクスチャ機能は1パイプで2テクスチャ以上貼れるのが一般的だが、DirectX 9世代では1テクスチャ程度に縮小するメーカーが多い。これは、DirectX 9のコードでは、テクスチャマッピングもバーテックスシェーダ内での処理へと移るからだ。
ちなみに、DirectX 9世代のGPUの多くは、コアクロックが300~400MHz以上に達すると見られる。これは、DirectX 9世代GPUのほとんどが、0.13μmプロセスで製造されるからだ。プロセス技術だけで数十%クロックが向上する上に、GPU内部がプロセッサ化するため、原理的にはより高クロック化が容易となる。インターフェイスはAGP 8X、これは時期を考えると当然だ。
こうして想定されたDirectX 9ハードの姿は、なかなか壮大だ。1億トランジスタを費やすのだから当然だが、GPUの複雑度と機能のリッチ度はDirectX 8世代から飛躍する。
□関連記事
【7月10日】【海外】「DirectX 9は全く新しい世界を開く」と語るATI
http://pc.watch.impress.co.jp/docs/2002/0710/kaigai01.htm
(2002年7月11日)
[Reported by 後藤 弘茂]