
|
|


●CPUの機能強化の焦点である分岐予測機能
AMDの次世代CPU「Hammer(ハマー)」は、既存のPCの使い方で性能を上げることよりも、今後のPCの利用形態や、サーバー&ワークステーションでの性能向上にポイントを置いているように見える。それが明確に現れているのは、分岐予測機能だ。Hammerの分岐予測は、より大きなワークロード(負荷)、つまり、大規模なプログラムや多数のプログラムの実行に適したものに大幅に強化されている。
今のCPUは、条件分岐命令が来たときに、その分岐命令で分岐するかしないかを予測して投機的に実行してしまう。パイプラインが深くなってしまったため、条件の成立を待ってから実行するのでは、膨大なロスが生じてしまうからだ。しかし、予測をミスした場合には、パイプラインをフラッシュしなければならず、これがCPUの性能向上の大きなハードルになっている。そのため、最新CPUでは、この分岐予測がもっとも重要な強化ポイントとなっている。
現在の最新CPUの分岐予測精度は90~95%程度と言われている。これは逆を言えば、5~10%外れるわけだ。そして、外れた場合、Athlonでは10サイクル、Pentium 4では20サイクル分のロスが発生して、パイプラインにある数十の命令をフラッシュしないとならなくなる。しかも、通常のコードの場合は、およそ6回に1回の割合で分岐命令が来る。このオーバーヘッドはかなり大きい。だから、精度を1%上げるだけで、CPUの性能はかなり上がると言われている。
●膨大な量のグローバル分岐履歴カウンタ
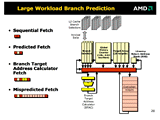 |
| 高負荷時の分岐予測 提供AMD、PDF形式 |
まず、分岐の方向を記録する、グローバル分岐の履歴カウンタテーブル「Global History Counter」は、16KBと記録的な規模を誇る。単純な量の比較では、Athlonの4倍だ。つまり、より多くのコードに対して、分岐したかしないかを記録しておくことができる。
ただし、分岐予測のカウンタは2bitと従来と同じ。また、予測のアルゴリズムに関しては、AMDは今のところ、より複雑なアルゴリズムを採用したという説明はしていない。もちろん複雑な方が精度が上がるが、アルゴリズムの複雑化は、分岐予測に時間がかかるようになるというトレードオフがある。アーキテクチャによっては、複数サイクルが必要になることもある。
Hammerの場合は分岐予測をして分岐ターゲットアドレスをゲットするまでは2ステージ目までで終わっており、3ステージ目で分岐先をフェッチしている。ロスは1サイクルだけで、これはAthlonも同じだったはずだ。また、Hammerでは分岐ターゲットアドレスはTarget Arrayに2KB分格納する。Return Address Stack (RAS)は12エントリだ。
この他、HammerはBranch Target Address Calculator(BTAC)という見慣れないユニットを持っている。BTACは、通常のCPUでは分岐先アドレスのキャッシュであるBranch Target Address Cacheを指すが、Hammerの場合は一種のアドレス生成ユニットだ。
Hammerでは、分岐予測ミスの場合は、正しい分岐先のフェッチまでに12サイクルを要するという。しかし、この予測ミスのケースの中には、分岐する方向の予測自体は正しいのに、分岐アドレスを予測ミスした、つまりターゲットアレイにある分岐先のアドレスが正しくない(分岐アドレスが固定されていないような場合)、あるいは分岐先アドレスがアレイにないというケースが存在するという。これまでは、そうしたケースでもパイプラインの下の方の演算ユニットでアドレス計算をしなければならず、分岐方向の予測自体をミスした場合と同様にペナルティが非常に大きかった。だが、HammerではBranch Target Address Calculator(BTAC)で、正しい分岐先を計算できる。そのため、ストールは最小限(プレゼンテーションの図だと合計5サイクル)に抑えられるという。
条件分岐によるロスは、結局「分岐予測ミスの確率×予測ミス時のペナルティ」なので、このBTACによってペナルティが減ることで、トータルで見た場合のパイプラインのロスが少なくなる。AMDがHammerでこのユニットを設けたのは、分岐予測機構の構成上、分岐予測情報自体はあっても、アドレスがキャッシュしていないというケースが多く発生するためかもしれない。
●負荷が増すほど有利なHammer
AMDのアーキテクチャでは、L1命令キャッシュに命令を取り込む際に、プレデコードビッツ(pre-decode bits)を加える。これは、可変長のx86命令の区切り位置やどの命令が分岐命令かといった情報を示す。このプレデコードビッツによって、L1命令キャッシュ内では、どこにどんな分岐命令があるかがわかる仕組みとなっている。この分岐命令のプレデコードビッツを、Branch Selectorと呼んでいる。
Hammerの場合は、このBranch Selectorデータが、64KBのL1命令キャッシュからL2キャッシュに追い出された命令についても、キャッシュされるという。また、これはECCビッツを使っているようだ。また、MPFでの説明によると、ここにも分岐予測情報をストアする1bitがあり、それもキャッシュされるらしい。つまり、HammerではL2キャッシュ全体に対しても、分岐命令の情報を保持できることになる。
もっとも、このあたりは、まだ詳細がわからないので、この理解で正確なのかどうかわからない。それから、この技術発表から実際の製品化までの間に機能が変わる可能性もある。実際、Athlonの時はMPFでの技術発表から製品化までの間に、分岐予測機能が大幅に強化された(例えば分岐履歴テーブルは2倍になった)。
いずれにせよ、こうやって見るとHammerの分岐予測機構は、精度を上げるという方向だけでなく、分岐予測情報を保持できるコードの範囲をこれまでになく大きく増やそうとしていることがわかる。これは、コードの局在性(頻繁に使われるコードが決まっている)の高いプログラムを限られたワークロードで使用する、これまでのPCの使い方向きではないように見える。大規模なプログラムを使うサーバー&ワークステーション向け、あるいは、今後、PCでもワークロードが増えてゆくことを想定した拡張の雰囲気がする。これは、サーバー&ワークステーションで非常に有効なHammerのインターフェイス構造と共通した思想で、Athlonと比べた場合のHammerの大きな方向性の違いとなっている。大ざっぱに言えば、HammerはAthlonの拡張だが、Athlonと違ってより先の展開を指向したプロセッサということになる。
ただし、こうしたHammerの特徴は、PC向けのベンチマークでは見えにくい可能性がある。AMDは、Athlon XPではIPC(instruction per cycle:1サイクルで実行できる命令数)×GHzが性能だと説明した。しかし、プログラムやワークロードによってIPCは大きく変わる。Hammerは既存のコードでもAthlonより性能を出せるだろうが、利点がもっとも発揮されるのはヘビーなワークロードの時になると思われる。つまり、ラージワークロード(高負荷時)でも高いIPCを維持できることが利点となると見られるので、AMDはそちらへ性能評価の基準を誘導する必要が出てくるだろう。
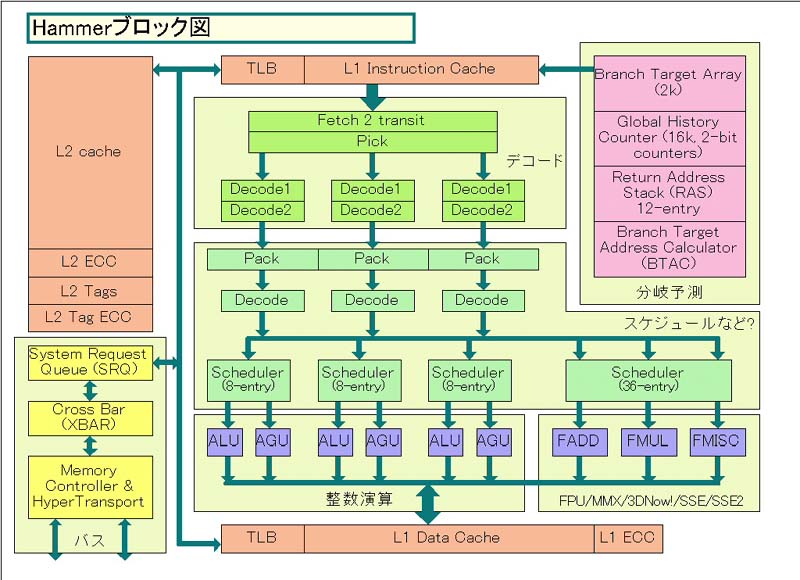 |
| Hammerのブロック図(再掲) |
(2001年11月5日)
[Reported by 後藤 弘茂]