
|
|


●フェッチの2ステージ化で高クロック化が容易に
AMDは「Microprocessor Forum(MPF) 2001」で、次世代CPU「Hammer(ハマー)」の基本的なアーキテクチャを明らかにした。今回はパイプラインに焦点を当ててレポートしたい。
MPFでの説明によると、Hammerのパイプラインは、整数演算12ステージ、浮動小数点演算17ステージ。ただし、AMDのWebサイトにあったHammerのWhite Paper( http://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_2315_3937,00.html ) では整数演算は13ステージになっているので数え方が変わる可能性もある。もっともこのWhite Paperはタイプミスも多いので、単なるミスかもしれない。そもそも、このWhite Paperは見つけた時はAthlon MPのコーナーに入っていた。入れる場所からして間違えていたというとんでもないシロモノだ。
 |
 |
| Hammerのパイプライン | HammerとAthlonのパイプラインの比較 |
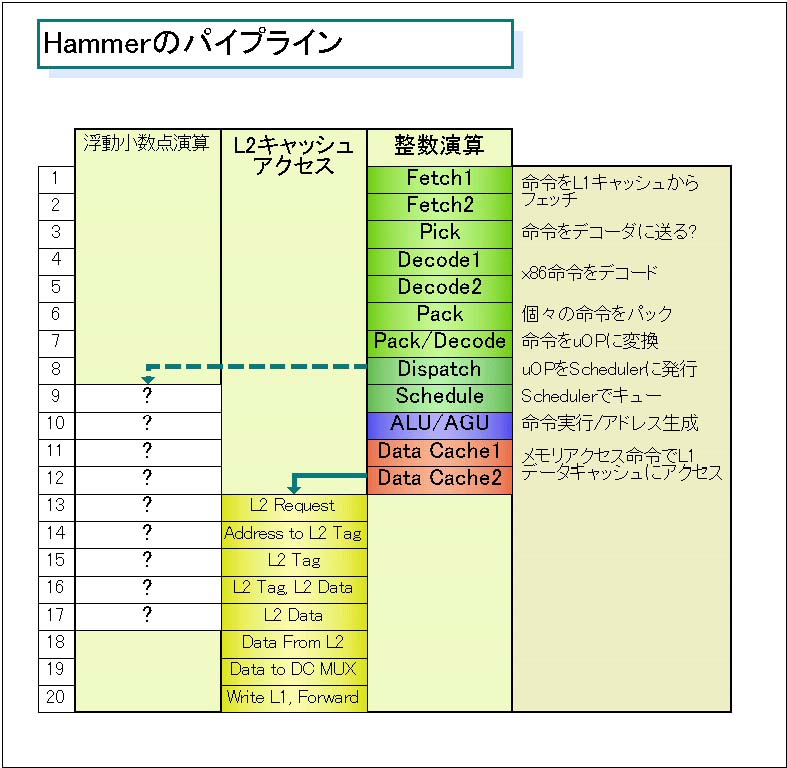
「Hammerのパイプライン」図を見るとわかる通り、Hammerは最近のCPUに多いロングフェッチ&デコードでショート実行パイプラインCPUだ。つまり、高クロック化のために、フェッチとデコード、スケジューリングが非常に長い。「HammerとAthlonのパイプラインの比較」を見るとわかる通り、Athlonの整数演算10段、浮動小数点演算15段より2ステージ多い。しかし、Pentium 4の20段と比べるとぐっと短い。
パイプラインの最初のL1命令キャッシュに対するフェッチは「Fetch(フェッチ)1/2」の2ステージ構成。Athlonではフェッチは1ステージだったため、L1命令キャッシュアクセスが、高クロック化の制約になる可能性があった。しかし、Hammerはここが2ステージになっているため、Athlonより原理的に高クロック化が容易になる。ただし、Fetch2は基本的には命令のトランジットステージらしい。
HammerのL1命令キャッシュはAMD伝統のプレデコード(pre-decode)キャッシュだ。つまり、可変長のx86命令の区切りや、どの命令が分岐命令かといった情報を示すプレデコードビットを、キャッシュに取り込む際に加える。このプレデコードビットで、各x86命令は識別される仕組みになっている。次の「Pick」ステージは、このプレデコードビットを使ってx86命令を、単純命令用デコーダ(DirectPath)とマイクロコードデコーダ(VectorPath)の2つのパスに選別するステージだと思われるが、MPFでは詳しくは説明されていない。
ちなみに、Athlonではさらにx86命令のキューである「Align1」というステージがこのあとにあったが、Hammerではこの部分のステージが減っている。そのため、フェッチからデコーダまではトータル3ステージでHammerとAthlonは変わらないように見える。MPFでプレゼンテーションをしたAMDのフレッド・ウェバー(Fred Weber)副社長兼CTO(Computation Products Group)は、「L1からデコーダへいかに命令を速く移動させるかが重要で、プロセッサではここが周波数向上の制約になっている」と説明している。つまり、L1からデコーダまでのステージもかなり改良され、その結果、フェッチステージは2段になったのに、デコーダまでのトータルのステージは3ステージに収まっていると思われる。
●謎のPackステージ
x86命令のデコードは次の「Decode1/2」の2ステージで行なわれる。Athlonではx86命令デコードは「Align2」ステージの後半と「Early Decode(EDEC)」ステージにまたがっていた。それに対して、HammerではDecode1/2の2ステージをフルに使っているらしい。これも、高クロック化に寄与する。
Hammerのパイプラインの最大の謎は、このあとの「Pack」ステージとそれに続く“3つ目”のデコードを含む「Pack/Decode」ステージだ。Weber氏はPackステージについては「個々のインストラクションをパックする」としか説明しなかった。また、次のDecodeステージについては、「この最終デコードで内部命令フォーマットに変換する」と説明した。また、White Paperでは「パイプラインのフロントエンドインストラクションフェッチとデコードロジックは、デコーダから実行パイプのスケジューラへのより高い度合いのインストラクションパッキングのために洗練された」と説明されている。今のところ、この部分は謎のままだ。
ただし、ある程度の推測はできる。まず、明らかなのは、Hammerのパイプラインがここに余計なステージを使っている以上、何か新しい要素があるということだ。AthlonではEDECステージでプロセッサの内部命令であるMicroOP(MOPS)に変換され、レジスタのリネーミングなどを行なう「Instruction Control Unit」のステージである「IDEC」に送られていた。それに対してHammerではおよそ次のような流れになっている。
・「Decode1/2」
↓
・中間命令?
↓
・「Pack」
↓
・パック化された命令
↓
・「Decode」
↓
・内部命令(uOP)
↓
・「Dispatch」
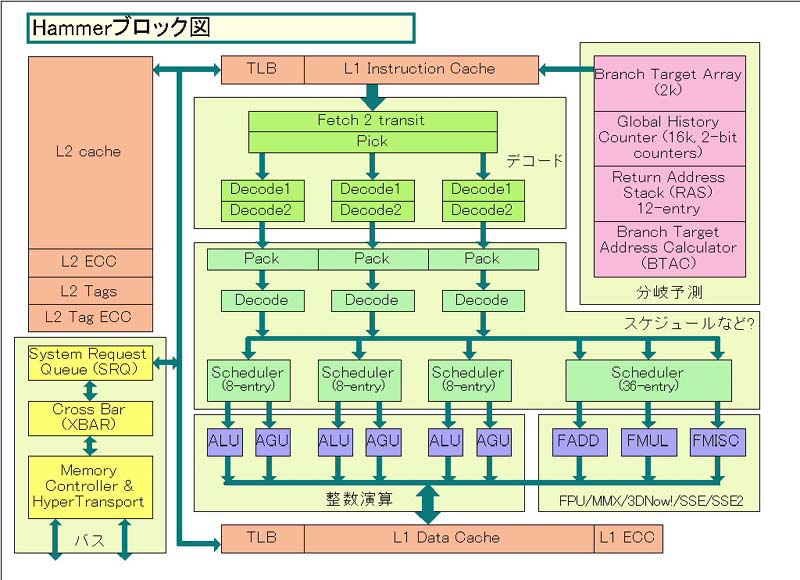
整数演算の場合、MOPに変換された命令が発行(ディスパッチ)される先は各実行ユニットペア(ALU&AGU)に命令を発行する「Scheduler」となる。このSchedulerは「Hammerブロック図」を見るとわかる通り、実際にはそれぞれが独立した8エントリの小Schedulerになっている。
 |
 |
| Hammerのブロック図 | Athlonのブロック図 |
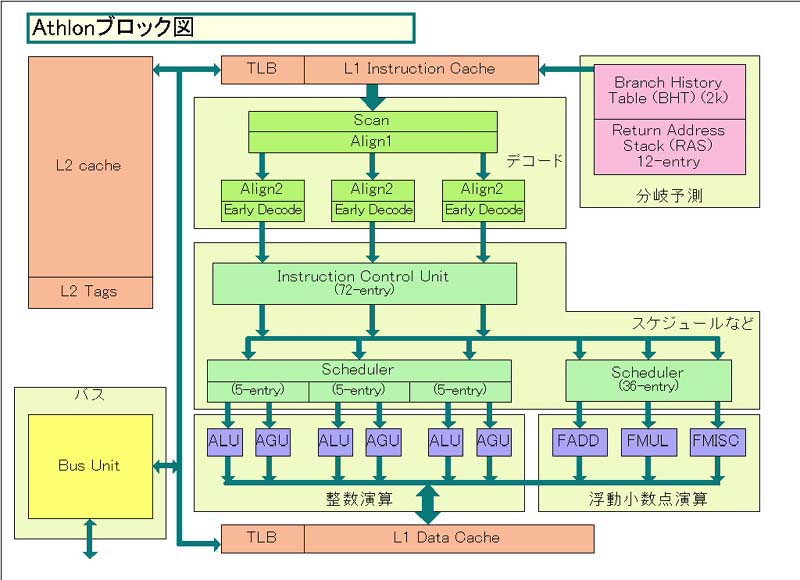
それに対して「Athlonブロック図」を見ると、この部分は統合された15エントリのSchedulerになっていたように見える。しかし、実際にはAthlonもここは各実行ユニットペア(ALU&AGU)毎に分離された5エントリのアウトオブオーダのキューになっていたという。つまり、実態はアウトオブオーダ発行が可能なリザベーションステーションになっていたわけだ。Hammerはこれが8エントリに拡張されたと考えることができる。
●Athlonより改善された? 命令発行効率
さて、Athlonの場合、x86命令のうちメモリアクセスを含む演算命令は、デコード段階で1個のメモリアクセスを含む演算MOPに変換されていた。これは、多くの最新プロセッサがデコード時に、メモリアクセスを含むx86演算命令を、メモリアクセスMOPとレジスタ間演算MOPの2つに分離する(ロード/ストアアーキテクチャ)のとは対照的だった。
もっとも、Athlonも実行時には、メモリアクセスオペレーションとレジスタ間演算オペレーションに分離している。そうしないと、実行に時間がかかり、命令の並列実行度が落ちるからだ。具体的には、Athlonでは、MOPはSchedulerに対して発行された段階で、メモリアクセスオペレーションとレジスタ間演算オペレーションに分離されている。これに対応するために、Athlonの演算ユニットはALUとAGUがペアになっていた。つまり、5エントリのSchedulerは、最大で10個のオペレーションを格納して、ALU&AGUペアに対してアウトオブオーダで発行することができるわけだ。
このアーキテクチャの意図は、内部命令発行の効率を上げて、演算ユニットの利用効率を上げることだ。3つのMOPは最大で6個のオペレーションを含む可能性がある。つまり、この手法によりAthlonは最大で6オペレーションの同時発行が可能になっていた。
AMDが命令のパッキングと言っているのは、こうした技術を指している可能性が高い。とすると、HammerではPackステージでよりアグレッシブにオペレーションの組み合わせや組み替えをやっているのかもしれない。もしかするとIntelのモバイルCPU「Banias(バニアス)」が採用するMicroOPsフュージョンも、似たようなアプローチなのかもしれない。いずれにせよ、命令発行の効率が改善されている可能性は高い。
というわけで、謎の多いPack/Decodeのあとは「Dispatch」ステージで、各SchedulerへとMOPが発行される。このあたりのステージでレジスタリネーミングが行なわれると見られる。整数演算の場合、次が、先ほど触れたアウトオブオーダのリザベーションステーションのステージと見られる「Scheduler」。そして、Schedulerから「ALU/AGU」ステージで実行ユニットペアに発行される。ロード命令の場合はAGUでアドレスを生成して次の2つのステージでL1キャッシュからデータをロードする。メモリアクセスまで含んで12ステージだ。ただ、もちろん現実的には、AGUとL1データの間にロードストアのキューもあるはずで、アクセス待ちでそれ以上かかる場合もありうる。
L2キャッシュアクセスの場合は、さらに8ステージが加わる。浮動小数点演算のパイプラインは今回は明かされていない。しかし、整数演算に対するレイテンシがAthlonと同じことから、ほぼ同じパイプライン構造と推測される。
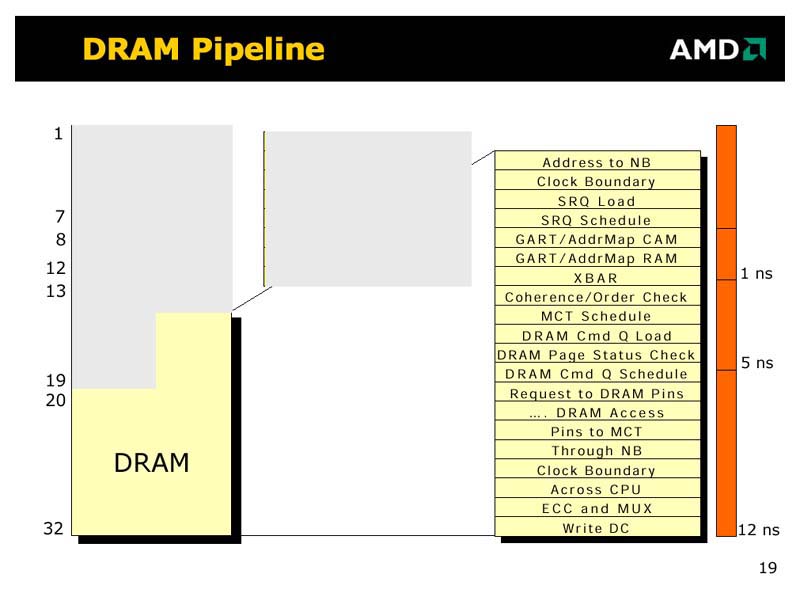
それから前回、DRAMアクセスの説明をしたが、次のプレゼンテーションシートがその図だ。ただし、このシートは妙なことに、Weber氏の話している内容とはステージ数が合わない。Weber氏の説明から計算すると、DRAMパイプラインではトータルで34ステージになるはずだからだ。
 |
(2001年11月2日)
[Reported by 後藤 弘茂]