
NVISION08レポート
PhysXやCUDAの最新状況を紹介
 |
| NVIDIA VP PhysX SolutionsのManju Hegde氏 |
会期:8月25日~27日(現地時間)
会場:米国カリフォルニア州サンノゼダウンタウン
NVISION初日は、基調講演が行なわれたのち、いくつかのテクニカルセッションが開催された。いずれも、それほど目新しい内容ではないものの、NVIDIAが現在取り組んでいる技術に関する概要が分かりやすく伝えられた。ここでは、GPGPUに関連したトピックとして、PhysXとCUDAのセッション内容をお伝えする。
●PhysXはゲームグラフィックの新たな開拓地
「Game Physics:The Next Frotier」と名付けらたセッションでは、NVIDIA Vice President PhysX SolutionsのManju Hegde氏が、GeForce PhysXの概要を紹介。セッションのタイトルのとおり「進化するゲーミンググラフィックにおいて、物理演算こそ次のフロンティアだ」として、ゲーム開発者にステップアップを呼びかけた。
GeForce PhysXに関しては、約2週間前に利用可能なすべてGPUに対応したドライバ(GeForce Release 177.83)がリリースされたばかり。また、ここ1~2カ月ほどは、かなり頻繁に将来的な対応ゲームタイトルのアナウンスが行なわれている。
例えば、カプコンのバイオニックコマンドーもその1つ。Manju氏は、'80年代以降のゲームグラフィックスを回顧するプレゼンを展開したが、ビデオゲーム開発の文明を知るためにも重要なことであるとして、バイオニックコマンドーの元となった2Dアクションゲーム(邦題:ヒットラーの復活)のデモを上映。この2Dゲームが主体であった'80年代の例として挙げられた。
そして、Open GLの「Quake」に端を発した3D一人称シューティングが人気を集めた'90年代から、3Dグラフィックスが本格化する。テクノロジーとしては、固定パイプラインによるレンダリングから、プログラマブルシェーダへと移り、現在は、グラフィックすべてをプログラマブルなものにする時代へと移りつつある。
Physics、およびPhysXについて、ここで詳しく紹介する必要はないだろう。今回のプレゼンでは、ボールの落下が例に挙げられたが、ボールを落としたとき、そのままストンと地上に落ち着いてはあまりに違和感がある。落とした位置に応じてバウンドしたうえで落ち着くのが普通だ。また、ボールの下に物があった場合、その物同士の干渉も考慮しなければならない。
リアルな3Dグラフィック表現がなされるようになってきても、物理表現が不十分であったために違和感を持つことは珍しくない。過去、ゲームデベロッパは、一部シーンでのみ物理表現を加えたり、まったく無視する、という大きく2つの手段を取ってきたというが、今後は物理表現がゲームグラフィックスにおいて非常に重要になると言われている。
そうした、物理表現のAPIとなるのがPhysXで、もともとはAGEIAが開発/提供していた。このAGEIAが2008年2月にNVIDIAに買収され、GeForceアーキテクチャのためのGPGPU開発プラットフォームであるCUDA上で動作するよう移植されたものが「GeForce PhysX」である。紹介が遅れたが、登壇したManju氏は、元AGEIAのCEOだった人である。
 |
 |
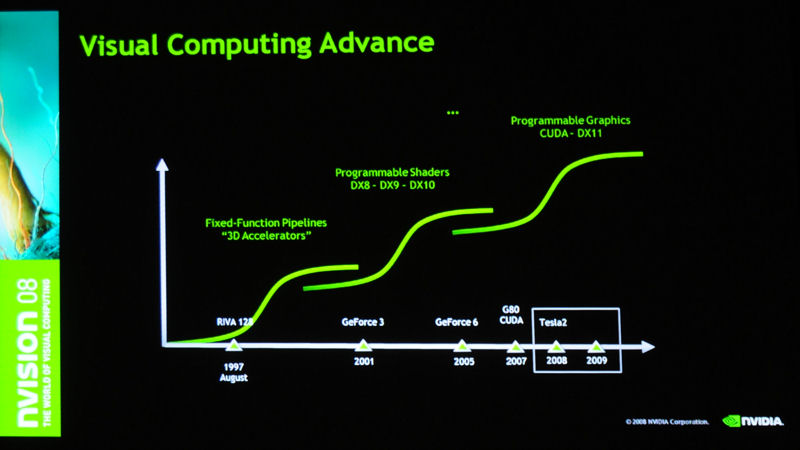 |
| カプコンから発売予定の「バイオニックコマンドー」の元となった「ヒットラーの野望」。'80年代の典型的な2Dアクションゲーム | 20年経過後にリメイクされたバイオニックコマンドーは、このようなリアルな3Dグラフィックゲームに生まれ変わった | 3Dグラフィックは固定パイプラインからプログラマブルシェーダの時代を経て、CUDAやDirectX 11のようなグラフィックすべてをプログラム可能な時代に移行しつつある |
GeForce PhysXは、CUDA 2.0上で動作するものであるが、PhysXエンジン自体は、ハードウェアの違いを変換して上位アプリケーションへ受け渡す“HAL”を介して、さまざまなプラットフォームに対応が可能となっている。API自体はすでにAGEIA自体から開発が進んでいるわけで、現状において大きなトピックとなるのは、このHALの下位で動作するGeForce用のPhysXドライバが出たところにあるわけだ。
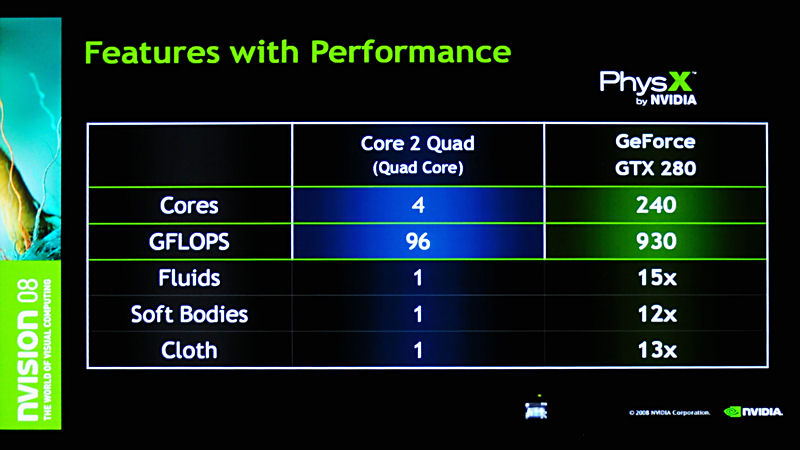
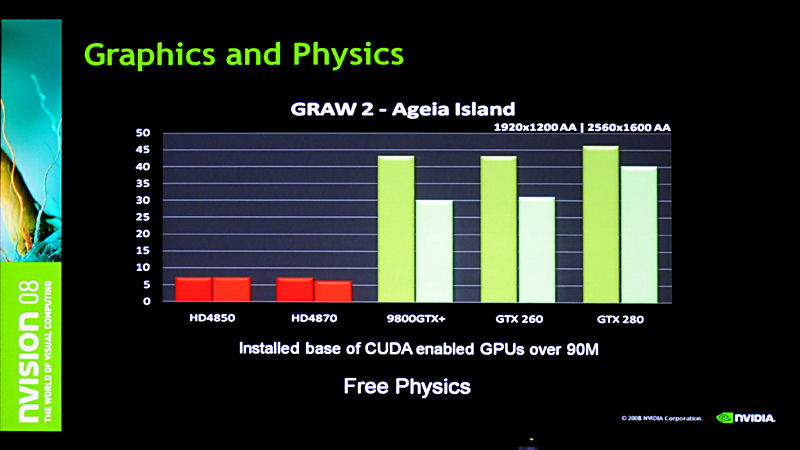
セッションでは、GeForce GTX 280とIntelのクアッドコアとでPhysXに含まれるAPIを用いて物理演算を実施した場合や、Radeon HD 4800シリーズとのパフォーマンス差も披露。そのアドバンテージをアピールした。
Radeon HD 4800シリーズはPhysXに対応しないため、どのパフォーマンスもGeForceとCPUとの比較ということになるが、例えば流体表現では15倍のパフォーマンスを発揮すると謳われている。コアの仕組み自体が異なるためコア数の比較はあまり意味を持たないものの、浮動小数点演算性能で十倍近い差があるため、こうした圧倒的なパフォーマンス差につながっている。
また、このGeForce PhysXはGPU内でグラフィックモードとGPGPUモードをコンテキストスイッチして利用できることから、1枚のビデオカードで3Dグラフィックスと物理演算の両方を同時に実行できる。また、このGeForce PhysXを利用可能なビデオカード(GeForce 8以降のGPUを搭載したもの)は9,000万個が出荷されており、ドライバはもちろん無料。そうしたユーザーに対して、“今あるものを使って無料で利用できる”ことも強くアピールされている。
 |
 |
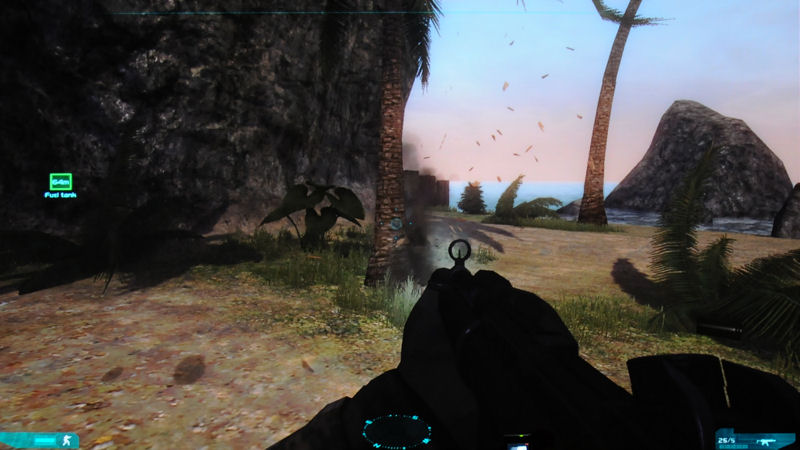 |
| PhysXのダイヤグラム。SDKの下位にHALレイヤーがあるおかげで、さまざまなプラットフォームで利用可能。SDKには、流体、布、ソフトボディなどのAPIが含まれる | クアッドコアCPUとGeForce GTX 280でPhysXのパフォーマンスを比較したもの。流体表現ではCPUの15倍の性能が出せるという | PhysXに対応した「Ghost Recon Advanced Warfighter 2」。木を銃撃すると破片が飛び散るなどの表現がなされる |
 |
 |
 |
| 「Ghost Recon Advanced Warfighter 2」のパフォーマンス比較 | セッション中に示された、さまざまなPhysXデモの1つ。ジェンガは典型的な物理表現の1つ | こちらは流体シミュレーション。こうした表現もコマ落ちすることなくスムーズに描画される |
 |
 |
 |
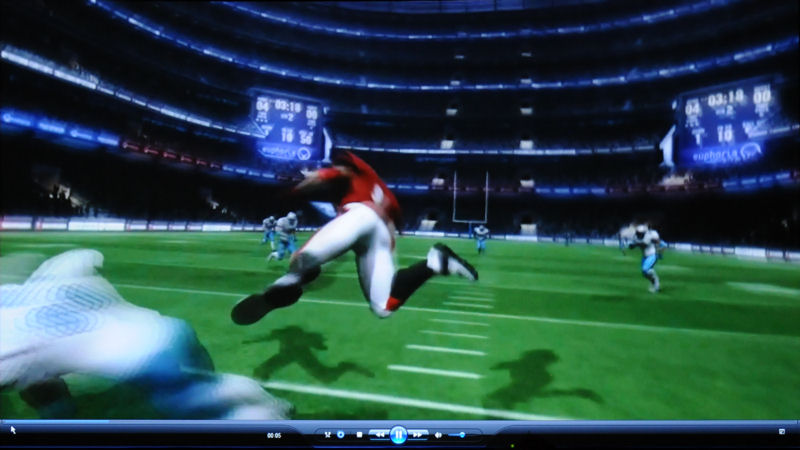
| 伊勢エビとラフレシアを合体させたような軟体動物。ソフトボディシミュレーションのデモである | 今年9月に発売予定の「Backbreaker」。アメリカンフットボールにおけるプレイヤー同士のぶつかり合いを物理演算によって表現している | 基調講演でも紹介された、Nurien Softwareのデモ。スカートの表現はPhysXに含まれるクロスシミュレーションを使ったものだ |
●ようやく正式リリースされたCUDA2.0
一方、GeForce PhysXのベースともなっているCUDAに関しては、この春にベータ版の提供が開始されたCUDA2.0が、NVISION開催のタイミングに合わせるかのように正式リリースされたという大きなニュースがあった。とはいえ、セッション自体はCUDA全般に渡る概要が示された程度となっている。このCUDAのセッションには、NVIDIA Chief ScientistのDavid Kirk氏が登壇した。
Kirk氏のプレゼンの冒頭、現在もっともポピュラーなトピックともなっているレイトレイシーングのデモを実施。これは、200万ポリゴンを利用した車のデモで、車の移動に応じて反射や光の屈折をリアルタイムに再現しているもの。中でも重要なポイントとして示されたのが、クリアなパーツが複雑に入り組んでいるヘッドライト部分で、クオリティを段階的に変更することで、現在におけるリアルタイムレイトレーシングのリアルさをアピールしている。
【お詫びと訂正】初出時にポリゴン数を「20億」と記載しておりましたが、「200万」の誤りでした。お詫びして訂正させていただきます。
このCUDAは、現在7万回程度のダウンロードを数え、最近は月に1万ダウンロードを記録しているという。その仕組みは、1つのアプリケーションを実行するCUDAカーネル内に多数のスレッドを持たせ、CPUよりも軽いウエイトでマルチスレッド処理が行なえるというものになる。アプリケーション(カーネル)間で共有するメモリも持っており、複数のカーネルで協力して処理を進めるといったことも可能になっている。現時点ではC言語向けのコンパイラしか提供されていないが、近々にC++、FORTRAN対応のコンパイラが提供される予定だ。
とくに、このCUDAは大学や研究機関などにおけるHPC(ハイパフォーマンスコンピューティング)用途での採用例が目立っている。日本でも東京大学や京都大学などで採用されているが、科学技術計算で使用されることが多いFORTRANサポートはユーザーからの要望も多かったと想像される。
ちなみに、Kirk氏にとって、CUDAを利用したアプリケーションでCPUの2~3倍程度の性能アップというのは、単なる高速化、に過ぎないという。そのために費やされるコストや手間などを考えれば、ムーアの法則に従った性能向上を待っても良いという考え方だ。5~10倍の性能向上で意義あるものと位置付け、ハードウェアの変更などを検討すべき段階。100倍を超える性能向上が得られる場合には、プラットフォームの変更やソフトウェアアーキテクチャを根本から見直した再コーディングなどを行なう価値が高いものとしている。
実際、CUDAにはCPUの100倍以上の性能を発揮するアプリケーションも存在しており、ムーアの法則を引き合いに出して、CPUは2年で2倍の性能向上を見せてきたが、CUDAを利用したGPGPUはそれを超える遙かに高いスピードで性能向上を見せていると主張した。
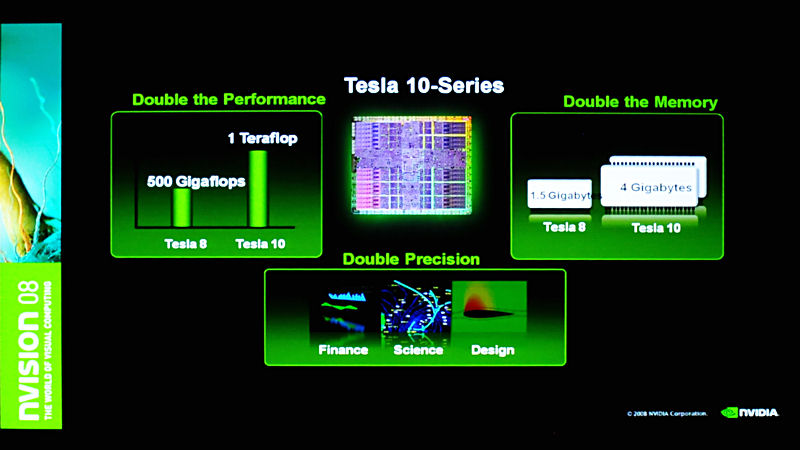
このCUDAを利用可能なGPUは周知のとおりGeForce 8シリーズ以降のGPUとなるが、NVIDIAではグラフィック出力機能などを省いたHPC用途向けソリューションの「Tesla」を展開している。G80世代のGPUを使った「Tesla 8」シリーズに続き、今年のGeForce GTX 280(GT200)リリースに合わせ「Tesla 10」を投入。GPU自体のアーキテクチャ見直し、スペックアップによる性能向上に加え、メモリ容量が最大4GBになった点、IEEE 754に準拠した倍精度の浮動小数点演算が可能である点などが主な特徴となる。
このTesla 10シリーズの事例としては、データセンターにおける利用方法を紹介。クアッドコアCPUのみを利用したシステムで100TFLOPSの性能を持つデータセンターを構築した場合と、クアッドコアCPUとGPGPUを併用したヘテロジニアス型システムを利用した場合とで比較。コスト、消費電力、そしてスペースの点で非常に優れた形で100TFLOPSのデータセンターが構築できるとした。実際に、こうしたGPGPUを利用したデータセンターを構築している例も多いという。
ちなみに、このTesla 10シリーズは、このデータセンターの事例で紹介された、GT200を4基搭載する1U型の「Tesla S1070」のほか、ビデオカードのような形状の1GPUタイプ「Tesla C1060」がリリースされている。
Kirk氏のセッションのラストでは、CUDAの次のステップについて紹介。現時点でCUDAは、C言語を用いて、GPGPUで実行するアプリケーションのコンパイルしか行なえない。先述のとおり、FORTRANやC++への対応を行なうほか、CUDAコンパイラからマルチコアCPUを利用可能するアプリケーションを書くことができるようになるという。従来はCUDAとマルチコアCPUのアプリケーションは別のプログラムで開発する必要があったが、これが実現すれば、マルチコアCPUとGPGPUを1つのプログラムで利用できるようになるわけで、NVIDIAが主張するCPUとGPUのそれぞれに合った処理を行なわせるという“ヘテロジニアスコンピューティング”が、より現実のものに近づきそうだ。
 |
 |
 |
| NVIDIA Chief ScientistのDavid B.Kirk氏 | NVIDIA Scene Graphを利用して作成されたレイトレーシングのデモ。ヘッドライト部分のクオリティを変化させて、レイトレーシングのリアルさを表現した | |
 |
 |
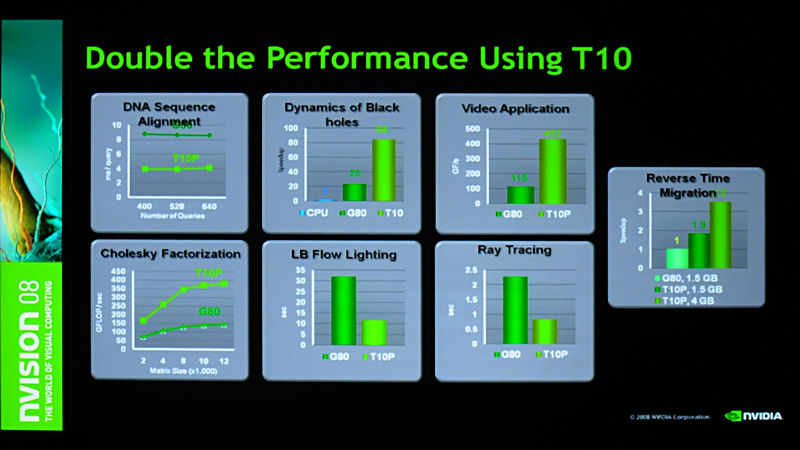 |
| 見慣れたプレゼンではあるが、CUDAによるパフォーマンス向上が得られるアプリケーションの種類。100倍を超えるものもあり、ムーアの法則を上回る性能向上と主張 | Tesla 10シリーズの概要。倍精度対応を含むGPUの違いのほか、最大4GBをサポートしたメモリ容量も大きな特徴 | Tegla 8シリーズと10シリーズで同じアプリケーションを実行したときの性能の違い。こうした性能変化にもメモリ容量の変化が大きく影響しているという |
 |
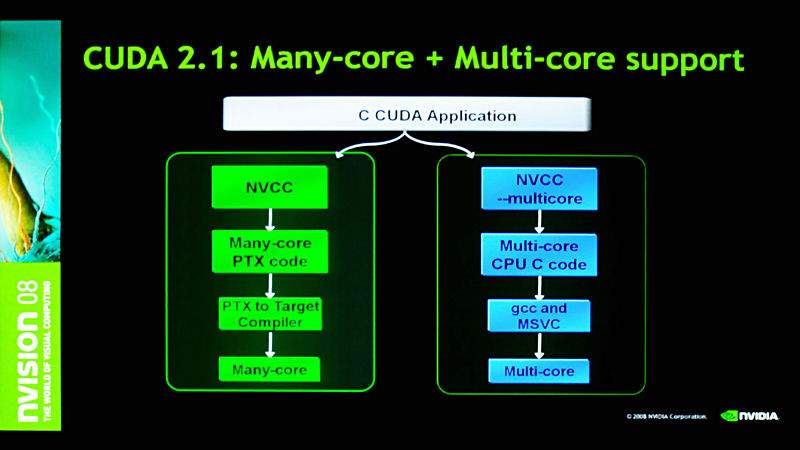 |
| Tesla S1070を使った、100TFLOPSの能力を持つデータセンターの構築。コスト、電力、スペースといった面で大きなメリットがある | CUDA2.1では、CUDAアプリケーションからマルチコアCPUを利用することが可能になる。実はCUDA2.0でこれが実現する予定だったはずなので、ちょっと後退したことになる |
□NVISION08のホームページ(英文)
http://www.nvision2008.com/
□関連記事
【8月26日】ペガシス、「TMPGEnc 4.0 XPress」にNVIDIA GPUエンコードを実装へ
http://pc.watch.impress.co.jp/docs/2008/0826/pegasys.htm
【7月23日】【多和田】コンシューマユーザーにとっても現実味が増す「GPGPU」
http://pc.watch.impress.co.jp/docs/2008/0723/tawada147.htm
(2008年8月27日)
[Reported by 多和田新也]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2008 Impress Watch Corporation, an Impress Group company. All rights reserved.