
MicroProcessor Forum 2007レポート
AMCCとARMの新プロセッサ
 |
| AMCCにおいてTitanのDesign Managementを行なったJoe Chang氏。前職はFreescale/Motolora、その前はIBMに在籍していたそうだ |
会期:5月21日~23日(現地時間)
会場:米カリフォルニア州サンノゼ
DoubleTree Hotel
今回はAMCCとARMの新プロセッサをご紹介したい。両者に共通するのは、意欲的な目標を現実的に収めたという点である。もっとも、そのアプローチはやや異なっているのだが。
●AMCC Titan
のっけから個人的な話だが、AMCCというベンダーにはある種の思い入れがある。いや、あんまりいい思い入れではないのだが、もう10年以上も前、当時はPCIバスマスタコントローラを自分で作るのは非常に困難であり、サードパーティからPCIバスブリッジを購入して利用するのが一般的だった。
ここでメジャーだったのがAMCCの、確かS5320か何かだったと思うのだが、ちゃんと動くものの、割と使いにくいデバイスだったと記憶している。しかも結構いい値段だった。今ではFPGAどころかCPLDですら大して手間がかからないPCI BusMasterの作成だが、10年も前だとこれが結構大問題だったりした。その当時から、AMCCはこうしたHigh-Speed InterconnectのPHYやMACを専門にしていた会社で、その方針は今も変わっていない。最近の製品ラインナップを見ると、Switched FabricやSATA RAIDのコントローラ、高速なEthernet PHYなどが主流だ。ちょうどマーケットポジション的にはMarvellと似たようなところを狙っているベンダー、という感じだ。
AMCCは、昨年(2006年)にはPower.orgに加盟してPowerPCコアのSoCの出荷を始めるといったニュースが流れているなど、このあたりも高速PHY専門からプロセッサコアを含む上位製品への移行を図るMarvellにちょうど重なっている感じだ。ただAMCCは伝統的にCPUコアにはそれほど強くなく、その結果AMCCは2004年にIBMからPowerPC 400シリーズの製品ポートフォリオを買収して自社製品として販売するという形を採っていた。そんなAMCCにとって初の自社開発プロセッサとなるのが、Titanだ。
そのTitanの狙いは“High performanc with lower power and lower cost”という、いい所取りを狙ったものだが、これはやや漠然としている(図2)。さらに、AMCCが上述のようにProcessorに関しては決して豊富なリソースを持っているわけではないから、汎用のIPやテクノロジを使うのは製品展開の上で欠かせないとしている(図3)。ただ同製品で採用するTSMCの90GTプロセスは性能は出しやすいしIPも豊富だが、その一方LP(Low Power)に比べればリークも少なくないはずで、消費電力の観点ではややディスアドバンテージとなる部分をどう料理するかが鍵になりそうな選択ではある。その消費電力に関しては、ターゲット周波数が決まったらあとは全ての要素を削るだけ(図4)という、わかりやすいが目新しいとは言いにくい主張だった。
 |
 |
 |
| 【図2】この話は別に珍しくない。というか、どんな会社も新製品に同じ事を言う。この矛盾した要求をいかに解決するかがDesignerの腕の見せ所なわけだが…… | 【図3】TSMCの90GTというのは、90nmのHigh Performance Process。身近な例では、nVIDIAのG80がやはりTSMC 90GTで製造されている | 【図4】一番利くのはVdd(トランジスタのコア電圧)だが、トランジスタ数の削減など他にも色々対処できる事はある、という話。変えられないのはF(ターゲット周波数)とI.leak(リーク電流:これはプロセスである程度決まってしまう)という話だ |
さて、特徴的なのはここからだ。図3に続く、もう少し明確な製品ターゲットをまとめたのが図5だ。2DMIPS/MHzのコアで2GHzまで動作し、マルチコアをサポートする製品で、しかも消費電力は2.5Wという、きわめて意欲的(というか、欲張りすぎ)な製品だ。この2.5Wという消費電力は、2005年のFall Processor ForumでP.A.Semiが発表したPA6Tが2GHzで7W、1.5GHz動作でも4Wだったことを考えると、かなりアグレッシブな目標と言える。これを実現するためにAMCCが採ったのは、ちょっと面白いアプローチだ。まず非クリティカルな部分は全てスタティックロジックで構成して駆動電力を削減し、クリティカルパスからはラッチを全部抜いてしまうことで低消費電力を可能にした、という話だ(図6)。
 |
 |
| 【図5】リーク対策も考えて、VddをTSMC 90GTの1.2V→1.0Vに落としたが、それなら初めから90LPを使えばという気もする。ただそうすると、使えるIPなどに制限があり、これを嫌ったのかもしれない | 【図6】ノーラッチだからといって非同期回路というわけではない。非同期回路ならば勿論低消費電力が狙えるというのはSPF2006におけるHandshakeの発表でも明らかだが、今度は高性能が狙いにくくなる |
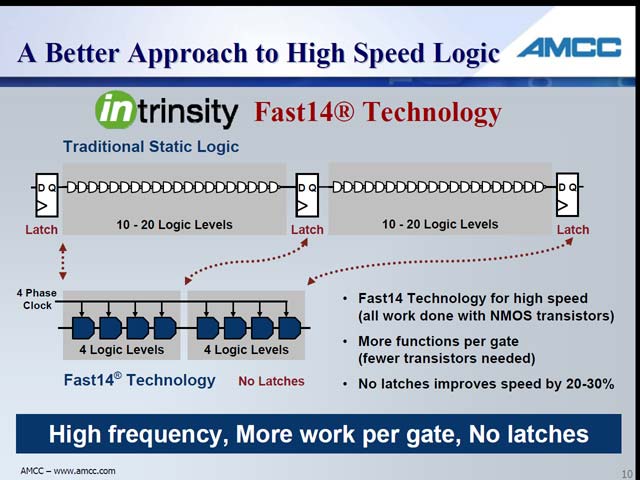
ではどうやってラッチを抜くか、ということで採用したのがintrinsityのFast14 Technologyだった(図7)。このFast14 Technologyというのは、同社のFastMIPS/FastMATHと呼ばれるCPUコアの設計の中で開発された技術を元にしたものだ。
FastMIPS/FastMATHはMIPSベースのプロセッサだが、ここで使われた技術を使ってPowerPCを作り上げたのがAMCCのTitanというわけだ。簡単にFast14 Technologyの紹介も行なわれた(図8)が、この技術の詳細はintrinsityのWhitePaperを見たほうがわかりやすい。
 |
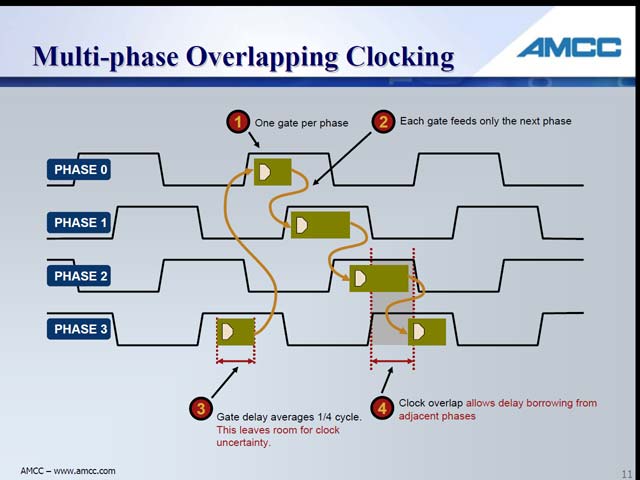 |
| 【図7】Fast14の概念図。まずLatchが存在せず(この時点で消費電力が大幅に減る)、更にデータの持ち方が通常と変わる関係で、ロジックの規模そのものが大幅に減るというメリットもある。もっともその分配線層は増えるのだが | 【図8】4分の1cycle刻みで各ゲートが動作する形になる。なので、各GateのDelayを平均4分の1cycle以内に抑える事で、ラッチをいれずにスムーズにロジックが構築されるという仕組み。 |
□intrinsityのWhitePaper(PDF)
http://www.intrinsity.com/templates/intrinsity/images/docs/Intrinsity_Fast14_Technology.pdf
特徴としては
・4フェーズの位相クロックを使っており、このクロックのオーバーラップタイミングを使ってゲートのアクセスが行なわれる関係で、ラッチが不要
・1-or-N Dynamic Logic(NDL)と呼ばれる、独自のデータの持ち方をすることで、回路規模を大幅に削減する
・NMOSトランジスタのみを使うことで、消費電力を減らす
・Expert Routing Technologyと呼ばれる独特な配線技法により配線の効率化を図る
といった事が挙げられる。(同社の主張によれば、他にも設計の容易化やEDAツールとの親和性が優れているとしているが、このあたりは上述のWhitePaperを参照されたい)。
このFast14は小規模な回路には最適だが、大規模なロジックにはあまり向いていない。例えばクロック。ユニファイドクロックを使う従来のCPUであっても、配線遅延に起因するクロックの位相差が大問題になっており、それゆえクロック信号のメッシュ化や、Tree Distributionによる配線均等化などのTrialが行なわれているわけだが、今度はこれが4フェーズになるわけで、大規模回路に適用するためにはハードルがかなり高いことが容易に想像できる。こうした事を考えると、Titanのロジックは、それほど複雑なものは採用できないことになる。
そのTitanの内部構造は図9のようになっている。Out-of-OrderかつSuperScalarといいながら、整数で7~10stage程度の、こじんまりとしたパイプラインだ。ただ先頭のIC(Instruction Cache)~DS(Dispatch)までの3段は、内部を更に細分化して、早いタイミングで依存性チェックとその解消を図っているという説明があった(図10)。そういうわけで、パイプラインは1GHz未満のCPUとしか思えないほどにシンプルだ(図12、13)。要するにTitanは、1GHz未満で動作する、2 DMIPS/MHzのプロセッサを、Fast14 Technologyの力で2GHz駆動したもの、と考えるのが妥当なのだろうと思う。
 |
 |
| 【図9】先に出たP.A.SemiのPA6Tの場合、Issue(Titanで言うところのDispatch)までで9stage、整数演算で12stage程度の段数になっており、半減とは言わないまでも3分の2程度の規模だ | 【図10】このあたりがラッチのない事の強みだろう。同じ事を従来のロジックで実装すると、結局パイプラインが無駄に細分化されることになってしまい、レイテンシが増えてBranch Penaltyが大きくなってしまう(し、消費電力も増える) |
 |
 |
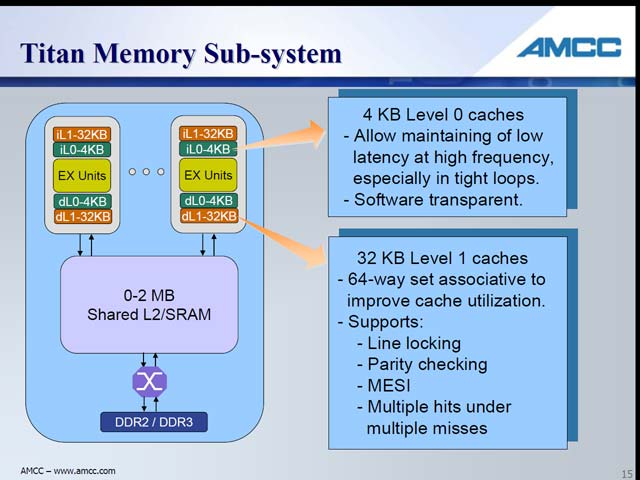 |
| 【図11】L0 Hitではたったの7cycle。L0 Miss/L2 Hitのペナルティは 3cycleとなっている | 【図12】流石に分岐命令やloadはもっとcycle数が掛かっている。とはいえ、それでもかなり短い方だと思う | 【図13】その分、L1キャッシュは64-way set associativeにLine Lockなどを備えた豪華なもので、レイテンシが大きいのも仕方ないと思わせるものがある。逆に恐らくL0は単なるLRUを実装しているだけだろう |
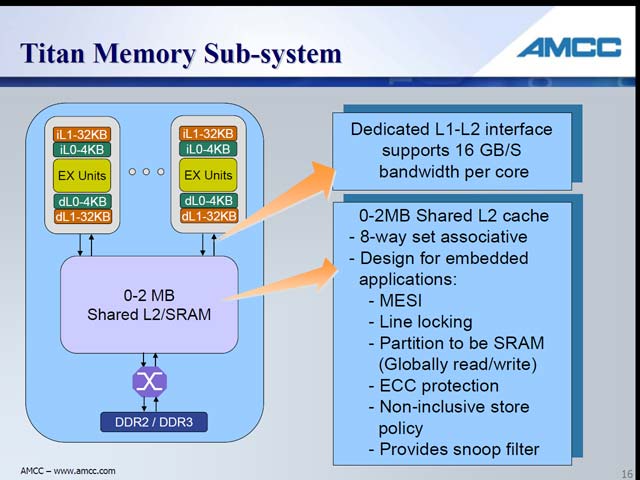
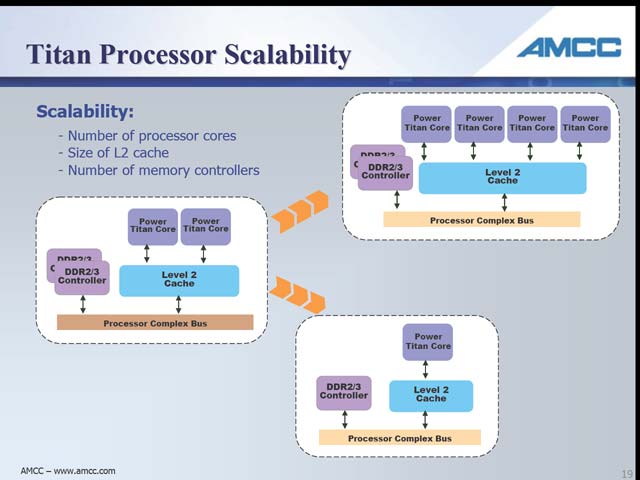
そうはいっても細かな工夫はちゃんと入っている。まずはL0 キャッシュの存在(図13)。恐らくは単なるWrite Throughのキャッシュだと思うが、L1のレイテンシがやや大きい事をこれで補えるようにしている。考え方としてはARMで使われていたMicroTLBなどと同じで、平均的なレイテンシ削減に効果があると思われる。一方L2はコア外部に共有キャッシュとして搭載されるが、このL2はコアの半分の速度で動作する。恐らくこれを等速にすると、その消費電力だけで馬鹿にならないことになるから、という事であろうが、これはなかなか賢明だ(図14)。またデュアルコアのみならず、シングルコアやマルチコアなどの構成も考慮されているという(図15)。今回はデュアルコアのフロアプランも示され(図16)、設計がかなり進んでいることを示した。ちなみに数カ月以内にはまずSoCのIPとして提供を開始し、来年(2008年)には製品が登場する予定だという。
 |
 |
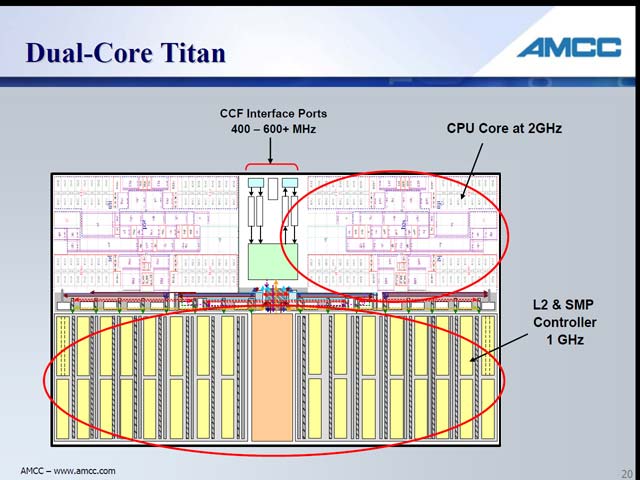 |
| 【図14】必要ならL2はSRAMも使えるというあたり、かつてのPentium IIIやAthlonを彷彿とさせる。ところでこのL2に“Non-inclusive store policy”とある。これに関しChang氏は「IntelのLyer氏はNCIDが有望だと話したが、我々は既にこれを実装している」としており、Snoop Filteringの機能も搭載していることを明らかにした。こういうあたりは、実に小技が効いている事を感じる | 【図15】L2が外に出ているのは、特にI/O Processorには有利な特徴だ(SoCの形で集積された周辺デバイスから、CPUを介さずにDMAで直接データを転送できる)。ちなみにL2へのレイテンシはきわめて少ない。先にL1が5cycleと示したが、L2へはたったの7cycleだ。もっともこのcycleはあくまでL2でのcycleであって、CPUは倍速(というか、L2が2分の1倍速)なので、CPUからみると14cycleということになるが。ちなみに最大何コアまで可能か、は今回明らかにされなかった | 【図16】ダイサイズ全体は明確にされていないが、「ロジック部」(つまりCPU Core 1つ分)は90nmプロセスでわずか1.6平方mmだとされる。そこから考えると、ダイサイズ全体でも7~8平方mm程度で収まりそうだ |
このTitanは、既存のPowerPC 440の全ラインナップを置き換えることが可能なだけの性能と特徴を持ち合わせているし、実際そうしたことを狙って設計が行なわれたのだろうと想像される。
ところで今回明らかにされなかったのは、このPowerPCコアがどのStandard、つまりPowerPC ClassicなのかPowerISAなのか、PowerISAならBook 3eなのかBook 3sなのか、という点。個人的には、まだPowerPC Classicベースで作られているのかもしれない気がする。というのは同社の現在の製品ポートフォリオが全部PowerPC 400シリーズをベースにしており、これらは全てPowerPC Classicベースとなっている。PowerPC ClassicとPowerISAでは、FPUやSIMD命令もさることながら、特にメモリ管理が全く異なっており、従って従来のインフラがそのままでは利用できない。組み込み向けという事を考えると、このあたりの互換性を維持するという判断を下しても不思議ではないからだ。このあたりが明確になるのは、最短でもIPの出荷が始まる今年後半だろう。
●ARM Cortex-M1
 |
| 発表を行なったDirector of Technology, Processor Division, ARM LtdのIan Devereux氏 |
今回ARMは2つの発表を行なった。1つはARM v7のマルチプロセッサ拡張であり、もう1つはFPGA上で動くCortex-M1の発表だ。
そもそもFPGAの上で動くARMコアは既にいくつかある。2000年にはAlteraがExcaliburという、ARM922Tをハードコアで集積した製品を出しているし、最近では2005年にActelが同社のProASIC3シリーズで動作するARM7のソフトコアであるCoreMP3の提供を始めている(*1)。他にも細かいものはいくつかあったと記憶しているが、いずれも主流にはなっていない。理由はいくつか考えられる。Excaliburの場合はハードコアであり、FPGA自身の選択の自由が非常に乏しかった。Actelの場合、ARM7というあたりがネックになったと考えられる。
ただし、FPGAでCPUを使う、というニーズ自体は確実に存在している。それはAlteraのNIOS/NIOS IIやXilinxのMicroBlaze/PicoBlaze、あるいはActelのCoreABCやLEON(関連記事参照)などを提供していることでも、これはわかる。こうしたマーケットニーズに対するARMの解が、Cortex-M1だ。
Cortex-M1は、FPGA用のソフトコアという形で提供される。である以上、例えば性能はいいけどプログラマブルエリアの9割を占有します、などでは使い物にならない(図18)。もう1つは、どの命令セットをサポートするかだ。ARMは従来のARM ISAの他に16bit縮小命令セットであるThumbを強力に推しており、2003年には16/32bitをシームレスに混在できるThumb-2を発表、翌2004年にはこれを搭載したCortex-M3をリリースした。このどちらを使うべきか、というのが最初の問題だ。
 |
 |
| 【図18】普通に考えればCortex-M3相当の16bit MCUの方がFPGA混載には向いている。ただ、割り込み処理がThumb-2にない、というあたりがちょっと問題だ | 【図19】ARM7TDMIのThumbを完全サポートというのは、おそらくActelのCoreMP3が存在することが影響したのだと思われる。CoreMP3は上にも書いたとおりARM7ベースのコアで、これを使ったアプリケーションがそのまま移植できることを狙ったものと考えられる |
これについて、ARMはCortex-M3のサブセットを新たに定義することにした。サブセット、というのはCortex-M3はThumb2に加えて、ARM V7のシステム命令をフルサポートしているが、これを全てインプリメントするのではなく、FPGAのコントローラとして最低限必要なもののみをサポートする、というアプローチだ。この最低限必要、というレベルがどの程度かに関する考察が図20だ。FPGAの上で動く、というのであればその上で本格的なOSが動く可能性は非常に少ない。普通に考えればFPGAで構築したデバイスのコントロールが主用途だから、基本的にはタスクが1個廻っている程度で、それにInterrupt Handlerがあれば十分という程度だろう。要するに古のMS-DOSと同程度の事が実現できれば十分、という判断であろう(図21)。OS ExtentionはSystem Timerを使って複数のプロセスを実行できるとしている。これ以上のもの、例えばKernelとUserの分離などを必要とするケースはFPGAソフトコアでは不要という判断であろう。
 |
 |
| 【図20】それでも4レベルで合計32の割り込みがハンドリングできれば十分だろう。それでもアプリケーションの要件上、もう少し丁重なハンドリングが、というケースではOS Extentionが提供されるが、これはエリアのペナルティを伴うことになるだろう | 【図21】OSが存在しないから、結局割り込みがあるとISR RoutineをCallするだけのインプリメントとなる。それでもちゃんとAuto Save/Restoreが働くから、ISR Routine exit後には元のルーチンに復帰する |
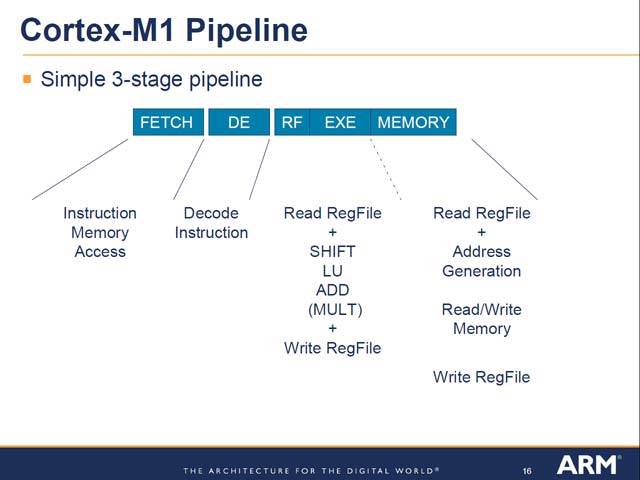
実際のインプリメントだが、実に3-stageのパイプライン構成で、限りなく小さくまとまっているのが特徴だ(図23)。パイプラインの内部はきわめてシンプル(図24)で、これなら分岐ミスのペナルティも少ないからBTBだの分岐予測も不要だろう。もともとFPGAでの動作だから、動作周波数は200MHzに届かない程度だろうし、それであれば下手をするとメモリとコアが等速で動くので、あれこれ細工をしなくても良いという判断なのかもしれない。もっとも性能を見ると、やはりIPCはやや落ちている事がわかる(図25)。さすがにシンプルすぎるのかもしれないが、その分動作周波数を上げられることで補っているのだろう。加えて言えば、ARM7TDMIの場合、ARMv4 ISAでは0.95 DMIPS/MHzだが、Thumb-1では0.74 DMIPS/MHz程度でしかないので、むしろCortex-M1の方が高速という考え方も出来る。結果として、従来よりも遥かにパワフルなSoft Coreが出来上がったとも言える。加えて言えば、Xilinx/Altera/Actelという大手FPGAベンダー全てで動作するという互換性の高さも、大きな魅力となるだろう。
 |
 |
| 【図22】MS-DOSがMP-DOSやCCPM/86に進化した程度だろうか? それでもプロセス別にInterruptを分離できるのは立派。本格的なOSをインプリメントするにはちょっと覚束ない程度ではあるが、普通に考えればこれで十分だろう | 【図23】Tightly coupled instruction and data memories(TCIM/TCDM)は、要するに命令/データキャッシュの代わりとして動くもの。Cortex-R4などでも利用されている。 |
 |
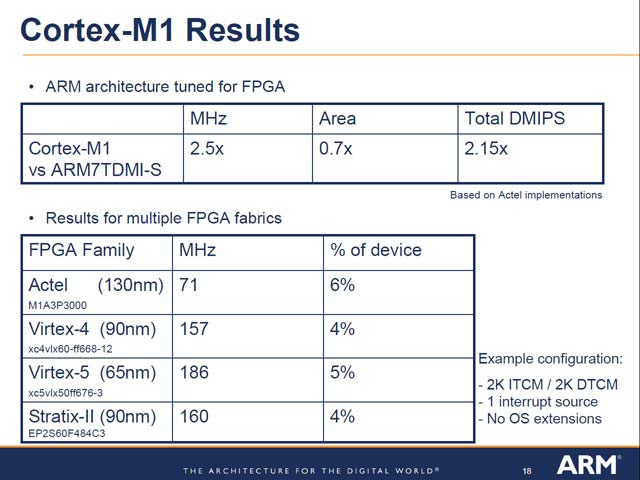 |
| 【図24】16bitのCPUとしても、やや短めに感じるパイプライン。まぁ複雑な命令がないから、Executeが1stageで済むという話だろう | 【図25】ARM7TDMIが概ね0.95 DMIPS/MHzなのに対し、Cortex-M1は0.8 DMIPS/MHzまで性能が落ちている。ちなみに元になったCortex-M3は1.25 DMIPS/MHz程度だ。ただCortex-M3のターゲットは、例えば0.18μmプロセスで50MHzくらいだから、トータルの性能で言えばCortex-M3がむしろ上回るケースもあるだろう |
Cortex-M1が魅力的な製品に収まった大きな要因は、やはり割り切りであろう。Thumb-2のみをサポートする事でデコーダや実行ユニットはシンプルに収まったし、FPGA上の動作ということでTCM以外にはほとんど高速化のトリックは見当たらないが、これがかえって動作の高速化を促している。もっとも、FPGAの高性能化に助けられた部分も少なくはないのだろうが。とりあえず今回のMPFで発表された中では、一番シンプルかつ美しいと感じたのが、このCortex-M1だった。
(*1) AtmelはまさにこのMPFの期間にあわせて、ARM9ベースのコアを統合したFPGAである AT91CAP9Sを発表するという不思議な動きをしている。まぁCortex-M1は16bit Solutionだから、32bit Solutionが必要なケースではこちらの方が良いのかもしれないが。
□Microprocessor Forum 2007のホームページ(英文)
http://www.in-stat.com/mpf/07/
□関連記事
【5月30日】【MPF】ARMv7のマルチプロセッサ拡張
http://pc.watch.impress.co.jp/docs/2007/0530/mpf06.htm
【2006年5月26日】【SPF】新アーキテクチャやクロックレスなど話題の多いARM
http://pc.watch.impress.co.jp/docs/2006/0526/spf07.htm
【2005年5月30日】【SPF】さまざまなDSP搭載プロセッサ(その2)
http://pc.watch.impress.co.jp/docs/2005/0530/spf06.htm
(2007年5月31日)
[Reported by 大原雄介]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2007 Impress Watch Corporation, an Impress Group company. All rights reserved.