
MicroProcessor Forum 2007レポート
【Intel編】
高速化をもたらすRadix-16 DividerとSuper Shuffle Engine
 |
会期:5月21日~23日(現地時間)
会場:米カリフォルニア州サンノゼ
DoubleTree Hotel
Microprocessor Forum(MPF)は、米In-Statが開催するプロセッサ関連のカンファレンスイベントである。昨年(2006年)までは、春と秋の2回開催で、春は組み込み系、秋は汎用プロセッサ系と分かれていたが、今年からは年1回の開催となり、両分野を同時に扱うようになった。
今回のカンファレンスプログラムをざっと概観すると、初日が汎用CPUと組み込み系のAutomotive関連のプロセッサ、2日目にメディア系や組み込みの通信系プロセッサなどが扱われる。
●IntelがPenrynなどの概要を報告
まずは、IntelのMark Bohr氏による「The New Era of Scaling for Energy Efficient Processors」と題した基調講演が行なわれた。その内容は、4月に北京で開催されたIDFでのBohr氏のスピーチとほとんど重なるものだった。
最初のセッションである「Advances in Computer Technology」を担当したのはIntelのMark Bohr氏で、以下の3つのテーマについてスピーチが行なわれた。
(1)45nm Next-Generation Intel Core Microarchitecture(Penryn)
(2)Beyond Multicore: The Dawning of Era of Tera
(3)Reinventing Multicore Cache & Memory: Architecture, Performance and QoS
(2)は、昨年のISSCCで発表された「Teraflops Research Processor」のリピートである。
(1)では、今回新たにPenrynの除算器に関する情報などが公開された。すでにニュースなどでは、「Radix-16 divider」が搭載され、割算が高速化されたことが報じられている。今回のカンファレンスでは、その概要が公開された。
 |
 |
 |
| 初日最初の基調講演を行なうIntel Senior Fellow、Technology and Manufactureing Group Director、Process Architecture and integrationのMark Bohr氏 | Penrynのアーキテクチャについて解説するSteve fischer氏(Senior Principal Engineer) | メニイコア時代のキャッシュやメモリについて話したのはRavi Lyer(Principal Research Scientist)氏 |
●高速化を実現するRadix-16 Dividerとは?
割り算を行なう回路(除算器:Divider)の実装方法にはいくつか種類があるが、主に使われるものとしては「減算シフト」、「乗算型」などがある。前者は、各桁の計算を行なうときにシフト処理と加減算の組み合わせで処理を行なうもので、後者は、掛け算を使う方法である。
Radix-16 Dividerは、その構造から「減算シフト型」に分類されると思われる。この場合、高速で加減算処理を行なう必要がある。割り算とは、割られる数(非除数)の中に割る数が何個含まれているかということである。たとえば10÷2の商は
10=2+2+2+2+2
10=2*5
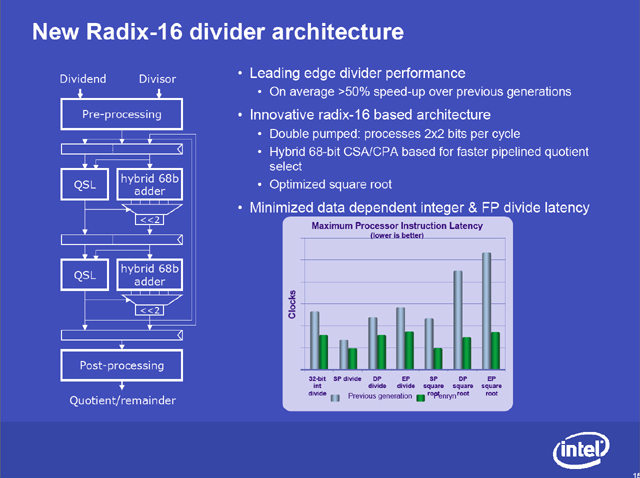
ということから5と求められるわけだ。このように割り算は、足し算や掛け算を繰り返して計算することができる。しかし、大きな数では、商を見つけるのが大変である。このため、人間が行なう筆算のように割り算を各桁ごとに処理している。このとき、何ビット同時に行なうかで、計算時間が変わってくる。Radix-16 Dividerとは、一度に2進数で4桁(4bit)の計算を行なうものだ。Radix-16とは「基数16」という意味で、一度に4bit処理することから「基数16」と名付けられている。
従来のMeromでは、Radix-4、つまり2bit単位で計算する除算器が使われていた。このためRadix-16 Dividerを使えば、2倍程度の高速化が行なわれることになる。
桁数が増えると全体の計算は速く終わるが、計算する回路が複雑になる。そのために通常は1または2bitで計算する回路が使われることが多い。
 |
| PenrynのRadix-16 Dividerは、4bitを1クロックで処理できるため、従来のRadix-4 Dividerよりも倍の性能を持つ |
北京で開催されたIDFで、Mobile Platforms GroupのGeneral ManagerであるMooly Eden氏は、PenrynでなぜRadix-16 Dividerを実装したのかと聞いたところ、その実装には必要なトランジスタ数が多く、今回ようやく、これを実装できるだけのトランジスタを確保できたからだという答えが返ってきた。つまり、これまでは、こうした改良をしたくとも、回路規模が大きすぎて困難だったわけだ。
具体的には、Radix-16 Dividerは、2段階のループ構造になっていて、1回のループで4桁(4bit)の部分割り算を行なえるようになっている。
中心になるのはHybrid Addrと呼ばれる加算機である。加算機には、繰り上がり(キャリー)の処理でいくつかのタイプに分類される。最も簡単なのは、キャリーを考慮して、下の桁から順に加算を行なうもので、キャリー伝搬型(Carry Propagation Adder:CPA)である。コンピュータなどでは、高速化のため、繰り上がりの有無と加算処理を別に行なう、キャリー・ルックアヘッド型が使われることも多い。
しかし、くり返し計算を考慮すると、必ずしも桁上がり処理を一度に行なう必要がなく、あとでやってもいい。こうしたものには、キャリー保存型(Carry Save Adder:CSA)がある。
Hybirid Adderとは、こうした複数タイプの加算器を組み合わせたものを指す。Penrynに採用されているのは、CPA/CSAを組み合わせた加算器だという。
こうした構造を持つため、割算の処理時間は、計算する数によって違いが出る。しかし、従来よりも桁数が増えているため、Radix-16 Dividerでは、同じ数を計算したときの計算時間(クロック数)が短縮される。特に最短クロック数も小さくなり、Penrynでは最短6サイクルで除算が可能だという。
Dividerは、整数演算や浮動小数点演算で利用され、このためにSSE命令などが高速化される。特にSSE関連では、複雑な計算が多く、割算を内部的に利用しているため高速化が期待できる。今回のRadix-16 Dividerでは、開平(ルートの計算)に最適化されているという。ルート計算は、2次元、3次元のグラフィックスや物理計算などで頻繁に利用されるため、これが高速化されると、メリットは大きい。
Intelが公開している資料によれば、倍精度浮動小数点(64bit)と拡張倍精度浮動小数点(80bit)の処理時間がほぼ同じであるため、浮動小数点の場合、拡張倍精度で計算を行ない、そこから倍精度の結果を得ているようだ。
もう1つの高速化のポイントはSuper Shuffle Engineである。SSEなどのSIMD型の命令では、連続したメモリ領域に複数のデータを配置し、ひとまとまりとして扱う。このとき、計算によっては、計算途中でbit位置を入れ替えるなどの処理が必要となる。Penrynは、こうした処理を1サイクルで行なうために、128bitの2つの数値中にあるbitの選択や入れ替えなどが可能なSuper Shuffle Engineを装備している。これにより、命令の最短実行時間が短縮されている。
IA-32には、メモリ内の数値をxmmレジスタへ転送する命令が2種類ある。1つは、メモリ内の数値が16バイト境界に並んでいることを前提とするmovapsと、そうでないことを許容するmovups命令である。moveaps命令は、データが16バイト境界にあることが前提となるため、高速だが、アライメントが正しくないアドレスを指定するとエラーになってしまう。逆にmovupsでは、アライメントは任意だが、その分実行時間が遅くなる。このとき、PenrynではSuper Shuffle Engineによりmovups命令が高速化されるという。
●メニイコア時代のキャッシュとメモリ
非常に多数のコアが利用できるシステムで、どうやってコアの稼働率を向上させるかには、大きく2つの手法がある。1つは、非常に多くのスレッドを使うアプリケーションを動作させる方法である。しかし、どんなアプリケーションでも多数のスレッドが必要になるわけではないし、スレッドを多く生成するようなアルゴリズムを採用してアプリケーションを開発する必要がある。
もう1つの方法は、多数の仮想マシンを動作させる方法である。各仮想マシン内で実行されるオペレーティングシステムやアプリケーションは、従来型のシングル~クアッドコア程度のシステムを想定したものでかまわない。より多くの仮想マシンを同時に動作させることで、コアの効率的な稼働が可能になる。
こうした状況を考えると、メモリやキャッシュの構造について考え直さねばならない、というのが最後のセッションである「Reinventing Multicore Cache & Memory: Architecture, Performance and QoS」のテーマである。
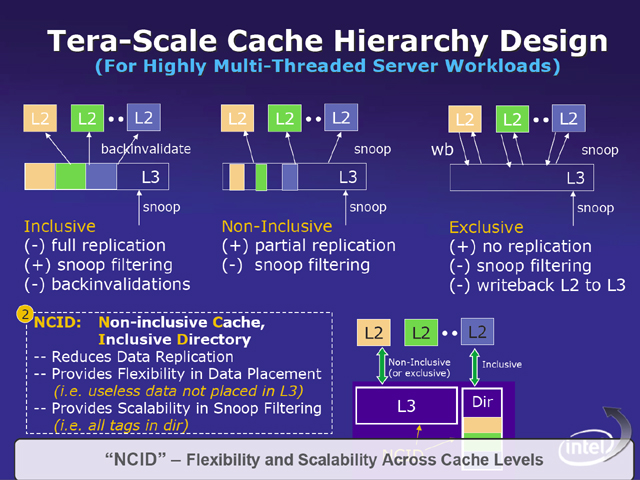
話は、多数のスレッドが動作する単一環境の場合と、多数の仮想マシンが動作する環境を分けて行なわれた。まず、多数のスレッドが動作する環境の場合、階層化されたキャッシュに問題が生じるという。L1~L3などの階層化されたキャッシュの場合、2次キャッシュに記憶されているデータを3次キャッシュにも置くかどうかで3種類に分類される。1つは、2次キャッシュに置かれたデータもそのまま3次キャッシュに保持する「Inclusive」、もう1つは、2次キャッシュに置かれたデータは3次キャッシュには保持しないが、データのセットとしては、2次キャッシュに入らないものを3次キャッシュに保持しておく「Non-Incusive」である。最後の1つは、必要なデータセットをすべて2次キャッシュに置き、不要になるまでは3次キャッシュへ移さない「Exclusive」である。
それぞれ、キャッシュメモリの利用効率、他のプロセッサからのスヌープ(データの同一性を確保するためにキャッシュ状態をお互いにチェックすること)、データの書き戻し処理や、3次キャッシュが2次キャッシュ側の変更を調べる処理(Backinvalidations)でメリット、デメリットがある。
多数のスレッドが動作するということは、多数のデータセットが同時に利用されることになるため、キャッシュの利用効率を上げる必要があり、また、スヌープ処理や書き戻し処理を簡単に行なえなければならない。
 |
| 多数のスレッドが同時実行されるときの効率的なキャッシュ方式としてNCID(Non-inclusive Cache,Inclusive Directory)が研究中だという |
こうした状況に対してIntelが研究しているのがNCID(Non-inclusive Cache,Inclusive Directory)である。これは、キャッシュするデータはNon-Inclusiveとするが、キャッシュデータと実メモリの対応を記憶するDirectoryは3次キャッシュ側で共有するもの。これにより、2次キャッシュに含まれるデータは、3次キャッシュに記憶されないために、利用効率が上がり、外部からのスヌープに対しては、3次キャッシュ側のディレクトリを使ってスヌープフィルタリング対応が可能になる。
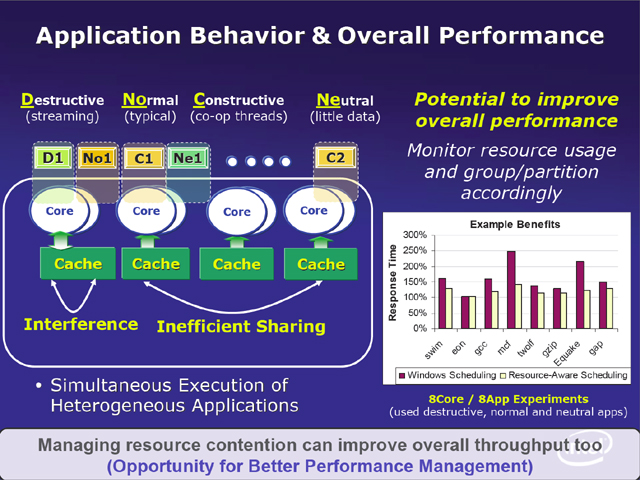
複数の仮想マシンを動作させる場合、物理的なCPUコアとスレッドの関係が成り立たなくなる。スレッドが見るのは、仮想化されたプロセッサとなる。このため、従来はOSが管理できていた、アプリケーションの動作タイプとプロセッサの対応が困難になる。そうなると、たとえば、キャッシュがほとんど有効に使われないストリーミングデータ処理を行なうスレッドと、通常スレッドが同じプロセッサで動作してしまう可能性がある。その他、複数スレッドがデータを共有のに、それぞれが別のプロセッサパッケージで実行されてしまう可能性がある。この場合、キャッシュが有効に利用できなくなる。
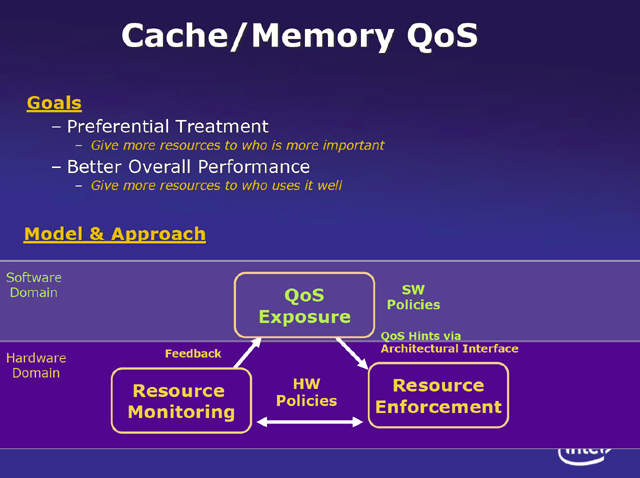
そこでアプリケーションに対して、QoSという概念を導入し、これを元にリソース割り当て(キャッシュやプロセッサ割り当て)を制御しようというのが、Intelの研究である。つまり、実行されるスレッドがどのようなタイプなのか(どのような割り当てを要求しているか)を仮想マシンマネージャなどに伝えるルートを作り、また、スレッドの動作パターンをハードウェアでモニターする。全体を管理する仮想マシンマネージャなどのソフトウェア側は、アプリケーションからの要求と、動作モニタからの情報を元に割り当てを制御するわけだ。
具体的な方法の1つとして、QoSに対応したキャッシュというのがカンファレンスでは提示された。これは、アプリケーションのプライオリティなどからキャッシュを共有している各コアで利用するキャッシュ領域を制御しようというものだ。仮想マシン側にQoSを指定するレジスタを置き、アプリケーションを実行するコアは、それを見て、利用するキャッシュを加減する。このようにすることで、プライオリティの高いアプリケーションには多くのキャッシュが割り当てられ、そうでないアプリケーションではキャッシュ利用量を制限するといったことが可能になる。
 |
 |
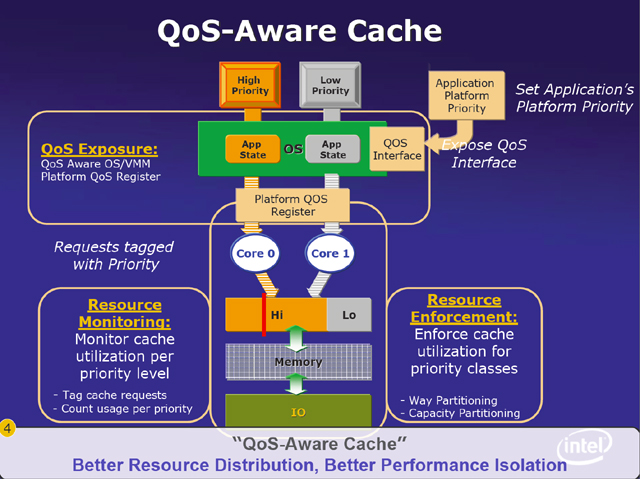 |
| 仮想マシンが多数動作する環境では、キャッシュを共有するコアで、キャッシュの使い方や要求が異なるアプリケーションが動作する可能性があり、このとき、相互に妨害が起こったり、キャッシュが有効に使われないといった問題が起こる可能性がある | そのためにIntelとしては、アプリケーションのタイプなどに応じた資源の割り当て要求とアプリケーションの振る舞いをモニタした情報を総合して割り当てを行なうQoS(Quality of Service)の考え方を導入すべきと提案 | 具体的にはQoSに対応したキャッシュ割り当てが可能なシステムを提示した。アプリケーションの優先度に応じ、必要ならば、アプリケーション(スレッド)に対して利用可能なキャッシュ量を制限する。このようにすることで、優先度が低く、大量のデータをアクセスするようなスレッドがキャッシュを占有してしまい、優先度の高いスレッドの実行が遅くなることを防ぐことができる。このためには、ハードウェア側に割り当てを制御、利用状況をモニタするための機構が必要となる |
こうした提案は、メニイコアのシステムが登場したときに、それをどうやって効率よく使うかという問題に対する答えである。つまり、複数の仮想マシンに分割してその中で従来型のオペレーティングシステムやアプリケーションを動作させるか、コンパイラなどにより自動的に多数のスレッドを生成させてそれを実行することで、メニイコアを有効に使い、そのパフォーマンスを引き出すことができる。
しかし、さらにメニイコア化がすすめば、いずれは、アプリケーションを設計する段階で、多数のコアに対応しなければならなくなる。仮想マシンを動かすといっても限界はあるし、中には、災害対策などで地理的に離れた場所にある物理的に違うマシンでの動作が要求されることもあるからだ。
今日のカンファレンスでも、こうしたメニイコアに対するプログラミングや設計などをどうすべきかといった質問、指摘があったが、だれもまだ明快な答えを持っていないようだ。
□Microprocessor Forum 2007のホームページ(英文)
http://www.in-stat.com/mpf/07/
□関連記事
【2月21日】【海外】テラフロップスメニイコア時代のIntel CPUの姿
http://pc.watch.impress.co.jp/docs/2007/0221/kaigai339.htm
【2月15日】【海外】Intel CPUの未来が見える80コアTFLOPSチップ
http://pc.watch.impress.co.jp/docs/2007/0215/kaigai337.htm
□Spring Processor Forum 2006レポートリンク集
http://pc.watch.impress.co.jp/docs/2006/link/spf.htm
(2007年5月24日)
[Reported by 塩田紳二]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2007 Impress Watch Corporation, an Impress Group company. All rights reserved.