 |


■後藤弘茂のWeekly海外ニュース■メモリが大きな壁となるAMDのFUSIONプロセッサ |
●統合できるGPUコアの性能レンジは1世代前のミッドレンジまで
AMDが「FUSION」プロセッサでCPUに統合できるGPUコアは、3つの要素のために、ある程度制約される。ダイサイズ(半導体本体の面積)と消費電力、そしてメモリ帯域だ。この3つの制約によって、FUSIONに統合されるGPUコアのパフォーマンスは、同世代のGPUのメインストリームクラスに抑えられる。AMDが、FUSIONをモバイルから先に持って来ることを示唆しているのは、そのためだ。また、FUSIONが登場した後も、この制約のために、ミッドレンジ以上のパフォーマンスのビデオカードはAMDプラットフォームで存続するだろう。
 |
| AMDのPhil Hester氏 |
AMDのPhil Hester(フィル・へスター)氏(Senior Vice President & Chief Technology Officer(CTO))は、2006年のインタビューで次のように説明していた。
「(FUSIONに統合するストリームプロセッシングの性能は)決してハイエンドには行かないだろう。なぜなら、ハイエンドの性能に必要なだけのシリコンは、(FUSIONでは)賄いきれないからだ。消費電力の面でも、ハイエンドの統合は難しい。だから、将来的にもTorrenza型のシステムが適したシステムが残るだろうと考えている。
(FUSIONによって)非常に効率的で、最適化され、以前より優れたグラフィックス機能を持つベースプラットフォームができる。Torrenza型システムでは、それにプラスして、より高レベルの機能の統合が可能になる。つまり、(CPUの)シリコンに(コプロセッサを)統合することで、市場に機能を広く普及させる。さらに、その後でTorrenzaライクのアクセラレータでより高度な機能を付加できる。シリコンに全てを統合するのではなく、Torrenzaで提供するものも併存する。Torrenza型のアクセラレータは、少なくとも我々が予想できる限り、将来ずっと併存して残ると考えている」
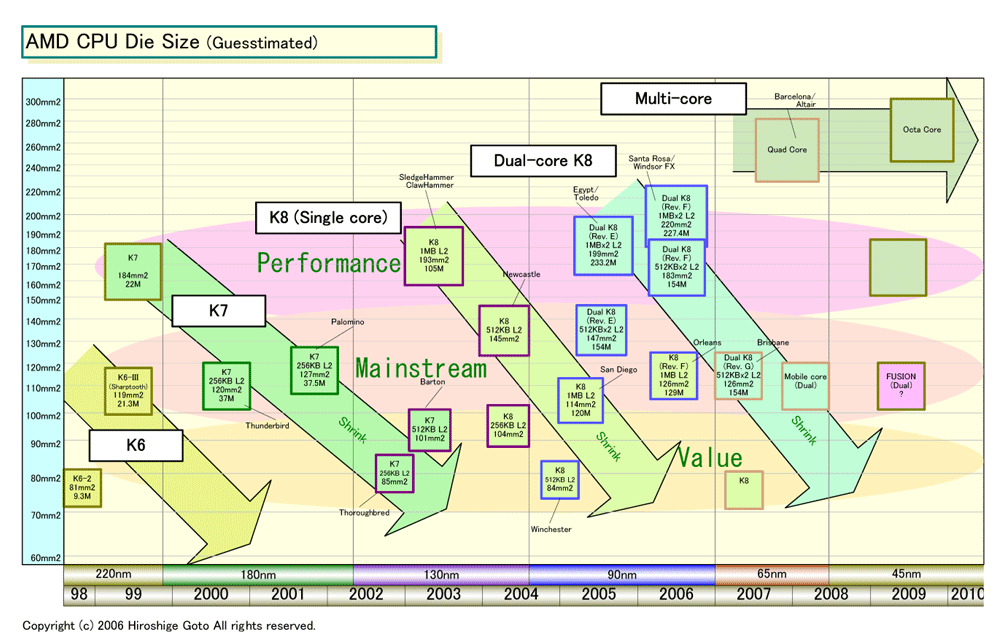
AMDのCPU製品のダイサイズは、ハイエンドのデスクトップCPUで200平方mm程度、メインストリームCPUで120~150平方mm、バリューCPUで100平方mm前後かそれ以下。そのため、FUSIONで半分のダイ(半導体本体)をGPUコアに割くとしても、搭載できるGPUコアの規模はある程度制約される。GPUのダイは、ハイエンドGPUで300平方mm以上、ミッドレンジGPUで120~150平方mm、バリューGPUで100平方mm前後かそれ以下。そのため、45nmプロセス世代のFUSIONに統合できるGPUコアは、65nm世代の1ランク下のディスクリートGPU程度の規模となる。
例えば、45nmのFUSIONがメインストリームCPU程度のダイサイズなら、統合できるGPUコアは65nm世代のミッドレンジGPUクラス。バリューCPU程度のダイサイズなら、GPUコアは65nm世代のバリューGPUクラスとなる。つまり、シリコン(=ダイ)のサイズを考えると、自ずとからFUSIONに統合できるGPUコアの規模が決まってしまう。
そのため、同世代のプロセス技術で作られるミッドレンジ以上のGPUのパフォーマンスはFUSIONでは提供できない。そこで、PCI Express接続のビデオカードも含む、Torrenza型のアクセラレータの提供が、将来的にも残ることになる。AMDは、FUSIONで提供するGPU/ストリームプロセッシング機能は、ベーシックなものと考えている。Torrenzaによって、CPUに接続するコプロセッサを充実させる戦略が、FUSIONと併存するのはそのためだ。AMDの主眼は、汎用CPUコアに、FUSIONとTorrenzaの2つの方法で、コプロセッサを加えて、特定処理のパフォーマンスを効率よくアップすることにある。
 |
| AMDのダイサイズ移行図 PDF版はこちら |
●メモリと消費電力がFUSIONプロセッサを制約する
FUSIONにとって、物理的なダイサイズ以上に壁となるのは、消費電力とメモリだ。プロセッサパフォーマンスを上げれば、それだけ消費電力が上がり、メモリ帯域が必要となる。しかし、システム側で対応できる消費電力には限界があり、汎用メモリで実現できる帯域にも制約がある。そのため、FUSIONはチップの限界までパフォーマンスを引き上げることができない。
「プロセッサ設計の観点から見ると、電力とメモリ帯域という2つのバランスを取ることが重要となる。紙の上では、潜在的にTeraFLOPSのパフォーマンスを達成するようなラディカルなプロセッサも設計できる。しかし、現実的な電力バジェットと現実的なメモリコンフィギュレーションでそれを達成することはできない。バランスポイントを考えて設計する必要がある。
特に、主流のPC技術に留まろうとすると制約がある。標準的なチップパッケージングや基板の技術、その時点で業界で標準的な量産メモリ技術。これらを利用しようとすると、自然に制約が設置される。その制約の中で、どれだけアグレッシブな実行ユニットを設計できるかというバランスとなる」とHester氏は基本的な姿勢を説明する。
つまり、FUSIONプロセッサも、PCの世界で標準的な技術の枠内で提供できるようにする。特殊な冷却システムや特殊なメモリを使わないで済むようにするというわけだ。FUSIONに統合するプロセッサコア群は、あくまでもその制約の中で設計しようという姿勢を持っている。
これは、じつはFUSIONにとって想像以上にきつい制約だ。特に、メモリの制約は厳しい。CPUにGPUの膨大な浮動小数点演算能力を加えるFUSIONでは、膨大なメモリ帯域と、より細分化されたメモリアクセスが必要になるからだ。
●CPUとGPUで大きく異なるメモリ回りのテクノロジ
GPUコアは、汎用CPUコアよりも膨大なメモリ帯域を必要とする上に、要求するメモリアクセスの粒度も小さいケースがある。また、メモリへのアクセスパターンも異なり、メモリアクセスレイテンシが演算コアに与える影響も異なる。そのため、CPUとGPUでは、最適なメモリ技術とメモリインターフェイスの構成が大きく異なっている。
汎用CPUは、「コモディティDRAM」と一般に呼ばれるメモリ業界主流のDRAM技術に最適化されている。コモディティDRAM側も、汎用CPUに最適化して設計してきた。コモディティDRAMでは、モジュール単位での増設性を第一に考えられている。また、コモディティDRAMでは、メモリ帯域だけでなくメモリレイテンシも重視しており、ラディカルに帯域を広げるアプローチは取らない。汎用CPUの場合は、入手性やコストも重要となるため、メモリベンダーが一致協力して同一規格のメモリを量産することも重要となっている。
それに対して、ハイエンドGPUはグラフィックスに特化したDRAMを前提に設計されて来た。ビデオカードでは、DRAMメモリはボードに直づけされ、モジュール型メモリは使わない。現状では、ハイエンドGPUでは、高転送レートに特化したGDDR3/4系メモリを採用している。
汎用CPUの場合、チップのエッジ長などの制約から、統合できるメモリインターフェイス幅は128bitまでに留まる。つまり、DDR2/3系では、現状のデュアルチャネル以上のメモリインターフェイスを統合することは現実的ではない。その一方、汎用CPUではメモリアクセス粒度は問題ではない。AMDの場合は、現在は128bit単位でDRAMコントローラを制御している。次の「Barcelona(バルセロナ)」からは64bit単位で制御する2つのDRAMコントローラを備えるようになる。しかし、それ以上DRAM制御を細分化することはできない。
それに対して、ミッドレンジ以上のGPUはメモリインターフェイス幅も256bitと広く取っている。インターフェイス幅を広く取ることで、広帯域化を図っている。それと同時に、メモリインターフェイスを分割して制御することで、メモリアクセス粒度を小さくしている。ATI Radeon X1000(R5xx)系の場合、DRAMコントローラは32bit幅の単位で制御されている。
●足りないメモリ帯域と大きすぎるメモリアクセス粒度
このようにメモリ回りが大きく異なるプロセッサコア同士を、同じチップに載せてメモリを共有する場合には、さまざまな問題や制約が生じる。まず、最大の問題となるのはメモリ帯域だ。ハイエンドGPUは、プログラマブルコアだけで300~500GFLOPSの演算パフォーマンスで、メモリ帯域は30~50GB/secクラスだ。10GFLOPS当たり約1GB/secのメモリ帯域が必要とされる計算となる。
ところが、PC向けのDDR系メモリは、2008~2009年の段階で、最高でもDDR3-1600のデュアルチャネルメモリだ。メモリ帯域は、ピークで25.6GB/secであるため、パフォーマンス的にバランスが取れるのは200~300GFLOPSとなる。GPUコアの場合は、キャッシュが効かないプロセッシングが多いため、CPUコアのようにキャッシュ量を増やしてカバーすることが難しい。メモリの制約から、FUSIONのGPUコアの性能は制限されることになる。
DDR3メモリを使う場合、もう1つの問題はメモリアクセス粒度だ。プロセス技術が微細化しても、DRAMのメモリセルの速度はほとんど上がらない。そのため、DRAMチップでは、メモリセルから読み出すデータの単位を大きくすることで高速化を図っている。これは「プリフェッチ(Prefetch)」と呼ばれる。例えば、「プリフェッチ4」のDDR2では、メモリセルから4n個のデータを1クロック毎に読み出し、4倍のスピードのインターフェイスでチップ外部に出力している。
プリフェッチ技術のおかげで、DRAMはメモリセル速度の制約にもかかわらず倍速化を続けることができた。しかし、その一方で、メモリアクセスの粒度は世代毎に倍増している。それは、メモリセルから1度に読み出すデータの量が倍々で増えているからだ。例えば、64bit幅のメモリモジュール当たりのアクセス粒度は、DDR2が32bytes、プリフェッチ8のDDR3では64bytesとなる。
汎用CPUコアの場合はメモリにはL2キャッシュのライン単位でアクセスするため64bytesでも問題は生じない。ところが、GPUコアの場合は、256bits(32bytes)程度の単位でデータアクセスを行なう場合がかなり発生するという。そのため、DDR3のメモリモジュールでは、アクセス粒度が大きすぎて無駄が生じる可能性がある。つまり、64bit幅でメモリアクセスを行なっても、そのうちの半分しか使わないというケースが出てくる。そうなると、実効メモリ帯域が削がれてしまう。
GPUコアはCPUコアと異なり、メモリ帯域インテンシブなので、このムダによってパフォーマンスが制約されてしまう。この問題は、FUSIONだけでなくグラフィックス統合チップセットについても言える。そして、CPUやチップセットに統合されるGPUコアのパフォーマンスが上がりメモリニーズが増えるにつれて、問題はクリティカルになって行く。FUSION時代には、大きな壁になるだろう。
●業界を巻き込んだメモリ改革が必要に
明瞭なことは、FUSION時代になると、コモディティDRAMのアーキテクチャを根本から変えて行く必要があるということだ。メモリ側をFUSION型のプロセッサに合わせて変えて行かないと、将来のFUSIONプロセッサのパフォーマンスは頭打ちとなってしまう。
こうした問題を解決できるメモリ技術もある。DDR2メモリの4倍のピン当たり転送レートを持つ、Rambusの「XDR DRAM」ファミリがそれだ。XDR2 DRAMになると「Micro-Threading」によってアクセス粒度を実質的に減らすことができる。つまり、将来にわたって、広帯域化を続けても、アクセス粒度を保つことができる。そのため、XDR DRAMはCell Broadband Engine(Cell B.E.)に採用されたことが示すように、ストリームプロセッサを統合したCPUには適したメモリ技術だ。
しかし、XDR DRAMは全てのDRAMベンダーが提供するメモリではなく、製造しているのは3社のみ。RambusとJEDEC(米国の電子工業会EIAの下部組織で、半導体の標準化団体)の関係はあまり協力的ではないため、同技術がメインストリームに取り込まれて行く可能性は低い。
こうした事情から、メモリはFUSION型のCPUにとって、最大のネックとなりそうだ。そして、この問題の解決はAMD単体では不可能で、DRAMベンダーなど業界を巻き込んで変化を呼び込む必要がある。問題は、AMDにそれだけ業界を牽引する力があるかどうか。標準化団体内では、Intelの力は依然として強い。
もっとも、Intelも現在、GPUコアを統合したCPU製品の導入を検討している。複数の業界関係者によると、IntelはAMDのFUSIONに対抗できる時期に、CPUとGPUの統合製品を投入する予定だという。これが、本当に統合プロセッサなのか、それとも単純にCPUとグラフィックス統合チップセットの2つのダイ(半導体本体)を1パッケージに収めた製品かどうかは、まだわからない。しかし、IntelもFUSION対抗を真剣に考えているようだ。
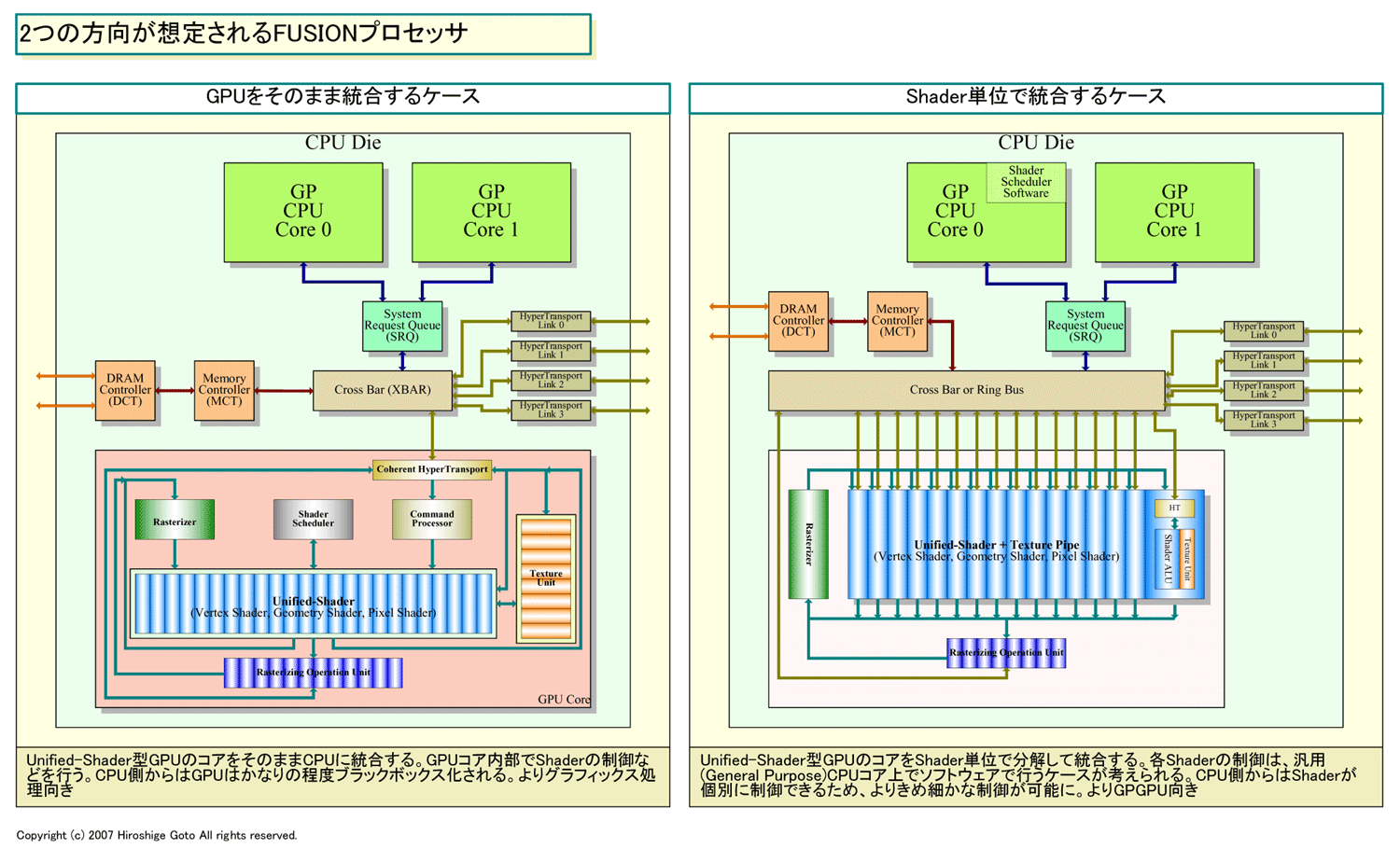 |
| FUSIONプロセッサの想定図 PDF版はこちら |
●ペタスケールのHPCシステムも視野に入れるAMD
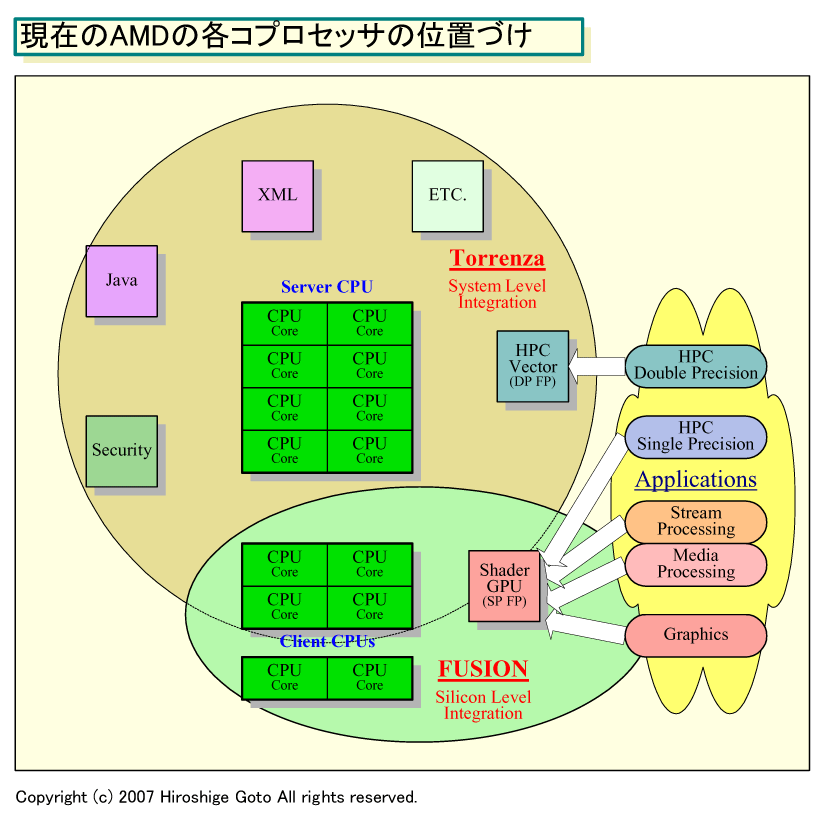
AMDはFUSION型のGPU統合プロセッサをクライアントスペースだけに限定して考えているわけではない。サーバーエリアでも、GPUコアを利用する方向にある。現在、AMDはGPUカードをストリームプロセッシングのアクセラレータとして提供しているが、GPUコアをCPUに統合できるようになれば、より統合された形で「ハイパフォーマンスコンピューティング(HPC)」向けにストリームコンピューティング能力を提供できるようになる。
「GPUの命令セットやシステムトレードオフなどを明確にできれば、GPUの機能をある意味で汎用化することが可能になる。すると、(GPUコアは)ローコストでハイボリュームの標準パーツのビルディングブロックとしてCPU設計で利用できるようになる。ハイエンドの科学技術マシーンにまで使える、スケーラブルなビルディングブロックの一種となるだろう。
今日のGPUを見ると、ピークパフォーマンスは500GFLOPSから1TFLOPSの間にある。さらに、クラスタ結合によって、数千ノードの巨大な科学技術マシンが今日現実的になっている。だから、うまく道筋を作れば、比較的簡単にローコストのペタフロップクラスのシステムを作ることができる。我々は、(GPUコアは)クライアントスペースに有用になるだけでなく、ラージ科学技術コンピューティング分野でも非常に効果的なビルディングブロックになるだろうと考えている」
つまり、近い将来のAMDは、500GFLOPS~1TFLOPSの浮動小数点演算能力を持つGPUコアを、CPUのビルディングブロックとして使えるようになる。すると、FUSION型のプロセッサを1,000ノード結合させればPetaFLOPSクラスのコンピュータも可能になる。しかも、クライアント向けのFUSIONをこのPetaFLOPSシステムに転用すれば、AMDが何100万個も量産するプロセッサを使うことで、コストも安く、インターフェイスや周辺ロジックも成熟したプラットフォームを提供できる。だから、ペタスケールマシンが、比較的低コストかつ容易に実現できるというわけだ。
●倍精度演算はGPUベースのHPCの壁
しかし、現在のGPUの演算コアは単精度浮動小数点演算エンジンで、HPCアプリケーションの多くが要求する倍精度以上の演算には対応できない。そのため、フルにHPC分野をカバーできるわけではない。Hester氏も、この点は認めている。
「たしかに、現在は倍精度をサポートできない。また、単精度演算も、現状ではIEEE準拠ではない。しかし、完全にフルIEEE準拠の倍精度演算ユニットを実装するとなると、かなりのシリコンエリアが必要となってしまう。そのため、どのような実装が適切かについては大きな議論がある。正しい答えは、おそらく、今日のGPUと、完全なハイエンド科学技術マシーンとの間の中間のどこかだろう。どのクラス(のタスク)までを満足させるかを、熟慮する必要がある」
GPUコアは、演算精度をグラフィックスに必要な単精度に抑え、演算ユニットをシンプル化することで、搭載できるユニット数を増やしている。そのためGPUコアがサポートする演算精度を高めると、演算性能が犠牲になってしまう。GPUコアをHPCに転用する場合には、この点が大きな壁となる。FUSION世代の現実的な解は、単精度演算をIEEE準拠に近づけ、倍精度は当面は見送るというあたりだと推測される。倍精度については、別なソリューションもあるからだ。
「我々にはTorrenzaもある。本当に真剣な科学技術コンピューティング機能はTorrenzaで提供できる。多分、Torrenza型アクセラレータで、倍精度が必要なワークロードは扱うことができるだろう」(Hester氏)
実際、現状でも倍精度浮動小数点演算アクセラレータはAMDプラットフォームに提供されている。こうしたソリューションが、Torrenzaで推進されアクセラレータがより低コストかつ広範囲に提供されるようになり、ソフトウェアインターフェイスも成熟して行くというのがAMDの描く図だろう。将来的には、それがAMDプロセッサのビルディンブブロックとして取り込まれて行く可能性もある。
「サーバースペースもクライアントと同じことだ。もし、特定の機能がパフォーマンス/消費電力の面から、CPUに統合しても理にかなうとなったら、統合しない理由はない」(Hester氏)
ただし、HPCは全体のボリューム的には小さいので、HPC向けの機能を統合したプロセッサが見合うかどうかはわからない。
明確なことは、AMDのFUSION戦略は、単純にCPUにグラフィックスをプラスするのではなく、HPCエリアまで含めた広汎なソリューションの提供を想定しているということだ。
 |
| 各コプロセッサの位置付け PDF版はこちら |
□関連記事
【1月26日】【海外】VistaとストリームプロセッシングがFUSIONを推進する
http://pc.watch.impress.co.jp/docs/2007/0126/kaigai331.htm
【1月22日】【海外】AMDが“Fusion”プロセッサとオクタコアに進む理由
http://pc.watch.impress.co.jp/docs/2007/0122/kaigai330.htm
【2006年10月13日】【海外】AMDがクアッドコアCPU「Barcelona」の詳細を発表
http://pc.watch.impress.co.jp/docs/2006/1013/kaigai311.htm
【2006年8月10日】【海外】AMD+ATIの統合プロセッサの姿
http://pc.watch.impress.co.jp/docs/2006/0810/kaigai294.htm
(2007年1月31日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.