
東大、1チップで512G FLOPSを達成する512コアプロセッサ
 |
| GRAPE-DRプロセッサ |
11月6日 発表
国立大学法人 東京大学は6日、1チップで512G FLOPSの浮動小数点演算が可能なアクセラレータチップ「GRAPE-DRプロセッサ」を発表した。
GRAPE-DRとは、研究者が“真に求めるシステム”を目指して「速く」、「安く」、「使いやすい」という3つの要素を融合したもので、2004年から2008年にかけて「GRAPE-DRプロジェクト」として研究されている。研究の具体的な目標は、2P(Peta) FLOPSのシステム、40Gbpsのデータ通信速度、関連アプリケーションの開発となっている。5年間の総予算は約15億円と非常に低予算である。
 |
 |
 |
| 「速く」、「安く」、「使いやすい」と、牛丼のフレーズのような要素を備えるスパコンシステムが目標 | GRAPE-DRプロジェクトの概要。5年間の予算総額は約15億円 | 目標のシステム |
 |
| 東京大学 情報理工学系研究科 平木敬教授 |
発表会では、東京大学 情報理工学系研究科の平木敬教授が、同プロジェクトの概要、新しく開発したプロセッサなどの説明を行なった。
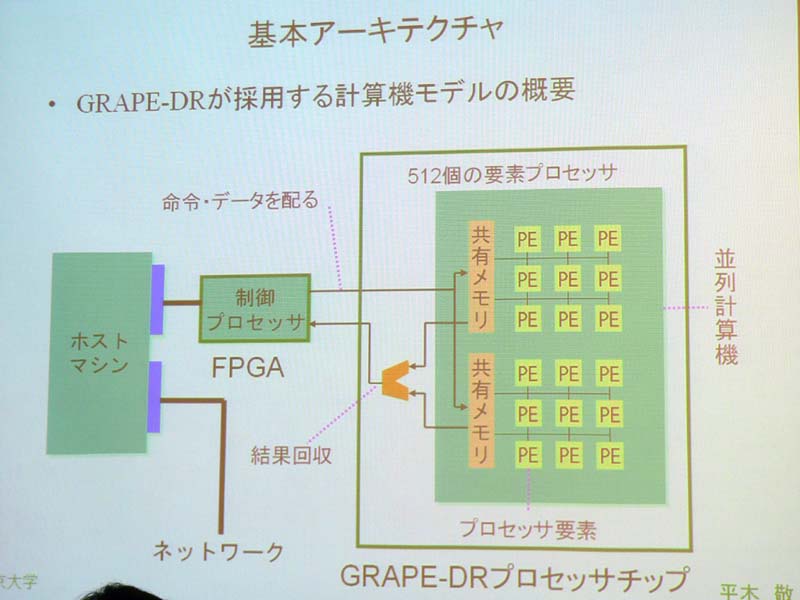
今回発表されたGRAPE-DRプロセッサは、できる限り機能を絞って小型化したというコプロセッサを512コア搭載し、動作周波数500MHzで512G FLOPSの演算性能を1チップで実現。1チップで512コア、512G FLOPSは世界最高を達成し、また、消費電力は最大60W、アイドル時30Wで、こちらも汎用プロセッサとして演算速度当たり世界最低だという。
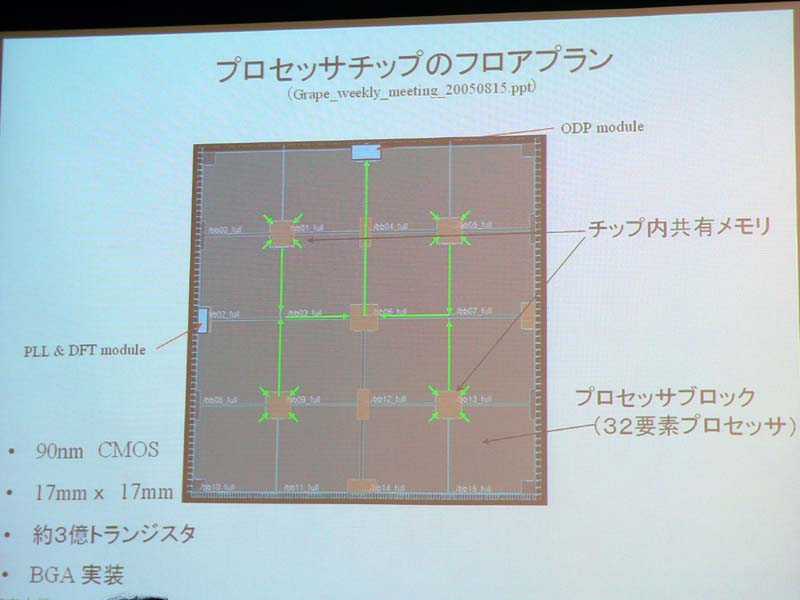
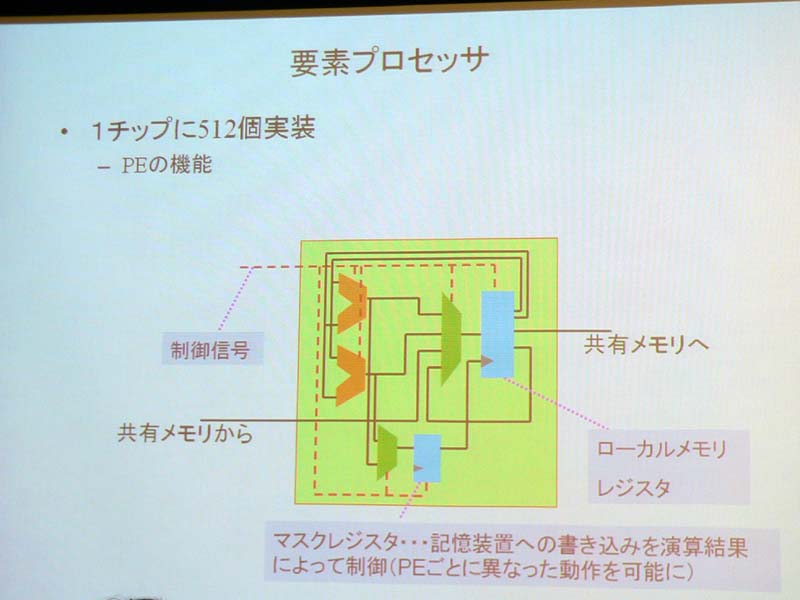
プロセッサは16の演算ブロック、共有メモリ、PLL(Phase Locked Loop)などの各モジュールで構成されたシンプルな構造。演算ブロックに32コアを内蔵し、32×16の512コアとなっている。1つのコアはレジスタ、加算(FADD)、乗算(FMUL)など、演算に必要な回路のみに切り詰めたという。演算の実行は、各コプロへのデータ分散作業、コプロでの計算、計算結果の回収、の3フェーズで行なわれ、各フェーズが重複して実行可能になっている。
プロセッサ自体は非常にシンプルなため、単体での運用ではなく、バスなどと接続し、データの受け渡しなどを行なう制御プロセッサをFPGAで用意。今回発表されたものはPCI-Xバス用のものだが、プログラム可能なFPGAを採用しているため、PCI Expressなど、より高速なバスへの移行も考えているという。このため、現行のPCアーキテクチャに追加する形で、強力な演算性能を持ったアクセラレータとして利用可能になっている。
 |
 |
 |
| GRAPE-DRプロセッサの概要 | ダイの構成図。演算ブロックと共有メモリでほとんどを占める | コプロセッサのレイアウト。役割で色分けされている |
 |
 |
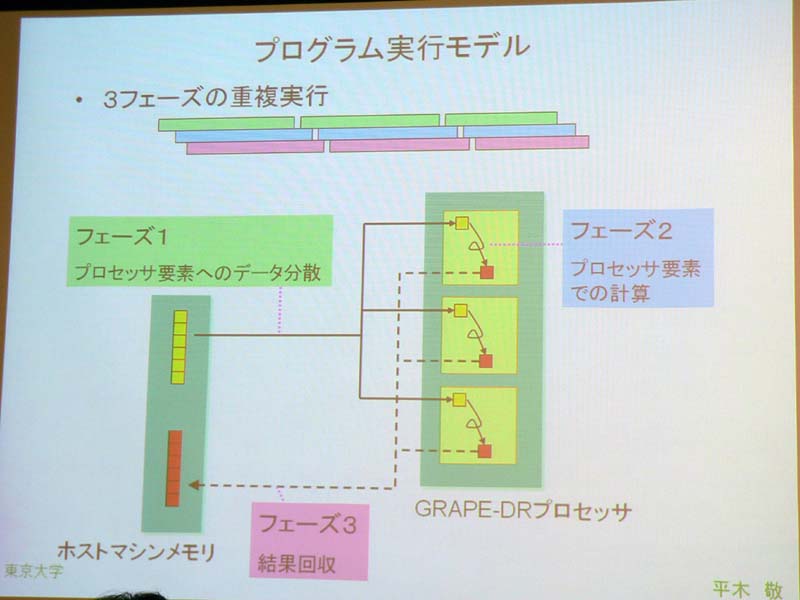 |
| 制御用のFPGAと組み合わせ、汎用バスで利用する | コプロセッサの概要 | 重複して行なえる3つのフェーズで演算を行なう |
 |
 |
| 試作された評価用ボード。自作ユーザーにもおなじみのZALMANのファンが装着されている。下部の銀色のチップが制御用のFPGA。2006年度中には4つのプロセッサを搭載したボードを製造予定 | こちらは小型化したPCI-Xバス用の1プロセッサボード |
浮動小数点の演算性能は、単精度で512G FLOPS、倍精度で384G FLOPSを達成。IBMとSonyが開発したCellは単精度256G FLOPS、倍精度25G FLOPSで、GRAPE-DRプロセッサが単精度で2倍、倍精度では約15倍となっている。また、ワット当たり性能も8.5G FLOPSで、ClearSpeedのCSX-600や、NECのSX-8を大きく上回る。これらが基本方式や命令セットなどを含め、すべて国産技術だということに大きな意義があるとした。
また、低コストなパーツで構成される汎用PCで利用できるプロセッサであることや、メモリの帯域幅を有効活用してメモリのコストも抑えているため、非常に低コストであるのも特徴。NECの「地球シミュレータ」クラスの演算性能はラック1本、費用は5,000万円で可能だとした。
プロセッサの開発に合わせて、スレッドの並列化や静的データフローを生成する「GRAPE-DR最適化コンパイラ」も開発中で、現時点では、基本的な最適化、C言語で記述されたソースを中間言語を介してGRAPE-DR用コードへの変換などが行なえるプロトタイプが動作中だという。
 |
 |
 |
| GRAPE-DRプロセッサの意義、その1。国産技術で世界最高性能を達成 | GRAPE-DRプロセッサの意義、その2。低コストで高い演算性能を実現可能 | 最適化コンパイラも開発中 |
プロセッサのダイ(半導体本体)は17×17mmと小さく、基板へはBGA(Ball Grid Array)で実装。トランジスタ数は約3億。製造はTSMCの90nmプロセス。2006年度中には、同プロセッサ4チップ(計2T FLOPS)を1枚のボードに搭載したアクセラレータを製造するという。また、1枚当たり1T FLOPSを超えるアクセラレータボードを100万円を切る価格で出したいとした。
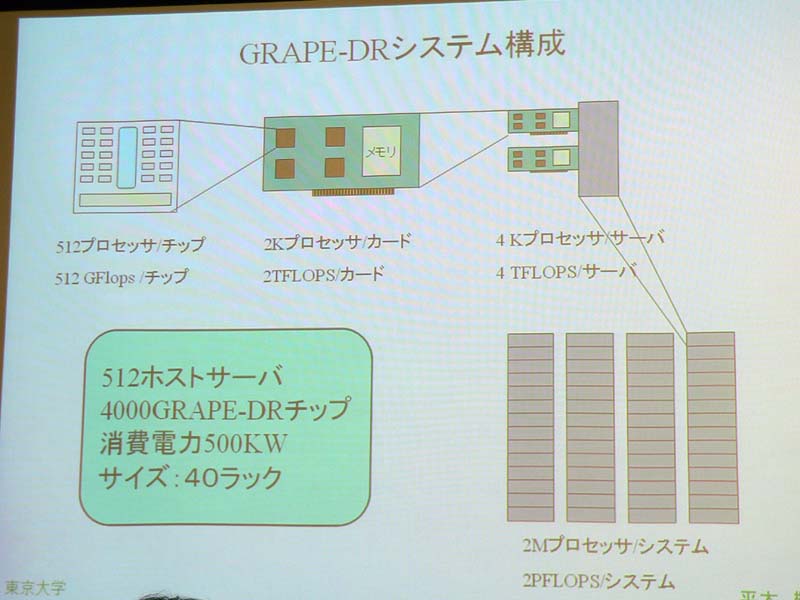
2008年に向け、2P FLOPSのGRAPE-DRシステム完成、コンパイラおよびシステムソフトの開発などを目標とした。GRAPE-DRシステムは、GRAPE-DRプロセッサを4,000個、512台の汎用PCクラスタとインターコネクトの構成を予定し、約40ラックで消費電力は500KW程度になるという。同時期に完成が見込まれているIBMのBlueGene/Pや、Roadrunnerなど、他のスーパーコンピュータの演算性能を上回り、TOP500の1位を目指したいと大きな目標を掲げた。
さらに今後、“予算ができれば”という条件付きだが、45nmへ微細化しトランジスタ集積度を高めた、より演算性能の高いプロセッサを開発したいという。ただし、現時点ではスポンサーが見つかっておらず、50億円を出してもらえるスポンサーを募集中だとした。
会場では、GRAPE-DRプロセッサを搭載したPCI-Xバス用ボードを装着したPCで動作デモが行なわれた。デモで使用されたPCはOpteron 2wayシステムで、汎用PCで利用できることを示している。
 |
 |
 |
| 1ボードに4プロセッサを搭載したボードを予定。演算性能はボード1枚で2T FLOPS | GRAPE-DRシステムの概要。目標は2008年の世界最速| スポンサーが現れればという条件で、45nmへの移行も視野に入れる |
|
 |
 |
 |
| GRAPE-DRプロセッサのダイ。大きさは17mm角 | 左がヒートスプレッダ。右がプロセッサ本体 | プロセッサの裏面。BGAを採用している |
 |
 |
 |
| 大きな試作ボードが目立つ動作デモのシステム | 試作ボードはPCI-Xバス用で、汎用PCでの利用が可能 | Opteron 2wayのシステムで動作していた。マザーボードはリオワークス製 |
□東京大学のホームページ
http://www.u-tokyo.ac.jp/
□ニュースリリース
http://grape-dr.adm.s.u-tokyo.ac.jp/press-release20061106/
□GRAPE-DRプロジェクトのページ
http://grape-dr.adm.s.u-tokyo.ac.jp/
□関連記事
【9月7日】IBM、1万6千個のCellと8,000個のOpteronを搭載したスパコン
http://pc.watch.impress.co.jp/docs/2006/0907/ibm.htm
【6月29日】IBM BlueGene/LがTOP500リストで3年連続1位
~東工大のOpteronシステムが7位にランクイン
http://pc.watch.impress.co.jp/docs/2006/0629/top500.htm
(2006年11月6日)
[Reported by yamada-k@impress.co.jp]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2006 Impress Watch Corporation, an Impress Group company. All rights reserved.