 |


■後藤弘茂のWeekly海外ニュース■なぜCPUは“シンプルコア”の“マルチコア”へと向かうのか |
●マルチコア化はCPU業界の規定路線
「マルチコアプログラミングがなぜ重要か。将来の全てのプロセッサはマルチコアチップになるからだ」、「これからはシングルコアのパフォーマンスは上がらない。パフォーマンスはマルチコアで上がる」
米Stanford Universityで開催されているチップカンファレンス「HotChips」のマルチコアプログラミングのチュートリアルでは、登壇する研究者が次々とマルチコアへのダイレクションがプロセッサ業界全体の決定的な方向であることを強調する。過去2年ほどのCPUカンファレンスでは、こうしたトーンで、業界挙げてのマルチコアへの急転換がうたわれてきた。
前回の記事でレポートしたように、マルチコアへとCPUが向かうのは、その方が理論上は効率的だからだ。CPUコア単体を拡張し続けることは、単純にパフォーマンスの面から見るとそれほど効率がよくない。「ポラックの法則」とIntelが呼ぶCPU業界の経験則では、同じプロセス技術でCPUのダイサイズ(=トランジスタ数)を2~3倍に増やしても、整数演算パフォーマンスはその平方根(約1.4~1.7倍)程度にしか伸びないとされている。
 |
| ポラックの法則(※別ウィンドウで開きます) PDF版はこちら |
では整数演算以外のパフォーマンスはどうか、という問題を置いておくと、CPUメーカーは数年前まで、こうした効率があまりよくないCPUコア拡張によるパフォーマンスアップを続けてきた。それでも問題にならなかったのは、半導体のスケーリングを重ねると、効率性の問題があまり見えなくなってしまうからだ。
●半導体のスケーリングがポラックの法則をカバーする
下が以前の半導体のスケーリングをポラックの法則に重ねたチャートだ。
半導体のスケーリングでは、プロセス1世代ごとにトランジスタがリニアに“0.7倍”にスケールダウンする。トランジスタ面積は“0.7倍”の二乗、0.7×0.7=0.5倍となる。つまり、2倍のトランジスタ数のCPUコアを、同じダイサイズ(半導体本体の面積)に納めることができる。そのため、CPUコアを2倍に拡張しても、プロセスを微細化すれば、1世代前のCPUと同じダイサイズに収まってしまう。
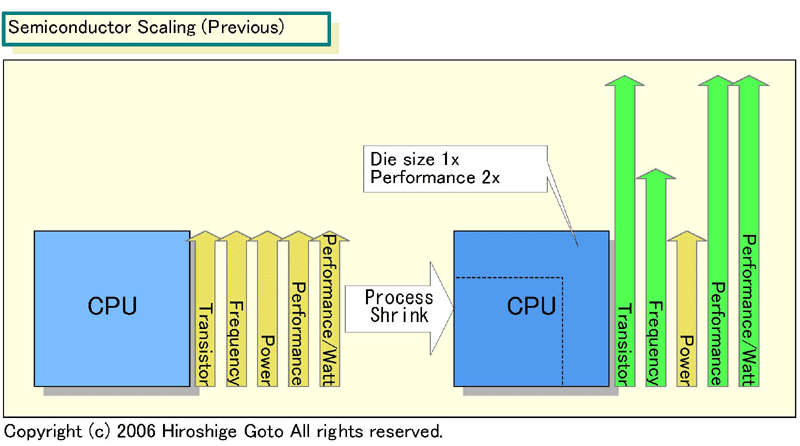 |
| Semiconductor Scaling (以前の状況)(※別ウィンドウで開きます) PDF版はこちら |
もっとも、2倍のトランジスタ数になっても、ポラックの法則に沿えばアーキテクチャ上のCPUパフォーマンスは1.4倍にしか上がらない。ところが、以前はプロセス微細化によるトランジスタの高速化のために、同じパイプライン段数でも1.4~1.5倍の周波数アップが得られた。つまり、アーキテクチャ上の性能アップがポラックの法則通り1.4倍であっても、プロセス技術によってさらに1.4倍強の性能が得られる。そのためCPUは、理論的には同じダイサイズで、パフォーマンスをプロセス世代毎にムーアの法則通り、1世代毎に2~2.2倍アップできていたわけだ。
だが、そもそもこれがおかしかったという指摘がある。
「CPUのパフォーマンスはムーアの法則に従って伸びてきたというが、それはおかしい。本当なら、ムーアの法則よりパフォーマンスが伸びなければならない」と以前、あるCell関係者が指摘していた。
これは、本来ならCPUパフォーマンスは世代毎に2.8~3倍にならなければおかしかったという意味だ。そのため、トランジスタ数の増加通りにCPUコアのアーキテクチャ上のパフォーマンスが上がるなら、トランジスタ数2倍×周波数1.4~1.5倍で、計2.8~3倍のアップにならなければ計算に合わない。つまり、ムーアの法則に沿ったパフォーマンス向上は、じつは、全然半導体のスケーリングに沿ったパフォーマンス向上ではなかったというわけだ。毎プロセス世代に2.8~3倍のパフォーマンスアップが、本来のCPUの性能向上曲線だったということになる。
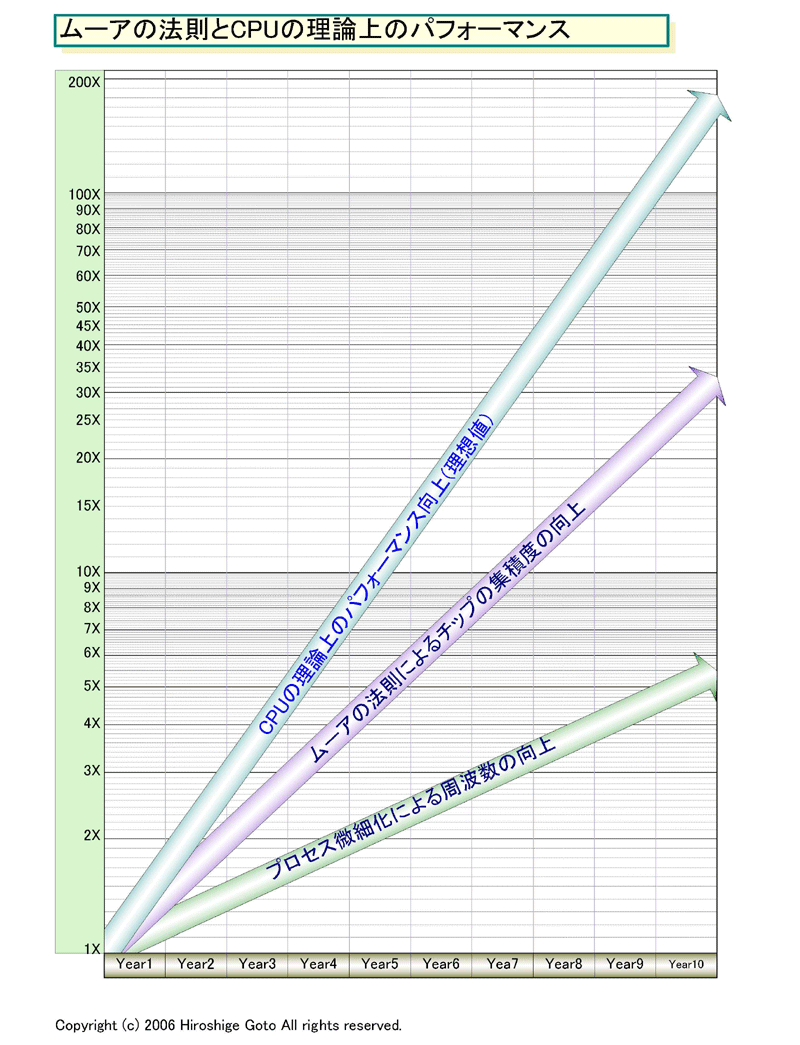 |
| ムーアの法則とCPUの理論上のパフォーマンス (※別ウィンドウで開きます) PDF版はこちら |
●半導体プロセスのスケーリングの鈍化で問題が噴出
それでも、世代毎に2倍前後のパフォーマンスアップは、悪くない数字だった。そのため、CPUメーカーはソフトウェア開発にインパクトの少ないシングルコアの性能アップを続けて来ることができた。130nmプロセスまでは。
問題は半導体のスケーリングが鈍化したことで、兆候が見え始めたのは130nmから、顕著になったのは90nmプロセスからだった。ムーアの法則のスケーリング自体、つまり、2年で0.7倍にスケールダウンして2倍のトランジスタの集積が可能になるというペース自体はまだ活きている。しかし、ムーアの法則に伴う他の要素のスケーリングが鈍化したため、CPUについては従来通りにはいかなくなってしまった。
Intelは、2004年秋の「Intel Developer Forum(IDF)」の「New Paradigms and Metrics for Scalability」というセッションでこの問題を論じた。それによると、以前は1世代毎に電圧が0.7倍にスケールダウンしていたのが、現在では0.9倍に鈍化。また、トランジスタのディレイタイムも0.7倍のスケールから0.75倍へと鈍化した(周波数の向上が鈍化した)という。特に、消費電力は電圧の二乗に比例するため、この変化で、CPUの消費電力はガクンと下がらなくなってしまった。
しかも、さらにリーク(漏れ)電流の増大がこれに加わった。トランジスタが微細化し過ぎたことで、リーク電流は90nmプロセスで激増した。ISSCCでのIntelの説明では90nm版Pentium 4(Prescott:プレスコット)では消費電力の30%がリーク電流になってしまったという。つまり、電圧低下が鈍化したことによるアクティブ電力のアップにプラスして、リーク電流による電力アップが加わった。
こうした要素を重ね合わせると、現状でのCPUコアの拡張は下の図のような結果をもたらすことになる。このチャートは厳密なものではなく、Northwood→Prescottの移行から逆算して推定している。あくまで目安程度のものだ。また、実際には、CPUの消費電力を2倍にすることはできないので、周波数を抑えるか、「Tejas(テハス)」のようにCPUの開発自体をキャンセルせざるを得ない。
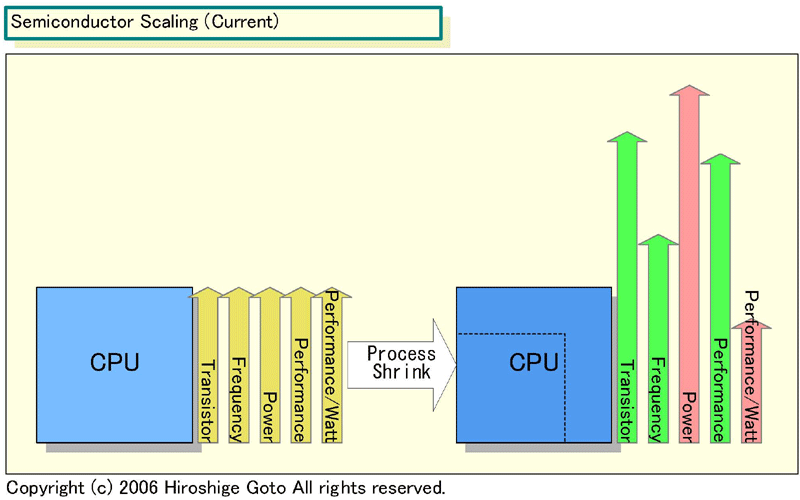 |
| Semiconductor Scaling (現状)(※別ウィンドウで開きます) PDF版はこちら |
●シンプルコア化でポラックの法則を破る
こうして見ると、CPUメーカーがパフォーマンス効率のアップに躍起になる理由はよくわかる。半導体のスケーリングが鈍化した以上、CPUコアの効率を上げるしかない。
そして、効率の向上はポラックの法則を逆に当てはめることで得られる。
CPUコアを1世代分シンプルコア化して、1/2のトランジスタ数に減らしたとする。そうするとポラックの法則での理論値では、パフォーマンスは0.7倍にしか下がらないのに、消費電力は半分の0.5倍に下がることになる。そのため、パフォーマンス/消費電力とパフォーマンス/ダイは1.4倍に上がる。
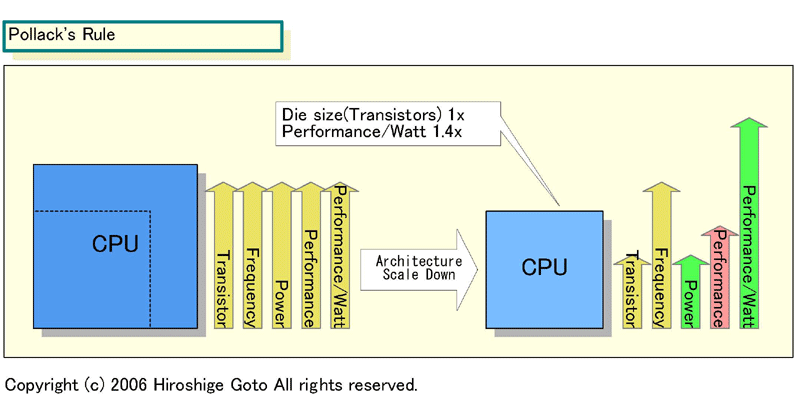 |
| トランジスタ数を減らしたシミュレーション (※別ウィンドウで開きます) PDF版はこちら |
ただし、これだけだと絶対パフォーマンスはコンプレックスコアCPUより低下してしまう。そこで、マルチコア化によってCPU全体のパフォーマンスのアップを図ることになる。
同じダイサイズ、同じトランジスタ数、同じ周波数、同じ消費電力で、CPUコア数の違いによる理論パフォーマンスを比べたのが下の図だ。
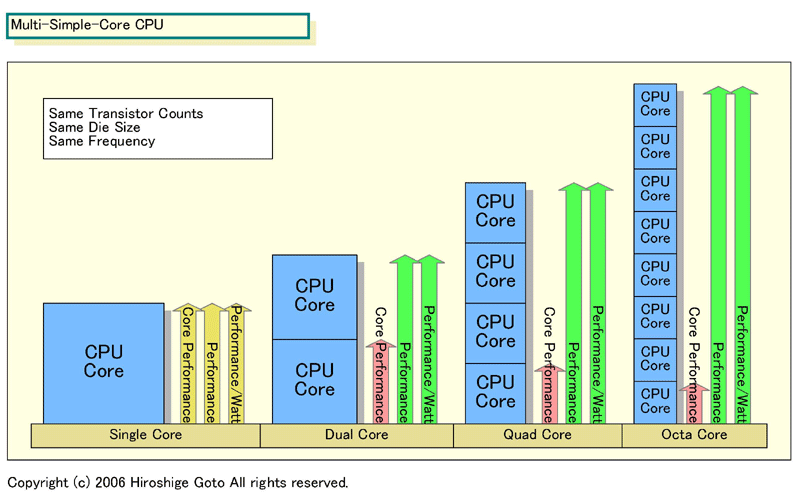 |
| コア数の差による理論パフォーマンスの比較 (※別ウィンドウで開きます) PDF版はこちら |
CPUコアをシンプルコア化にしてマルチコア度を高めると、理論上のパフォーマンスがアップする。例えば、シングルコアCPUと同じダイサイズでデュアルコア化した場合は、CPUコアパフォーマンスは0.7倍に下がるが理論上のパフォーマンスは1.4倍に上がる。
これは、ちょうどIntelのPentium D(Smithfield:スミスフィールド)と、Intelがキャンセルした「Tejas(テハス)」の関係に当たる。
Intelは、次のCore Microarchitectureでも、より小さなダイ(半導体本体)に2つのCPUコアを載せた。ベースアーキテクチャが全く異なるため、Core MAとNetBurstを単純には比較ができない。しかし、Core MAの実行コアは65nmプロセスでダイエリアが約36平方mm、トランジスタ数は1,900万(19M)と、比較的小さい。CPUコアの複雑化はできる限り抑えたと言っていいだろう。
プロセスの微細化を機に、CPUコア性能は同レベルに留めるか向上させながら、コア数を増やすという手法だ。今のPC向けCPUは、現在、この方向にある。
●シンプル&マルチ化が理論パフォーマンスを上げる
さらにもう1段階シンプルコアにして、クアッド(4)コア化した場合は、CPU全体のパフォーマンスは2倍になる。AMDのHoundファミリのクアッドコア版はこのラインで、デュアルダイのIntelのクアッドコアも基本的な考えは同じだ。
AMDもIntelも、CPUコアの大型化はできる限り抑えて、CPUコア数を増やすことに注力した。プロセスの微細化を利用することで、シングルスレッド性能を犠牲にすることなくクアッドコア化でCPU全体のパフォーマンスを引き上げる方向だ。
もう1段階シンプルコアにしてオクタ(8)コア構成にすると、理論値ではCPU全体のパフォーマンスは4倍に達する。ただし、CPUコア単体のパフォーマンスは0.35倍、約1/3にまで下がることになる。このトレードオフは大きいため、PC向けではプロセス微細化があと1回進まないとこの手法は採りにくい。微細化が進めば、CPUコアの複雑度を一定に留めてコア数を増やすことができる。
しかし、特定用途向けなら話は異なる。エッジサーバーなどをターゲットに8個のシンプルCPUコアをワンチップに搭載したSun Microsystemsの「UltraSparc T1(Niagara:ナイアガラ)」はこのラインにあり、ゲームコンソールのCellもコア数だけを見るとこのレベルになる。
もちろん、ここで言っているパフォーマンスは、あくまでも理論上のもので、実効パフォーマンスは異なる。しかし、この理論チャートから見えるのは、シンプルコアのマルチコア化によるスレッドレベルの並列性「TLP(Thread-Level Parallelism)」の向上の方が、シングルコアの拡張による命令レベルの並列性「ILP(Instruction-Level Parallelism)」の向上より有利という点だ。ソフトウェアさえ、TLPを活かすことができれば。
●SIMD型の浮動小数点演算パフォーマンスにフォーカス
シンプルコアのマルチコアへと向かうCPUの潮流は、コンピュータアーキテクチャ的には「ILPを超える(Beyond ILP)」流れである。
それは、整数演算のILP向上が、効率性のボトルネックになっていると考えているからだ。ポラックの法則でも、パフォーマンス向上が非効率だと指摘しているのは整数演算についてだ。
整数演算の汎用コンピューティングでは、複雑な命令フローを効率よく制御してILPを高める必要がある。その制御のオーバーヘッドが大きい。実際、現在のPC向けCPUでは、命令の制御やデコードなどの部分にCPUのダイのかなりの面積が取られ、実行ユニット自体の面積は制限されている。CPUコアを拡張しても、演算ユニットだけでなく、余計な制御回路が増えるのだから、性能がトランジスタ数に比例して向上しないのも当たり前となる。
CPUコア拡張の非効率性は、整数演算のILP向上のためだったとすると、逆を言えば、他のパフォーマンス要素なら、それほど非効率にせずに上げることができることになる。例えば、浮動小数点演算なら、整数演算の汎用コンピューティングのような命令スケジューリングはさほど重要ではない。浮動小数点演算中心のコンピューティングなら、実質的にシリアルな命令ストリームの処理になるので、より効率的にパフォーマンスを引き上げることができる。
もう1つの可能性は、SIMD(Single Instruction, Multiple Data)型のデータ処理。SIMDによってデータレベルの並列性「DLP(Data-Level Parallelism)」を高める方法でも、効率よくパフォーマンスを上げることができる。それなら、これらの処理にフォーカスしてCPUコアを強化すれば、CPUパフォーマンスを効率的に上げることができることになる。
実際、Core MicroarchitectureにしろAMDのHoundにしろ、SSEユニットを倍増してSIMD浮動小数点演算性能を高める部分にリソースを割いている。これは、効率性を重視すると、整数演算のILP向上にリソースを大きく割くより、SIMD浮動小数点演算に注力するのが有効だからだ。Core Microarchitectureは整数演算のILPも上がっているが、これは、そこに膨大なリソースを割いたのではなく、そこそこのリソースでうまく性能を引き上げる効率的な手法を考えた結果のように見える。また、その前のNetBurstが、周波数当たりの性能効率が悪すぎたというのもある。
●ヘテロジニアスマルチコアが論理的な帰結
Beyond ILPとして、さらに効率的な方法は、CPUコア自体を特定の演算にフォーカスして設計してしまうことだ。そうすれば、よりシンプルなコアで、高い性能を達成できる。
例えば、整数演算も実行できるが、主体はSIMD浮動小数点演算に置いてCPUコアを設計する。フル機能のSIMD演算ユニットは載せるが、オーバーヘッドの大きいアウトオブオーダ型実行や、3wayや4wayのパイプラインは排除して、インオーダの2way程度のパイプラインに抑えてしまう。この手法なら、CPUコアのパフォーマンス効率を大幅に上げることができる。
Cellが取ったのはこの手法だ。CellのSPE(Synergistic Processor Element)は、命令セット的には汎用だが、インオーダの2wayパイプで、SIMD浮動小数点演算の性能向上に特化している。そのため、コンパクトなシンプルコアで高浮動小数点演算パフォーマンスを実現できた。
Cellチップ上で1個のSPEが占めるサイズは、90nmプロセスのプロトタイプチップで2.5mm×5.8mm、面積はわずか14.5平方mm。65nmにシュリンクすれば、Core MAのCPUコアの1/4以下に収まるだろう。トランジスタ数は2,100万トランジスタだが、実際にはワークメモリを内蔵しているため、このうち1,400万がSRAMを占める。CPUのロジック回路は700万トランジスタに過ぎない。
特定の演算や用途に特化すると、CPUコアをコンパクトにできる。このことは、TLPの向上にもつながる。Cellの場合は、1チップ上に1個の汎用(General Purpose)コアPPE(Power Processor Element)と、8個のSPEを搭載している。SPEを特化させることで小型化、より多くのCPUコアを搭載するという戦略だ。ただし、SPEだけで構成すると汎用コンピューティングは問題が出るので、汎用のPPEも搭載するヘテロジニアス(Heterogeneous:異種混合)構成を取った。
AMDのCPU+GPUも、おそらく同種の発想だ。AMDが統合するGPUコアも、SIMD浮動小数点演算にフォーカスしたシンプルコアの集合体となるだろう。ただし、AMDの場合はPC向けにより強力な汎用コンピューティングコアを備えることになる。
こうして見ると、Beyond ILPを追求していくと、論理的にはヘテロジニアスマルチコアが最良の解となる。ただし、そこには必ずソフトウェアがついて来れればという但し書きがつくことになる。そのため、現実的な意味でヘテロジニアスマルチコアが本当に最適解になるのか、まだ結論は出ていない。
□関連記事
【8月21日】【海外】“シンプルコア”に向かう次世代CPUアーキテクチャ
http://pc.watch.impress.co.jp/docs/2006/0821/kaigai296.htm
【8月18日】【海外】決定的となったヘテロジニアスマルチコアへの潮流
http://pc.watch.impress.co.jp/docs/2006/0818/kaigai295.htm
【8月10日】【海外】AMD+ATIの統合プロセッサの姿
http://pc.watch.impress.co.jp/docs/2006/0810/kaigai294.htm
(2006年8月22日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.