 |


■後藤弘茂のWeekly海外ニュース■「Core Microarchitecture」の速さの秘密は“CISCの美” |
●じつは大きなアーキテクチャ革新であるCore MA
Intelは、いよいよ新CPUマイクロアーキテクチャ「Core Microarchitecture(Core MA)」をベースにした新世代CPU群を発表し始めた。サーバー向けの「Xeon 51xx(Woodcrest:ウッドクレスト)」に続き、デスクトップ向けの「Core 2(Conroe:コンロー)」、モバイル向けの「Core 2(Merom:メロン)」が今後数カ月で相次いで登場する。IntelはCore MAのパフォーマンス/消費電力に強い自信を持っており、これで近年の落ち込みを一気に回復するつもりだ。
パフォーマンス/消費電力では強力なアドバンテージがあるCore MA。しかし、その秘密の源は、あまり理解されていない。Intelが体系的な説明をあまり行なっていないためだ。そのため、Core MAは、「細かな省電力技術の集合体で、抜本的なマイクロアーキテクチャ革新とは見えない」あるいは「Banias(Pentium M)のベースとなったP6(Pentium Pro/II/III)アーキテクチャを拡張しただけ」とよく言われる。
しかし、おそらく、これはどちらも正しくない。Core MAは、明確にP6やNetBurst(Pentium 4)とは異なるフィロソフィ(思想)を持ち、マイクロアーキテクチャが抜本的に革新されているからだ。それを象徴するのは、内部命令(Micro Operations:uOPs)のアーキテクチャだ。Core MAとNetBurstでは、これが根本的に異なっているため、パイプラインの構造が全く異なるものとなっている。
また、Core MAは、その先に続く新アーキテクチャ路線の第1ステップに過ぎない。Core MAの先には、P6/NetBurstと逆の方向へと伸びる、よりラディカルな将来マイクロアーキテクチャ展望できる。実際、Core MAの特徴的なテクニックの一部は、Core MAを開発したIntelイスラエルに所属する研究者が数年前に発表した「Power AwaReness thRough selective dynamically Optimized Traces(PARROT)」アーキテクチャの論文の中に、すでに見られる。新しいフィロソフィに基づくマイクロアーキテクチャのゴールは先に見えており、その最初のステップがCore MAと考えることもできる。
では、Core MAは何がNetBurstと異なるのか。それは、「CISC(Complex Instruction Set Computer)」である点だ。
●CISCの利点をパイプラインに活かしたCore MA
 |
| IntelのBob Valentine(ボブ・バレンタイン)氏 |
「Core MAの重要な点は、CISCの美(beauty=利点)をパイプラインに持ち込んだことにある」と語るのは、IntelのBob Valentine(ボブ・バレンタイン)氏(Senior Architect, Intel Architecture Group)。
Valentine氏は、Intelの新世代マイクロアーキテクチャ「Core Microarchitecture(Core MA)」の、デコーダ回りのアーキテクチャを開発したアーキテクト。つまり、Core MAの要(かなめ)となる命令デコーダを最もよく知る人物だ。そして、その彼が、Core MAの秘密は、CISC命令セットアーキテクチャ(ISA:Instruction Set Architecture)の利点を持ち込んだことにあると言う。
CISC云々は、ちょっと聞いただけだと奇妙な話に聞こえるかも知れない。x86系は、典型的なCISC系ISAだからだ。しかし、よく知られていることだが、CPUのマイクロアーキテクチャとなると話が違う。P6/NetBurstは、x86命令を、CPU内部でRISC(Reduced Instruction Set Computer)風のuOPsに変換しているからだ。P6以降のIntelのIA-32系マイクロアーキテクチャの最大のポイントは、RISC風に命令を分解し、RISCの手法を取り入れて高速化することにあった。だが、Core MAはそれを否定する。「(Core MAは)もはや内部RISCプロセッサではない(it's no longer RISC Processor inside)」とValentine氏は言う。
乱暴に言ってしまえば、NetBurstまでのIntel CPUは、CISCの皮をかぶったRISC風CPUだった。それに対して、Core MAでは、中身もかなりの部分までCISC風になった。中身を完全にCISCに戻したのではなく、ある程度までCISC風のuOPsを採用したという意味だが、方向性が全く逆であることは確かだ。言い換えれば、RISC風が素晴らしいとするフィロソフィを否定し、CISC風に利点があるとするフィロソフィを採用したのがCore MAとなる。
IntelがRISC風→CISC風への転換を図った理由は明快だ。NetBurstでは、RISC風uOPsを採用したために、RISCの難点もパイプラインに持ち込んでしまったと、Intelが考え始めたからだ。最大の難点は、パフォーマンス/消費電力で、Intel CPUが非効率になり、消費電力が増大してしまった原因は、RISC化にあったとIntelは見る。そこで、Core MAでは、これを逆転させることで、パフォーマンス/消費電力を劇的に向上されることに成功したわけだ。
この意味を明確にするには、かつてのCISC対RISCのISA論争にまで遡る必要がある。
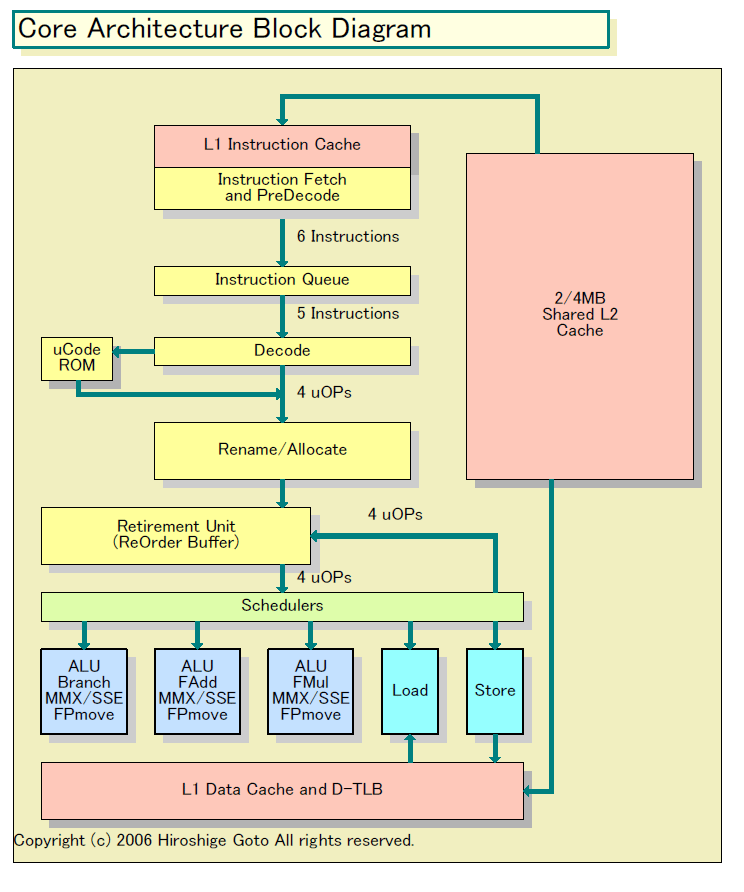 |
| Core Architecture Block Diagram (※別ウィンドウで開きます) PDF版はこちら |
●リソースが少ない時代に適合していたCISCアーキテクチャ
CISCの特徴と一般的に言われるのは、命令数が多く、複雑な処理を行なう命令が多く、命令長が可変で、命令フォーマットが複数あり、メモリ-レジスタ間演算命令があることなど。
こうしたCISCの特徴は、コンピュータの歴史に由来する。CISCが産まれた時点ではアセンブラコーディングが前提で、プログラマの生産性を高めやすいISAを定義する必要があった。そのため、人間が扱いやすいように命令種類を増やし、コーディングの際の命令ステップ数を減らした。
そして、CISCの特徴は、当時のハードにも向いていた。命令ステップ数の削減によるプログラムのコードサイズの削減は、高価だったメモリの節約にもなった。また、CPUのフェッチ帯域の節約にもなった。つまり、CISCは元々、ハードウェアリソースが限られていた時代に適合していたわけだ。CISCのこうしたアプローチは、'80年頃まではうまく働いていた。
ところが、半導体技術の進歩とプログラミング環境の変化によって状況が変わり始めた。メモリは安価になる一方で、高級言語の普及によってISAを複雑にする必然性が薄れた。また、チップの集積度の向上とともに、CPUのマイクロアーキテクチャではパイプライン処理などが登場し、高速化への道が開けてきた。
そこで、よく知られているように、高級言語からコンパイルしたオブジェクトコードを高速に走らせるように特化したCPUを作ろうというアイデアが浮上してきた。その源流は、30年ほど前のIBMの「801 Project」で、そこから次々にSPARC、MIPS、PowerPC、AlphaといったRISCアーキテクチャが生まれてきた。
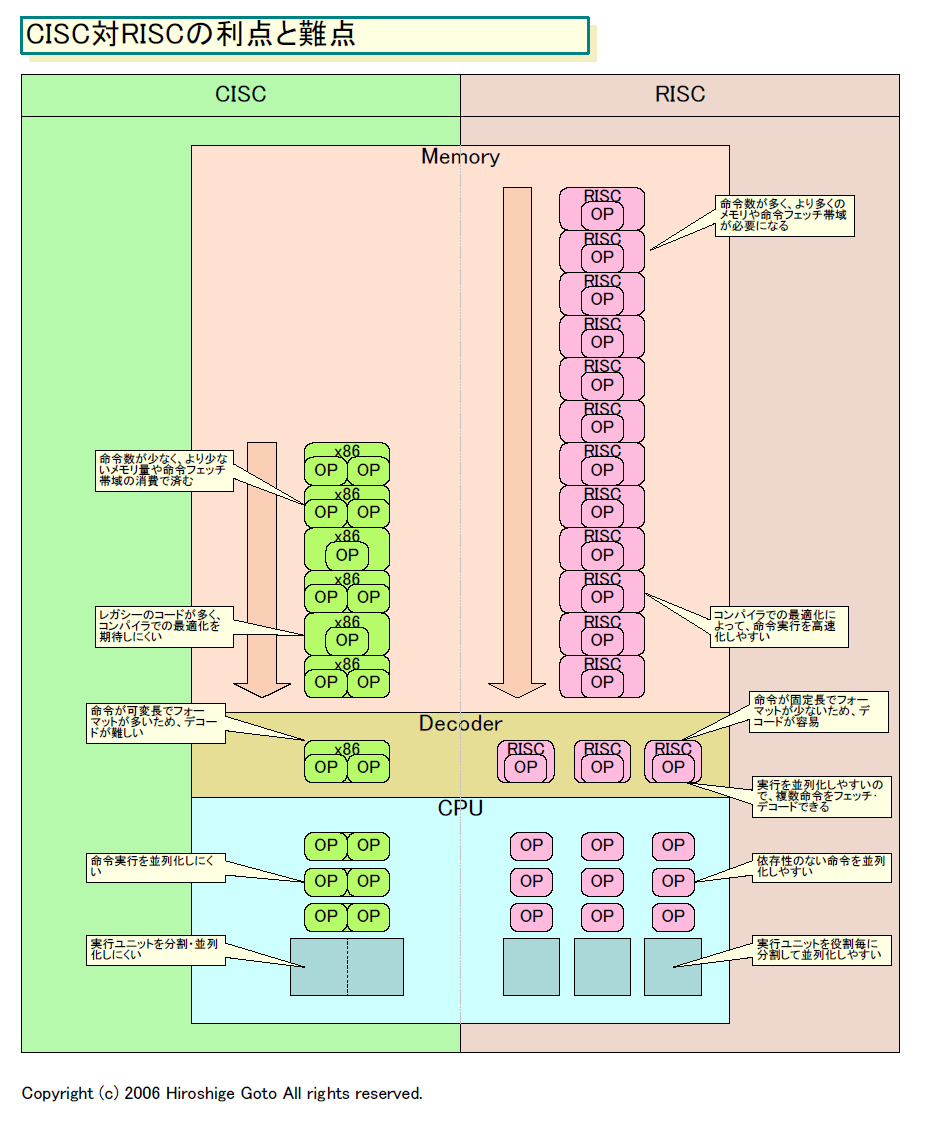 |
| CISC対RISCの利点と難点 (※別ウィンドウで開きます) PDF版はこちら |
●増えたリソースを活かすRISCアーキテクチャ
RISCに共通すると言われるフィロソフィは、高級言語を前提として、単純で少数の命令に限定し、命令長を固定して、命令フォーマットも限定すること。メモリアクセスはデータのロード(Load)系命令とストア(Store)系命令に限定し、演算命令はレジスタ間の演算に限定する。命令デコードを速くし、単純な命令をパイプラインで高速に実行できるようにする。実際には例外もあるが、基本的なアイデアは上記だと言われている。
RISC ISAは、ソフトウェア(コンパイラ)によるスタティックスケジューリングと、ハードウェアによるダイナミックスケジューリングのどちらも容易にする。例えば、レイテンシの長いメモリからのロードを、前へスケジューリングすることで、ロードレイテンシを隠蔽することができた。依存性のない命令同士を並列に実行させることも容易になる。その結果、スーパースカラやアウトオブオーダ(out-of-order)実行などが適用し易くなる。そのため、RISCは目覚ましくパフォーマンスを伸ばすことができた。
しかし、RISCにも難点があった。それはハードウェアリソースを必要とすることだ。スタティックな命令数が増えるためプログラムメモリ容量が増えて、より多くの物理メモリを必要とする。ダイナミックには、同じ処理に必要な命令ステップ数がCISCよりも増えるため、命令実行サイクルが増える。そのため、同じ時間内に、CISCと同等かそれ以上の処理を行なうためには、単位時間により多くの命令を実行できるように、ハードウェア側の工夫が必要となる。その点もリソースを消費する。
例えば、スーパースカラでより多くの命令を並列に実行するなら、CPUに広い命令フェッチ帯域とパイプライン帯域が必要になる。スーパーパイプラインでCPUをより高速に回すなら、より細分化されたパイプラインが必要となる。そうしたマイクロアーキテクチャの拡張もリソースを必要とする。つまり、RISCは一般論では、CPUのパフォーマンスを上げる代わりに、リソースも必要とする。実際には、ISAやマイクロアーキテクチャの改良の結果、必ずしもそう言い切れなくなっているが、CISC対RISCの論争時にはそう言われていた。
●パフォーマンス/消費電力の時代に疑問視されるRISC風x86 CPUアーキテクチャ
CISC対RISCで激しい論戦が盛り上がったのは386からPentium Pro(P6)前までの時代だった。そして、P6アーキテクチャは、ある意味でこの論争に終止符を打った。P6がCISC型のx86命令を、RISC型の内部命令(uOPs)に変換する方式を取ったからだ。RISC風uOPsを使うことで、P6ではスーパーパイプライン、スーパースカラ、アウトオブオーダ実行といった、当時のRISCの先端のテクニックをほとんど取り込んだ。
IntelはRISCの利点を認めて、それを積極的に取り入れることで、CISCの問題点と指摘されていた部分を克服したわけだ。ISA自体は変えずに、CPUの中でRISC風に変換すればいいというのが、Intelが出した答えだった。この方式は、デコード時の命令変換のオーバーヘッドはあるものの、高パフォーマンスを達成できた。
その結果、次第にCISC対RISCの論争は収まっていく。もっとも、RISC風変換はIntelだけの独創ではなく、当時はAMDの「K5」やNexGenの「Nx586」など類似のアーキテクチャのCPUが一斉に登場している。Intelは先駆ではなく、CPU業界全体の技術トレンドに従っただけだった。
P6のRISC風uOPsの技法は、次のNetBurst(Pentium 4/D)アーキテクチャにも拡張され受け継がれた。NetBurstでは、命令キャッシュがx86命令ではなくRISC風uOPsを格納するトレースキャッシュとなり、ますますRISC風のステージが増えた。RISC化が行き着いたのがNetBurstだった。
CISC→RISC変換方式は、こうしてx86 CPUで花開いていったわけだが、プロセス技術が0.13μm(130nm)に達する頃から問題が浮上してきた。プロセスが微細化しても、消費電力が下がらなくなり、CPUのパフォーマンス/電力効率が最重要になり始めたためだ。そして、NetBurstの効率が悪い理由の1つは、RISC風uOPsに変換してしまう点にある、とIntelは考えた。
NetBurstでは、フロントのデコーダでCISC x86命令からRISC風uOPsに変換して以降は、パイプライン中は常にRISC風uOPs単位で扱われる。RISC風uOPsに分解することで、CISC時よりも命令数が増えるために、パイプライン内部では命令スロットや命令制御などのCPU内リソースが膨大に必要になる。パイプライン全体に渡ってリソースを食うので、これはばかにならない量となる。CPUが肥大化する最大の原因になっていると言われる。
NetBurstは、パイプライン中は3 uOPs/サイクルの帯域なので、元のCISCのx86コードに換算すると、並列度は3命令/サイクル以下となってしまう。そこで、NetBurstでは、パイプラインを細分化して、高クロックで回すことで、3 uOPs/サイクルの帯域でもパフォーマンスを得ている。しかし、パイプラインを細分化することで、リソースを費やしてしまっている。
乱暴な言い方とすると、NetBurstでは、RISC風uOPs変換を追求したために、パイプライン中では、リソースを食うというRISCの難点もひきずってしまったわけだ。そして、リソースは消費電力に換算される。CPUの消費電力が許容枠内だった時代は、それも許容できた。しかし、CPUの消費電力が天井に達すると、RISC変換で生じる無駄は、荷物になり始めた。
●RISCにしないことこそCore MAの最大のポイント
Core MAでは、この問題を“RISC風に分解しないこと”で解決している。Intelは何にでも名前をつけるので、これにも“Micro-OPs Fusion(最近はMicro-Fusionと呼ばれる)”とつけている。Micro-OPs Fusionは、Banias(バニアス)マイクロアーキテクチャ(Pentium M)から採用され、Core MAでほぼ完全な姿になった。BaniasよりCore MAの方が、より多くのx86命令を、1個のFused uOPsとして扱うことができる。
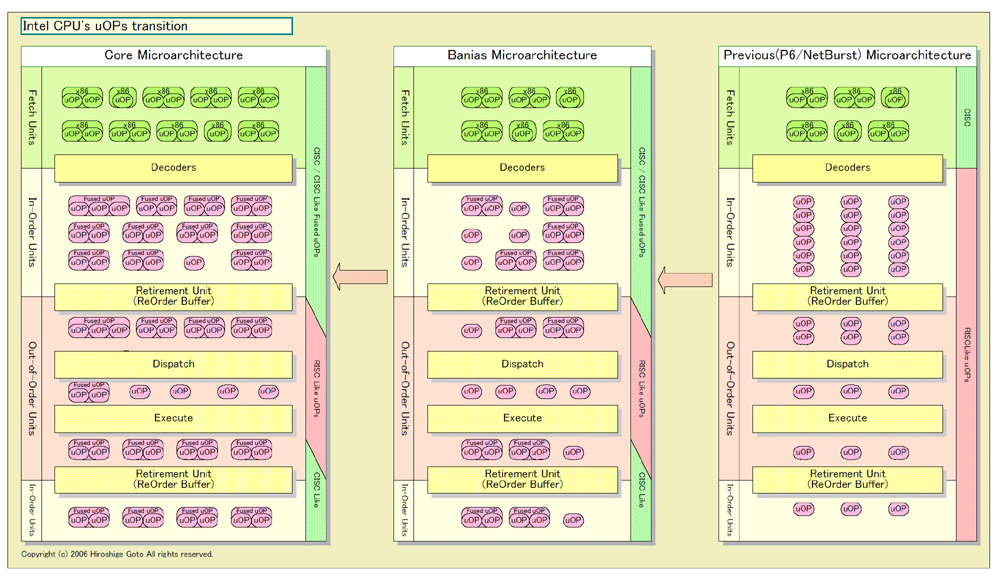 |
| Intel CPU's uOPs transition (※別ウィンドウで開きます) PDF版はこちら |
知られているように、Fusion(融合)と呼んでいるのは、複数のRISC風uOPsを1個のuOPsに融合させるという概念からだ。だから、Core MAでの、複合uOPsは「Fused uOPs」と呼ばれている。しかし、実態は、比較的単純なCISC型x86命令を、1対1でFused uOPsに変換しているに過ぎない。つまり、CISC命令を分解しないことがMicro-OPs Fusionの本質だ。
「Micro-Fusionでは、CISC命令(の変換)を、より複雑なフォーマットのuOPsに保ち、少ないuOPs数を維持する。それによって、C dynamic(ダイナミックキャパシタンス)を低く保ち、消費電力を抑える」
「Core MAでは、やや複雑なx86 命令、例えば、『レジスタ-メモリ間の加算(ADD Register, Memory)』が(Fused uOPsで)できる。これらのオペレーションを、(uOPsに分解しないで)1つのバンドルにまとめてしまう。だから、もはや内部RISCプロセッサではない。しかし、(まるっきり)CISCというわけでもない。見方によっては、非常にシンプルなCISCと考えることができる。コモンな2つのuOPsを、1つの(Fused)uOPsにまとめてしまうからだ」とValentineは語る。
つまり、Core MAではMicro-OPs Fusionによって、従来なら複数のRISC風uOPsに分解していたx86命令を、1個のFused uOPsに変換する。Fused uOPsは、複数のuOPsを含む、ある意味でCISC風の構造となっている。例えば、レジスタ-メモリ間の加算の例なら、従来のRISC風uOPsでは、メモリからレジスタへのロードuOPと、レジスタ間の加算uOPの2つに分解されていた。Core MAでは、それを、1個のFused uOPとしてまとめて扱うわけだ。
そのため、RISC風uOPsに分解していた時と比べると、パイプライン内部でのuOPs数を大きく減らすことができる。結果、パイプラインの回路規模が減って、電力を消費するダイナミックキャパシタンスを増やさずに、IPC(instruction per cycle:1サイクルで実行できる命令数)を高めることが可能になるというわけだ。
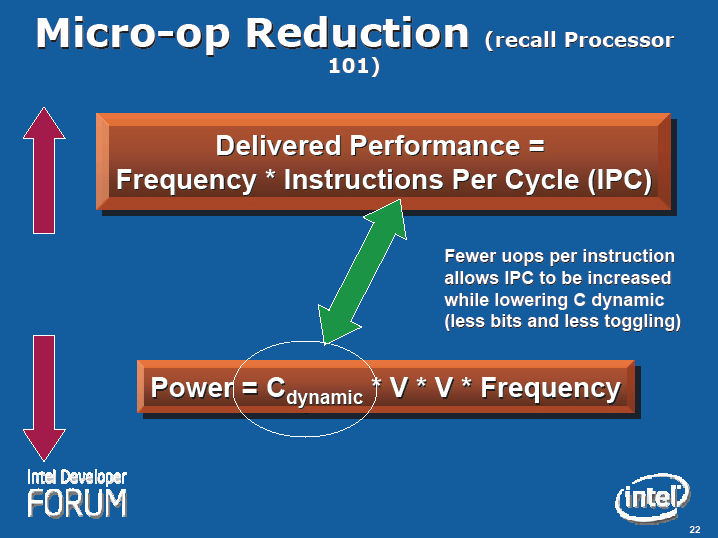 |
| Micro-op Reduction (※別ウィンドウで開きます) PDF版はこちら |
●最後の最後だけRISC風uOPsとして実行
もっとも、パイプラインを通してCISC風uOPsにすると、CISCのx86命令をネイティブ実行するのと同じように、高速化が難しくなってしまう。レジスタ-メモリ間の加算の例なら、メモリからのデータを待つ間、実行ユニットがアイドル状態になってしまう。そこで、Core MAでは、最後の最後でFused uOPsを分解する。
「Micro-OPs Fusionでは、(x86命令を)複雑なFused uOPsにデコードしている。Fused uOPsに融合されているuOPsは、各クロックサイクル毎に一緒(にパイプラインを流れる)。しかし、実際には、実行自体は2 uOPsとして行なわれる。再スケジュールを行なってから実行しており、依然としてアウトオブオーダ型マシーンのままだ」とValentine氏は言う。
Core MAでは、実行ユニット群にuOPsを発行する直前まで、CISC風のFused uOPsに留め、土壇場で、ようやくRISC風のuOPsに分解するわけだ。RISCの利点は、やはり活かすのだが、RISC風uOPsとして扱うステージを出来る限り少なくしている。
Valentine氏によると、各実行ユニットにそれぞれリザベーションステーションが設けられているという。Fused uOPsの分解と再スケジューリングが行なわれるのは、その直前と見られる。分解されたuOPsは、リザベーションステーションで待機して、実行できる組み合わせで発行される。考えようによっては、「x86命令→Fused uOPs→uOPs」と、2段階でデコードされたと見ることもできる。もっとも、実際には最初のデコードの段階で、後段で分解しやすいようなフォーマットにされているという。
Core MAでは、4個のx86命令を1サイクルでデコードし、4 uOPs/サイクルのパイプライン帯域で回す「Wide Dynamic Execution」が強調される。しかし、こうして見ると、それ以前に、内部命令がFused uOPsになることで、より高効率になっていることがわかる。NetBurstでは、3 uOPs/サイクル。ところが、Core MAでは、4 Fused uOPs/サイクルなので、uOPsに換算すると、ピークのuOPs/サイクルははるかに多くなる。つまり、NetBurst→Core MAでは、3が4になった以上に大きな差が存在する。
こうして見ると、Core MAのパイプラインでは、できる限り、CISC風のアーキテクチャを維持しようとしていることがわかる。RISC風に置き換えるのは最小限。これは、CISCの部分はパイプライン中で最小限に留め、できる限りRISCにしようとしたNetBurstとは対極だ。NetBurstまではRISCの利点を活かすことを主眼にしたが、Core MAでは発想を逆転させ、CISCの利点を活かそうとしている。
CPUのマイクロアーキテクチャの要(かなめ)となるuOPs。そのuOPsに着眼すると、Core MAは、これまでのIntel CPUと全く逆の方向へと向いたアーキテクチャであることがよくわかる。AMDは、K7/K8アーキテクチャで、すでにある程度似たような方向へ向かっていた。これもまた、トレンドで、CISC対RISCの論争がはるか後ろへと遠のいたところで、再び、CISCへと揺り戻しの時代がやってきたようだ。
□関連記事
【3月11日】【海外】明瞭になった「Core Microarchitecture」の全貌
http://pc.watch.impress.co.jp/docs/2006/0311/kaigai249.htm
【3月9日】【海外】Intelの次世代CPUアーキテクチャ「Core Microarchitecture」
http://pc.watch.impress.co.jp/docs/2006/0309/kaigai248.htm
【2004年3月10日】【海外】これが真のNetBurstアーキテクチャだ
http://pc.watch.impress.co.jp/docs/2004/0310/kaigai072.htm
(2006年6月26日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.