 |


■後藤弘茂のWeekly海外ニュース■物理シミュレーションで現実化し始めたGPGPU |
●フィジックスシミュレーションをGPUで
リアルタイムのフィジックス(物理)シミュレーションが、昨年から今年にかけての潮流になりつつある。フィジックスシミュレーション専用に設計されたPPU(Physics Processing Unit)が登場し始める一方、GPU上でフィジックスシミュレーションを行なうデモも本格化。フィジックスシミュレーションのハードウェアアクセラレーションが一気に現実化し始めた。
そのため、フィジックスシミュレーションに最適なのは、PPUかGPUか、あるいはCPUか、という議論が巻き起こっている。また、この動きは、GPU上で汎用プロセッシングを行なうGPGPU(General-Purpose GPU)の本格的な第一歩であり、GPGPUの行方を占うカギでもある。ちなみに、“物理”という単語は、後述するプロセッサの“物理”的な実装の話と混同しやすいため、この記事ではシミュレーションの場合はフィジックスと表記している。
 |
 |
| 3月のGDCで発表されたPPU。AGEIA「PhysX」 | 5月登場予定のPhysX搭載カード |
フィジックスシミュレーションの応用分野は広いが、現在話題になっているのは、3Dゲーム中で使うリアルタイムの物理効果のシミュレーションだ。PPUもGPUも、ゲーム内のフィジックスを最初のターゲットにしている。ハードウェアでアクセラレートすることで、フィジックスシミュレーションを、より広汎な「エフェクツフィジックス(Effects Physics:FX Physics)」に広げようとする。
エフェクツフィジックスは、効果型物理シミュレーションと訳すのが正しいだろうか。ゲームプレイの中で副次的に発生したり、環境的に発生する物理シミュレーションを指す。フィジックスシミュレータメーカーのHavokは、エフェクツフィジックスの例として煙や霧、破片、流体、布といったオブジェクトの物理を挙げていた。ビルから瓦礫が崩れたり、液体が流れ落ちたりといった効果が、このカテゴリに入る。
エフェクツフィジックス型のシミュレーションタスクでは、膨大な数のオブジェクトの3D空間座標に対する演算が必要となる。また、エフェクツフィジックスは、並列化が可能なので、並列に演算ユニットを多数備えた方が有利となる。しかも、空間座標を扱うため、SIMD(Single Instruction, Multiple Data)型の浮動小数点演算が中心となる。SIMD浮動小数点演算ユニットを多数備えたGPUを、フィジックスシミュレーションに転用しようという発想が生まれたのは自然な流れと言える。
●HavokがGPUに移植したエフェクツフィジックス「HAVOK FX」
GPU上でのフィジックスシミュレーションは、2005年3月の「GDC(Game Developers Conference)」から登場し始めていた。昨年の段階では、流れ落ちる血糊や雨粒の物理運動をシミュレートする程度だったのが、より広汎で汎用的なエフェクツフィジックスに広がったのが今年のトレンドだ。今年のGDCでは、フィジックスエンジンを以前から開発しているHavokが、NVIDIAと共同開発したGPU向けの「HAVOK FX」のデモを行なった。
デモでは、キャラクタが動くにつれて煙幕が切れたり、キャラクタの動きに応じて膨大な数のゴミがかき分けられるといった、これまでのフィジックスでは実現できなかった効果が示された。Havokは、ゲーム中のプレイヤの操作によって直接的に生じる物理運動のシミュレーションを、CPU上の「HAVOK 4」エンジンで実現している。両エンジンが連携しながら、より広汎なHAVOK FX部分をGPU側で行なうという分散コンピューティングとなる。それに対して、PPU(Physics Processing Unit)でフィジックスを行なうAGEIAは、全てをPPU上で処理する。
GDCでのHAVOK FXのデモは、NVIDIA SLI上で行なわれた。1枚のビデオカードでグラフィックスを処理、もう1枚のビデオカードでフィジックスシミュレーションを行なうといった具合だ。3DグラフィックスをSLIで2枚のビデオカードに分散する場合は、パフォーマンスが上がらないケースも多い。しかし、フィジックスを2枚目のカードに割り当てる場合は、フィジックスがグラフィックスから独立した処理となるため、SLIによるコンピューティングパワーの増加をフルに活かすことができる。SLIにとっては、うまい使い方ということになる。
●汎用性のあるHAVOK FXの実装
 |
| NVIDIAのDavid B. Kirk氏 |
NVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)は次のように説明する。
「SLI自体は要求項目では全くない。フィジックス専用(のビデオカード)が必ずしも必要というわけではない。同じShaderコアで実行できる。なぜなら、フィジックスもシェーダ(プログラム)の1つに過ぎないからだ。グラフィックスとは異なるタイプのシェーダだ。だから、1つのGPUで、ある時はグラフィックス、別な時はフィジックスを走らせることができる」
現状でSLIを使っているのは、単純にパフォーマンスのためだという。GPU側のパフォーマンスが上がれば、タイムシェアリングで、3Dグラフィックスとフィジックスの両方のタスクを走らせることが可能となる。
「SLIの素晴らしい点の1つは、フレキシビリティだ。現在はSLIをターゲットに開発している処理が、来年にはシングルGPUに簡単に持っていくことができる」
NVIDIAはめざとく他社に先行してHavokに開発支援を行ない、一定期間の独占契約を結んだため、現在、Havokは公式にはNVIDIAプラットフォームでしかデモを行なっていない。しかし、Havokによると、同社のGPU用エンジン自体はシェーダで実装されており、GPUのネイティブISA(命令セットアーキテクチャ)を使っていないという。GPUはそれぞれ独自のISAを持っているため、ISAでコーディングすると依存性があるが、シェーダはドライバで変換されるため依存性が薄い。そのため、Havokのエンジンは、原理的には汎用に多種のGPU上で走らせることができる。
あるGPU関係者によると、「NVIDIAとHavokの独占契約は今夏には切れる。それ以降は、他社のGPUでも公式に使えるようになる」という。
実際、ATIも今回のHAVOK FX on SLI的なアイデアを、以前から語っていた。例えば、ATI TechnologiesのRich Heye(リッチ・ヘイズ)氏(Vice President and General Manager, Desktop Business Unit)は、2005年9月に行なったカンファレンス「Tech Day」で次のように語っている。
「デュアルGPUで、2つのGPUのうち、GPUナンバー1がグラフィックスを担当し、GPUナンバー2がフィジックスを担当するといったことも可能になる。同じマザーボードのPCI Expressスロットに2枚のカードを挿すだけで、何も特別なことをする必要がない。フィジックスをやらせても、パフォーマンスが落ちる心配がなくなる。同じカードを揃える必要もない」
ATIも、ほぼ同じ構想を持っていることになる。ただし、こう言いつつ、NVIDIAにHavokとの契約で先を越されてしまうあたりが、ATIの弱点だ。
●GPUでは効率的な処理が難しいフィジックス
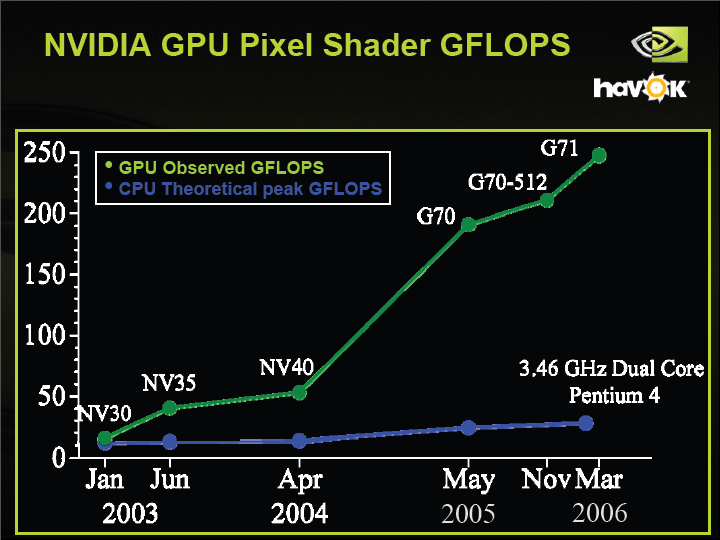
HavokがGPUにエフェクツフィジックスのエンジンを移植したのは、GPUの方がSIMD型の浮動小数点演算パフォーマンスがはるかに高いからだ。現状ではフィジックスエンジンに使えるのはPixel Shader側。GeForce 7900 GTX(G71)は24個Pixel Shaderに、4wayのSIMD演算ユニットとスカラ演算ユニットをそれぞれ48個を備える。浮動小数点演算の並列度では、GPUの方がCPUより遙かに高い。
GPUとCPUのギャップが開いた理由は明快で、CPUが動作クロックの向上につまづいてパフォーマンス向上が滞った間も、GPUはひたすら並列度を上げていたからだ。GPUでは、膨大な数の頂点やピクセルを処理するため、並列化に特化しており、そのパワーをフィジックスにも応用できる。伝統的な汎用CPUに対しては、GPUは圧倒的な利点を持つ。
「GPUはフィジックスを効率的に実行できる。なぜなら、グラフィックスはフィジックスよりずっとハードな処理だからだ。フィジックスでは数千あるいは数万のオブジェクトを扱うだけだが、グラフィックスでは数億のポリゴンやピクセルを扱う。ずっと複雑で、スケールが大きい。だから、グラフィックス処理向けに設計したエンジンなら、フィジックスにも十分に対応ができる。GPUは知的なマッチョだ」とNVIDIAのKirk氏は語る。
ただし、実際にはフィジックスのタスクは、GPUの並列エンジンでの実行に必ずしもフィットするとは言い難い。GPUの扱うグラフィックスデータの場合、大量のデータに対してストリーム的に一連の処理を行なう。各頂点とピクセルは、それぞれ独立しており依存性がなく、並列化がしやすい。そのため、パイプラインレイテンシは重要ではなく、スループットが問題となる。GPUは、こうしたストリーミングデータタイプに最適化されて設計されている。
ところが、フィジックスシミュレーションでは要求される要素がかなり異なる。まず、フィジックスではオブジェクト間の相互作用を演算する必要があるため、オブジェクト間に相互依存性がある。運動するオブジェクトが他のオブジェクトに衝突(Collision)、その結果、衝突されたオブジェクトが次々に動き、さらに他のオブジェクトに衝突するといったタスク群を演算する必要があるためだ。相互依存のないオブジェクト同士の衝突は並列に演算できるが、連動する衝突は依存性がある。タスクが独立していないため、グラフィックス処理とはかなり性格が異なる。
GPU上では、オブジェクト同士の衝突のうち、相互依存のない複数のリンクを並列に実行し、次に別なリンク群を実行と、数サイクルに渡ってリンク群の演算を繰り返してフィジックスを実行している。オーバーヘッドはそれなりに大きいはずだが、GPUは、PPUを上回る数の演算コアを使うことで、フィジックスシミュレーションを実現している。“知的なマッチョ”というのは、まさに正しい表現だろう。
 |
| AGEIAのManju Hegde氏 |
「我々のプロセッサは(GPUのような)ストリーミングプロセッサではない。フィジックスではストリーミング型のデータ構造ではないからだ。例えば、オンチップのメモリ帯域が重要となる。演算で使うデータはオンチップに載せる(ことで高速化を図っている)からで、PPUでは2Tbit/secの内部メモリ帯域を持つ」とAGEIAのManju Hegde氏(Co-Founder, Chairman and CEO)は語る。
GPUも内部に各種キャッシュを持つが、PPUほどの帯域は備えていないし、PPUのように明示的に使うことができない。AGEIAの特許を見ると、PPUでは内部メモリの1つ「Inter-Engine Memory (IEM)」にリードとライトで合計32ポートを備えるなど、極端に広いメモリ帯域を備えている。演算ユニットと内部メモリ間を、膨大なクロスバスイッチで相互接続することで、高速かつ広帯域の演算用メモリを実現するアーキテクチャだ。
●まだ汎用コンピューティング向けではないShaderの実装
GPUのProgrammable Shaderの演算コア自体の物理的な実装も、現状ではフィジックスシミュレーションのようなGPGPUに向いていないとHegde氏は指摘する。
「GPUでは(Programmable Shaderの)汎用レジスタの数が極めて少ない。これは、フィジックスのように、複雑なデータ構造に対して、異なる複数のアルゴリズムで処理を行なう場合には、特に問題となる。PPUでは、そのために多く(のレジスタ)を備えている」とHegde氏は指摘する。
GPUの場合、シェーディング言語はトランスレートされてしまうため、通常はShaderコアの物理レジスタは隠蔽されている。しかし、実際には、Shaderの物理レジスタは、かなり限られているケースが多い。そのため、シェーダプログラミングでは、一定数以上のレジスタを使うとパフォーマンスが大きく削られることが知られている。GPGPUでは、一般にグラフィックス処理よりも多くのレジスタを使うため、これが問題となる。
また、GPUによってレジスタ数の違いが大きいことも、問題を複雑にしている。2005年9月にATI Technologiesが行なった「Tech Day」カンファレンスでは、GPGPUの研究者Mike Houston(マイク・ヒューストン)氏(Stanford University)が登場、ATIのRADEON X1800(R520)系のGPGPU上の利点としてShaderのハードウェアレジスタ数が32本であることを挙げた。Shaderの実レジスタ数は、通常GPUベンダーからは公表されていないが、Houston氏は次のように説明した。「NVIDIAハードウェアで(GPGPUを行なう場合)の問題点の1つは、ハードウェアレジスタが少ないこと。我々が書いた(GPGPU)タイプのアプリケーションでは8レジスタ以上を使うので、パフォーマンスでの問題があった」
つまり、Shaderの実装自体も、まだGPGPUへの最適化で足並みが揃っているわけではない。この他、今のGPUは、外部メモリのレイテンシやアクセスパスも、CPUやPPUのような汎用処理向けの自由度を持っていない。例えば、データのフェッチは、テクスチャパスを使って行なう必要がある。
●DirectX 10世代のUnified-Shaderアーキテクチャがフィジックスを容易に
ただし、現在、GPUが抱えているこうしたGPGPU上の問題は、将来的には軽減されていくだろう。それは、GPUの構造がよりGPGPUに向いたアーキテクチャへと変化してゆくからだ。
DirectX 10世代GPUでは、ATIとS3 Graphicsは、アーキテクチャ的に統合されたShaderコアアレイで、各種Shaderの機能を実現するUnified-Shader型の実装を採る。NVIDIAは、初期のDirectX 10世代は従来通りの独立型のShader構成を取るが、将来的にはUnified-Shaderへと移行していくことを示唆している。
Unified-Shaderのゴールは、どのShaderでも同じ処理を同パフォーマンスでできるようにし、メモリアクセスもShaderアレイからダイレクトにできるようにする。演算パイプも、原理的には、より短レイテンシになる。さらに、GPUベンダーが、Unified-Shader化とともに物理レジスタ数を増やすといった最適化を行なうと、GPGPUがより快適に実現できるようになる。
また、GPUベンダーが、演算レイテンシなどの情報を公開したり、GPGPU向けのAPIセットを共通化したり、さらにネイティブISAでのアクセスをオープンにすれば、もっとGPGPUはやりやすくなる。GPUベンダーが、すぐにこうした動きに転じるとは思えないが、見据えていることは確かだ。
例えば、NVIDIAのKirk氏は、ネイティブISAでのGPGPUプログラミングについては「今回ではない(Not this time)」と含みを残した言い方をする。ATIのHeye氏も、グラフィックス向けではないAPIの必要性を認識していることを、昨年のTech Dayで表明している。また、OpenGL ESなどのAPIの規格化を進めるKhronosのNeil Trevett氏(President, Khronos Group; Chairman, OpenGL ES Working Group; Vice President Embedded Content, NVIDIA)は、Khronosのメディアプロセッシング向けAPI「OpenMAX」とグラフィックス向けAPI「OpenGL/OpenGL ES」が、同じGPU上で併用されることも、起こりうるだろうと語る。OpenMAXは、構想ではフィジックスシミュレーションも視野に入れている。
GPGPUへ向けて、徐々に形を整えつつあるGPU。GPUの利点は、高パフォーマンスが必要な3Dグラフィックスに最適化したハードを、汎用プロセッシングに転用していく点。ニーズが強い分野でインストールドベースを構築するため、PPUと異なり普及の問題がない。3Dのニーズで浸透させた上で、ハードを汎用に応用分野を広げていく戦略だ。NVIDIAのJen-Hsun Huang氏(Co-founder, President and CEO)は、昨年、こうしたGPUの戦略を「GPUは21世紀のDSPになる」と表現した。つまり、DSPのように汎用途に使われるようになると宣言したわけだ。
●フィジックスシミュレーションのニーズ
 |
| ATI TechnologiesのDinesh Sharma氏 |
ただし、現在のGPUの浮動小数点演算精度は32bit単精度。それに対して、CADや科学技術系のフィジックスシミュレーションで要求されている精度は、大抵の場合、64bit倍精度以上。実際には、そっくりタスクを持って来ることはできない。こうした事情は、同様に32bit単精度と見られるAGEIA PPUも同様だ。
ちなみに、倍精度のフィジックスシミュレーションのシステムでは、日本発の科学技術計算用の「GRAPE」がある。ただし、こちらは今の段階では、価格帯的に同レベルにあるシステムではない。
GPGPUの議論では常に出てくる問題だが、現状では演算精度が汎用途への応用への壁となる。ゲームやOSのUIといった、広いニーズにターゲットを合わせたシステムは、ボリュームが見込めるため低価格にできる。しかし、ゲームやUIといったニーズでは、現状は単精度までしか必要としないため、GPUやAGEIA PPUは倍精度演算ユニットは実装しない。倍精度の演算ユニットを実装すると、載せられる演算コアの数が半分になってしまい、演算パフォーマンスが半分になってしまうという事情もある。
そのため、GPUやAGEIA PPUは、倍精度/拡張倍精度がデフォルトとなるような用途には応用が広げにくい。これは、GPUやPPUだけの問題ではなく、単精度の性能は高いものの、倍精度演算が遅い「Cell」プロセッサも同じ問題を抱えている。GPGPUやPPU、Cellといった、SIMD型浮動小数点演算に特化したアーキテクチャが、今後、どう花開くかは、応用分野の開拓に依存している。
| 2006のGDCでNVIDIAが行なったHavok_FXの発表資料 | |
|---|---|
 |
 |
| Why Physics on GPUs? PDF版はこちら |
NVIDIA GPU Pixel Shader GFLOPS PDF版はこちら |
 |
 |
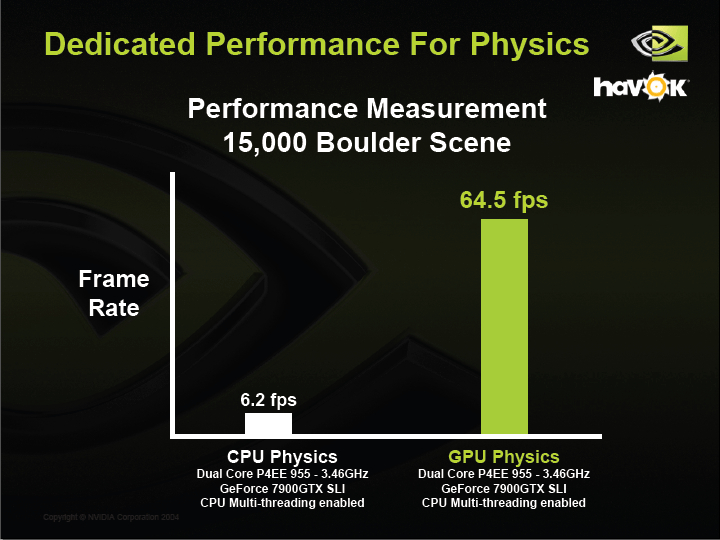
| Dedicated Performance For Physics PDF版はこちら |
Physically-based Simulation on GPUs PDF版はこちら |
 |
 |
| Havok FX Features Overview PDF版はこちら |
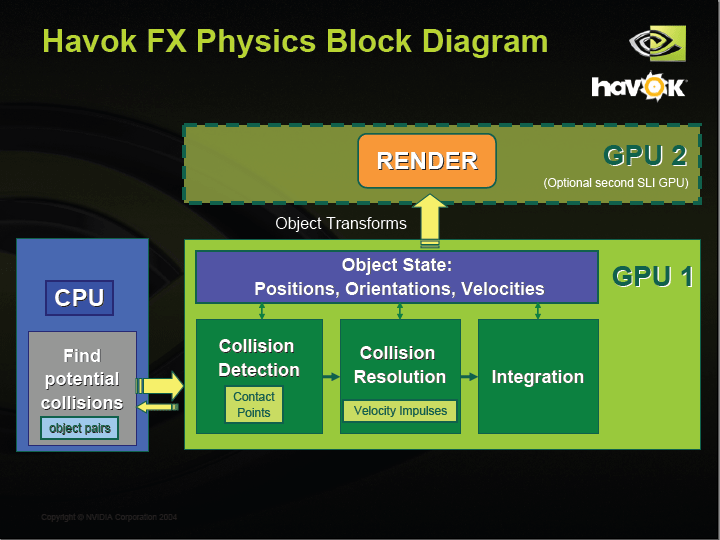
Havok FX Physics Block Diagram PDF版はこちら |
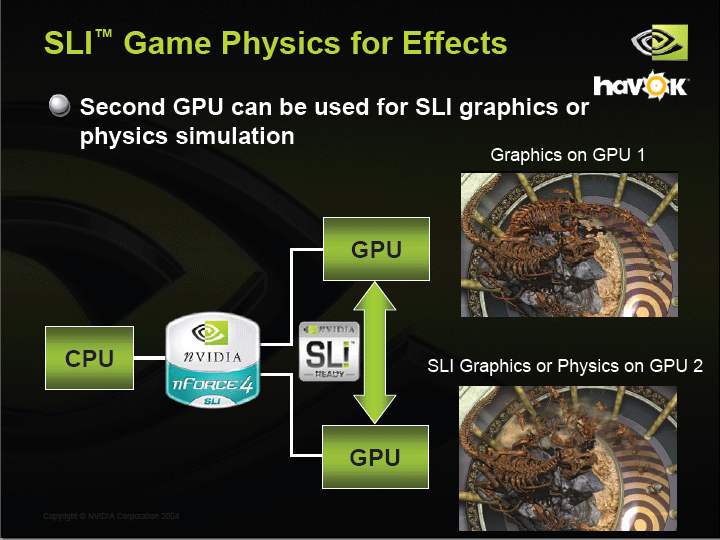 |
| SLI Game Physics for Effects PDF版はこちら |
□関連記事
【4月7日】【海外】物理シミュレーションをハードで実現するAGEIAの「PhysX」
http://pc.watch.impress.co.jp/docs/2006/0407/kaigai259.htm
【2005年4月26日】【海外】WGF2.0時代の次世代GPUのアーキテクチャはこうなる
http://pc.watch.impress.co.jp/docs/2005/0426/kaigai174.htm
【2003年12月26日】【海外】5年後に“GPUスパコン”の時代がやってくる!?
http://pc.watch.impress.co.jp/docs/2003/1226/kaigai054.htm
(2006年4月12日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.