 |


■後藤弘茂のWeekly海外ニュース■物理シミュレーションをハードで実現するAGEIAの「PhysX」 |
●グラフィックスが向上した結果フィジックスが重要に
 |
| GDC 2006の会場となったMcEnery Convention Center |
時代はフィジックス(物理)シミュレーションだ。米サンノゼで、3月20日から24日にかけて開催されたゲームデベロッパ向けカンファレンス「GDC(Game Developers Conference)」の、今年の話題はフィジックスだった。フィジックスシミュレーションをGPU上で実現するデモが登場する一方、フィジックスシミュレーションを専門に行なうPPU(Physics Processing Unit)も製品発売に向かう。
ゲームで言うフィジックスシミュレーションとは、大まかに言うと3Dオブジェクトの運動物理をリアルタイムにシミュレートすること。3D空間の中のさまざまなオブジェクトが物理法則に従って運動しているように見せる。現実世界では、石を投げれば重力に従って放物線を描き、クルマがぶつかれば人が跳ねとばされる。そうした動きを、仮想世界の中で、できるだけ正確にシミュレートする。物理的に正しい3D空間を作ろうとする流れだ。
ちなみに、“物理”という単語は、後述するプロセッサの物理的な実装の話と、ちょっと混線しやすいため、この記事ではフィジックスシミュレーションと書くことにする。
フィジックスシミュレーションへの流れは、2005年春から盛り上がっていた。2005年のGDCでは、PPUを開発した米AGEIAが出展し話題をさらった。また、この頃からゲームコンソールベンダーのMicrosoftとソニー・コンピュータエンタテインメント(SCEI)の双方が示し合わせたかのようにフィジックスシミュレーションを強調し始めた。両社は、ともにフィジックスエンジンを開発するベンダーの取り込みを図り、自社プラットフォームへの移植を加速させた。ゲーム業界では、次のフロンティアはフィジックスにある、といった雰囲気だ。
なぜフィジックスシミュレーションがゲームで重要になったのか。理由は簡単だ。3Dグラフィックスのクオリティが上がったからだ。
グラフィックスがリアルになったら、それに見合うだけのリアルな動きがなければ、ゲームが不自然に見えてしまう。リアル度の高い3D世界の中で、モノが不自然に運動したり、キャラクタが不自然な挙動をすると、ぶちこわしになりかねない。3Dグラフィックスのレベルが上がり、ゲームのグラフィックスが記号的なものではなく、現実を模したものになると、グラフィックス以外の要素もリアルでないと違和感が強くなってしまう。そのため、シミュレーションやAIが、より重要になるという構図だ。
中でもフィジックスシミュレーションが注目されているのは、リアリティに対する効果が大きい一方で、演算負荷が高く汎用CPUでは実現しにくいからだ。AIなどが汎用CPUでやりやすい処理なのに対して、フィジックスシミュレーションは広汎に行なおうとすると膨大な演算量になるため、PC向けの汎用CPUには重過ぎる。
そこで、解決策として、汎用CPUではなく、GPUや専用に開発されたPPUを使おうという話が浮上してきた。GPUやPPUを使うことで、従来型のCPUでは実現しにくいレベルのフィジックスシミュレーションが実現できるとなって、話が盛り上がってきたわけだ。
●フィジックス演算に特化した専用プロセッサPPU
特に話題をさらってきたのは、専用のPPU「PhysX」を開発したAGEIAだ。PhysX搭載カードも、ASUS(ASUSTeK Computer)などから5月に登場する予定となっている。PPUが、いよいよ現実の段階に入ってきたわけだ。
 |
 |
| AGEIA「PhysX」 | 5月登場予定のPhysX搭載カード |
PPUは、GPUがグラフィックスをアクセラレートするように、フィジックスシミュレーションをアクセラレートする。グラフィックスに特化したGPUと異なり、フィジックスに特化しているため、PPUでは効率的にフィジックス演算を実現できるとしている。
現在、AGEIA自身は、PPUのアーキテクチャ概要を明らかにしていない。しかし、AGEIAの開発者がいくつかの特許を米国で申請しており、そこからアーキテクチャがある程度は類推できる。すでに特許内容の一部は、Webメディアである程度露出しているが、特許から見えるPPUは、部分的にCellプロセッサに似ており、現在のGPUとはかなり異なる。
下が、特許から推定されるPPUの想定図だ。PPUは1個の制御用プロセッサコア「PPU Control Engine(PCE)」と、複数のデータ演算用プロセッサコア「Vector Processing Engine(VPE)」、1個のデータの移動を制御する「Data Movement Engine(DME)」といったユニットが並ぶと推定される。PPU全体の制御を行なう、汎用的な命令セットのプロセッサが1個あって、それが、ベクタ/スカラ型の浮動小数点演算エンジンを載せた多数のデータプロセッサを管理するようなイメージだ。
 |
| 特許の一例から推測されるAGEIAのPPU (別ウィンドウで開きます) PDF版はこちら |
 |
| AGEIAのManju Hegde氏 |
もっとも、特許に記述されているハードウェア構成は、実際のPPUとは完全には一致しない可能性も高い。AGEIAのManju Hegde氏(Co-Founder, Chairman and CEO)は、基本コンセプトは特許にあることを認めながらも「特許と実際の実装は必ずしも同一ではない」と指摘する。
また、AGEIAの特許は複数あり、PPUの構成についての記述も特許とその出願時期によって多少異なっている。ここに示した図は、出願の日付が最も新しい特許にあった構成をベースとしているが、これと若干異なる構成や、異なる構成ユニット間の区分や名称を記した特許もある。
そのため、ここに示した構成は、あくまでも特許からの“想定”でしかない。特に、実際のPPUの、演算プロセッサの数や構成などは不鮮明だ。しかし、各特許で共通する特徴も多い。特に、PPU全体の基本的な構成やフローは共通しており、この図で示したような特徴は、実際のチップにも受け継がれていると推定される。
●制御用プロセッサと演算プロセッサアレイを分離
実際のPPUが、全体を制御するプロセッサ「PPU Control Engine (PCE)」を備えていることはほぼ確実だ。PCEは、汎用のRISC系CPUコアを含んでおり、特許文書ではMIPS64が好ましい例として挙げられていた。これは、命令セットの拡張が容易かどうかという点も絡んでいるのかもしれない。PCEは、ホストのCPUからのコマンドを受け取り、ホストとPPU間のコミュニケーションを制御する。つまり、CPU側から見た場合はPCEがPPUのフロントエンドとなる。
PPU内で実際にフィジックス演算を行なうのは複数の「Vector Processing Engine(VPE)」群となる。この構造も、ほぼ確実に実際のPPUに存在すると考えられる。特許文書によっては、これは「Floating Point Engine(FPE)」と総称されている場合もある。VPEもフルプログラマブルなプロセッサ群だ。
このほか、PPU内部の各ユニット間のデータの移動を制御する「Data Movement Engine(DME)」が1基存在する。DMEの実態は、クロスバースイッチとそのコントローラ、VPEに対する命令ディスパッチャ、そしてスレッドスケジューラだ。DMEでは、外部のPPU MemoryとPPU内部メモリ間のデータの転送と、複数の内部メモリの間のデータの転送を制御する。また、PCEからVPEへの命令を受け取り、VPEに発行し、プログラムの実行を司る。スレッドの管理もDMEの役割だ。
AGEIAは、現在のPPUに含まれるVPEの数や構成は明らかにしてない。AGEIAの特許の1つでは、好適なVPE群の構成は次のように説明されている。PPU内部に合計で4ユニットのVPEが搭載され、それぞれのVPEは4ユニットの「Vector Processing Unit (VPU)」を含む。この例だと、合計で16ユニットのVPUが存在することになる。
また、1ユニットのVPUの中にはデュアルのデータプロセッシングユニットが含まれる例も記されている。1個のデータプロセッシングユニットは、それぞれ1ユニットの「Vector Processor」と「Scalar Processor」を含む。つまり、PPU全体では、合計で32ユニットずつのVector ProcessorとScalar Processorがあることになる。
●SIMD命令を含むVLIW形式のVPUの命令セット
特許文書によると、Vector Processorの構造はフィジックスに最適化されている。1ユニットのVector Processorの中には3個の「Floating-Point execution Unit(FPU)」が含まれ、それぞれ3次元空間座標(x, y, x)の演算を担当する。扱うのは空間座標だけなので、3wayのベクタ演算で十分というわけだ。別な特許では、各FPUは32bit単精度IEEE 754準拠のユニットとなっている。そうすると、ベクタデータタイプは32bit×3の96bitとなる。
一方、Scalar processorには、演算ユニット「Arithmetic Logic Unit(ALU)」、ロード/ストアユニット「Load-Store Unit(LSU)」、分岐ユニット「Branching Unit(BRU)」、プレディケートロジックユニット「Predicate Logic Unit(PLU)」が含まれる。最後のプレディケートユニットは、条件分岐の分岐パスを投機的に実行する場合の制御を行なう。
VPUに対する命令語は、1命令語の中に複数のオペレーションを含むことができるVLIW(Very Long Instruction Word)形式を取ることが望ましいと特許にはある。VPU側の演算アレイの構造自体がベクタ(SIMD)とVLIWのハイブリッドの構造が好ましいという。どういうことかというと、ベクタ(SIMD)命令を含むVLIW型の命令セットアーキテクチャを取るということだ。
特許によると、VPUは64bit固定長のVLIWが望ましいという。命令スロットは2つ。例として1つの命令スロットにベクタ(SIMD)命令、もう1つの命令スロットにスカラ命令を格納した例が挙げられている。つまり、1つの命令語で、1つのベクタ演算と1つのスカラ演算を同時に実行できることになる。
レジスタセットはやや複雑で階層化されている。特許では、各FPU毎に16本のローカルレジスタと8本の共有レジスタを備え、そのほかにグローバルレジスタ「Global Register Unit(GRU)」を持つとされている。ローカルレジスタは主に演算結果をストアし、グローバルレジスタは主にオペランドの格納に使われる。共有レジスタは、異なるVPUからのアクセスが可能となっている。
プロセッサコアが共有レジスタを持ち、他のプロセッサコアからアクセスできる構造はネットワークプロセッサなどで見かける。ちなみに、AGEIAの共同設立者であるHegde氏は、元ネットワークプロセッサメーカーのCTOだった。
●キャッシュ階層を持たないメモリアーキテクチャ
PPUのアーキテクチャ上の大きな特徴の1つは、メモリアーキテクチャだ。PPUは、外部メモリ用に128bitのGDDR3インターフェイスを備えるが、PPU内部にキャッシュメモリを持たない。
「我々はどのようなキャッシュメモリ階層も持たない。これは非常に重要だ。伝統的なキャッシュはフィジックスに馴染まないからだ」とHegde氏は語る。
外部メモリとの間で、セットアソシエイティブ方式で連携を取り、自動的にアップデートするCPUのキャッシュのような構造は、PPUには持たせていないという。フィジックスシミュレーションの場合、データの局在性が薄いためだ。メモリのキャッシュ階層は、かえって邪魔になってしまうからだという。
「CPUやGPUではデータに局在性がある。しかし、フィジックスでは局在性がない。多くのオブジェクトにランダムにアクセスする必要があるからだ。データ構造が全く異なる」とGPUベンダーからAGEIAに移ったNadeem Mohammad氏は語る。
しかし、PPUも、大容量の内部メモリ自体は備える。キャッシュの代わりに、さまざまな内部メモリを備え、内部メモリと外部メモリの間の転送を明示的にプログラマブルに行なう仕組みを取る。
特許にはVPUに接続されたデュアルバンクの「Inter-Engine Memory(IEM)」、多用途に使うことができる「Scratch Pad Memory(SPM)」、命令のキューイング的な役目を果たすと見られる「DME Instruction Memory(DIM)」などのメモリが説明されている。Hegde氏は、特許にあったこれらのメモリがPPUに「多分搭載されているだろう」と、実際の実装でも反映されていることを示唆した。
これらのメモリのうちIEMが、従来のデータキャッシュ的な使われ方をする。特許では、DMEが明示的に、演算ユニット群のオペレートに必要とされるデータセットをIEMにロードするとされている。キャッシュメモリとは異なり、IEMでは低レイテンシのアクセスが可能で、膨大な数の入出力ポートも実装できたと見られる。その結果、PPUでは膨大な内部メモリの帯域を実現できたという。
「フィジックスアーキテクチャで重要な要素の1つは、膨大なオンチップのメモリ帯域が必要になることだ。我々のPPUでは、2Tb(Tera-bit)/secのオンチップメモリ帯域がある」とHegde氏は語る。
簡単に言うと、キャッシュの複雑な制御を外した内部メモリにすることで、PPUではL2キャッシュのサイズで、L1キャッシュのレイテンシと、膨大な帯域を持つ内部メモリを可能にした。そして、これがフィジックスのアルゴリズムには合っているという。
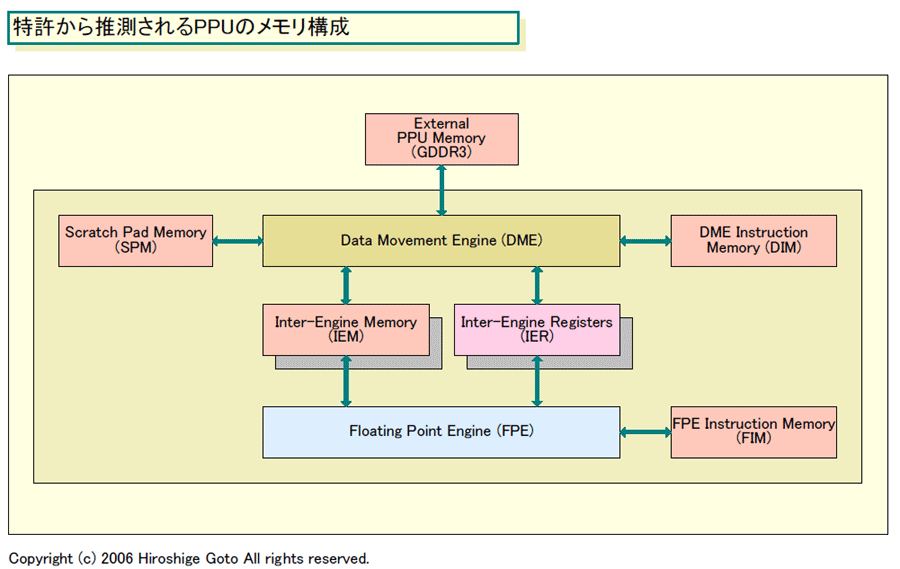 |
| 特許から推測されるPPUのメモリ構成(別ウィンドウで開きます) PDF版はこちら |
●Cellとよく似たPPUの全体構造
PPUのアーキテクチャの概要から、すぐに気がつくのはCellとの共通性だ。どちらも、膨大な浮動小数点演算ユニットを備えた並列プロセッサで、キャッシュ階層を持たず、メモリ間のデータの移動もプログラムで操作する。
PPUのRISCコアである「PPU Control Engine (PCE)」をCellのPowerPCコア「PPE(Power Processor Element)」に、PPUのデータ演算エンジンである「Vector Processing Engine (VPE)」を、Cellのデータ演算プロセッサの「SPE(Synergistic Processor Element)」に置き換えると、ほぼ当てはまる。
どちらも、1個のRISCコアがプロセッサ全体の制御を担当し、多数のベクタ型データ演算プロセッサが並列にデータ処理を行なう。Hegde氏は、アーキテクチャの親和性について、次のように語る。
「非常に高いレベルから見れば両者は似ている。どちらも、膨大な並列エンジンで、浮動小数点演算ユニットを備え、内部メモリを個別に制御する。しかし、違いも大きい。例えば、Cellでは内部のデータ転送をリングバスで行なっている(ため帯域が限られる)。それに対して、我々のアーキテクチャは、Cellよりもずっと大きな(内部データ)帯域を持つ。
とはいえ、Cellはフィジックスプロセッシングに対しては、比較的向いたアーキテクチャであることも確かだ。PS3では、GPUは“GeForce 7900+”のアーキテクチャだが、Cellがある。そのため、PS3では、GPU側ではなく、PPU的なアーキテクチャ(のCell)でフィジックスを行なうことができる」
こうしてPPUのアーキテクチャを見ると、PS3向けライブラリの開発では、AGEIAは比較的馴染みやすいことが想像される。
現在のPPUのトランジスタ数は125M(1億2,500万)で、TSMCの0.13μmプロセスで製造される。チップ規模的にはGeForce FX 5800(NV30)クラスで、製造プロセスも同じ、ダイサイズは約182平方mmとされており、これもNV30よりやや小さい程度。NV30をフィジックス用に載せたと考えれば、それほど間違えていないだろう。
GPUと比較すると、VPUの構成も想像がつく。GPUで120Mクラスの場合、Programable Shader個数は6~12個程度。PPUはGPUと比べると、テクスチャのハンドリングなどがないため、演算ユニット自体はややシンプルになると推定される。そうすると、AGEIAの現在のPPUのVPUも、多くて16個止まりと想像される。
□関連記事
【3月25日】【GDC】西川善司の3Dゲームファンのための物理エンジン講座
~AGEIA PhysX編~物理エンジンアクセラレータの真実(GAME)
http://www.watch.impress.co.jp/game/docs/20060325/physx.htm
【3月23日】AGEIAの物理演算プロセッサ搭載PCがDellなどから登場
http://pc.watch.impress.co.jp/docs/2006/0323/ageia.htm
(2006年4月7日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.