 |


■後藤弘茂のWeekly海外ニュース■Pixel Shaderを3倍にしたモンスターGPU
|
●ピクセルプロセッシング性能の強化に特化したアーキテクチャ
ATI Technologiesが、再びモンスターを産み出した。今回発表したのは、新たなハイエンドGPU「Radeon X1900(R580)」だ。コードネームからもわかる通り、これは2005年秋に投入した「Radeon X1800(R520)」の強化版だ。ATIは、新アーキテクチャGPUを投入すると、その半年後に改良アーキテクチャの派生チップを投入する。R580は、R5xxシリーズの中間リフレッシュアーキテクチャだ。R580の内部アーキテクチャはR520を継承するが、ユニット数を増強、さらにテクスチャパイプに新フィーチャを組み込んだ。
最大のポイントは、Pixel ShaderがR520の16個から48個へと一気に3倍へと増やされたこと。演算コアを3倍にしたことで、演算性能は著しく向上した。GPU全体の演算性能は、R520の272.5GFLOPSに対して、R580は533.8GFLOPSになったという。理論上の演算性能だけを比較するなら2倍の性能のGPUだ。
ユニット数だけで比較すると、NVIDIAのGeForce 7800 GTX(G70)の24 Pixel Shaderの2倍となる。ただし、実際にはPixel Shaderの内部アーキテクチャが両社で大きく異なるため、実際の演算パフォーマンスは単純には比較できない。
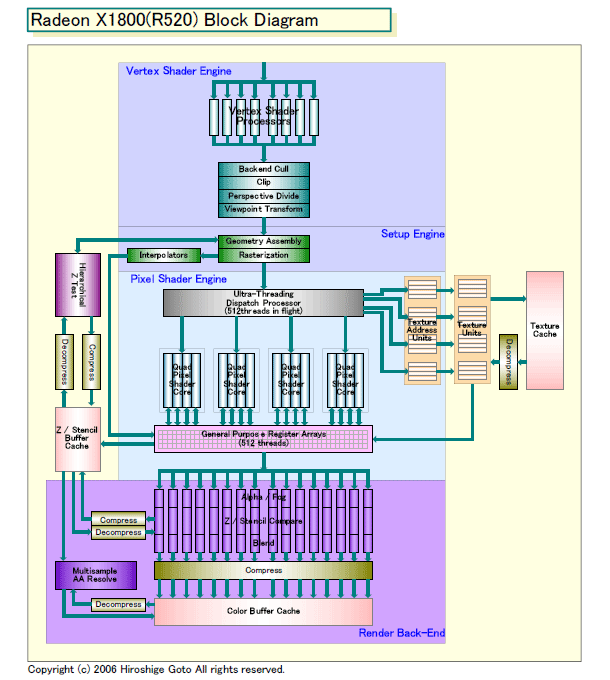
また、図を比較すればわかる通り、R520からR580では、ユニット数が増強されたのはPixel Shaderに限定されている。それも、Pixel Shaderの中の、演算ユニットコア「Pixel Shader Processor(=ALUs)」だけを3倍の48個にした(R520は16個)。その他のユニット、例えば、頂点処理のVertex Shader、テクスチャハンドリングのテクスチャユニット、固定ピクセル処理のレンダバックエンド(Render Back-End)は、いずれもR520と同じユニット数に留まる。
つまり、簡単に言えば、R580は、R520のピクセルプロセッシング性能だけを強化したアーキテクチャだ。従って、原則的には性能向上も、ピクセルシェーディングのコンピュテーションだけに限られる。
その意味では、シェーダプロセッシング性能の強化にフォーカスしたXbox 360 GPUと、ベースの設計思想は若干似通う。Xbox 360 GPUも48個のProgramable Shaderを備えている。しかし、両GPUのShaderコアのアーキテクチャや制御などは全く別物で、類似性は薄い。R580は、あくまでもPCアプリケーション向けのR520の延長にあり、異なる設計思想に立つ。シェーダプロセッシング性能の強化が両GPUで共通するのは、それがグラフィックス業界の全体トレンドだからだ。
| 名称 | Radeon X1900 | Radeon X1800 | Radeon X1600 | Radeon X1300 |
| Code Name | R580 | R520 | RV530 | RV515 |
| DirectX | DirectX 9 SM3.0 | DirectX 9 SM3.0 | DirectX 9 SM3.0 | DirectX 9 SM3.0 |
| Core Clock | 650MHz | 625MHz | 590MHz | 600MHz |
| Memory Transfer Rate | 1,550MHz | 1,500MHz | 1,380MHz | 800MHz |
| Vertex Shader | 8 | 8 | 5 | 2 |
| Pixel Shader | 48 | 16 | 12 | 4 |
| Thread | ? | 512 | 128 | 128 |
| Texture Unit | 16 | 16 | 4 | 4 |
| Render Back end | 16 | 16 | 4 | 4 |
| Transistors | 384M | 320M | 157M | 120M |
●テクスチャパイプはR520と同じ16本
 |
| Radeon X1800(R520) Block Diagram (別ウィンドウで開きます) PDF版はこちら |
ATIのDaniel Taranovsky氏(Product Manager, Discrete Desktop Graphics Group)は、テクスチャユニット数が16と、Pixel Shader Processorの48より少ない理由を次のように説明する。
「数年前までは、イメージクオリティは単純にテクスチャで拡張された。しかし、現在は、ゲームデベロッパはドラマティックに手法を変えている。彼らは、最終カラーデータを得るために、膨大な量の演算を行なうようになっている。そのため、各ピクセル毎のカラー生成のワークロードを検証すると、GPUに取り込む必要があるデータの量は限られると判断した。もし、各Pixel Shader Processor毎にテクスチャユニットを備えると、不必要なペースでテクスチャユニットも増えてしまう」
つまり、以前はGPUの性能やクオリティはテクスチャに依存していた。非プログラマブルなパイプラインでは、ピクセルの最終カラーは、単純なシェーディングとテクスチャを比較的単純にマップすることで得ていた。そのため、ピクセルの演算パイプと同数のテクスチャパイプを備えていないと、ピクセルパイプが必要とするだけのテクスチャのロードができなかった。
しかし、現在のプログラマブルなピクセルパイプでは、ピクセルの最終カラーは、膨大な演算と、それに付随するある程度の量のテクスチャロードで得るように変化している。つまり、単純に絵をポリゴンに貼り付けて終わり、ではなく、ピクセル毎に膨大な演算をして複雑な絵を生成する方向へと向かっている。そのため、ピクセルパイプでは、必要とされる演算の量が増え、相対的に必要なテクスチャの量の比率が減っている。
それなら、テクスチャユニット数を相対的に減らしても性能にインパクトは出ないという判断だ。不要なユニット増加は避け、必要とされるユニットだけを集中的に増やしたらR580の構成になったというわけだ。これは、ATI独自の考え方ではなく、グラフィックス業界に共通した認識で、NVIDIAも同じ方向へと進んでいる。
ただし、R580では、テクスチャユニット自体も一部拡張され、シャドウマッピングなどの処理では効率が大幅にアップしている。これは「Fetch 4」と呼ぶテクニックを実装したからだ。
通常のカラーテクスチャロードでは、テクスチャデータの各ピクセル毎に、1ピクセルを構成する4コンポーネント「RGBA(Red, Green, Blue, Alpha)」をバンドルでロードする。ところが、シャドウマップなどに使われるデプステクスチャの場合は、1ピクセルにつき1デプス(Depth)値しかない。通常は、1回のテクスチャルックアップで1ピクセルのデプス値しかフェッチできないため、非常に効率が悪い。
そこで、R580のテクスチャユニットでは、こうしたテクスチャをフェッチする場合には、4ピクセル分の値をまとめてフェッチできるようにした。隣接するピクセルのデプス値を1回のアクセスでロード、さらに、ロードした値を、テクスチャユニット内でブレンディングするという。その結果、最大で4倍のテクスチャフェッチ効率で、しかも、ブレンドにシェーダの演算ユニット側のリソースを一切使わないで済むという。
つまり、データのロード自体も、アルゴリズムを改善して効率化したわけだ。現在の3Dグラフィックスでは、シャドウイングはシャドウマップがトレンドとなりつつある。それに対応した実装とも言える。
 |
| Radeon X1900(R580) Block Diagram(別ウィンドウで開きます) PDF版はこちら |
●レンダバックエンドパイプも16本
R580ではレンダバックエンドも16本で、これもProcessorの48個の1/3に過ぎない。これについて、Taranovsky氏は次のように説明する。
「X1900のアーキテクチャでは、16のラスタユニット(レンダバックエンド)で、16の個別の命令を、同時に48ピクセルに対して適用することができる。ポリゴンは、少なくとも3ピクセルに分解されるので、こうした構成にした。ラスタユニット自体は16だが、48ピクセルを出力できる」
説明の通りだとすると、R580のレンダバックエンドでは、同じ命令で複数ピクセルを処理することで、最大48ピクセルに対する処理を行なうことができることになる。ただし、この構成での実際のプログラム実行時のスループットはわからない。もっとも、現在のピクセルシェーダ(プログラム)を考えると、48ピクセルのスループットは、おそらく必要がない。
以前の固定パイプラインでは、各ピクセルパイプが、毎サイクル、最終カラーを出力していた。そのため、固定ピクセル処理を担当するレンダバックエンドも、ピクセルパイプと同数備える必要があった。しかし、現在は、ピクセル演算に何サイクルもかかるため、各Shaderからは、必ずしも毎サイクルピクセルが出力されない。NVIDIAは、そのために、レンダバックエンドはPixel Shaderと同数備える必要がないと説明していた。
また、テクスチャパイプとレンダバックエンドは、メモリ帯域に制約を受けるという事情もある。これらのユニットの処理はメモリアクセスを伴う処理であるため、ユニット数を無闇に増やしても、メモリ帯域がボトルネックとなって、性能が上がらない。ATIがバランスドアーキテクチャと言う理由は、このあたりにもあると思われる。
これはGPUに限らないが、オフチップのインターコネクトの制約を受けるメモリ帯域はプロセッサにとって常にボトルネックとなる。特に、ストリームプロセッサであるGPUは、メモリ帯域イーターで、膨大なメモリ帯域を必要とする。しかし、GPUのトランジスタ数とクロックの増大による演算能力の増大に、メモリ帯域の増大を追いつかせることは難しい。
そのため、GPUでは、メモリ帯域を消費するのではなく、演算性能を消費する方向へとアプリケーションを向かわせている。そうしないと、アプリケーション性能が向上しないからだ。つまり、GPUの物理的な制約からも、演算パフォーマンスへの偏重へと向かわざるを得ないわけだ。
R580では、ジオメトリパイプのVertex ShaderもR520と同数の8個から増強されていない。
「理由は、現在のアプリケーションでは、ジオメトリプロセッシングはボトルネックではないからだ。Pixel Shaderの負荷の方が増えている。例えば、ライティングでは、頂点レベル(のライティング)ではなく、パーピクセルライティングテクニックをPixel Shaderで行なう傾向にある。そのため、増やすリソースはボトルネックになりやすい場所に割いた」とTaranovsky氏は説明する。
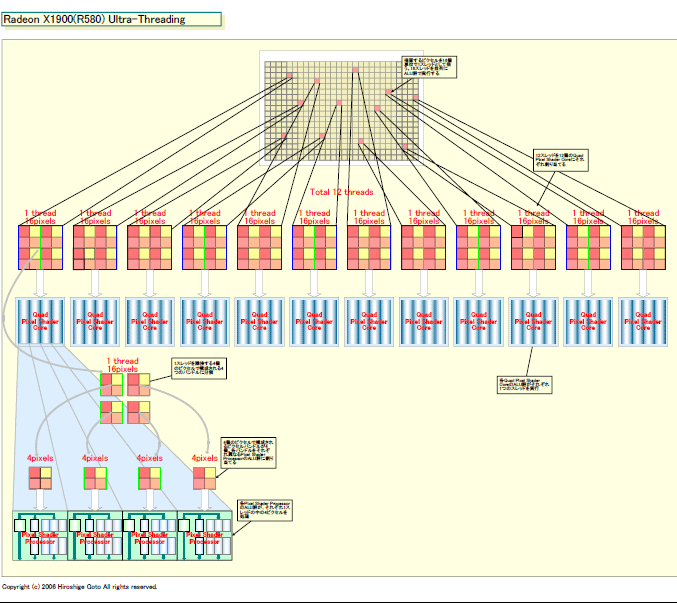
●12スレッドを同時に実行可能
 |
| Radeon X1900(R580) Ultra-Threading (別ウィンドウで開きます) PDF版はこちら |
GPUのShaderのスレッドは、ピクセルや頂点のバッチだ。R520/580では、16個のピクセルで構成されたブロックが1スレッドとして扱われる。R520の「Ultra-Threading(アルトラスレッディング)」では、4個のQuad Pixel Shader Coreで、最大4スレッドを同時に実行できるアーキテクチャだった。それに対して、R580では、12個のスレッドを、12個のQuad Pixel Shader Coreで同時実行できる。つまり、演算コアでのスレッド並列性も3倍に増えたわけだ(テクスチャパイプなども別スレッドを実行できる)。
また、R520では各Quad Pixel Shader Coreが、それぞれ128wayのハードウェアマルチスレッディング機能を備えていた。つまり、128個までのスレッドを次々に切り替えて実行できるわけだ。そのために、膨大な数の汎用レジスタアレイを備えていた。
R580もこのアーキテクチャを継承する。ただし、具体的なマルチスレッディングの並列性はわからない。
ピクセルシェーディング能力を大幅に拡張し、拡張しても効果が薄い部分は据え置いたR580。設計思想は、現在のグラフィックス技術のトレンドに沿っており、R520からの自然な拡張だ。しかし、アーキテクチャ拡張のトレードオフもある。それはGPUのトランジスタ数や消費電力の増大だ。R580のトランジスタ数は3億8,400万、消費電力は約150W(高ストレスのアプリケーション使用時)にのぼる。ATIが、こうしたデメリットを承知した上で、あえてR580のようなモンスターを作った背景には、ATI全体の戦略の変化がある。次回は、ATIの戦略の中での、R580の位置づけをレポートしたい。
□関連記事 (2006年1月25日) [Reported by 後藤 弘茂(Hiroshige Goto)]
【1月25日】ATI、シェーダーパフォーマンスが向上した「Radeon X1900」
http://pc.watch.impress.co.jp/docs/2006/0125/ati.htm
【1月25日】【多和田】早くもトップ交代、ATI「Radeon X1900 XT」
http://pc.watch.impress.co.jp/docs/2006/0125/tawada67.htm
【PC Watchホームページ】
PC Watch編集部
pc-watch-info@impress.co.jp
ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.