 |


■後藤弘茂のWeekly海外ニュース■G70にR520、次世代GPUはマルチスレッディングが標準的に |
●NV40/G70系はShaderによってマルチスレッディングの実装が異なる
現在、マルチスレッディングの実装が判明しているGPUは、NVIDIAでは「GeForce 6800(NV40)」系や「GeForce 7800 GTX(G70)」系、PLAYSTATION 3に載せる「RSX(Reality Synthesizer)」、ATIなら次世代GPU「R520」系やXbox 360 GPU(R500)。しかし、マルチスレッディングは、2強GPUベンダーの突出したGPUの特殊な実装ではなく、業界の技術トレンドとなると見られる。例えば、S3 Graphicsの次世代GPU「Destination」なども、何らかのマルチスレッディング機能を実装すると言われている。おそらく、今後のGPUではマルチスレッディングは標準的な機能となるだろう。
では、各社のマルチスレッディングの実装はどうなっているのだろう。
NVIDIAのGPUアーキテクトのJohn Montrym氏が昨年夏のHotChipsカンファレンスで行なったプレゼンテーションによると、NV40系ではVertex ShaderはそれぞれのShaderユニットで最大3スレッドを実行できるという。NVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)も、各Vertex Shaderでそれぞれ3wayのマルチスレッディングが可能かという質問に対して「その通りだ」と答えている。NV40は6基のVertex Shaderがあるので、合計18スレッドという計算になる。Kirk氏によると、G70も「NV40と同様のマルチスレッディング機能を備えている」という。おそらく、RSXも同じ実装だと推定される。
Kirk氏によると、NV40のPixel Shaderもマルチスレッディングを行なうという。しかし、どの程度の数のスレッドを扱えるかは明確にされていない。NVIDIAの論文(「THE GEFORCE 6800」, John Montrym & Henry Moreton, IEEE MICRO MARCH-APRIL 2005)では「外部メモリからのフェッチのテクスチャ参照のレイテンシを隠蔽するために、各Fragment Processor(Pixel Shader)は、数100のインフライトスレッドのステートを保持する」となっている。また、昨秋のインタビューでは、Kirk氏は次のように説明していた。
「Shaderでは、あるピクセルに対する命令1(の実行)の後に、別なピクセルに対する命令1を実行といった形を取ることができる。最初のピクセルに対する命令2が実行されるのは、100サイクル後になるかもしれない」(Kirk氏)
常識的に考えれば、Vertex Shaderよりもテクスチャフェッチが多いと推定されるPixel Shaderの方が、より並列性の高いマルチスレッディングを行なうのが当然と思われる。NV40/G70系のPixel Shaderの正確なスレッド並列性はわからないが、おそらくVertex Shaderよりも広い並列性を備えていると推定される。
 |
| GeForce 7800 GTX(G70) Block Diagram PDF版はこちら |
●Unified-Shaderでマルチスレッディングを行なうATI
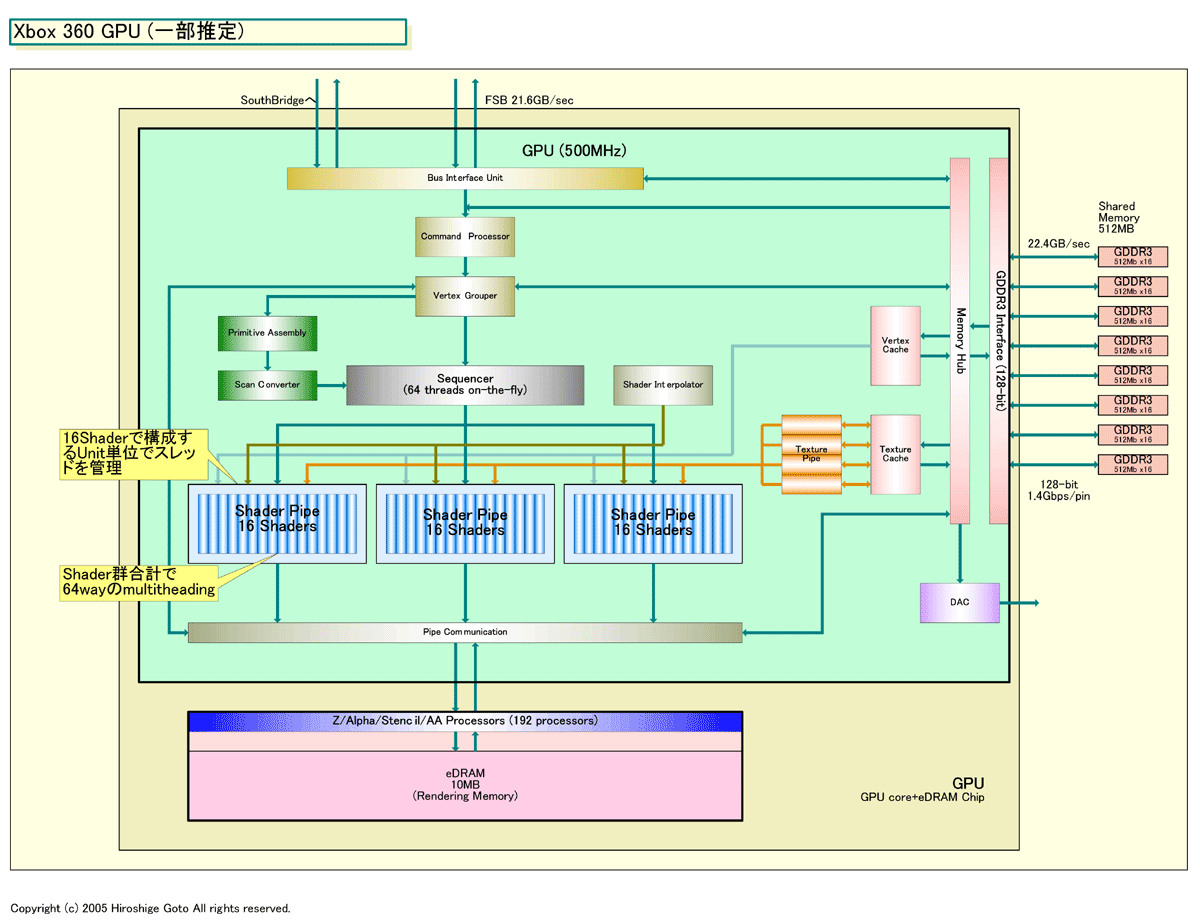
ATIが開発したXbox 360 GPUは、Unified-Shaderアーキテクチャなので、Vertex ShaderとPixel Shaderの区別がない。Xbox 360は、Shader群全体で、合計で64スレッドをインフライトで制御することができる。「我々はチップ内にステートバッファを備えている。だから、オンザフライで64スレッドを切り替えることができる」とATIでXbox 360を担当するRobert Feldstein氏(ATI Technologies, Vice President - Engineering)は語る。
Feldstein氏によると、合計48個のXbox 360のShaderは、16 Shaderずつ3グループに分かれてスレッディング制御されているという。「我々は、プロセッサ群を、16プロセッサで構成するユニット3つに分割した。そして、それぞれのユニット(16 Shader)がそれぞれ異なるスレッドを走らせる。だから、(スレッディングしない場合でも)1スレッドがストールしても、他の2スレッド32 Shaderは動作し続ける」とFeldstein氏は語る。
つまり、ユニット(16 Shader)単位で3スレッドを同時に走らせ、64スレッドまでのオンザフライの切り替えが可能になっている。ここには、NVIDIAとATI両社の“スレッドの定義”が同じかどうかというやっかいな疑問もあるが、それは脇へ置いても、ATIも広いスレッド並列性を持つことがわかる。
 |
| Xbox 360 GPU(一部推定) PDF版はこちら |
ちなみに、ATIのPC向け次世代GPUのR520は、トータルで128wayのマルチスレッディングを行なえると言われている。だとすると、Xbox 360 GPUの2倍のスレッドをインフライトで制御できることになる。あるPC業界関係者によると、ATIはR520ではマルチスレッディングをアーキテクチャの重要なカギとして顧客に説明しているという。
他のGPUのマルチスレッディングについては、まだ概要がわからない。しかし、Unified-Shader世代になると、どのベンダーもマルチスレッディングを実装して来ると推定される。GPU関係の情報ソースによると、あるGPUベンダーは、Unified-Shaderの各Shaderにそれぞれスレッドキューを搭載し、キューの中の複数のスレッドのステートを保持して切り替えられるようにするという。基本的には、各Shaderに1スレッドを割り当て、さらにそれをマルチスレッドするのが、一般的な制御のようだ。
●SRAMをShader毎に分散配置してステートを保持
GPU全体で数10~100以上のスレッドのマルチ化。CPUの場合、マルチスレッディングは各CPUコアにつき2wayから4way程度なので、NVIDIAとATIのどちらのGPUも、CPUよりずっと広いマルチスレッディングを行なっていることがわかる。
しかし、マルチスレッディングには当然トレードオフがある。インフライトで扱うスレッドの各ステート(レジスタファイルや各種コントロールステート)を保持しなければならないからだ。
「各ピクセルスレッド毎に、シェーディングを完了するまで、必要な全てのステートを、チップ上に保持する必要がある。ピクセル毎、スレッド毎に多くのステートが存在する」(Kirk氏)
そのため、ワイドなマルチスレッディングの実装は、多くのトランジスタ(=ダイ面積)を必要とする。2004年8月に開催された汎用コンピューティングGPUのカンファレンス「GP2」では、スタンフォード大学のBill Dally氏(Computer Systems Laboratory, Stanford University)が、この問題に触れている。全ステートを保持しなければならないマルチスレッディングでは、非常にコストが高くつくとDally氏はプレゼンテーション(「Stream Processors vs. GPUs」, Bill Dally, GP2, August 8, 2004)で指摘している。
だが、GPUの場合、それも実装上は見合うとNVIDIAのKirk氏は説明する。
「NV40は膨大なトランジスタを搭載している。GPU Shaderアーキテクチャは、CPUのような極めて大きなキャッシュをプロセッサ上に必要としない。そのため、(キャッシュに使う分の)非常に大きな量のメモリを、パイプライン上に分散することができる。分散したメモリでステートを保持することによって、Shaderコアがストールすることなく効率的に動作し続けることを保証する」
現在のCPUは数MBクラスのSRAMキャッシュを載せているが、GPUのキャッシュはそんなに大きくはない。その代わり、SRAMメモリをパイプラインの各所に分配して、SRAMをステートの保持に使うことによって、ワイドなマルチスレッディングを実現しているというわけだ。SRAMをキャッシュに費やしてキャッシュヒットを上げてDRAMアクセスを減らしてストールを防ぐか、SRAMをステートの保持に費やしてスレッド並列性を上げてメモリレイテンシを隠蔽してストールを防ぐか。整理すると、kirk氏の主張は次のようになる。
CPU→大容量キャッシュSRAM→キャッシュヒット向上→DRAMアクセス低減→ストール低減
GPU→大容量ステート保持SRAM→マルチスレッディング向上→DRAMアクセスレイテンシ隠蔽→ストール低減
キャッシュミスに合わせて設計するGPUでは、必然的に後者の実装になるというわけだ。
●GPUでのステートの保持
もっとも、GPUの場合、実際、どのステートをどんな形で保持しているのか、まだ明瞭ではない。CPUの場合は簡単で、スレッドを生成した親プロセスと共有するメモリ空間などはそのままで、スレッドごとにデータステートとコントロールステートを複製する。4wayマルチスレッディングなら、レジスタファイルなどを4面持っていて、実行するスレッドによって切り替える。
しかし、GPUのようなストリームプロセッサの場合は、異なる実装の可能性がある。例えば、スタンフォード大学でDally氏らが研究しているStream Processorの場合は、レジスタファイルを階層化したようなイメージで管理している。
そもそも、GPUの場合は論理上のレジスタ構造自体がCPUとはかなり異なっている。ロジカルな見方では、Shaderにはテンポラリレジスタ、インプットとアウトプットのレジスタ、コンスタントレジスタ、命令スロットなどがある。インプットとアウトプット、それにテンポラリなどは、スレッドユニークとなる。
命令スロットのために物理的に実装しているInstruction RAMは、シェーダプログラムを格納するエリアで、Shaderの場合は命令キャッシュではなく明示的に管理するこのメモリに命令を格納する(命令キャッシュも実装されているケースもあると見られる)。ストリームプロセッシングには色々あるが、GPUの場合はプログラム(シェーダ)は一定で複数データを処理する形態が中心となる。つまり、一定のシェーダプログラムで、複数のピクセルまたは頂点を処理するケースが多い。そのため、もともとInstruction RAMは必ずしも処理するピクセルや頂点によってスイッチされない、あるいはShader間で共有されている可能性もある。
このあたりのステートの保持や制御方法は、まだ明瞭になっていない。
●GPUは粒度の細かなスレッディングを採用
マルチスレッディングには、制御の方式によっていくつか種類がある。
SMT(Simultaneous Multithreading)
Fine-Grained(細粒度) Multithreading
Coarse-Grained(粗粒度) Multithreading
SMTはPentium 4のHyper-Threadingのように、複数のスレッドの命令を1サイクルの中で同時に実行することができるアーキテクチャだ。スレッドを切り替えるのではなく、異なるスレッドの命令を完全に混合して実行できる。
それに対して、Fine-Grained Multithreadingは、同じサイクルに複数スレッドの命令は同時実行できない。1サイクル単位でスレッドを切り替えて実行できる。CellプロセッサのPPE(Power Processor Element)などのマルチスレッディングがこの方式だ。
Coarse-Grained Multithreadingは、より大きな単位での切り替えのみをサポートする。毎サイクルの小刻みなスレッド切り替えはできず、長レイテンシのイベントが発生した場合のみ、別スレッドに処理を切り替える。切り替えにある程度のレイテンシがかかる場合もあるが、コンテクストをメモリに待避させるよりはずっと速い。
GPUの場合、採用しつつあるのはいずれもFine-Grained Multithreadingだ。
「NV40のスレッディングはFine-Grainedだ」(Kirk氏)。「(Xbox 360 GPUは)小さな粒度でスレッディングする。サイクル毎に切り替えることもできる」(Feldstein氏)
SMTは、演算リソースの有効利用には効果があるが、制御が複雑で、そもそも演算リソースの並列性が高くないと意味がない。メモリレイテンシを隠蔽するだけなら、Fine-Grained multitheadingで十分に有効という判断だろう。
●スレッディングのスイッチ
もっとも、実際のスレッディングは、長レイテンシのイベントをトリガにすると見られる。
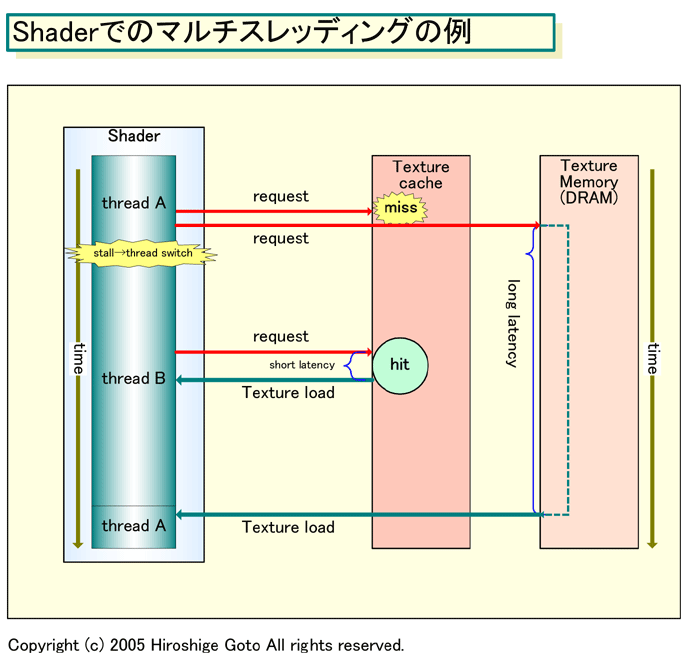
「テクスチャキャッシュミスを含めて、多くの要素がスレッドスイッチを起こす可能性を持つ。1つのスレッドは完了するか、何らかのリソースがミッシングしてその先の実行が妨げられるまで走る。ミッシングするケースの中には、キャッシュミスや、別スレッドが特定のリソースを占有している場合など、さまざまなケースが考えられる。条件分岐も、ストール&スレッドスイッチを起こす可能性があるが、キャッシュに入っているかどうか、分岐の局所性で変わる」(Kirk氏)
ATIも、メモリへのテクスチャフェッチがスレッディングを起こすと説明している。ただし「分岐を実行して(分岐方向が)間違えていてストールした場合も、別スレッドを据えることはしない」(Robert氏)といい、スレッディングの管理にも多少違いがあるようだ。
ちなみに、シェーダプログラムでも、CPU上のプログラムと同様に、テクスチャロード命令をできるだけ前に出すなどのレイテンシを隠蔽するための最適化を行なう。マルチスレッディングは、こうした命令レベルの静的スケジューリングとバッティングするように見えるかもしれないが、そうではない。命令レベルでやっているのは、CPUと同様に基本的にはキャッシュヒット時の短いレイテンシ程度を隠蔽するスケジューリングで、キャッシュミス時の長いレイテンシはマルチスレッディングで行なうと推定される。
このあたりの静的スケジューリングとマルチスレッディングの関係は、CPUと同じだ。いい例がIA-64で、IA-64ではコンパイラがロード命令をストア命令や分岐命令の前に出すなどのアグレッシブな手法で、命令スケジューリングでメモリレイテンシを隠蔽する。しかし、それと同時に「Montecito(モンテシト)」からはCoarse-Grained multitheadingも実装し、より長いレイテンシが発生する時にスレッドを切り替える。
 |
| Shaderでのマルチスレッディングの例 PDF版はこちら |
メモリレイテンシをカバーするために、マルチスレッディングへと向かうGPU。マルチスレッディングは、Shaderの効率性のカギとなるため、GPUパフォーマンスに大きく影響する重要な技術要素になると見られる。GPUの性能は、ますます、単純なパイプ/Shader数やクロック、ピーク時のShader演算性能といった要素では、判断できなくなりつつある。例えば、ピーク「○○GFLOPS」と言っても、マルチスレッディングなどShader制御アーキテクチャによって、Shaderの稼働効率が異なるため、実際の性能は異なってしまう。
□関連記事
【7月11日】【海外】マルチスレッド化へ向かうGPUアーキテクチャ
http://pc.watch.impress.co.jp/docs/2005/0711/kaigai197.htm
【7月8日】【海外】対照的なアーキテクチャでぶつかるNVIDIAとATI
http://pc.watch.impress.co.jp/docs/2005/0708/kaigai196.htm
(2005年7月13日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2005 Impress Corporation, an Impress Group company. All rights reserved.