 |


■後藤弘茂のWeekly海外ニュース■マルチスレッド化へ向かうGPUアーキテクチャ |
●CPUと同様にマルチスレッディングの実装へ
GPUもマルチスレッディングへと進んでいる。GPUはもともと複数パイプ(Shader)を備えて複数タスクを走らせることができる。しかし、次のステップとして、各Shader内で複数スレッドを走らせることができるマルチスレッディングの実装へと向かっている。CPUがマルチコア&マルチスレッドへと向かったように、GPUもマルチパイプ&マルチスレッドへと走っている。GPUベンダーも、マルチスレッディングを次世代GPUの重要なキーとして打ち出しはじめている。
マルチコアとマルチパイプは、どちらもチップのパフォーマンスを上げるためのアプローチだ。それに対してマルチスレッドは、各コアや各パイプの効率を向上させ、特にメモリアクセスのレイテンシを隠蔽することを主目的としている。例えば、Intelが自社のマルチスレッド技術Hyper-Threadingを発表した直後のProcessor Forum 2001でのプレスセッションでは、IntelのCPUアーキテクトMatthew Adiletta氏(Intel Fellow, Director of Communications Processor Architecture)が「マルチスレッディングの最大の効用はどの(CPU)アーキテクチャでもメモリレイテンシを隠蔽することだ」と言っていた。
なぜ、メモリレイテンシがそれほど問題になるのか。それはプロセッサが速くなりすぎて、メモリサイクルとのギャップが広がったからだ。CPUの内部クロックは数GHz、GPUですら500MHz前後かそれ以上の周波数で動作する。サイクルタイムは0.26ns(3.8GHz)から2ns(500MHz)といったレンジ。ところが、DRAMのメモリセルは実質133~200MHz動作で、外部DRAMにアクセスすると最初のデータを読み出せるまで最小でも数十nsかかる。そのため、DRAMメモリへのアクセスは、プロセッサの内部クロックで数十~数百サイクルのコストになってしまう。
「(CPUの性能向上にとって)メモリレイテンシはクリティカルだ。L1とL2キャッシュをミスすると、メモリからのバックまでの間、CPUは文字通り数百クロックも待たなければらなない。最悪のケースではロスは1,000クロック以上になる」とIntelのPatrick P. Gelsinger(パット・P・ゲルシンガー)氏(Senior Vice President and General Manager, Digital Enterprise Group)は語る。
GPUはCPUより動作周波数が低いため、CPUほどクリティカルではないものの、やはりロスは膨大だ。GPUがDRAMにアクセスに行くと、依存性がない処理以外はストップさせなければならない。その間は、GPUのパイプはムダにアイドル状態に陥ってしまう。そこで、GPUでも、メモリレイテンシの問題を指摘する声も多くなっている。
例えば、2004年8月に開催された汎用コンピューティングGPUのカンファレンス「GP2」では、スタンフォード大学のBill Dally氏(Computer Systems Laboratory, Stanford University)が、GPUやStream Processorなどでのレイテンシ隠蔽の必要について触れている。プレゼンテーションでは「メモリアクセスで数百サイクル待たされる時に、ストールしたままにするのは明確に間違った回答。全てのリソースは全アクセスレイテンシの間、アイドル状態になってしまう」と指摘している。
メモリレイテンシは、GPUに限らずあらゆるプログラマブルプロセッサの共通の課題で、それぞれのプロセッサが適した解を実装しつつある。今後も、DRAM自体のレイテンシは大幅に軽減される見込みがないため、プロセッサ側で対策を取る必要がある。
●伝統的なGPUでのメモリレイテンシ隠蔽
もっとも、GPUにとって、メモリレイテンシ問題は、今に始まったことではない。以前から大きな問題だった。
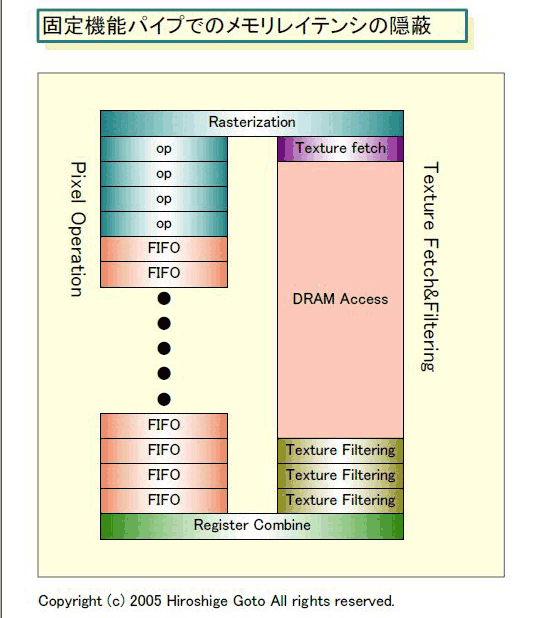
数年前、Shader時代に入る前に、複数のGPU関係者に、固定機能グラフィックスパイプラインでの、メモリレイテンシの問題について聞いたことがあった。その時、彼らが答えたのは、GPUではこの問題の解決を、パイプラインを深くすることで図っているということだった。つまり、レイテンシを吸収できる長大なパイプにして、テクスチャフェッチから実際のテクスチャのコンバインまでのサイクルを空けるというわけだ。
下が、当時のGPU関係者からの話をまとめた、固定パイプでのレイテンシの吸収方法だ。伝統的GPUはプリミティブをラスタライズステージ群でピクセルに分解したら、ピクセルデータのレンダリングをスタートするのと平行して、テクスチャフェッチにかかる。外部DRAMに読みに行くテクスチャフェッチは時間がかかるので、その間に演算パイプにはFIFO(First In, Fist Out)メモリをかませて、遅滞させておく。
当然、そのピクセルの処理はストールするが、その間に他のピクセルの処理を他のステージでパイプライン実行する。FIFOが十分に深ければ、パイプラインを詰まらせることなく、テクスチャフェッチを待つことができる。パイプライン自体はビジーに動作し続ける。テクスチャがロードされフィルタリングが終わったら、その段階でピクセルデータとテクスチャデータの両方を揃えて、レジスタコンバインステージへと持ってくる。
このように、パイプを深くすることでレイテンシを吸収するため、トラディショナルな固定パイプGPUのパイプラインは長い。NVIDIAによると、パイプの深さは200~500ステージに達するという。しかし、固定パイプでのグラフィックス処理は、単純な一方方向のストリーム処理なので、メモリロード以外の要素でパイプラインの乱れが生じにくい。また、グラフィックス処理はスループットオリエンテッドなので、基本的にはスループットが保たれるなら、レイテンシは問題にならない。つまり、処理に数百サイクルかかろうとも、サイクル毎にピクセルが出てくるならOKだったというわけだ。
 |
| 固定機能パイプでのメモリレイテンシの隠蔽 PDF版はこちら |
●Shader時代になって難しくなったレイテンシ隠蔽
しかし、Shader時代になると、話はそう簡単には行かなくなった。GPUは単純な一方向の長いパイプラインではなく、プログラマブルな演算ユニットであるShaderを実装するようになった。そのため、レイテンシ問題を解決するために、これまでとは違った手法が必要になり始めた。テクスチャフェッチの間は、FIFOに入れて待たせるといった単純な手法はもはや取れない。メモリアクセスの間、依存性のない命令は実行できるが、100サイクル以上もストールしたら、必ずアイドル状態になってしまう。アイドル状態が多くなると、Shaderは稼働率が下がり、パフォーマンスが落ちてしまう。
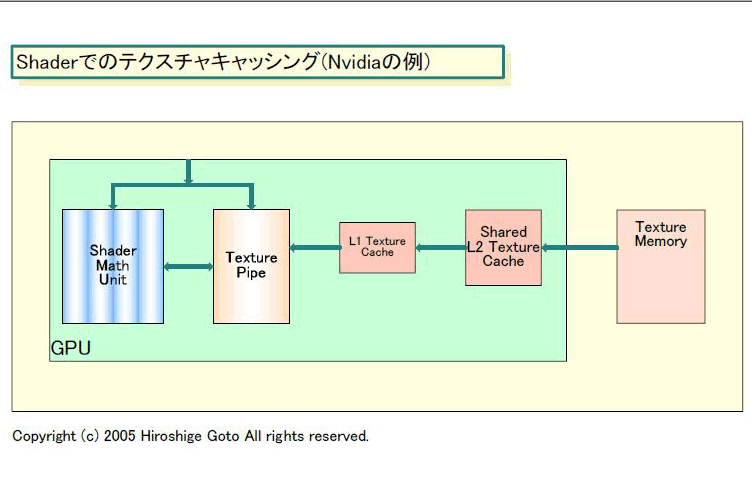
問題の根元は、オフチップのDRAMにアクセスすると遅いことにある。この問題に対する伝統的なソリューションはメモリの階層化、つまりキャッシュだ。そのため、現在のGPUはある程度の容量のテクスチャキャッシュを搭載しはじめている。例えば、NVIDIAのGeForce 6800(NV40)/GeForce 7800 GTX(G70)系だと、Shader内部に小容量のL1テクスチャキャッシュを、Shader外に全Shaderで共有する大容量のL2テクスチャキャッシュと、2階層のキャッシュを備える。ATIは、GAMECUBEに搭載したメディアプロセッサ「Flipper(フリッパー)」から、すでに1MBの大容量テクスチャキャッシュを搭載している。
しかし、GPUの場合は、キャッシングだけで問題は解決しない。キャッシュヒット率が低いために、キャッシュに頼り切れないからだという。
最新のCPUの場合はキャッシュヒットは95%以上、命令やデータの局所性の高いプログラムだと98~99%といった高率を達成する。それに対してGPUのキャッシュヒットは、ずっと低いという。NVIDIAの論文(「THE GEFORCE 6800」, John Montrym & Henry Moreton, IEEE MICRO MARCH-APRIL 2005)を見ると、同社のデザインの場合、90%程度のヒットレートしか見込めないという。キャッシュの効率は、ロードするデータの局所性に依存するので、汎用コンピューティングよりGPUのようなメディア処理の方がキャッシュが効きにくいのは意外ではない。数%の違いは大きくないように見えるが、98%と90%なら、ミスする回数は5倍も多くなる。そのため、GPUではCPUと異なる設計が必要になる。
「CPUは“キャッシュヒット”に合わせて設計されている。CPUではキャッシュミスすると、ひどいことになる。しかし、キャッシュがいったんフィルされてしまえば、ミスする確率が低い、という設計思想だ。それに対してGPUは、“キャッシュミス”に合わせて設計されている。GPUはCPUと比べるとキャッシュミスが頻繁で、ヒット率を高めにくい。だから、ヒット率より、ミス時のレイテンシを隠蔽することにフォーカスしている」とNVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)は説明する。
 |
| Shaderでのテクスチャキャッシング PDF版はこちら |
●Shaderをビジーに保つにはマルチスレッディングが必要
また、プリフェッチが難しいことも影響する。現在のCPUの場合は、必要と予測されるデータや命令を、前もってメモリからロードするプリフェッチを、ハードウェアあるいは命令として実装している場合が多い。しかし、GPUではこの手法もうまく働かないという。
「プリフェッチはGPUでは難しい。ほとんどのアクセスは、(アドレスを)計算した後になるため、予測が難しいからだ。例えば、メモリアクセスで最も多いのはLOD(Level of Detail)付きのテクスチャマッピングだが、これはフェッチが実際にリクエストされるまでは、事実上プリフェッチできない」とKirk氏は語る。
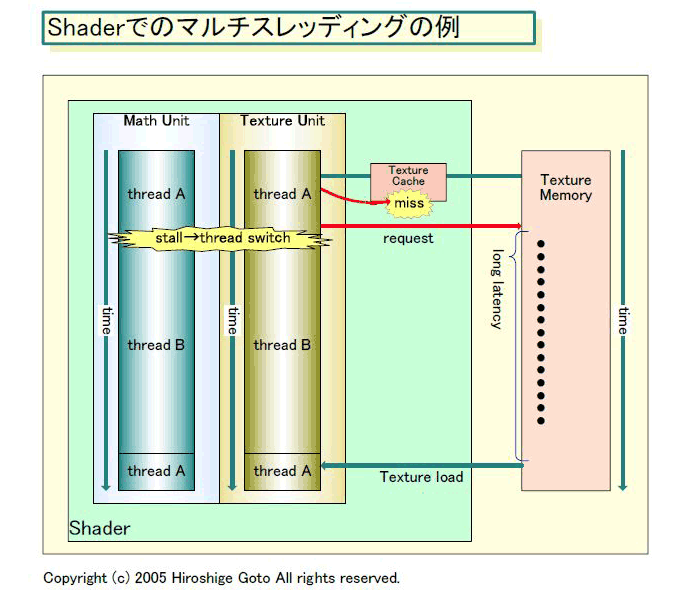
キャッシュミスが生じた場合、DRAMアクセスによる最大数百サイクルのレイテンシがShaderにのしかかる。例えば、15命令おきにテクスチャフェッチ命令があり、そのうち10%がミスするとしたら150命令に1回はストールが発生する計算になる。もし、1/150の確率で100サイクルのアイドルが発生すると、Shaderの実行時間のかなりの割合がアイドル状態で空転してしまう。
こうした事情から、GPUは演算ユニットをビジーに保つために、キャッシュ以外の、メモリアクセスレイテンシ隠蔽メカニズムを実装する必要に駆られている。そして、そのための解決策がマルチスレッディングだったというわけだ。
「GPUは依然としてストリームプロセッサだ。ストリームプロセッシングでは、プロセッサをビジーに保つために、(CPUとは)異なるソリューションが必要となる。メモリアクセスのレイテンシを隠蔽するために、我々はスレッディングとスケジューリングを積極的に行なう。複数のコンテクストを走らせてスレッディングするために、多くの(物理)レジスタも搭載する」とKirk氏は語る。
また、ATIでXbox 360を担当するRobert Feldstein氏(ATI Technologies, Vice President - Engineering)も同様の説明をする。
「テクスチャフェッチは非常にレイテンシが長いパスだ。それが、我々がマルチスレッディングする理由の1つだ。テクスチャをフェッチする時に、(データのロードを待つ代わりに)他の命令ストリームを実行する。(そうすることで)Shaderを決して止めない」
 |
| Shaderでのマルチスレッディング PDF版はこちら |
●CPUとGPUのソフトウェア環境の違い
この問題は、逆の側面から見ることもできる。PC CPUの場合、現在のソフトウェア環境では、CPU上でメインに走る負荷の高いタスクの数が少ない。そのため、スレッドを切り替えるよりも、キャッシュヒット率を高め、プリフェッチを行ない、1つのスレッド(命令ストリーム)を効率よく走らせようとする。
それに対して、GPUの処理は膨大な数のタスクに分かれている。実行しなければならないタスクは山ほどあり、個々のスレッドの高速化にフォーカスする必要は薄い。そのため、GPUでは、キャッシュやプリフェッチにリソースをかけるよりも、ストールしたら単純に別なスレッドに切り替えた方が合理的な解となる。
「GPUにとって(スレッドの並列実行)は簡単だ。我々には並列に実行できるタスクが多数あるからだ。レンダリングなら、1,600×1,200ピクセルの解像度の場合、ピクセルの数だけ、つまり200万のタスクがある。各ピクセルは独立していて、依存性がなく並列化できる。それに対して、(PCの)CPUは通常、1つのタスク、多くても2つ程度のタスクしか実行しない。メインワークは多分1つだろう。そのため、CPUの場合は、(あるスレッドの)命令1を実行したら、できるだけ直後に(同じスレッドの)命令2を実行する必要がある」とKirk氏は言う。
つまり、CPUはそもそもソフトウェアのスレッド並列性が低いために、1スレッドをできる限りストールさせずに処理する方向へと進化した。実行できるスレッドが少ない→個々のスレッドを高速に実行する、というパターンだ。一方、GPUはソフトウェア面ではスレッドはいくらでも並列化できるため、1スレッドの処理がストールしたらスレッドを切り替える方向へと向かっている。実行できるスレッドが多い→スレッドを切り替えて実行する、というパターンだ。GPUにとってはマルチスレッディングは、自然な流れと考えることもできる。
□関連記事
【7月8日】対照的なアーキテクチャでぶつかるNVIDIAとATI
http://pc.watch.impress.co.jp/docs/2005/0708/kaigai196.htm
(2005年7月11日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2005 Impress Corporation, an Impress Group company. All rights reserved.