 |


■後藤弘茂のWeekly海外ニュース■PLAYSTATION 3のグラフィックスエンジンRSX |
●RSXとG70は双子のGPU
ソニー・コンピュータエンタテインメント(SCEI)の次世代機「PLAYSTATION 3」に搭載されるGPUは、NVIDIAと開発した「RSX(Reality Synthesizer)」。このRSXは、NVIDIAの最新ハイエンドGPU「GeForce 7800 GTX(G70)」と、双子のGPUだと推定される。
NVIDIAのDavid B. Kirk氏(Chief Scientist)は、両GPUについて「RSXのShaderアーキテクチャは、G70をベースにしている」と説明している。おそらく、RSXとG70の違いは、プロセス技術とシステムバス、そして、メモリインターフェイス幅程度に過ぎないと見られる。G70がTSMCの0.11μmプロセスでPCI Express x16、256bit幅のGDDR3インターフェイス。RSXがソニー/東芝の90nmプロセスでFlexIO(Redwood:レッドウッド)で、128bit幅のメモリインターフェイス。それ以外のShader構成やShaderのマイクロアーキテクチャなどについては、両GPUに違いはほぼないと推定される。
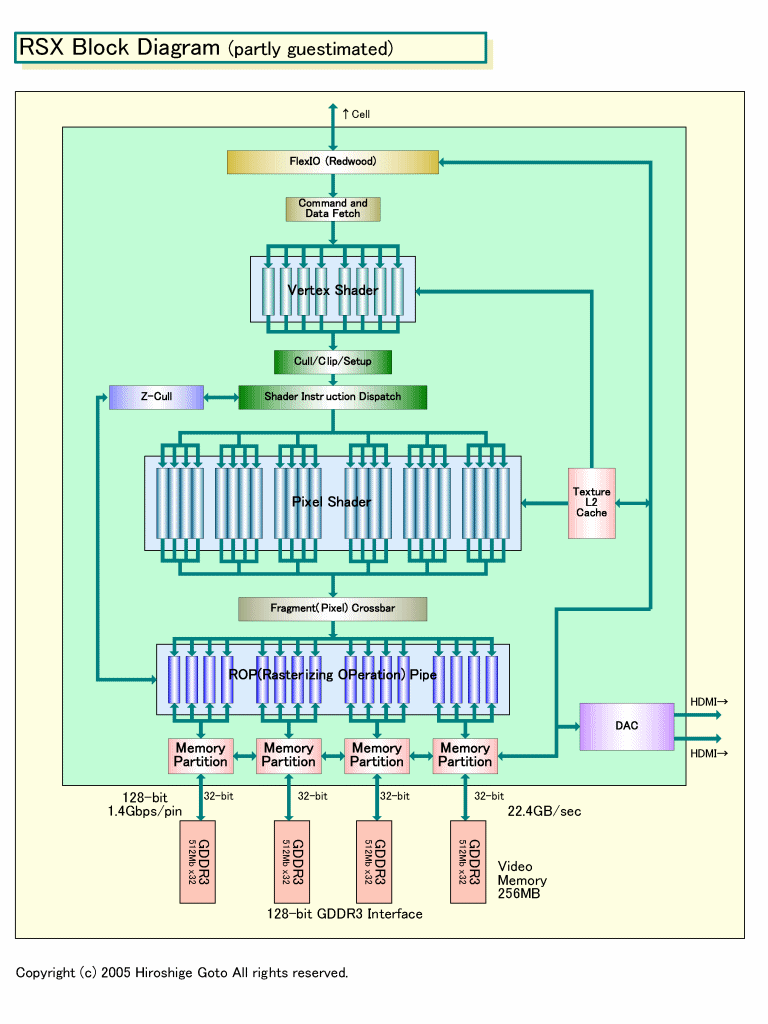 |
| RSX Block Diagram PDF版はこちら |
Shader構成に違いがないと考える理由はいくつかあるが、最大の根拠はE3での発表スペックにある。E3でNVIDIAは、RSXのShaderの並列性について、136 Shader Operations/cycleになると説明した。
このスペックは、Microsoftが発表したATI開発のXbox 360 GPU(R500)のスペックに対抗して公表されたものと推測される。Microsoftは、Xbox 360 GPUのShaderオペレーション性能が、48 billion shader operations/secと公表しており、換算すると96 Shader Operations/cycle(500MHzで割る)となる。スペック競争をするNVIDIAとしては、それより高い数値を示したかったのだろう。
ただし、“Shader Operations/sec”はATIの表現で、NVIDIA的な表記ではInstructions/secにほぼ相当する。NVIDIAは、1命令で発行する複数オペレーションをOperations/secとしてカウントしており、命令発行の並列性は別スペックとしてカウントしているからだ。E3時のスペックは、NVIDIAがATIに対抗するために、一時的に表記をすり合わせたと見られる。
というわけで、RSXの136 Shader Operations/cycleは、NVIDIAの本来の表記では136 Instructions/cycleになると推測される。では、これはどういうスペックなのか。G70系のVertex Shaderは2 Instructions/cycle、Pixel Shaderは5 Instructions/cycleの命令発行の並列性を持つとNVIDIAは説明している。そのため、G70の構成(Vertex Shader 8/Pixel Shader 24)の場合、GPU全体では136 Instructions/cycleとなると公表されている。
つまり、Instructions/cycleのスペックを見る限り、G70とRSXのShader構成は全く同じだと推測できる。RSXも、Vertex Shaderが8ユニット、Pixel Shaderが24ユニットの構成で、それぞれG70と同じ命令発行の仕組みを持っているとしたら、このスペックとなる。
実際、GPU業界関係者には、G70とRSXがほぼ同一アーキテクチャだと語る人は多い。ある関係者は「NVIDIAがSCEIと最終的に契約を結んだのは2004年夏頃だった。だから、NVIDIAはSCEI向けにカスタマイズしたアーキテクチャを開発する時間的な余裕がなかった」と語る。
両GPUの構成にほぼ違いがないだろうことは、トランジスタ数からも推測できる。トランジスタ数は、G70が3億200万(302M)、RSXが3億(300M)以上と発表されている。PCI Express x16の方がFlexIOより実装は重く、DRAMコントローラも2倍であることを考えると、この違いは納得できる。
●RSXのShader演算パフォーマンスはG70の28%増
G70のShaderアーキテクチャは、GeForce 6800(NV40)をベースに、特にPixel Shader内部の並列性を強化した。例えば、NV40では、Pixel Shader内に2つのベクタ演算ユニットを持つが、片方のベクタユニットは1サイクルスループット積和算ができなかった。G70では積和演算ができるようになっている。下の図がG70のShader内部構成図だが、RSXもこれとほぼ同じだと推定される。
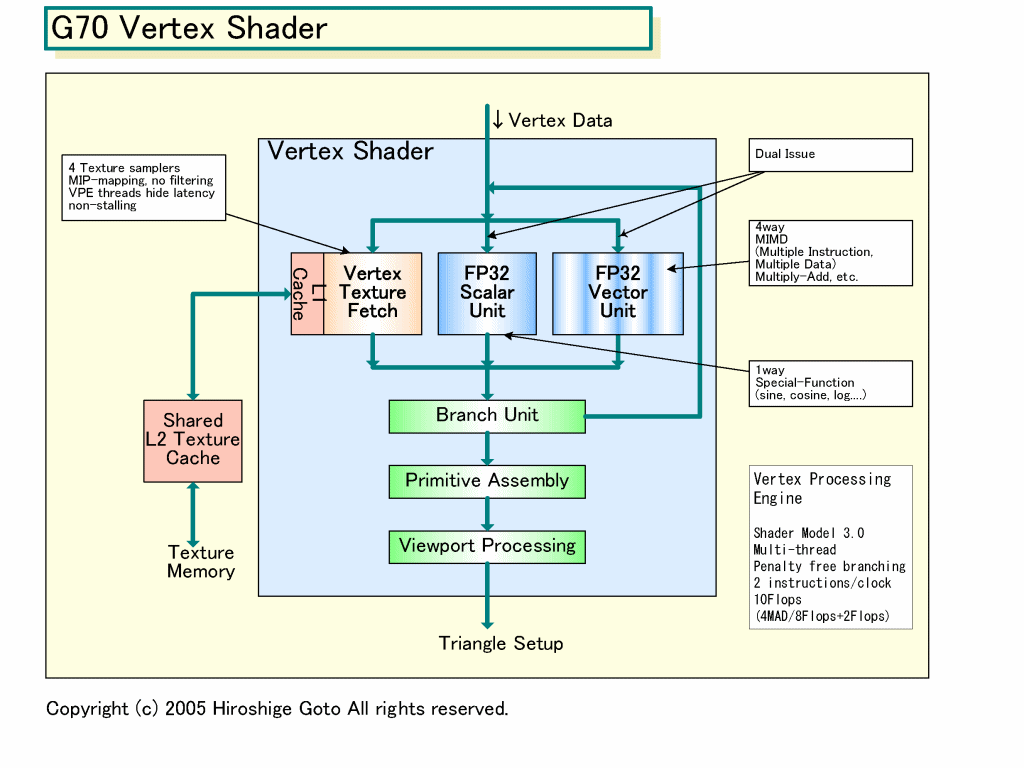 |
| G70 Vertex Shader PDF版はこちら |
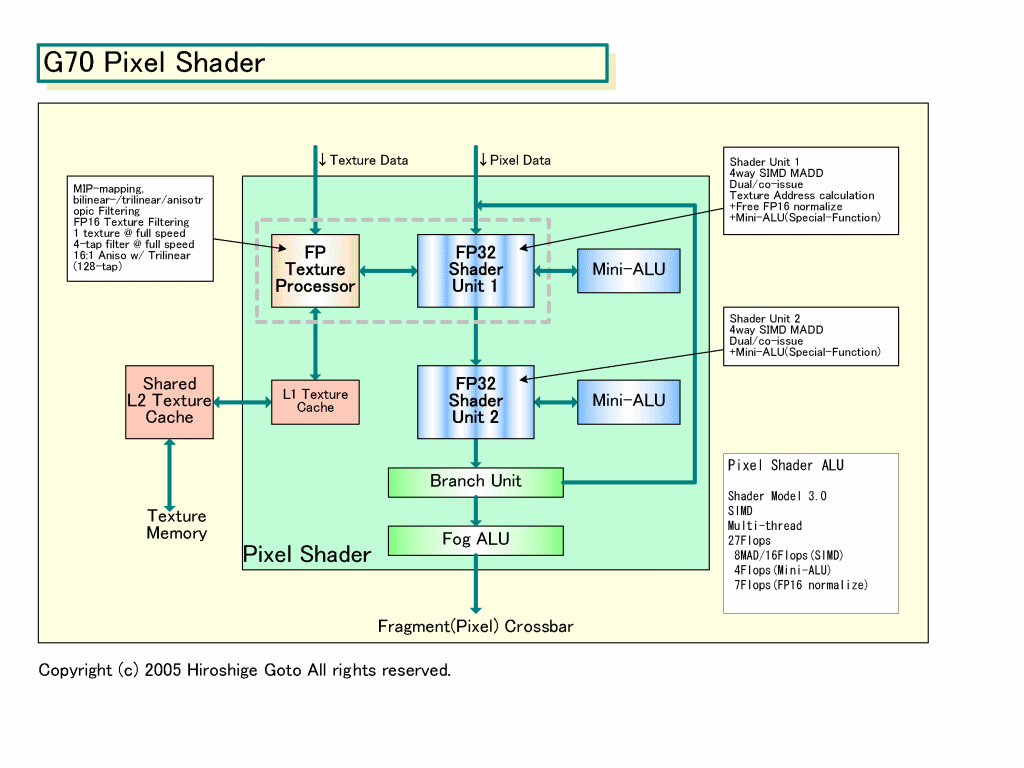 |
| G70 Pixel Shader PDF版はこちら |
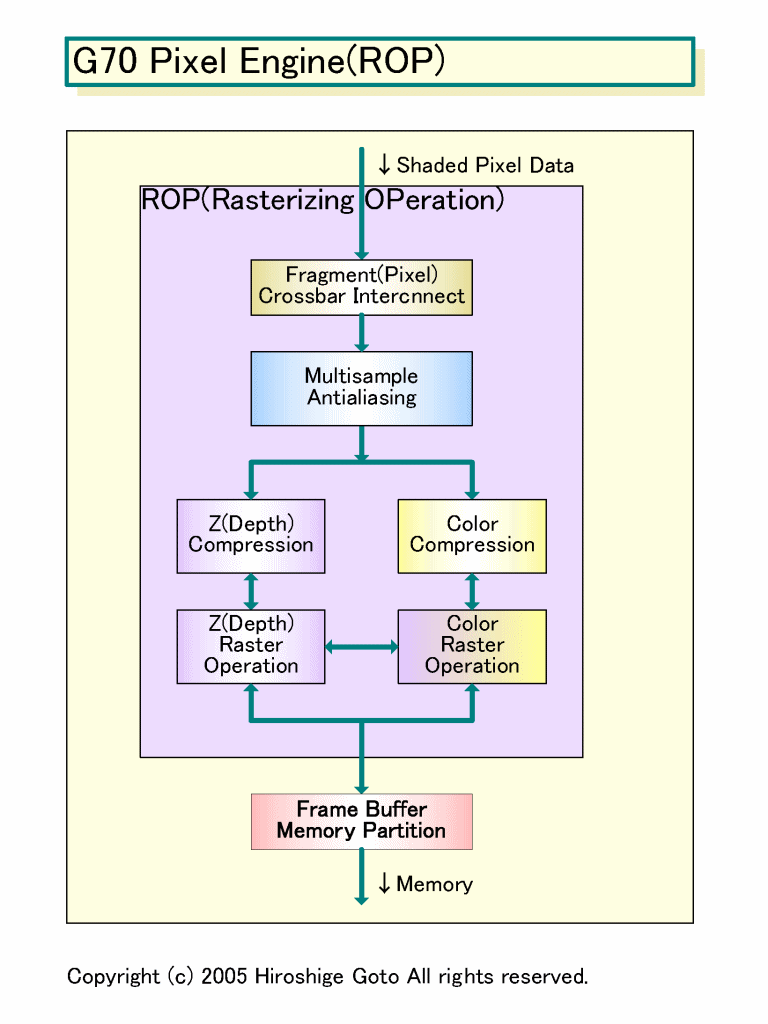 |
| G70 Pixel Shader(ROP) PDF版はこちら |
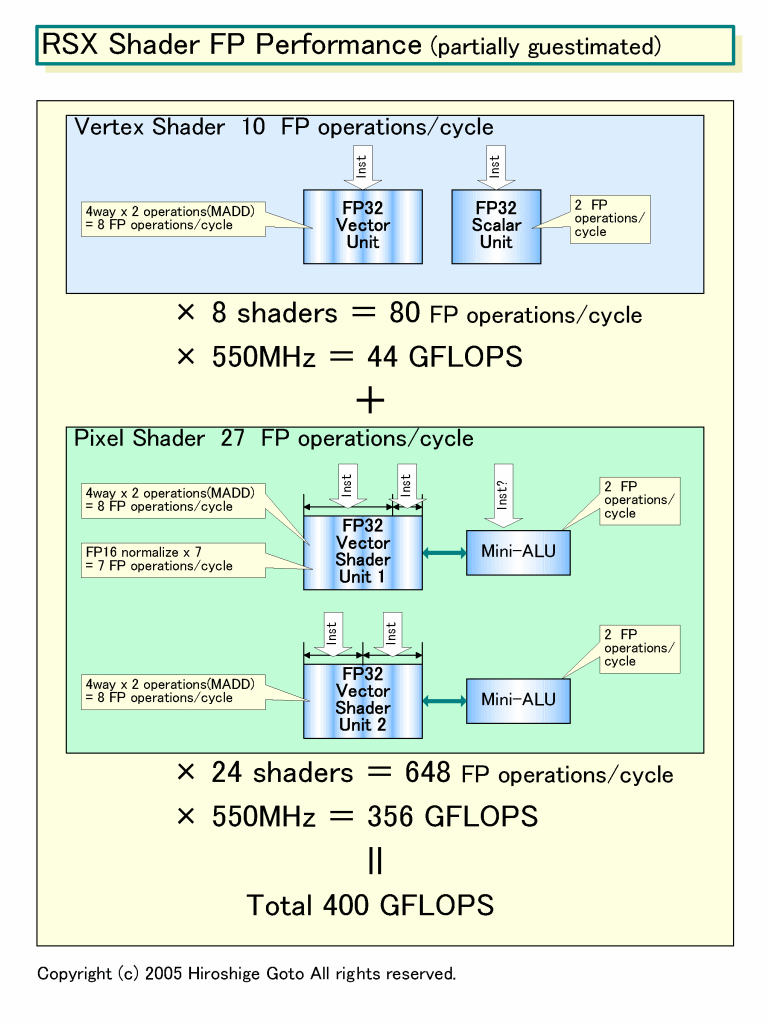
G70とRSXのShaderアーキテクチャが同じだとしても、演算パフォーマンスは大きく異なる。それは動作周波数が違うからだ。現在のG70は製品スペックは430MHz、それに対してRSXは550MHzを予定している。周波数は28%ほどRSXの方が高いため、理論上のピーク演算性能ではRSXはG70の1.28倍となる。
NVIDIAが公開しているG70のスペックでは、Vertex Shaderが4way VLIWユニット+ 1 スカラユニットで、5データを並列に演算できる。積和算で、1サイクル当たりの浮動小数点オペレーションは10。Vertex Shaderは8個なので、演算性能は計算上、次のようになる。
(4way+1scalar) x 2 FP operations(MADD) = 10 FP operations/cycle
10 FP operations x 8 Shader x 430MHz = 34.4GFLOPS
G70のPixel Shaderは、4wayのSIMDユニットが2ユニット、Mini-ALUと呼ばれるスカラ演算ユニットが2個、7wayのFP16 normalize(正規化)処理ユニットがあるという。そのため、演算性能は下のようになる。
((4way x 2 Units + 2 scalar) x 2 FPoperations) + 7 normalize = 27 FP operations/cycle
27 FP operations x 24 Shader x 430MHz = 278.6GFLOPS
Shader構成が同じでクロックが550MHzだとすると、RSXの演算性能は以下のようになる。
Vertex Shader
10 FP operations x 8 Shader x 550MHz = 44GFLOPS
Pixel Shader
27 FP operations x 24 Shader x 550MHz = 356.4GFLOPS
44GFLOPS + 356.4GFLOPS = 400.4GFLOPS
 |
| RSX Shader FP Performance PDF版はこちら |
Xbox 360 GPU(R500)のShader浮動小数点演算性能は240GFLOPSなので、計算上は1.66倍のピークShader浮動小数点演算性能となる。しかし、RSXとXbox 360 GPUはアーキテクチャが全く異なるため、この数字から実際の性能は単純に推し量ることができない。あくまでも、演算量の目安でしかない。
●GPUの使い方を変えるFlexIOの広帯域
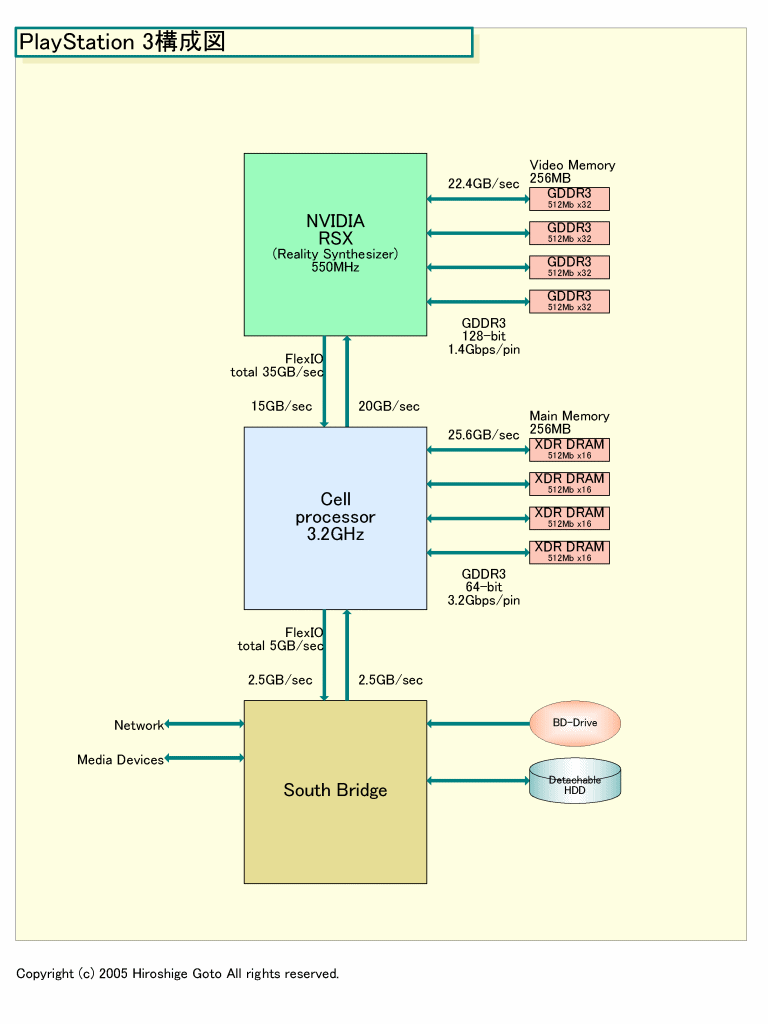
G70とRSXで最も異なるのはホストバスのアーキテクチャだ。G70がPCI Express x16であるのに対して、RSXはRambusのFlexIO(Redwood:レッドウッド)を使う。PCI Express x16の帯域は片方向4GB/sec、双方向で8GB/sec。それに対して、FlexIOは下り(Cell→RSX)が20GB/sec、上り(RSX→Cell)が15GB/secとはるかに帯域が太い。4.5倍の広帯域だ。
この帯域の極端な違いは、単にデータ転送量が大きくなったというだけでなく、CPUとGPUの関係にも影響する。両プロセッサ間でもっと積極的な役割分担ができるようになるからだ。ホストバスが限られているPCグラフィックスとは、根本的に異なるグラフィックスが可能になる。これについては、もう少し詳しく説明したい。
FlexIOには実装上の利点もある。それは占有するダイ(半導体本体)面積当たりの帯域が広いことだ。NVIDIAのPCI Expressの実装がどの程度の面積を占めているかはわからない。しかし、チップセットベンダー関係者は、いずれもPCI Express x16が膨大な面積を必要とすると指摘する。FlexIOは、96bit幅のCell側の実装でも13.1平方mmで、RSX側はインターフェイス幅が狭くなるため、それより小さくなる可能性が高い。
ちなみに、FlexIOは8bit単位で構成が可能なパラレルインターフェイスで、スペック上は転送レートは6.4Gbpsとなっている。しかし、20GB/secと15GB/secというPS3のスペックは、この転送レートと合わない。転送レートが5Gbpsで、下り32bit、上り24bit時と計算が合う。そのため、製品ではFlexIOは5Gbpsの転送レートに落とされている可能性がある。Cellの場合、現在のところ、CPUの動作周波数とXDR DRAMメモリの転送レートは同期されており、CPUクロックを落とすとXDR DRAMの転送レートも落ちている。しかし、FlexIOは非同期になっていると思われる。
 |
| RSX Shader FP Performance PDF版はこちら |
●メモリインターフェイスのアーキテクチャ
もうひとつの違いはメモリインターフェイス幅だ。PC向けのG70は256bit幅のGDDR3インターフェイスを備えている。それに対して、RSXはメモリ帯域から逆算すると128bit幅となる。メモリコントローラは半分に減っていることになる。メモリ容量は256MBなので、DRAMチップは512Mbitのx32品が4個だと推定される。
RSXのメモリコントローラの構成図は推測で、まだ確実ではない。NV40/G70系アーキテクチャでは、メモリコントローラは4パーティションに分かれている。各パーティションは64bit幅のDRAMコントローラに接続されている。ROPは4ユニットづつ特定のメモリ(コントローラ)パーティションに接続されており、各パーティションも相互に接続されている。メモリコントローラに対して16個のROP全てをクロスバー接続するのではなく、4 ROP単位で接続することで、クロスバーの設計を容易かつ効率的にしていると見られる。
RSXがG70と同様に、4 ROPが1 メモリパーティションに接続される形態を備えているとしたら、各メモリパーティションは1チャネル32bit幅のDRAMコントローラに接続されていることになる。8 ROPが1パーティションだとすれば、64bit幅のDRAMコントローラに接続されていることになる。
ちなみに、PLAYSTATION 3は、Cellに256MBのXDR DRAM、RSXに256MBのGDDR3と、2種類の異なるメモリを備える。NVIDIAのKirk氏はその理由について次のように述べている。
「各メモリ技術は、それぞれ異なる帯域とレイテンシ特性を持つ。我々は、それを研究して、GPUのパイプラインを最適化している。現在、我々のパイプラインは、GDDR3に最適化されている。もちろん、我々はXDR DRAMに最適化することもできるが、それはGDDR3に対する最適化とは異なるものになる。XDR DRAMに合わせてパイプラインを最適化するより、現在のパイプラインでGDDR3を採用した方が、結果的にはいいと判断した」
おそらく、これには時間的な制約も関係していたと推測される。XDR DRAMに合わせてメモリコントローラとパイプラインの最適化を行なうには時間がかかる。そのためには、NVIDIAの通常のGPU開発サイクルである18~24カ月でも足りないと推測される。
●プロセス技術の違いがクロックの違いに反映
RSXの方がG70よりコアクロックが高いのは、プロセス技術の違いが大きく影響している。G70が0.11μmプロセスに留まるのに対して、RSXは90nmプロセスを使う。G70世代がNV4x世代とほぼ周波数が変わらないのは、0.11μmプロセスだからだ。
「0.11μmプロセスはハーフ世代で、0.13μmや90nmのように完全に世代が変わるわけではない。オプティカルシュリンクになる。そのため、動作周波数は0.13μmと比べてそれほど上げられない」とKirk氏は説明する。
G70とRSXのプロセス技術が異なるのは、時期的な問題だという。
「G70はすでにレディで、そのためには0.11μmプロセスが望ましかった。G70で90nmプロセスを使う選択肢もあったが、選ばなかった。微細なプロセスでチップサイズを小さくしても、必ずしも歩留まりが上がらないからだ。ダイが大きくなっても、成熟したプロセスの方が、結局は歩留まりが高くなる」、「G70では非常に保守的なプロセスにした。Low-kを含めて、一切プロセスオプションは使っていない」、「RSXは、G70より後になる。そのため、90nmプロセスを使っても大丈夫だと判断した。PS3のローンチの時までには、90nmがレディになっている」とKirk氏は語る。
RSXはソニーグループのFab2と、東芝とソニーが共同で運営する大分ティーエスセミコンダクタ(OTSS)で製造される。90nmプロセスで、SOI(silicon-on-insulater)は使わないと言われる。同じ90nmでも、TSMCとは当然パラメータが異なる。
ちなみに、両GPUの物理的な設計は完全に並行して行なわれている。「RSXとG70は、ベースアーキテクチャは共有していても、実際の設計は全く別個にスタートしている」(Kirk氏)
G70は0.11μmプロセスであるため、ダイサイズが非常に大きい。ダイを見た限りは300平方mmを軽く超えており、NV40の最初のダイより一回り大きいように見える。それに対して、90nmのRSXは同程度のトランジスタ数でも70%程度ダイがシュリンクするはずだ。計算上ではダイは200~250平方mmの間になると見られる。だとすれば、PS2のGraphics Synthesizerの初代のダイ(279平方mm@0.25μm)よりも小さいことになる。ダイが小さければ、その分、歩留まりは高くなる。
微細化で、さらにダイは小さくなる。65nmにシュリンクすれば100平方mm台前半のダイサイズとなり、45nmになれば100平方mmを軽く切るようになると推測される。微細化によるコストダウンが見込めるわけだ。その段階になれば、DRAMチップをパッケージに入れ込んだSIP(System in a package)型にする可能性もあるだろう。また、SCEIはRSXについてはIPについて何らかの権利を保有しており、例えばCellとのシステム統合もできる可能性がある。
□関連記事
【6月22日】【海外】NVIDIAからハイエンドGPU「G70」が登場
http://pc.watch.impress.co.jp/docs/2005/0622/kaigai193.htm
【6月22日】NVIDIA、新GPU「GeForce 7800 GTX」
http://pc.watch.impress.co.jp/docs/2005/0622/nvidia.htm
【6月17日】【海外】SCEI 久夛良木社長インタビュー(4)
「PLAYSTATION 3のコストダウン戦略」
http://pc.watch.impress.co.jp/docs/2005/0617/kaigai191.htm
【5月26日】【海外】Xbox 360から見えるUnified-Shader時代のGPUの姿
http://pc.watch.impress.co.jp/docs/2005/0526/kaigai183.htm
【5月18日】【海外】ベールを脱いだPlayStation 3の姿
http://pc.watch.impress.co.jp/docs/2005/0518/kaigai180.htm
(2005年7月1日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2005 Impress Corporation, an Impress Group company. All rights reserved.