 |


■後藤弘茂のWeekly海外ニュース■シリアルになるFSBとメモリ
|
Intelの研究部門を統括するPatrick P. Gelsinger(パット・P・ゲルシンガー)CTO兼上級副社長(CTO & Senior Vice President)に、今後のCPU開発の方向性を聞くインタビューの2回目。10月の来日時のインタビューをベースに、9月のIntel Developer Forum(IDF)時の内容も若干加えてある。
 |
| Patrick P. Gelsinger氏 |
【Q】 CPUのマルチコア化は、メモリ帯域とFSB(フロントサイドバス)の拡張を要求するはずだ。マルチコア化により、ムーアの法則を超えてCPUが高性能化すると、メモリとFSBも急激に高速化しなければならないと予測している。
【Gelsinger】 その観測の通りだ。今後のプロセッサにとって、メモリ帯域は非常にクリティカルな部分だ。ケモノを養わなければならない(feed the beast)からだ。テラフロップのプロセッサには、1GB/secのメモリ帯域で(命令とデータを)供給することはできない。プロセッサへの供給のために、もっともっと広いメモリ帯域が必要になる。
ただし、帯域が必要なのは外部のメモリ帯域だけではない。多くの要素が絡んでいる。例えば、メモリ帯域の問題は、より多くのオンダイキャッシュを載せることで緩和できるが、ここでもさまざまな要素がある。キャッシュをコア毎に載せるか、複数コア間での共有キャッシュにするか、キャッシングアーキテクチャをどうするのか。
マルチコアの場合は、チップ上のCPUコア同士のインターコネクションをどうするのかも重要だ。ひとつのコアがあるデータをキャッシュしている場合、コア同士の(キャッシュコヒーレンシのための)コネクションを制御する必要がある。また、(共有する)メモリシステムへの帯域を、複数コア間でスケジュールすることも重要だ。実行時に間に合うようにデータを取ってこれるように予測してスケジュールする必要がある。この分野では、さまざまな研究と調査が行なわれている。全ての要素が帯域の面で重要だ。
【Q】 オフチップのインターフェイスの高速化は、シリアル技術の導入で実現するのか。現在、DRAMメモリとFSBはまだパラレルインターフェイスのままだが、これもシリアルに変わるのか。
【Gelsinger】 もちろんだ。我々は、時ともにポイントツーポイントのシリアルインターフェイスへと移行させていく。ちょうどI/OバスをPCI Expressに移行させたのと同じように、メモリも同様にシリアルへ移行する。シリアル化によって、メモリ帯域は飛躍し、メモリチャネルも簡単に増やせるようになる。FSBも同様に、パラレルインターフェイスからポイントツーポイントのシリアルインターフェイスへと移行する。
時とともに、パラレルインターフェイスは終わり、全てのインターフェイスがシリアルになる。
【Q】 IntelがPCI Expressの発表を行なった時、1GHz前後がパラレルインターフェイスの限界で、それ以上の転送レートではシリアルインターフェイスが必要になると説明していた。パラレル接続は1GHz程度で止まり、そこから先はシリアルになるのか。もう少し行けそうな気もするが。
【Gelsinger】 あの時の説明の背景には、1GHz前後の転送レートがマルチドロップ接続の限界だという、技術的な調査結果がある。我々は1,066MHz(のFSB)を提供しつつあり、ほとんどの人々は我々が1,266MHzまでいくと考えている。確かに、我々は1GHzを超えつつあるわけだが、そんなに大きく超えることはできない。1.2GHzは可能だろうが、5GHzにすることはできないと考えている。この点で、我々は、少し慎重だ。
●DRAMは2段階でシリアル化
【Q】 メモリではIntelが推進するFB-DIMMがシリアルインターフェイスを採用する。メモリについては、もうシリアル化は始まっているようだが。
【Gelsinger】 その通り、FB-DIMMは、メモリのシリアル化の第1歩だ。FB-DIMMアーキテクチャでは、DRAMはパラレルインターフェイスでバッファチップにアクセス、バッファがハイスピードのシリアルインターフェイスに変換する。ハブを挟んで、DRAM側のインターフェイスは広いパラレル接続、CPU側は狭い高速なシリアル接続となる。実質的にメモリインターフェイスをシリアル技術にする。
【Q】 FB-DIMMはハブチップを使うソリューションであるため、クライアントのPCには導入しにくい。
【Gelsinger】 確かにFB-DIMMのアーキテクチャはサーバー向けだ。サーバーではもともとメモリ容量の確保ために、バッファチップを載せたRegistered DIMMを使っているからだ。だから、我々は単純にバッファチップを高機能化することを提案した。バッファリングだけでなく、バッファリングとシリアル変換の機能を持たせるように。このアプローチは業界に受け入れられた。
しかし、デスクトップPCでは事情が異なる。PCではもともとバッファチップを持たないUnbuffered DIMMを使っている。PCメモリでは、インターフェイスコントローラはメモリチップにダイレクトに統合することが求められる。そのため、デスクトップでは少々移行に時間がかかる。
【Q】 そうすると、将来的には、DRAMチップ自体がシリアルインターフェイスを搭載すると考えていいのか。
【Gelsinger】 それについては、話はもう少し複雑で、困難がある。まず、プロセス技術の問題がある。我々のようにハイパフォーマンスロジック回路を作っているとシリアル化は容易だ。高速性が要求される次世代I/Oは、高速ロジック回路に合致するからだ。
それに対してメモリはDRAMセル密度に最適化してきた。「我々はbit当たりの単価を下げる方向に向かってきた、トランジスタ性能ではない」と彼らは言う。そのため、ほとんどのメモリ向けトランジスタの駆動特性は、ロジック回路向けと比べると3世代ほど遅れている。言い換えると、今日のDRAM技術では、トランジスタの駆動特性は90nmではなく、250nmレベルにとどまる。だから、DRAMへのハイパフォーマンスインターフェイスの搭載は、今のところは非常に難しい。
しかし、それは必ず起こる。約束しよう。
【Q】 Intelは、銅ベースのシリアルインターフェイスの限界は12GHz程度で、その先は光インターフェイスになるとも説明した。
【Gelsinger】 我々はPCI Expressで2.5GHzを実現、さらに5GHz、7.5GHz、10GHzと伸ばして行こうとしている。シリアルインターフェイスの限界は、おそらく、10GHz、12GHz、15GHz、そのあたりだろう。業界の研究だと10GHz程度と言われているが、もしかすると、15GHz、あるいは20GHzまで行けるかもしれない。しかし、100GHzではない。そのあたりのどこかで、我々は光インターフェイスへと移行するだろう。
パラレルからシリアルへの移行は、ピン当たりの転送レートを高めるためだった。光への移行では、重要なのは多分コストになる。例えば、銅配線で10GHzの時に、光で40GHzを達成できるとしよう。その場合、光インターフェイスのピン当たりのコストが銅の4倍以下になると光の方が安くなり、移行できるようになる。コストエフェクティブであることが重要な要素だ。
そのため、Intelは光インターフェイスのコストを下げる研究に注力している。シリコンフォトニクスで、光インターフェイスを直接シリコン上に組み込もうとしている。これが実現すれば、光のコストをドラマティックに下げることができる。しかし、全てはまだ研究段階だ。
●ランタイム環境への移行を前提にしたCPU開発
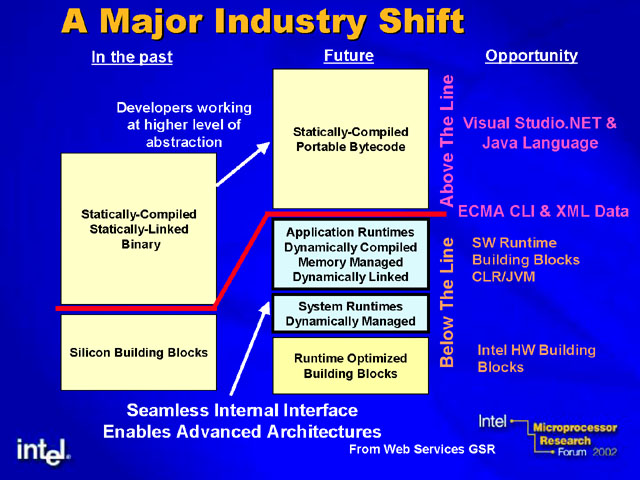 |
| 「Microprocessor Research Forum」で示されたランタイム環境への移行。PDF版はこちら |
【Gelsinger】 逆に私の方から質問しよう。ランタイムは、Intelにとっていいことかわるいことか。あなたはどう思う。
【Q】 両面があると考える。中間コードをランタイムで実行するJavaや.NETのCLRになると、究極的にはその下のISA(命令セットアーキテクチャ)への依存がなくなる。Intelの、現在の利点は、IntelのISAに膨大なソフトウェア資産があることだが、それは薄れてしまう。だが、その反面、利点もあると理解している。ISAに縛られなくなることで、CPUベンダーはもっとラディカルにアーキテクチャを変革することができるようになると思う。
【Gelsinger】 あなたは3つのポイントのうち2つを指摘した。いい成績だが、もうひとつ付け加えることがある。それは新命令をISAに加える場合のことだ。現状では、新命令をCPUのISAに加える場合、全てのアプリケーションベンダーが対応するのには非常に時間がかかる。まず、アプリケーションベンダーは、1~2年後にコンパイラが対応するのを待たなければならない。新コンパイラを使い始めたとしても、それでコンパイルした次世代アプリケーションのリリースまで時間がかかる。そのため、新命令が幅広く使われるまでには、通常5年かかる。非常にスローだ。
実際に、MMXやSSEは5年かかった。場合によってはもっと長くかかることもある。そのため、我々はアプリケーションの増殖に力を注がなければならない。だから、新プロセッサの発表の時には、あなた方プレスを呼んで、数少ない対応アプリケーションを並べて「見ろ!」というわけだ(笑)。そうすると、あなたたちはいつも「我々がよく使うアプリが対応するのはいつ頃か」と聞いてくる。そういう時は我々は「それはわからない。アプリケーションベンダーと話してくれ」と答えることにしている(笑)。
ランタイムは、そのサイクルを短縮できる利点がある。新命令に対して、何百、何千のソフトウェアベンダーに対応してもらう必要がなくなる。1~2のランタイムに新命令を使ってもらうだけで、多くのアプリケーションが、新命令を利用できるようになる。
あなたの質問に戻ると、我々は、ランタイムがより良く動作できるシリコンの研究を行なっている。ガベージコレクション、コードトランスレーション、セーフデータタイプなどへのよりよいサポート、それからもちろんスレッディングのサポート。広いレンジで最適化を目指している。これらは、ハードウェアに実装するだけでない。いくつかはマイクロコードやファームウエアにも実装する。
説明したように、これまでは最適化には5年問題があった。ソフトウェア側がそこから利点を得られるようになるまで5年かかった。
しかし、ランタイムの場合は、5年問題は解決される。アプリケーションは古いコードのままで、リコンパイルも再最適化も、再リリースも再検証も必要がない。すぐに、新しいハードウェア仕様の利点を得られるようになる。
ただし、OSやクラスライブラリは依然としてISAに堅固にバインドされ続けるだろう。だから、ISAの価値がなくなるわけではない。しかし、多くのアプリケーションコードは、中間コードで走るようになり、それはランタイムを通してアクセラレートされるようになる。
●コンパイラレベルでスレッド生成や投機スレッドをサポートへ
【Q】 マルチスレッドへのソフトウェアの対応を促すために、Intelはコンパイラレベルでスレッドの自動生成をサポートし始めている。こうした手法は一般的に浸透すると思うか。
【Gelsinger】 現状ではまだいくつか問題がある。1つ目は、プログラマにとってデバッグが問題になることだ。スレッド化されたプログラムはデバッグが難しい。2つ目は、パフォーマンス面での恩恵(ベネフィット)がそこそこでしかないこと。なぜならコンパイラは、まだ初期段階であるため、非常に保守的でパフォーマンスを追求していない。
しかし、こうした問題も時間が経てば解決されるだろう。現状は、かつてのベクタ化コンパイラと似ている。スーパーコンピュータで、最初にベクタ化コンパイラが登場した時に、プログラマは使いたがらなかった。しかし、時間とともに、ベクタ化コンパイラは業界のスタンダードになった。
【Q】 自動スレッド生成や投機マルチスレッドなども、ダイナミックコンパイラにもたらされるようになるのか。
【Gelsinger】 もちろんだ。我々がスタティックコンパイラで提供している機能は、将来のダイナミックコンパイラでも見ることができるようになるだろう。もっとも、Intelはランタイムを提供していない。ダイナミックコンパイラを提供しているのは、Sun MicrosystemsやIBM、Microsoftなどだ。しかし、Intel Compilerは業界では高く評価されている。そのため、Intel Compilerで採用したテクノロジは、静的コンパイラでも、プロファイルガイデッド最適化やダイナミック環境でも、段々と一般的になっていく。
【Q】 あなたは以前、「LaGrande」と「Vanderpool」が同じ基礎メカニズムを使うと説明した。「RING -1」とも呼べる新しいレベルで、仮想化やセグメンテーションをサポートすると。
【Gelsinger】 我々はLaGrandeとVanderpoolについてロードマップを持っている。我々が仮想化レイヤと呼ぶ部分のサポートする機能は、長期的に、どんどんリッチになっていくだろう。
まず、仮想マシンソフトウェアによるハードウェア仮想化を容易にする機能をハードに実装する。しかし、最初の世代は、フルのRING -1と呼べる機能を備えているわけではない。時間とともに、よりリッチな機能を加え、もっとフルRING -1のような機能を備えるようになるだろう。ページテーブルやI/O、割り込み、メモリエグゼキューションの仮想化などで、もっと機能を充実させる。
【Q】 GPUを汎用コンピューティングに使おうという動きがある。汎用GPUと呼ばれている動きで、今年前半はこの話題が大きく盛り上がった。IntelはCPUメーカーとして、こうした動きをどう見ているのか。
【Gelsinger】 確かに、グラフィックスパイプラインは、非常に高パフォーマンスな浮動小数点ユニットを備えている。だから、人々がそれを利用することに関心を寄せるのは不思議ではない。しかし、こうしたパイプラインをプログラムすることは非常に難しい。なぜなら、割り込みやメモリアクセスの汎用的なモデルを持っていないからだ。興味深い研究は行なわれているものの、実際にグラフィックスプロセッサを使うアプリケーションは非常に少ないと思う。
一般的に言って、GPUをもっと汎用にする、つまりGPUの中にCPUを作り出すようなこともできないだろう。なぜなら、CPUは高度にプログラマブルで、優れたコンパイラのサポートがあり、長期にわたって(プログラム性を)チューンされてきた。NVIDIAなどが語る汎用コンピューティングへのビジョンは楽しいが、しかし、幅広いアプリケーションが対応するとは考えていない。また、我々も、マルチコア、メニーコア(Many-Core)に向かいパフォーマンスを高める。そして、CPUはずっとプログラム効率がよい。
□関連記事
【11月12日】【海外】“Many-Core CPU”へと向かうIntel
http://pc.watch.impress.co.jp/docs/2004/1112/kaigai133.htm
(2004年11月15日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright ©2004 Impress Corporation, an Impress Group company. All rights reserved.