 |
■大原雄介のEmbedded Processor Forum 2004レポート■組み込み用マルチコアプロセッサ「ARM MPCore」 |
 |
| 発表を行なった同社CPU Engeneering ManagerのPeter Middleton氏 |
ARMは今年も基調講演を含む3つの発表を行なった。主要なテーマは2つで、1つはNECエレクトロニクスとの提携により完成したマルチコアのARM MPCore、もう1つは新しいVLIWスタイルのDSPである。まずはARM MPCoreについてご紹介したい。
●NECとの提携から生まれたARM MPCore
2003年10月、ARMとNECエレクトロニクスは正式に戦略的提携を結んだことを発表し、この際にNECエレクトロニクスはマルチプロセッサコアの技術をARMに供給し、これをもとにARMはARM V6ベースのマルチプロセッサ製品を開発することが明らかにされた。その成果が今回早速ARM MPCoreという形で登場したことになる。
さて、まず基本から行こう。なぜ組み込み系でマルチプロセッサが有効か? というと、消費電力をそれほど増やさずに、処理能力を増やすことができるからだ。
例えばここに100MHz動作、100MIPSのCPUがあったとする。これを400MHzで動かせば400MIPSになるし、あるいは4プロセッサで動作させればやはり400MIPSということになる。問題はこの場合の消費電力である。このプロセッサが100MHzで5Wの消費電力だとすると、4プロセッサの場合は5×4=20Wとなる。一方400MHz動作はというと、やはり5×4=20W「にはならない」。100MHzと400MHzで、同じ動作電圧で動作するとは限らないからだ。
一般に、動作速度を上げるためには、コア電圧も上げてやる必要がある。そうなると消費電力は電圧の2乗に比例して増えるので、つまり400MHz動作の場合の消費電力は25Wとか30Wになっても不思議ではないことになる。つまりマルチプロセッサは、消費電力を抑えて処理性能を上げるためにはきわめて有効な手段となるわけである。
また、そもそも絶対的な処理性能が欲しい場合にも役に立つ。基本的にCPUの処理性能は、そのCPUのアーキテクチャとプロセス(というか、そのプロセスで利用されるトランジスタの速度)で決まる。が、アーキテクチャはそうそう簡単に変えられるものではないし、プロセスにしても処理性能を重視すると消費電力などの点で組み込み系には向かないものになってしまう。マルチプロセッサ化は、こうした問題をクリアするための有効な手段となるわけだ。
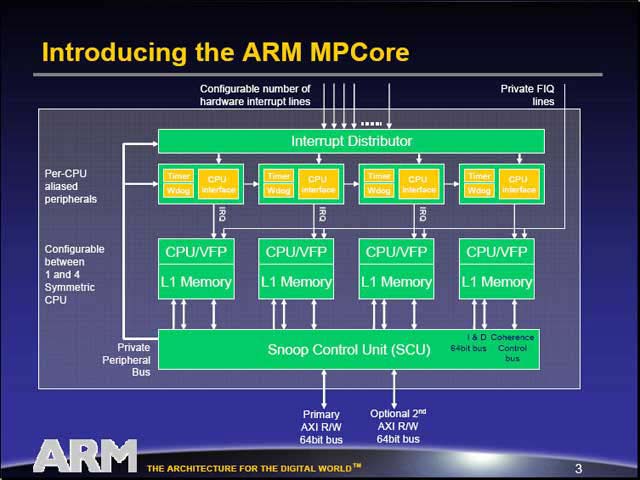
さて、マルチプロセッサにはこうしたメリットがある一方、リソースの排他やデータの同一性保持(スヌーピング)、割り込みの分配方法など難しい側面もある。こうした問題をどうするかについての1つの回答が、このMPCoreということになる。一見して感じるのは、非常に重装備になっていること。
・割り込みを任意のプロセッサに自由に分散できるという
・Watchdog/TimerをInterrupt Distributorの下に持っている
・各プロセッサにローカルL1を持たせ、これをSCUで管理した上でAXIバスに繋ぐ
という構造は、明らかに非対称型マルチプロセッサの構成を睨んだ構造である。このあたり、対称型マルチプロセッサを前提にすれば、もっとすっきりした構造になる。もちろんこれは、この構成では対称型マルチプロセッサが作れないという意味ではない。対称型と非対称型のどちらでも構成でき、かつ外部に高速なリンクなどを必要としない、という条件を満たすためには、ここまで複雑にならざるを得なかったという事だ。このあたりの構成の詳細については、後でまた触れよう。
●MPCoreの詳細
MPCoreの特徴の1つは、ダイナミックにプロセッサの数を変えられることだろう。こちらの記事でも触れた通り、昨年ARMはIEM(Intelligent Energy Management) Technologyを発表しており、動的に消費電力を最小に設定する仕組みを提供しているが、これに加えて不要なプロセッサは動的にシャットダウンしたり、必要になったら起動したりという仕組みをソフトウェアから利用できるようにするという(こんな動作はもう絶対に対称型マルチプロセッサではありえない)。これにより、マルチプロセッサ構成と言いながらも最小動作時の消費電力は既存の1プロセッサ構成のものとほとんど変わらない事になるわけだ。
 |
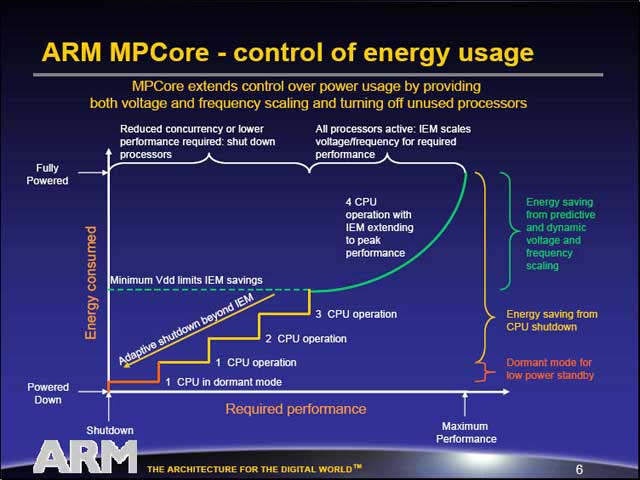 |
| 4プロセッサで1つのコアという形になる。AXIバスを2本出せるところがちょっと普通と異なる部分だが、これはAMDのOpteronとかIBMのPower4/5が複数本のI/Oリンクを出せるのと同じで、決して初めてというわけではない。ただ、このクラスのCPUでは初である | 段階的にCPUの数を減らすに伴い、消費電力も段階的に減ってゆく |
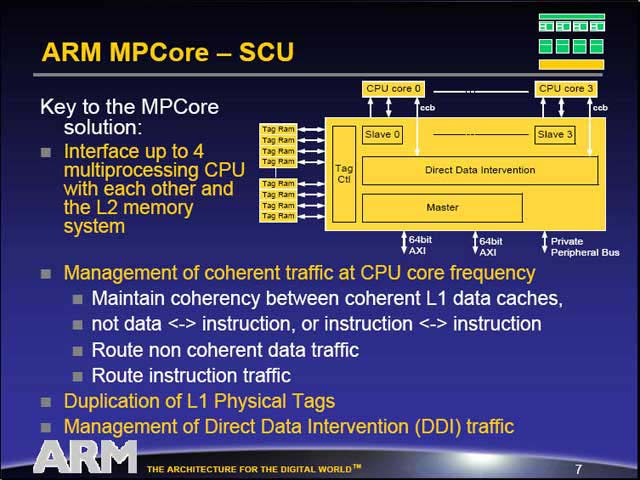
さて、もう少し細かく見てみよう。まずSCUの構造だが、面白いのは各プロセッサはSlaveとなり、MasterはSCU側が握っていることだ。通常シェアードバス方式を取るマルチプロセッサでは、CPUがマスターとなる関係でマルチマスター構造となるから、ここでバスアービトレーションによってマスター間の調停を取る必要があるわけだが、SCUではこのアービトレーションが必要ない事になる。ちなみにSCU→CPU間はMESIプロトコルを使って管理が行なわれている。
次は割り込みコントローラの構造だが、こちらは割り込みキューの機能を提供すると共に、共有メモリを使ったメッセージパッシングの機能も提供できるとしている。Timer/Watchdogが各プロセッサ用に別々に設けられているのは、そもそも各プロセッサが別々の動作周波数で動作したり、あるいは停止したりする事があるからで、ここに同じ頻度でWatchdogが入ったりするのはインプリメントがやや面倒になるからだろう。
 |
 |
| L1のTagRAMがSCU側にあるのも面白いが、冷静に考えるとこれがCPU側にあったらスヌープの際に余分な手間がかかるわけで、賢明なアイディアである | 最大988割り込みという中途半端な数が面白い。Message Passingは、例えばMailboxという形でプロセッサ間通信に使われる実装もあるが、プロセッサ間の同期(セマフォ)の実装に利用するのが一般的な使い方だろう。気になるのは、Timer同士の同期である。一応各Watchdog/Timerモジュールから横に矢印が出ているのは、このための同期だと思う |
ちなみにCPUコア自体は、ARM v6ことARM11コアをベースにしているが、
・スヌープの処理の高速のために、L1データキャッシュはインデックス化され、TagRAMが追加された
・ライトバック領域用にWrite allocationの機能が追加された。
・64bitロードストア命令が追加された
・スレッド制御レジスタが追加された。
・メモリ制御方式が(マルチプロセッサ環境に備えて)やや変更された
・(データバスのアクセスに関して)MESIプロトコルをサポートした
というのが主な違いとなっている。
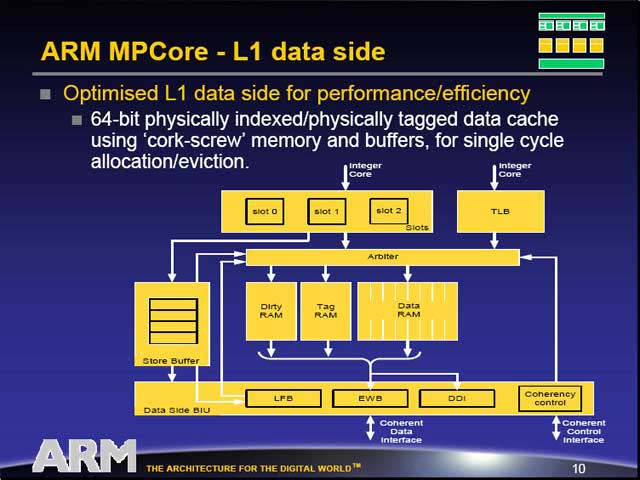
また、L1データキャッシュに関しては、“Cork-screw”型の構造が取られている。何が“Cork-screw”かというと、CPUコアからはSlot0~2というデータスロット経由でL1データキャッシュにアクセスする形を取るわけだが、ここでいったんData RAMやTag RAM、Store Bufferなどに(目的に応じて)データは展開される。ところがそのあと、BIU(Bus Interface Unit)にそれらが集約され、再びデータの流れが1本に絞り込まれる様を表しているわけだ。このあたり、オリジナルのARM11とはずいぶん異なる構造になっている。
このCork-Screw型のメリットはというと、同時に多数のメモリアドレスにアクセスが出来る事だ。特にマルチプロセッサ構成となる場合、メモリアクセスがボトルネックになる可能性は多い。これを可能な限り避けるため、CPU→メモリの間で絞込みを行なう事で同時アクセス性能を高め、その際に処理性能が落ちないようにデータキャッシュをはさむという訳だ。
一方命令キャッシュに関しては、もともとARM11でかなり強化されており、今回も特に機構的な変更は見られない。
 |
 |
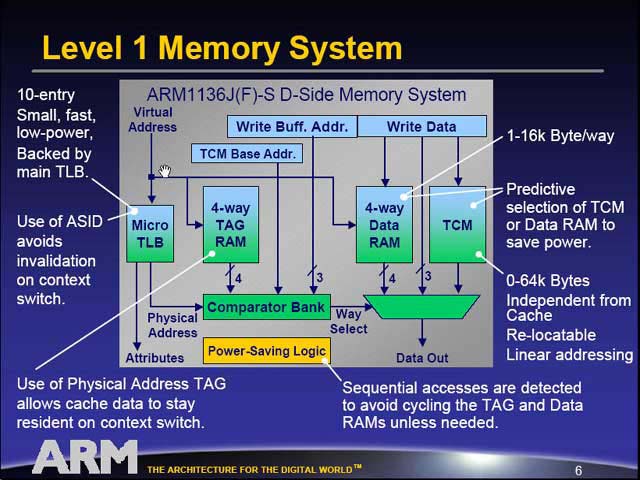 |
| ほとんどはハードウェア側の違いで、アプリケーションから見ると主な違いはThread context registerと64bitロードストアだけである。つまり従来のARM11アプリケーションはそのまま実行できるわけだ | L1データキャッシュのレベルでデータのコヒーレント性を確保するため、ちょっと面倒な構造になっている。ちょっと気になるのは、オリジナルのARM11にあったMicroTLBが見当たらないこと。右図と見比べるとこれが判る | 2002年のMPFで発表されたARM11(ARM1136J-S/ARM1136JF-S)のL1データキャッシュ構造図。単にArbiterが無い、という以上にいろいろ違いがある |
 |
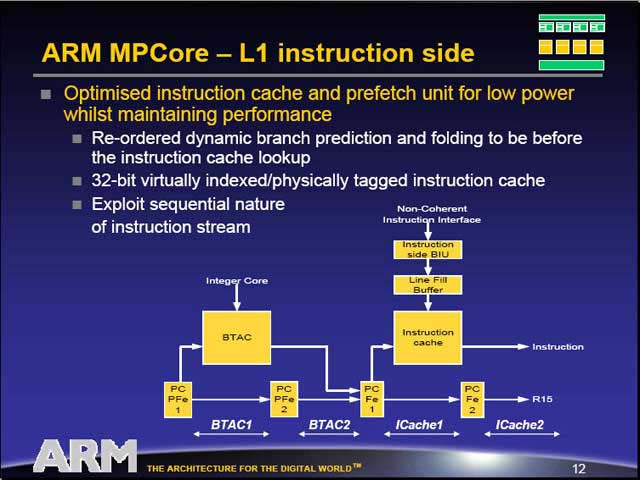 |
| メモリアクセスの模式図。WayというのはCPUの番号である。8バンクのメモリに対して、4つのプロセッサから同時にアクセスしても干渉しにくい構造になっている | ARM11はもともと64エントリのBTAC(Branch Target Address Cache)を装備して動的分岐予測を行なうとともに、これで予測出来ない場合は静的分岐予測を行なう仕組みになっている |
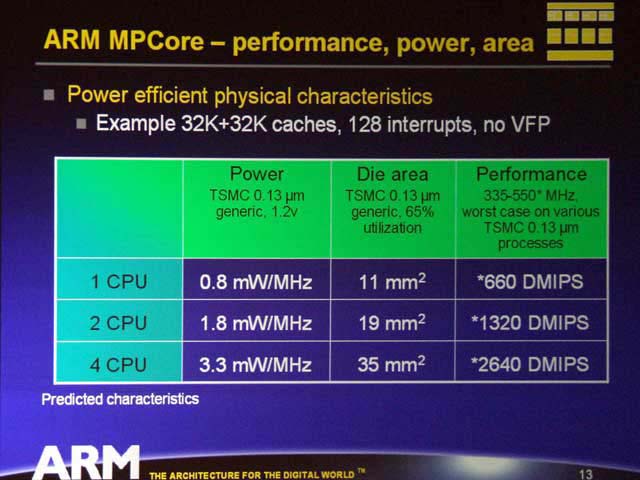 |
| 35平方mmというと、大体VIAのC5Jと同じ程度になる。消費電力は550MHz動作で1.8W強だからほぼ同等。2640DMIPSは換算しにくいが、Sandra 2004 SP1でPentium4/3GHzのDhrystone ALUの数字が9000強だから、C3/2GHzだと大体3分の1程度で3000位となり、大きな差はない。つまり、ARMアーキテクチャはVIAのC3並みの性能を得られるほどにまで進化してきた訳だ |
●性能向上の割に抑えられたダイサイズ
こうした結果として、どんな性能が得られるかだが、例えばTSMCの0.13μmプロセスを使った場合の2CPU構成と4CPU構成での特徴は写真右に示されるようになるという。ARM11コア自信の性能はこちらを見ると、1.2DMIPS/MHz、0.4mW/MHzとなっているが、これはキャッシュを含まない数値だから、多少消費電力が増えるのは仕方ないところだ。
さて結果を見てみると、プロセッサの数に応じて性能はシーケンシャルに増えているが、ダイ面積や消費電力はそれほどでもない。まぁ性能がシーケンシャルに増えるというのはあくまでも推定値であるが、ダイ面積や消費電力もここまでパラレルに増えない事で、ある程度マルチプロセッサコアの優位性が判るというものである。
このARM MPCore、現時点では2005年の出荷を予定しているという。
□Embedded Processor Forum 2004のホームページ(英文)
http://www.mdronline.com/epf04/index.html
□関連記事
【2003年10月20日】NECエレクトロニクスとARM、次世代マルチプロセッサ分野で提携
http://pc.watch.impress.co.jp/docs/2003/1020/armnec.htm
【2003年6月19日】大原雄介のEmbedded Processor Forum 2003レポート
ARMが3つの機能拡張を発表
http://pc.watch.impress.co.jp/docs/2003/0619/epf01.htm
(2004年5月21日)
[Reported by 大原雄介]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2004 Impress Corporation All rights reserved.