 |


■後藤弘茂のWeekly海外ニュース■AMD用チップセット市場の制覇を狙うNVIDIAの次世代戦略 |
●AMD市場の50%シェアが目標
NVIDIAはOpteron/Athlon 64(Hammer)向けのチップセット「nForce3(Crush K8)」ファミリに賭けている。Intel系CPUのバスライセンスを持たない同社は、AMD市場にフォーカスする。今夏から来年にかけて、Hammerアーキテクチャに特化したチップセット製品を次々に投入する予定だ。その中には、PCI Expressチップセット「Crush 3GIO」とGeForce FX統合版「Crush K8G3」も含まれる。
NVIDIAによると、同社のチップセット戦略の当面の目標は、AMDのデスクトッププラットフォームの50%シェアを取ることだという。NVIDIAの現在のnForce3系で技術的に目立つのは、Hammerアーキテクチャの利点をフルに活かしている点だ。Hammerでは、CPUがメインメモリのインターフェイスを備えるため、チップセット側にはメモリインターフェイスが必要ない。そのため、Hammer向けノースブリッジチップは、HyperTransportとグラフィックスインターフェイスだけの簡単な構造になる。そこで、NVIDIAは、nForce3ではAGPインターフェイスとサウスブリッジチップ機能を一体化した。ワンチップ化でコストが安くなるだけでなく、チップ間のデータ転送を省略できる分パフォーマンスも上がる。
NVIDIAが、最初に提供するチップセットは「nForce3 Professional 150(Crush K8)」で、シングルCPU構成のOpteronがメインターゲットになるという。「マルチプロセッサにももちろん対応しているが、ワークステーション市場の80~90%はシングルプロセッサだから、そこにフォーカスする」とNVIDIAのScott Baker氏(Senior Product Manager)は説明する。nForce3 150はAGP 8X、USB 2.0、ATA133などをサポートする。
NVIDIAはnForce3 Proをファミリ展開する。「今秋には機能を強化したnForce3 Professional 250(Crush K8S)を投入する」とNVIDIAのBaker氏は言う。250では新たに4ポートのSerial ATAとGigabit Ethernet(MACを統合)、ハードウェアアクセラレーテッドのRAID(0, 1, 0+1)が加わる。また、「IPv6のサポートやTCP/IPオフロードなど、コマーシャルネットワークに向けた機能を入れる。ネットワークプロセッシングはすべてnForce側で行なう」とBaker氏は説明する。
NVIDIAは「nForce3 Proラインはいずれもワークステーション向け製品」(Baker氏)と位置づける。しかし、ハイエンドコンシューマ市場にも力は注ぐ。「AMDが9月にAthlon 64を発表する時には、Athlon 64に対してもフルスイートのチップセットサポートを提供できる」とBaker氏は強調する。
●機能的にはPCI Express TunnelのCrush 3GIO
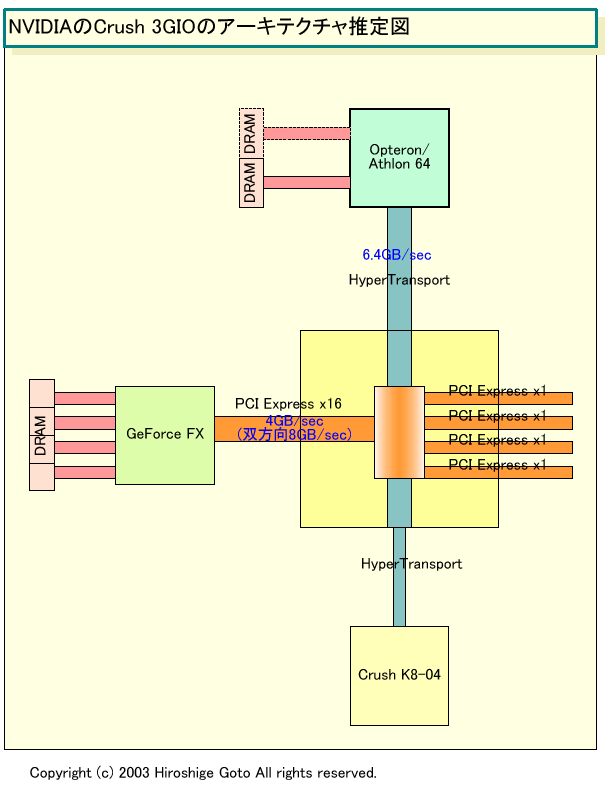 |
| Crush 3GIO PDF版はこちら |
NVIDIAは統合チップセットも、このアーキテクチャをベースにすると言われる。「(統合グラフィックス版は)適切な時期になれば、当然投入する。しかし、Athlon 64が登場した段階では、まだ市場のハイエンド。メインストリーム、そしてバリューへと降りてくるのはその先だ。統合チップセットが必要になる時期は、来年の中盤とか後半ではないだろうか」とBaker氏は言う。
Crush K8G3と呼ばれるNVIDIAの統合版チップセットは、Crush 3GIOにDirectX 9世代のGeForce FX系コアを統合したものになると言われている。まだ詳細はわからないが、GeForce FX 5200(NV34)と同系列のコアになると推測される。
AMD系のアーキテクチャの場合、グラフィックス統合チップセットにとってはハードルが高い。それは、メインメモリがCPU側に接続されているため、メモリアクセスをCPU経由で行なわなければならないからだ。そのため、GPU側からはメモリアクセスのレイテンシが増えてしまう。これは、3Dグラフィックスで、バックバッファの量が増え、メモリアクセスが増えると問題になりかねない。
それに対してBaker氏は「ペナルティがあるのは確かだが、それはどのチップセットベンダーにとっても同じことだ。また、HyperTransportは非常に高速なバスだから、ペナルティも、それほど大きくはない」と言う。
もっとも、NVIDIAは最近になって統合チップセットのグラフィックスコアの戦略を変更。GeForce MXコアからGeForce FXコアへと、搭載コアを切り替えた。そのため、アーキテクチャの変更を考えている可能性もある。ひとつの可能性として考えられるのは、チップセット側にも64bit程度のメモリインターフェイスを設けることだ。実際、SiSのHammer向け統合チップセット「SiS760」は、そうしたアーキテクチャを採る。CPU側に1チャネルのメモリ、チップセット側に1チャネルのメモリなら、ちょうどデュアルチャネルメモリ相当になるという考え方もできる。
●レンダリングサーバーにも対応できる?
NVIDIAのアーキテクチャが、VIAやSiSと異なるのは、チップセット間接続にもHyperTransportを使うと見られる点。そのため、原理的には、サウス側のチップとCPUとの間のレイテンシが小さくなる。そして、非常に面白いのは、そうしたアーキテクチャの場合、GPUベースのレンダリングサーバーの設計が容易になることだ。
現在、オフラインCG制作での最終レンダリングの多くはCPUで行なわれている。しかし、これが将来は、GPUでレンダリングする形へ置き換わっていくと思われる。フルプログラマブルになったGPUで、オフライン向けのシェーダを走らせるわけだ。その場合、1台のサーバーに多数のGPUを搭載したコンフィギュレーションが必要になる。ホストのCPUから多数のGPUにレンダリングジョブを割り当てるわけだ。そして、低コストにGPUレンダリングサーバーを作ろうとした場合には、特殊なロジックチップを作らないで多数のGPUを搭載したい。
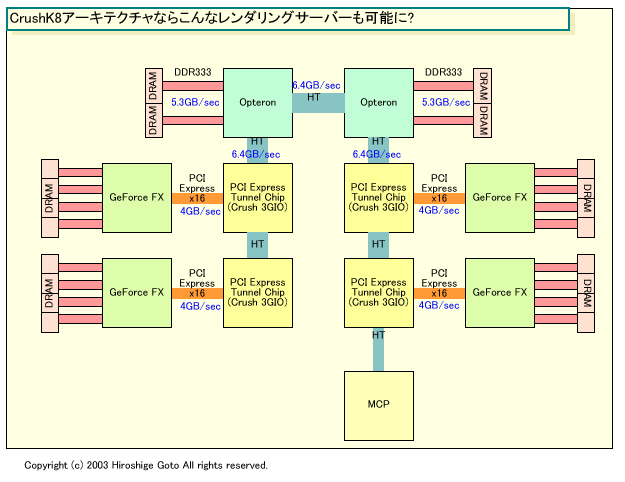 |
| CrushK8レンダリングサーバー推定図 PDF版はこちら |
nForce3が推定されるようなアーキテクチャを取るなら、こうしたニーズを満たすことができる。それは、HyperTransportでPCI Expressブリッジチップを複数繋げてしまうことができるからだ。HyperTransportでOpteronと複数のPCI Expressブリッジを高帯域で接続すれば、十分レンダリングに必要なデータを各GPUに転送できるはずだ。上がそうした想定のもとに描いた推定図だ。レンダリングジョブの間は、ホストからのコマンドとデータの転送量がそれほど多くないとするなら、GPUの数が8個以上の構成も可能かもしれない。各GPUはそれぞれ8個程度のピクセルに対するシェーダ実行が可能だから、合計で64ピクセルのレンダリングを並列にできることになる。
もちろん、NVIDIAが本当にこうした構想を描いているかどうかはわからない。しかし、技術的にはこうした構成の可能性もあるし、NVIDIAの方向性を考えると、ありえない話ではない。また、そう考えると、NVIDIAがディスクリートチップセットに力を注いでいる理由もそこにあるのかもしれない。
□関連記事
【6月12日】【海外】Shader 3.0とPCI Express x16への対応を進めるNVIDIA
http://pc.watch.impress.co.jp/docs/2003/0613/kaigai01.htm
(2003年7月2日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2003 Impress Corporation All rights reserved.