 |


■後藤弘茂のWeekly海外ニュース■究極のMacintosh用CPU「PowerPC 970」 |
●Macintoshの巻き返しを実現するCPU?
究極のMacintoshを実現できるCPU、それが「PowerPC 970」だ。
PowerPC系CPUは、ここ数年、x86系PCに周波数で大きく引き離されていた。特に、Macintoshが採用するMotorola系PowerPCは、周波数が低く、パフォーマンスでもx86に及ばない状況が続いており、それが、Macintoshの前途を暗くする原因のひとつとなっていた。
だが、IBMが10月15日に「Microprocessor Forum(MPF) 2002」(米サンノゼ)で発表したPowerPC 970は、こうした状況を多少なりとも変化させる可能性を秘めている。それは、PowerPC 970が0.13μm時に1.8GHzのクロックを実現し、パフォーマンスでは1GHz以上も上のPentium 4に匹敵するからだ。特に、マルチメディア処理性能は、大きく伸びる。そのため、このCPUをうまく使えば、Macintoshがコンテンツ制作といった場面で強力な競争力を維持(または強化)できる可能性がある。
| PowerPC 970 | |
|---|---|
| クロック | 1.4~1.8GHz |
| 製造プロセス | 0.13μm |
| L1命令キャッシュ | 64KB |
| L1データキャッシュ | 32KB |
| L2キャッシュ | 512KB |
| FSB | 900MHz(ベース450MHz) |
| トランジスタ数 | 5200万 |
| サンプル | 2003年第2四半期 |
| 量産 | 2003年後半 |
●全く新しいアーキテクチャのPowerPC
PowerPCは、'93年のPowerPC 601から現在のPowerPC G3やMotorolaが独自の拡張を加えたPowerPC G4系まで、継続して進化してきた。PowerPCのオリジンは、IBMのハイエンドRISC「Power」で、その命令セットアーキテクチャを引き継ぎ、PC向けにカットダウン&ワンチップ化されたのがPowerPCだった。RISCとしてはやや複雑な命令セットと、短いパイプライン、アウトオブオーダ実行、効率的な分岐処理などが特徴で、その後、機能拡張はされたが、基本的な設計思想はIBM系とMotorola系のどちらでも、現在まで引き継がれている。
だが、PowerPC 970はこのPowerPCの系譜とは異なる流れから生まれた。これまでとは全く異なるアーキテクチャのPowerPCだ。それは、IBMの最新のハイエンドRISCアーキテクチャ「Power4」をカットダウンして、小型コンピュータ向けにしたのがPowerPC 970だからだ。つまり、再びPower系アーキテクチャから、PowerPCに新しい血が注ぎ込まれたことになる。
オリジナルのPower4は、ワンチップ上にCPUコア2個と共有2次キャッシュが1個搭載されている「チップマルチプロセッサ(CMP)」型CPUだ。しかし、PowerPC 970はそれよりはずっと大人しく、普通の1個のCPUコア+L2キャッシュの構成となっている。しかし、CPUコアの中身は、Power4のマイクロアーキテクチャを持ってきており従来のPowerPCとは全く異なっている。また、Power4のアーキテクチャにプラスして、MotorolaのPowerPC G4に搭載されているマルチメディア拡張「AltiVec」互換のマルチメディアユニットも備えられている。
 |
 |
 |
| IBM PowerPCの系譜 | Power4からPowerPC 970へのアーキテクチャ変更 | Power4よりずっと小さくなったPowerPC 970。左がダイで右がパッケージ。それぞれ右がPower4、左がPowerPC 970 |
 |
 |
 |
| PowerPC 970の基本ダイアグラム | PowerPC 970のダイ。かなり整然としている | |
●リッチな構成のPowerPC 970
さて、PowerPC 970でなにがリッチかというと、まず演算ユニット数が膨大だ。
| 整数演算ユニット | 2 |
| ロード/ストアユニット | 2 |
| 浮動小数点演算ユニット | 2 |
| SIMD/ベクタ演算ユニット | 2 |
| ブランチユニット | 1 |
| 条件レジスタユニット | 1 |
マルチメディア系処理を担当するSIMD/ベクタ演算ユニットの片方は3つのサブユニットに分かれているので、細かく見れば全部で12個の実行ユニットがある。従来のIBMのPowerPC G3系と比べると浮動小数点演算ユニットやロード/ストアユニットが2倍になり、G4系と同様にSIMD/ベクタ演算ユニットが加わっている。ちなみに、Pentium 4は整数演算ユニットが2、浮動小数点/SIMD演算ユニットが2、ロード/ストアのアドレス生成ユニットが2なので、数の上ではPowerPC 970の方が浮動小数点演算/SIMD演算が強力だ。
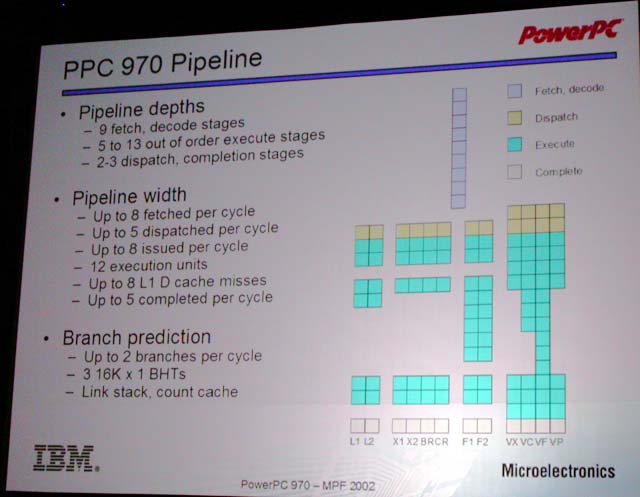
パイプラインを見ても、PowerPC 970は従来のPowerPCとは大きく異なっている。PowerPC系は伝統的にパイプラインが短いのが大きな特徴だった。G4までは整数演算で4ステージ、大幅に強化したG4+でさえ7ステージに過ぎない。
それに対して、PowerPC 970は、フェッチからコンプリーションまでで整数演算で16ステージ。ベクタ演算系はもっと長くて最長25ステージ。分岐ミス時のペナルティステージ数なら11だ。もちろん、分岐ミス時でさえ20ステージ(しかもx86命令デコードは含まない)もあるPentium 4の異常に深いパイプラインと比べると、PowerPC 970はおとなしい。しかし、PowerPC 970のパイプラインは、今までのPowerPCと比べると2~3倍長いことになる。
パイプラインが深くなったのは、ひとえに高速化のためだ。PowerPC 970は、従来のPowerPCとはかなり異なる高速化手法を取っている。それは、PowerPC命令をいったん単純な内部命令に変換して実行する手法だ。そのために、命令フェッチ&デコードに9ステージも費やしている。
●PowerPC命令を分解するPowerPC 970
この9ステージで具体的になにをしているのか。PowerPC 970は8命令/サイクルで命令フェッチができる。このフェッチしたPowerPC命令を、Power4系アーキテクチャでは、複数のシンプルな内部命令に分解(crack)する。シンプルな命令に分解することで、エグゼキューションステージでの高速実行を可能にする。つまり、Pentium 4やHammerが、複雑なx86命令をRISC風の内部命令に分解するのと同じ理由でPowerPC 970も命令を分解するわけだ。
PowerPC 970がこんな面倒なことをするのは、PowerPC命令セットがRISCにしては複雑な命令を含んでいるためだ。RISCのもともとの理念は、命令セットをデコードと実行が簡単なシンプル命令だけに絞って、高速CPU設計を容易にすることだった。しかし、PowerPCも登場から10年近く経ったため、設計時には想定していなかったような高速化が要求されるようになり、さらにシンプルな命令に変換しなければ対応できなくなったようだ。確か、数年前のMPFのパネルディスカッションでIBMは、PowerPCはx86のようなデコードの負担がないからパイプラインはx86系CPUほど深くならない、というようなことを言っていたと思う。しかし、もうそうしたセオリーは通用しないようだ。
こうしたアーキテクチャ変更の結果、PowerPC 970ではRISCの特徴のはずだったショートデコードは完全に失われている。もちろん、PowerPCアーキテクチャの特徴だった短い分岐ペナルティもない。分岐ミス時のペナルティはPowerPC G3が2サイクルなのに、PowerPC 970は11サイクルとはるかに長い。つまり、理論上はCPUの効率が悪くなる。
そのため、PowerPC 970は分岐予測も大幅に強化している。これも、x86系CPUのトレンドと同様だ。こうした流れを見ると、PowerPC 970はPowerPC本来の特徴の半分を失って、その代わり、x86系CPUと同じようなアプローチを取り込んだと見ることができる。変な話だが、x86系CPUを見てくるとわかりやすいCPUだ。極端な言い方をすれば、PowerPCのx86系CPU化とも呼べるかもしれない。
 |
 |
| PowerPC 970のパイプライン。下の4つのグループは左からロードストア、整数演算&分岐、浮動小数点演算、SIMD/ベクタ演算 | SIMD/ベクタ演算ユニットの概要 |
●命令スケジューラの負担を減らす
PowerPC 970はフェッチ&デコードの9ステージの中で、命令のグループ化という処理も行なう。これは、変換した内部命令を複数個まとめたバンドルにいったん構成するもので、1グループは最大4命令プラス分岐命令で構成される。Power4系アーキテクチャでは、内部命令はインオーダコアではグループ単位で扱われ、アウトオブオーダコアに入るところで分解される。グループ単位で扱えるようにすることで、スケジューラの命令トラッキングの負担を減らすのが目的だと思われる。このグループ化は、やっていることは違うが、目的はBaniasのMicro-OPsフュージョンやAthlon/Hammer系のデコードと似ている。これもCPU設計のトレンドだ。
グループ化された内部命令は、デコーダからディスパッチステージへ送られる。ここの帯域は1グループ/クロックなので、PowerPC 970のピーク性能は最大で4命令+1分岐命令/クロックとなる。これは、通常のx86 CPUのピークである3命令/クロックより理論上高い。
Power4アーキテクチャでは、命令グループは、アウトオブオーダコアに送るMapperステージに送る時に分解され、命令発行ステージに送られる。PowerPC 970の場合、実行ユニットへの発行は、最大8命令/サイクルで可能だ。そして、アウトオブオーダコアからインオーダコアへのコンプリーションは、再びグループ単位で行なわれる。PowerPC 970では、200以上の命令をインフライトで制御できる。
PowerPC 970の実行ステージの詳細はわからない。しかし、Power4と同様なら、実行もレジスタファイルアクセスのステージが実行ステージから分離されていると思われる。実際、ステージ数を数えると、そうでなければ計算が合わない。つまり、ここも従来のPowerPCより細分化され、高クロック化が容易になっているわけだ。
●高速化に余裕があるPowerPC 970
こうしたアーキテクチャを考えると、PowerPC 970は従来のPowerPCと異なり、高速化ではかなりの余裕があると考えられる。0.13μm時のターゲットが1.8GHz。そうすると、90nmプロセス時には3GHz近くを狙える計算になる。90nmで4GHz台を狙うIntelにはかなわないが、少なくともAMD系CPUに近いクロックは狙えそうだ。また、パフォーマンス的にもかなり近づくことになる。
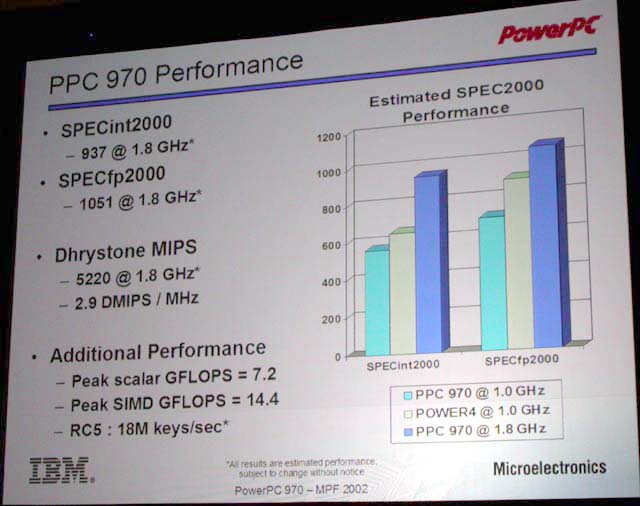
ちなみに、PowerPC 970の予想パフォーマンスをPentium 4、Hammer(Opteron)と比較すると次のようになる。
| PowerPC 970 | Pentium 4 | Opteron | |
| クロック | 1.8GHz | 2.8GHz | 2GHz |
| SPECint2000 | 937 | 1032 | 1202 |
| SPECfp2000 | 1051 | 1034 | 1170 |
Intel系CPUはPowerPC 970が登場する来年後半には3.3GHz以上に達しているはずなので、PowerPC 970は依然として追いつけない可能性が高い。しかし、これまでよりは差はずっと小さい。ちなみに、SPECint/fpの値はコンパイラの最適化などで大きく変わるので、実際に来年登場する時の値は、かなり変わっている可能性がある。IntelもマジックのようにSPECint/fpのスコアを伸ばしてきている。実際、PowerPC 970が性能でどこまで匹敵できるかはフタを開けてのお楽しみということになる。
 |
 |
| PowerPC 970のパフォーマンス | PowerPC 970のスペック |
□関連記事
【10月14日】IBM、1.8GHzのPowerPCを2003年に出荷
http://pc.watch.impress.co.jp/docs/2002/1015/ibm.htm
Microprocessor Forum 2002レポートリンク集
http://pc.watch.impress.co.jp/docs/2002/link/mpf02.htm
(2002年10月21日)
[Reported by 後藤 弘茂]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2002 Impress Corporation All rights reserved.