
|
|


●予想よりずっと控えめなMcKinleyのエンハンス
Intelの次世代IA-64プロセッサ「McKinley(マッキンリ)」は、現在のItanium(Merced:マーセド)と比べて、思ったほどエンハンスされていない。改良の幅は拍子抜けするくらい少ないように見える。どうしてこうしたアーキテクチャになったのか、謎の部分がある。そこからは、IA-64アーキテクチャの限界と新しい展開が見えるような気がする。
まず、McKinleyはMercedと比べて、実行ユニットは強化された。しかし、その強化は、かなり控え目だ。具体的には、整数演算ユニットが4個から6個に増え、それに対応して命令発行ポートも9から11に増えた。各実行ユニットは下のようになる。
分岐ユニット 3個
整数演算ユニット 2個
整数演算&メモリユニット 4個
浮動小数点演算ユニット 2個
Mercedでは、整数演算ユニットが2個、整数演算&メモリユニットが2個の構成だった。それに対して、McKinleyでは整数演算&メモリのユニットが4個に増えているため、最大4個のメモリオペレーション命令を同時に発行できる。つまり、Mercedでは1クロックに2つのロードまたはストア命令しか実行できなかったのに対して、McKinleyでは1クロックに2つのロードと2つのストアを同時に実行できる。これに対応して、L1データキャッシュもデュアルポートからクアッドポート(64bitのリードとライトがそれぞれ2ポートづつ)へと拡張されている。
 |
| MaKinleyブロック図 |
|---|
こうして見ると、実行ユニットの強化は、ロード/ストアを中心にした強化であることがわかる。逆を言うと、性能を伸ばすには、ロード/ストアを強化する必要があると判断したことになる。ちなみに、浮動小数点演算はデータを直接L2キャッシュから取ってくる構造になっているので、これは影響されない。それから、Merced向けのバイナリでは、増えた分の実行ユニットは使えないため、性能には寄与しない。
じつは、CPUにとって実行ユニットを増やすことは、それほど大変なことではない。浮動小数点演算ユニット以外のユニットは、今ではダイの上でたいした面積を取っていないからだ。ところが、IA-32(x86)の場合は、実行ユニットを増やせば、その分スケジューラの複雑度が増えてしまう。そのため、簡単には実行ユニットを増やすことができない。ところが、IA-64の場合は、スケジューリングはコンパイラが原則としてやるので、実行ユニットを比較的単純に増やすことができる。つまり、もっと増やすこともできたはずだ。それをしなかったのは、まず次の理由からだ。
●命令フェッチ幅は変わらず
McKinleyでは実行ユニットの強化に対して、フェッチ部分は不釣り合いに強化されていない。IA-64では、3命令づつ128ビットの「Bundle(バンドル)」と呼ばれる命令グループに収められる。Mercedでは、これを2バンドル/サイクルでフェッチするようになっていた。ところが、これはMcKinleyでも変わっておらず、2バンドル/サイクルづつのフェッチのままなのだ。L1命令キャッシュの帯域も、それに合わせて32GB/sec(1GHz時に256bit幅)となっている。
Merced→McKinleyで、フロントエンドだけを見ると6命令/サイクルの命令イシュー幅は変わっていない。つまり、McKinleyで、実行ユニットを増やしたのに、その実行ユニットに供給される命令数/サイクルは増えていないのだ。McKinleyで、命令の組み合わせの自由度が増えた(例えば4つのメモリ命令と2つの整数演算命令の組み合わせができる)わけだが、逆を言えば、それだけだ。というか、6命令/サイクルにつりあう分しか実行ユニットは増やされていないといった方がいいかもしれない。つまり、6命令/サイクルなら、整数演算ユニットを6個以上に増やしても意味がないから、6個までしか増やさなかったのだ。
McKinleyでは、以前は、このバンドルのフェッチ幅が増えるのではないかと予想されていた。'99年のMicroprocessor Forumのセミナーでの予測でも、3~4バンドル、つまり9~12命令/サイクルに増えると予測していた。実行ユニットを増やすなら、それに対する命令発行の幅を増やすと予測するのは当然だからだ。
ではなぜここで、9命令/サイクルにしなかったのだろう。じつは、Intelのプレゼンテーションにその謎の答えがある。IntelのFred Pollack氏(Intel Fellow,Director, Intel Architecture Strategic Planning, Intel Architecture Group)が昨年10月のPACT 2000で行なったプレゼンテーション「New Challenges in Microarchitecture and Compiler Design」によると、スタティックなILP(Instruction Level Pararelism:命令セットレベルでの並列化)では命令発行数をいくら増やしても実効IPC(instruction per cycle:1サイクルで実行できる命令数)は4.x命令/サイクルで止まってしまう(メモリボトルネックが全くない場合)という。そして、命令発行幅が“6命令”くらいまではIPCは順調に増えてゆくが、それ以上増やしてもサチュレートを起こしてしまい寄与しないという図を示している。
そう、6命令発行から先はサチってしまうのだ。これは、McKinleyのアーキテクチャと見事に符合する。だから、McKinleyでは6命令/サイクルにとどめたと思われる。逆を言えば、IA-64タイプのILPでは、もうMcKinleyが限界ということになってしまう。つまり、IA-64の性能を向上させるには、この先は、スレッドレベルパラレリズム(TLP:Thread-Level Parallelism)」に頼るしかないのだ。Intelが、McKinley-Madison系列からあとはTLPを使おうとしている理由はここにあると思われる。
●最近のCPUにしてはとても短いパイプライン
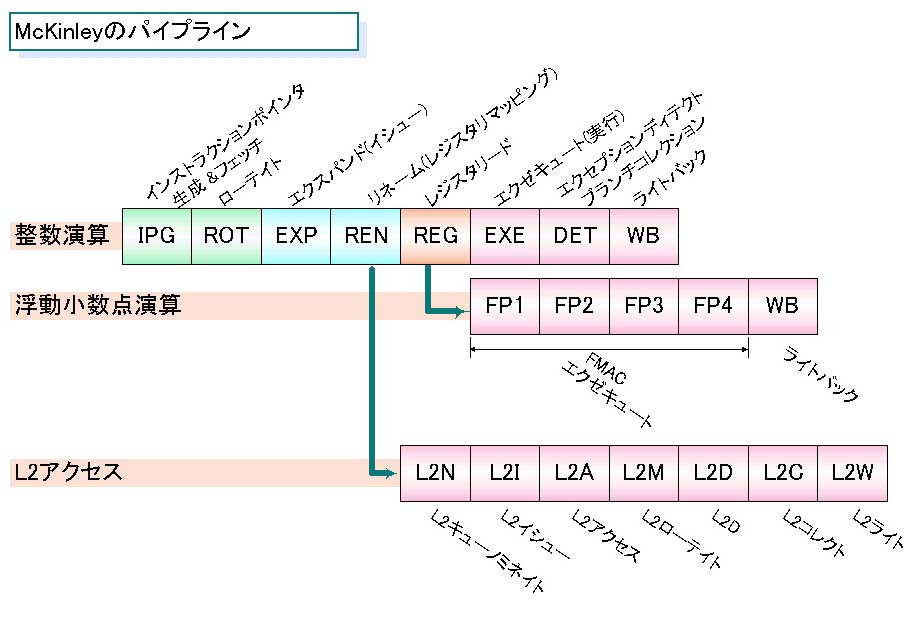
限界が見えた実行ユニットの強化。それに対して、McKinleyで目立つのは、パイプラインの改良だ。McKinleyのパイプラインは、整数演算で8段、浮動小数点演算で10段、L2アクセスで11段となっている。
 |
| MaKinleyのパイプライン図 |
|---|
パイプラインの構造は「McKinleyのパイプライン図」のようになっている。最初のIPGステージでIPジェネレーションとL1命令キャッシュアクセス、次のROTでフェッチした命令をインストラクションキューに入れるローテイト。次のEXPで11のイシューポートに発行。RENで、レジスタのリマッピングなど。REGで実際にレジスタファイルにアクセス。EXEで実行ユニットで実行する。
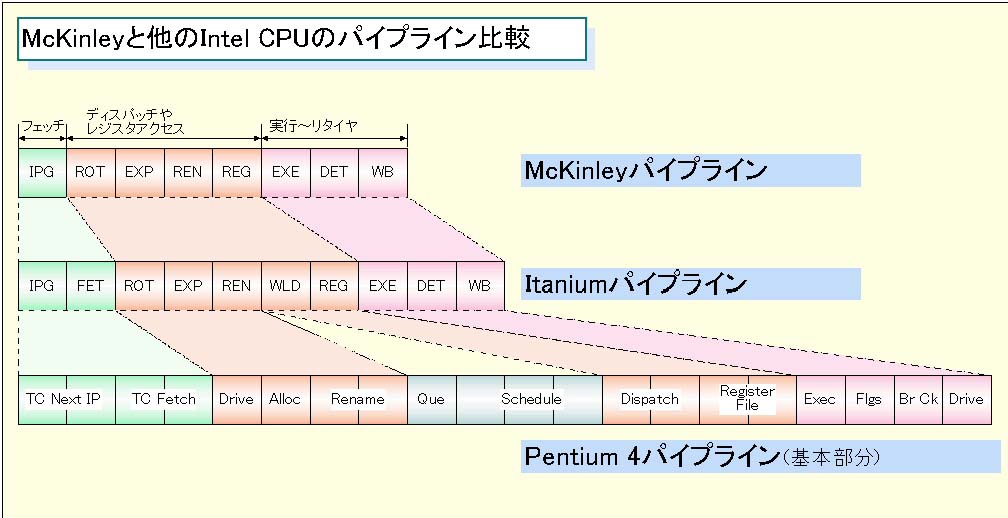
これだけを見ると、わかりにくいが、パイプラインをMercedやPentium 4(Willamette)と比較すると面白い。下が、比較しやすいように色分けした図だ。とりあえず、(1)フェッチ、(2)ディスパッチやレジスタアクセスやスケジューリング、そして(3)実行からあとの3つに分けてみた。ROTは本当はフェッチに含まれるべきなのだが、ここでは比較のために後ろのディスパッチやレジスタにくっつけた。
 |
| MaKinleyと他のIntel CPUのパイプライン比較図 |
|---|
まず、10ステージのMercedと比べるとMcKinleyは2ステージ減った。Mercedでは、フェッチがインストラクションポインタのジェネレーションとキャッシュアクセスの2ステージに分かれていたのが1ステージになった。また、レジスタファイルへのアクセスも実質2ステージ(WLDとREG)だったのが1ステージになった。つまり、一番物理的に時間がかかりそうで、高クロック化のひっかかりになりそうなキャッシュやレジスタへのアクセスのステージが軒並み減っているのだ。
さらに、これをWillametteと比較すると面白い。アーキテクチャが大きく異なるので単純には比較できないが、方向性の違いは明確だ。Intelは、Willametteのパイプラインは、分岐ミスL1トレースキャッシュヒット時で20ステージだと説明している。これには、IA-64にはないスケジューリングが含まれているが、それにしても細分化が目立つ。これはもちろん、ステージを細かく分けた方が高クロックで駆動しやすいからだ。
そして、Willametteでは、この20ステージのうちフェッチに合計で4ステージを費やしている。これは、キャッシュSRAMへのアクセスは物理的な制約があるので、高クロック化のヘッドルームのためには、ステージを分割しておいた方が得策だと考えたためと見られる。それに対して、McKinleyはこの部分が逆に1クロックと極端に短くなっている。また、レジスタアクセスも2ステージになっている。
パイプラインが長ければ長いほど、分岐ミスでパイプラインをフラッシュした場合のペナルティは大きくなる。Pentium 4はこのために、クロック当たりの性能はそれほど高くない。McKinleyはそれに対して、ひたすらパイプラインを短くしようとしている。McKinleyだと、ミスプレディクションのペナルティはわずか6サイクルだという。前にも説明した通り、ここにはクロック向上とは逆の方向へと走るIA-64の姿が見える。IA-32とは見事に逆向きのアーキテクチャなのだ。
(2001年9月19日)
[Reported by 後藤 弘茂]