 |


■後藤弘茂のWeekly海外ニュース■メモリ帯域をセーブするLarrabeeアーキテクチャ |
●演算はコストが安いが帯域はコストが高い
CPUコア数はムーアの法則に従って増えつつあり、45nmプロセスのサーバーでは、CPUコアの大きなIntel CPUでもネイティブ8コアに到達する。PC&サーバー向けの大型CPUコアでも10コア越えは目前で、CPUコアがより小型な「Larrabee(ララビ)」では16コアに達すると言われている。Larrabeeタイプのプロセッサが世代毎にCPUコア数を増やすと、24コア32コアはすぐにやってくる。
こうしたメニイコア時代のCPUの最大の問題の1つは、外部メモリバスと、オンチップインターコネクト、そしてメモリ階層の構成。この3つは密接に絡み合ってプロセッサの設計に大きな影響を与える。そして、今までのCPUでの手法は、メニイコアでは通じない。コアが数個の時と同じインターコネクトとメモリの構成では、数十個のコアを効率よく接続して動作させることができないからだ。
これまでのPC&サーバー向けCPUの場合は、CPUコアが大きく、チップ当たりの演算パフォーマンスが低かったため、こうした問題は大きくなかった。しかし、LarrabeeのようなメニイコアCPUになると、CPUコアは小さく効率的で、伝統的なCPUより10倍も演算パフォーマンスが高い。そのため、各CPUコアに充分なデータを供給することが重要になる。データに飢えた猛獣にエサをどんどん与える「ケモノを養う(feed the beast)」問題だ。
ここで重要なポイントは、トランジスタが小型化した現在は、演算ユニットのコストは極めて安いことだ。それに対して、オフチップの帯域は極めて高コストになりつつある。下は、ストリームプロセッシングに特化したメニイコアプロセッサを開発したStream Processors, Inc.のBill Dally氏(Co-founder, Chairman and Chief Scientist, Stream Processors, Inc.)が、昨年(2007年)のMicroprocessor Forumで示したプレゼンテーションだ。
 |
| 2007年のMicroprocessor Forumでのプレゼンテーション |
試算では90nmプロセスなら1GOPS(Giga Operation Per Second)当たりのコストはわずか0.02ドルで消費電力は10mWに過ぎない。ところが、オフチップの帯域はGB/sec当たりで2ドルのコスト0.5Wの電力となる。そして、さらに悪いことに、オンチップのトランジスタはプロセスが微細化するとさらに増えて、演算のコストはさらに下がって行く。ところが、オフチップの帯域のコストはそれほど下がらない。
つまり、何が起こっているかというと、演算パフォーマンスはどんどん上がるのに、チップの外からデータを供給するのが追いつかない状況になりつつある。飢えたケモノが騒いでいるのに、エサを運べないという事態になりかねない。データの供給が追いつかなければ、プロセッサは演算パフォーマンスを発揮できない。そして、LarrabeeのようなメニイコアCPUは、効率的な小型CPUコアを多数載せるために、演算パフォーマンスが非常に高く、この問題はよりクリティカルだ。
●試行錯誤でさまざまなアプローチをトライ
こうした事情から、メニイコア時代のチップ設計の方向性はある程度定められる。それは、オンチップのメモリをうまく使ってデータの局所性(Locality)を活用することで、オフチップのメモリ帯域を節約することだ。つまり、頻繁にタッチするデータは内部メモリに載せておいて、全ての処理が終わったらメインメモリに書き戻す。そうすれば、高速な内部メモリを使うことで、外部メモリ帯域を最小に抑えることができる。
しかし、そのためには、チップの中のメモリ階層を注意深く組み立てる必要がある。また、オンチップのインターコネクトも、外部バスから効率よくデータを転送できるように作る必要がある。
この問題に対する解は、まだスタンダードができておらず、各社がさまざまなアプローチを試みつつある段階だ。内部バスは「リングバス(Ring Bus)」がいいのか「クロスバスイッチ(Crossbar Switch)」がいいのか、あるいは「メッシュネットワーク(Mesh Network)」が適しているのか。CPU内部のメモリはキャッシュがいいのかスクラッチパッドメモリがいいのか、その中間的な解はありうるのか。下は2年前(2006年)のIntel Developer Forum(IDF)のプレゼンテーションで、Intelもかなり前からこれらの比較研究を行なっている。
 |
| 2006年のIDFで示したプレゼンテーション |
実際のチップでは、例えば、Cell Broadband Engine(Cell B.E.)はリングバスで9個のCPUコアを結び、各CPUコアの内部メモリのコヒーレンシを取るメカニズムは持たない。これは、IntelやAMDの現在のマルチコアCPUと対照的だ。IntelやAMDは、「クロスバスイッチ」でコアを結び、各コアのキャッシュのコヒーレンシを取る。一般に、CPUコア数が増えるにつれて、クロスバ接続は難しくなりリングバスやメッシュの方が適するようになる。しかし、分散した多数のキャッシュのコヒーレンシの維持は難しくなる。
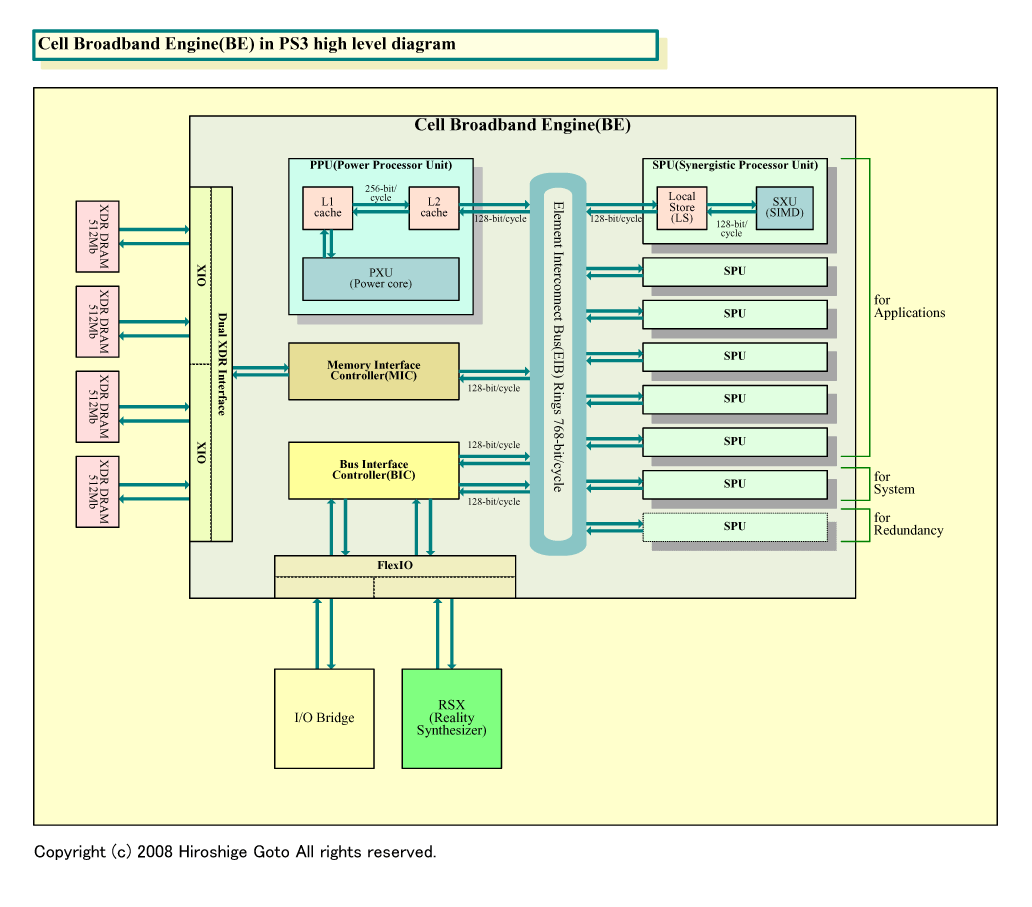 |
| Cellのダイアグラム ※別ウィンドウで開きます (PDF版はこちら) |
また、この問題はアプリケーションによって効率的な解が異なる。例えば、ストリームコンピューティングが中心となるなら、非明示的(Implicit)なアクセスのキャッシュより、明示的(Explicit)にアクセスできるスクラッチパッドメモリの方が効率がいい。ただし、プログラミングの手法に対する影響も考えなければならない。明示的にアクセスするスクラッチパッドメモリでは、メモリに対するスケジューリングを必ず行なう必要がある。消費電力も重要な問題だ。複雑な制御をハードウェアで行なうと、電力の消費が増えるために、できるだけメカニズムはシンプルにしなければならない。
●グラフィックスで効率のよいGPUのアプローチ
こうした要素を考え、ターゲットとするアプリケーションにおいて、もっとも効率よくデータの流れを作ることができるハードウェアを作るために、プロセッサベンダーはさまざまなトライをしている。
じつは、この苦しみは、GPUベンダーが一足先に味わっている。PC向けCPUの10倍の生プロセッシングパフォーマンスに、DirectX 10世代から突入しているからだ。加えて、非グラフィックスのより汎用なアプリケーションのサポートのために、GPUに柔軟性を加える必要が強まったためだ。GPUベンダーが出した、現状での解は、柔軟性やプログラムの容易性はある程度犠牲にして、グラフィックスに対してシンプルで効率のいいハードを作ることだった。逆の言い方をすれば、グラフィックスに最適化したハードを改良して、ある程度の柔軟性を挿入するというバランスを取った。
例えば、現在のGPUでは、内部バスはグラフィックスのトラフィックに最適な非対称型に構成している。柔軟なデータの入出力が可能なパスを作るが、CPUのように柔軟なインターコネクトでコア(=クラスタ)同士を結ぶ構成は取らない。内部メモリについても、ある程度の改良は行なう。伝統的なGPUは、リードバッファとライトバッファは持っていても、ライタブルなキャッシュメモリは持たなかった。現在のGPUは、小さなスクラッチパッドメモリを各クラスタに備えるが、コア(クラスタ)間でのコヒーレンシは取らない。
こうした構成によって、GPUは比較的シンプルで効率のよいマルチコア(マルチクラスタ)構成を実現している。グラフィックスに対しては、高い効率を依然として保っている。しかし、そのために、クラスタ(コア)間の協調や柔軟なデータフローにはある程度の制約がある。それが、GPUをより汎用的に利用する「GPGPU(General Purpose GPU)」あるいは「GPUコンピューティング(NVIDIA用語でグラフィックスAPIを使わないGPGPU)」を、やや難度の高いものにしている。
それに対して、LarrabeeやCell B.E.のようなCPU系のアーキテクチャは、より柔軟で汎用的なバス構造を取っている。より汎用的なアプリケーションに比重を置いているためだ。ここが、GPUとベクタ重視型メニイコアCPUの大きな分かれ目の1つとなっている。
●リングバスを使ったサーバー型インターコネクトからスタート
では、実際にIntelはLarrabeeでどんな解を採ったのか。Intelの解は、非常にCPU屋的で、汎用性と柔軟性を重視したものだった。それは、リングバスとキャッシュアーキテクチャだ。そして、このアーキテクチャチョイスのために、Larrabeeはグラフィックスではタイルアーキテクチャを取ることになった。
Larrabeeでは、リングバスをコア間のインターコネクトに使っている。リングのデータパスはそれぞれ片方向512-bit幅、双方向なら1024-bit幅。つまり、Larrabeeの16-wideベクタプロセッサのベクタレジスタ1本分のデータを1サイクルで伝送できる。
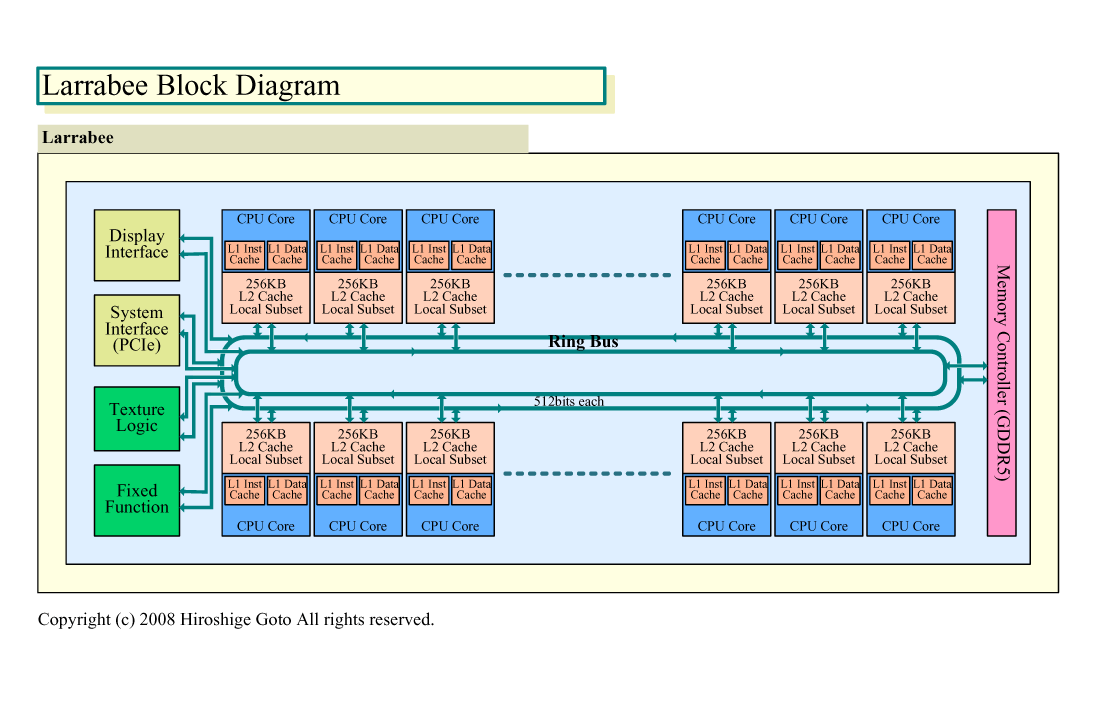 |
| Larrabeeのブロックダイアグラム ※別ウィンドウで開きます (PDF版はこちら) |
CPUコアなどのリングエージェントは、偶数クロックに1方向のメッセージを受け取り、奇数クロックに逆方向のメッセージを受け取る。CPUサイクルで1サイクル置きに、片方向のリングのメッセージを受け取るシンプルなシステムとなっている。リングはCPUコアの半分のサイクルでメッセージを伝送できることになる。
Larrabeeのリングバスは、汎用的で拡張性もある柔軟なシステムだ。リングバスなら、データがどんな形に流れても、CPUのパフォーマンスを引き出し易い。CPUコア数を増やすことも比較的簡単だ。クロスバスイッチのように、コア数が増えると設計がどんどん難しくなるといった問題もない。
 |
| Doug Carmean氏 |
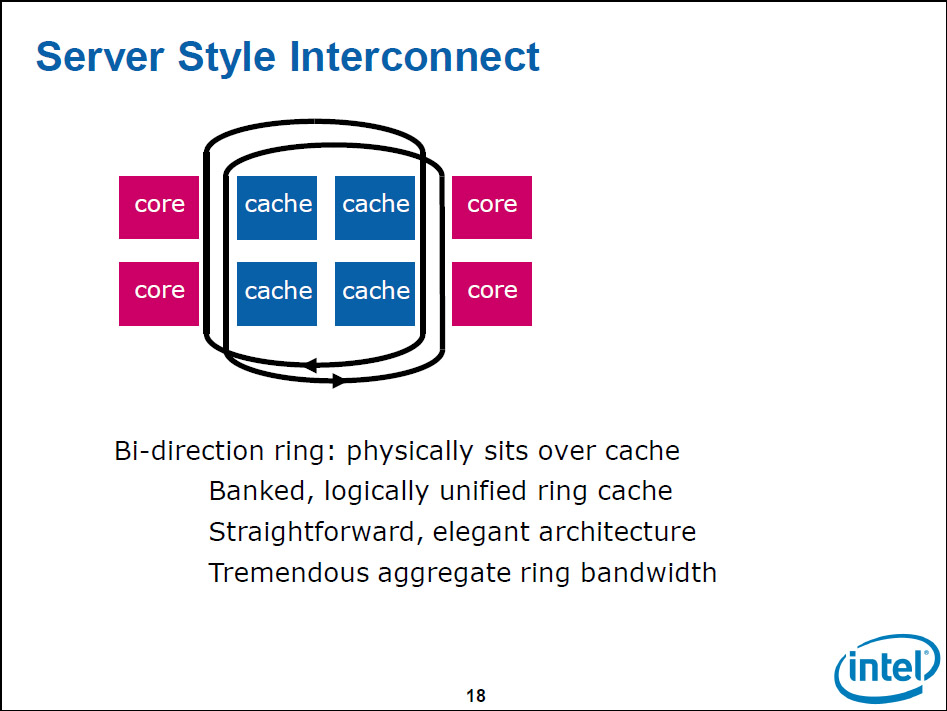
Intelは、Larrabeeの開発の当初からリングバスを使うつもりでいた。ただし、リングバスへのCPUコアやキャッシュなどの配置では、上流設計の段階で、さまざまな試行錯誤を行なった。Larrabeeのアーキテクチャを担当したIntelのDoug Carmean氏(Larrabee Chief Architect, Intel)によると、まず、多数のCPUコアを載せたサーバー型のインターコネクトを使ったアプローチからスタートしたという。CPUコアとキャッシュ、I/Oなどそれぞれをリングバスで結ぶアーキテクチャだ。
下の左のスライドがそれで、このアーキテクチャでは、「キャッシュは実際にはリングバス上でコアとは逆サイドに位置する」(Carmean氏)。CPUがキャッシュにアクセスする際はリングバスを経由する。ここで言っているキャッシュはL2で、論理的にはユニファイドされた構成となっており、各CPUコアでシェアして使う。下の右の図は、これをわかりやすく図に起こしたものだ。物理的にはCPUの中に大きなL2キャッシュが位置し、リングバスはそれを囲うように配置され、その外側にCPUコアが配置される構想だったと推測される。
 |
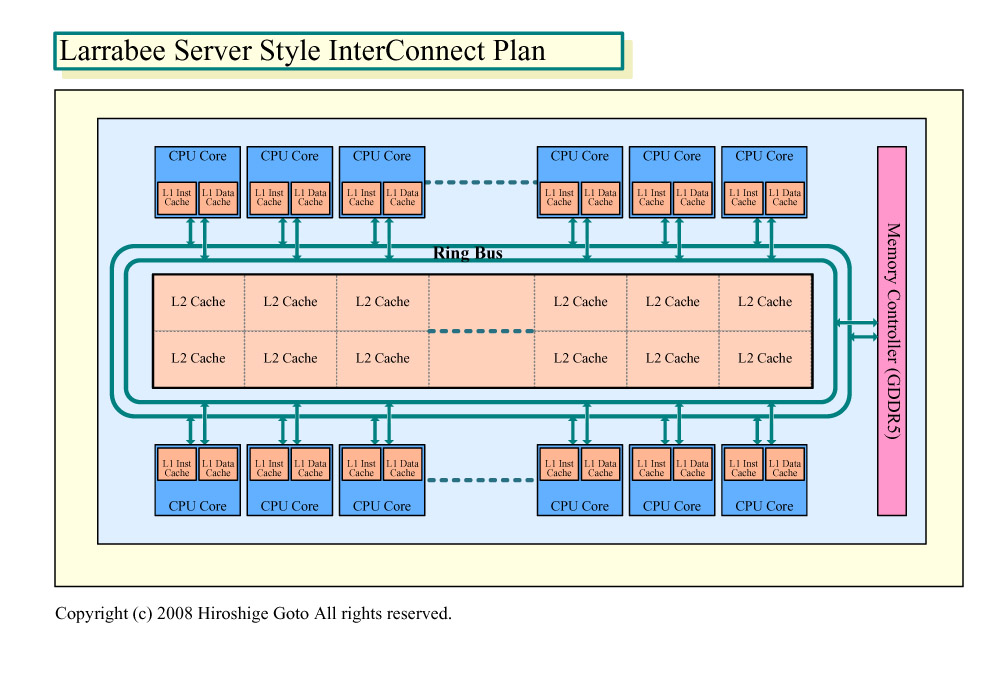 |
| Larrabeeのリングバス構想 | 構想を具体的にした図 |
この構成は、Intelが以前のIntel Developer Forum(IDF)で、マルチコア時代のキャッシュの一例として挙げた「リコンフィギュラブルキャッシュ」との組み合わせに向いている。リコンフィギュラブルキャッシュでは、物理的には単一のキャッシュメモリを、用途に応じて再構成する。各CPUコアに論理上のキャッシュを割り当てたり、部分的にライトバックからライトスルーに変更するといったポリシーの変更を動的に行なう。
Intelは、メニイコア時代のキャッシュの研究としてリコンフィギュラブルキャッシュを示していた。しかし、Larrabeeではこの構成はとらなかった。Larrabeeがターゲットとするアプリケーションに合わなかったからだ。
●グラフィックスでデータの局所性を活かしたアプローチ
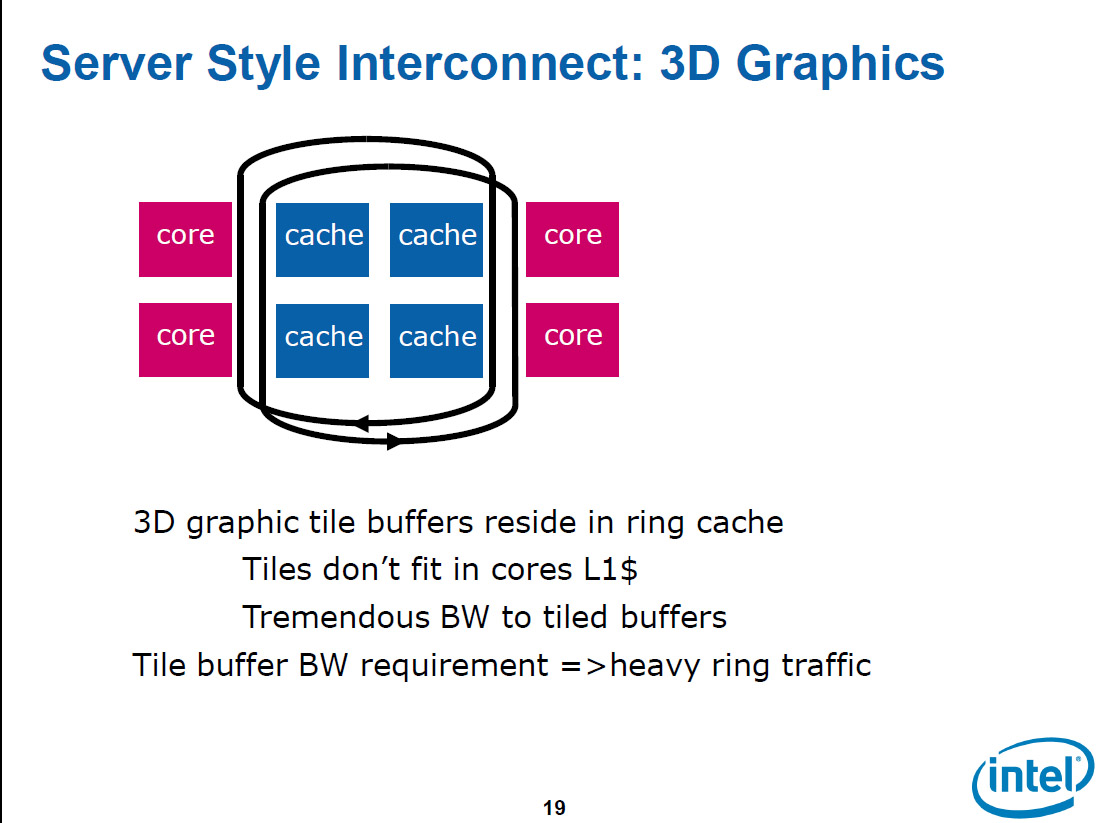
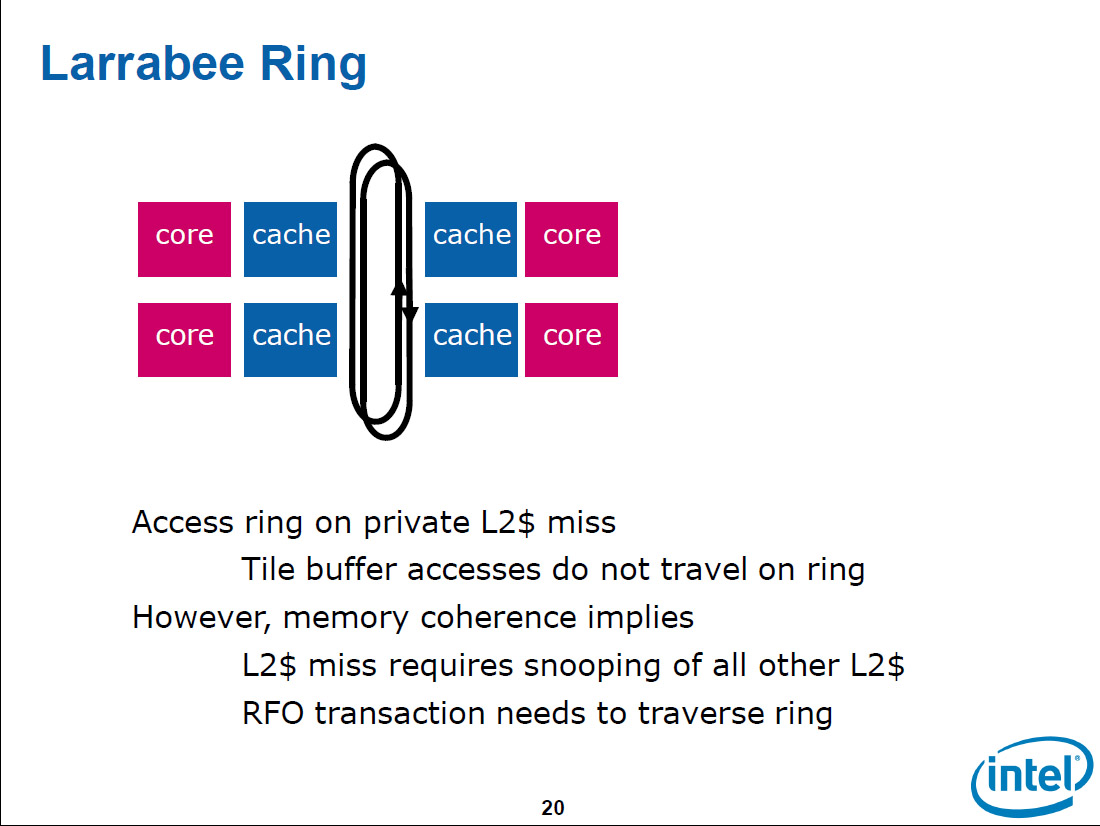
リングバスを介してCPUコアとキャッシュが配置されたバス構成は、「インターコネクトの構築方法としては、非常にエレガントで堅牢でスケーラビリティもある。多くの要素をコネクトする方法としてはシンプルで優れていたが、問題もあった」とCarmean氏は言う。それは、Larrabeeがグラフィックスアプリケーションを主なターゲットにするためで、グラフィックスの特殊なデータフローを考慮する必要があったからだ。下のスライドの左が問題点を指摘したスライドで、右がそれに対する解のスライドだ。
 |
 |
| グラフィックスのデータフローを考慮したときの問題 | 問題を解決するための解 |
伝統的な3Dグラフィックスパイプラインでは2カ所に非常にヘビーなデータ転送が生じる。1つはテクスチャフェッチで上りの帯域を大きく食う、もう1つは「ラスターオペレーション」とか「コンポジッタ」と呼ばれる最終段で、各ピクセルのカラーとZ(深度)データの書き込みと参照によって上下の帯域を食う。
伝統的なGPUでは、テクスチャフェッチはリードバッファである程度キャッシュするが、カラーとZは外部メモリへと打ち込む。GPUがとてつもないメモリ帯域を必要とする理由の1つはここにある。すでに説明したように、外部バス帯域は高コストなので、GPUは多大なコストを払っている。メモリインターフェイスにチップ上の膨大な面積とチップエッジ長を割き、高速メモリのために膨大な電力も消費している。現在のGPUも、この状況はそれほど変わっていない。
そして、GPUはこうしたデータの流れに合わせて内部インターコネクトも設計している。そのため、内部インターコネクトは非常に特殊で柔軟性のやや低いものになっている。例えば、GPUでは、テクスチャデータは上り専用の広帯域クロスバスイッチで送る。パイプラインの最終段のラスターオペレーションはメモリコントローラに直結して、内部インターコネクトを通さないように配置している。
Intelは、Larrabeeではグラフィックスに適した構造を取らなければならなかった。しかし、GPUのようにグラフィックスに特化して、柔軟性がより薄い構造も取りたくはなかった。Intelが選んだ道は、柔軟なリングバスでCPUコアを結び、帯域問題は内部メモリでデータの局所性をフルに活用することで解決する道だった。頻繁にタッチするデータはオンチップメモリに載せてしまい、CPUコアから短レイテンシ広帯域でアクセスできるようにする。下のスライドは、そのアプローチでどの程度メモリ帯域をセーブできるかを示したものだ。
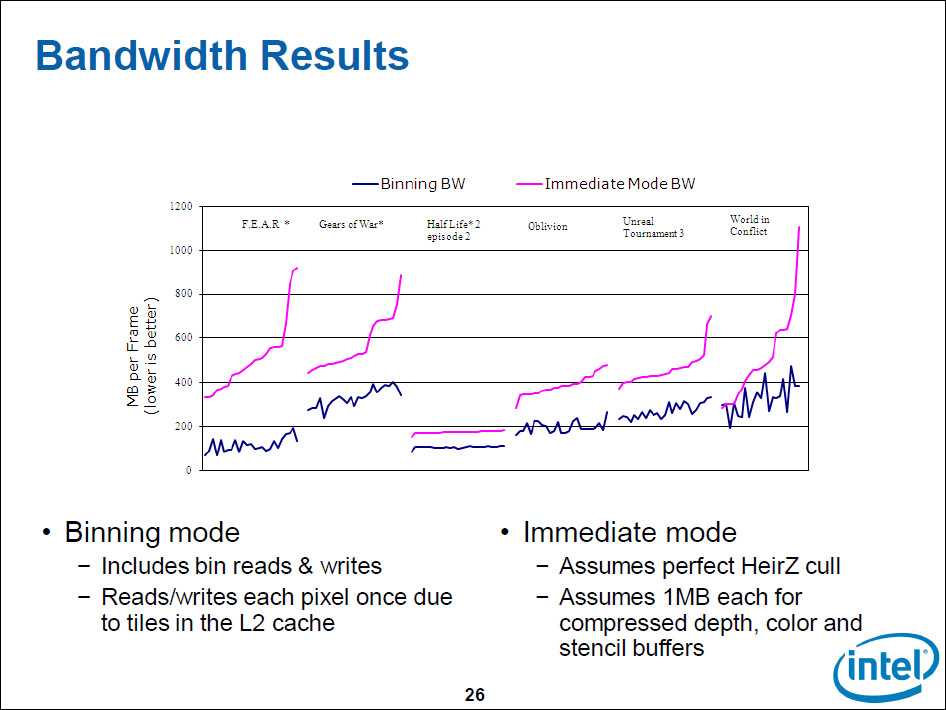 |
| メモリ帯域セーブの結果 |
しかし、局所性を活かすためには、Larrabee開発チームはスタート地点のサーバー型インターコネクトから離れる必要があった。また、グラフィックスではタイルアーキテクチャを取る必要があった。つまり、Larrabeeのタイルアーキテクチャとメモリ階層、そしてインターコネクト構造の3つは密接に絡んでいる。もう2つ加えると、外部メモリインターフェイスと汎用コンピューティングのプログラミングモデルも絡む。そして、バックグラウンドには、CPU内部の演算パフォーマンスのコストはどんどん安くなるのに、コストが下がらないCPU外部バスという不均衡がある。
次の記事では、実際にLarrabeeがどのようなアーキテクチャを取っているかをレポートしたい。
□関連記事
【10月6日】【海外】CPUに統合できるLarrabeeアーキテクチャ
http://pc.watch.impress.co.jp/docs/2008/1006/kaigai470.htm
【8月22日】【海外】正式発表されたLarrabeeアーキテクチャ
http://pc.watch.impress.co.jp/docs/2008/0822/kaigai461.htm
【8月11日】【海外】Cell B.E.と似て非なるLarrabeeの内部構造
http://pc.watch.impress.co.jp/docs/2008/0811/kaigai458.htm
(2008年11月11日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.