 |


■後藤弘茂のWeekly海外ニュース■PCからノースブリッジが消える日 |
●ノースブリッジチップが消えるIntelとAMDの戦略
PCからチップセットが消えて行く。メインストリーム&バリューPCのメインチップは、GPUを統合したCPUとI/Oチップの2チップ構成になる。PCのシステムパーティショニングは、新しい時代に入る。この変化は、CPUメーカーのFab戦略に大きな変動をもたらす。CPUメーカーは、統合化によって先端プロセスのキャパシティを増やさせなければならないからだ。
今後2~3年で、ノースブリッジチップ(MCH/GMCH/IOH)は、ハイエンドPC以外では姿を消してゆく。伝統的なPCの「CPU+ノースブリッジチップ+サウスブリッジチップ」の3チップソリューションは消え、「CPU+I/Oチップ」2チップ構成へと移行する。
Intelは、次のCPUアーキテクチャ「Nehalem(ネハーレン)」世代からCPU側にグラフィックス統合チップセット(GMCH)機能を統合する。具体的には、GPUコアとDRAMインターフェイス、PCI Express Gen2が統合される。当初はMCM(Multi-Chip Module)でGMCHダイ(半導体本体)をCPUと同パッケージに封止するが、次のステップでは1つのダイに統合すると見られる。AMDも、すでにCPUにDRAMコントローラを統合しているが、次のステップとして「Accelerated Processing Unit(APU)」でGPUとPCI Expressを統合する。統合化は、数年のうちにPC向けCPUのほとんどに及ぶようになると推測される。
 |
| PC向けNehalemファミリ (※別ウィンドウで開きます) PDF版はこちら |
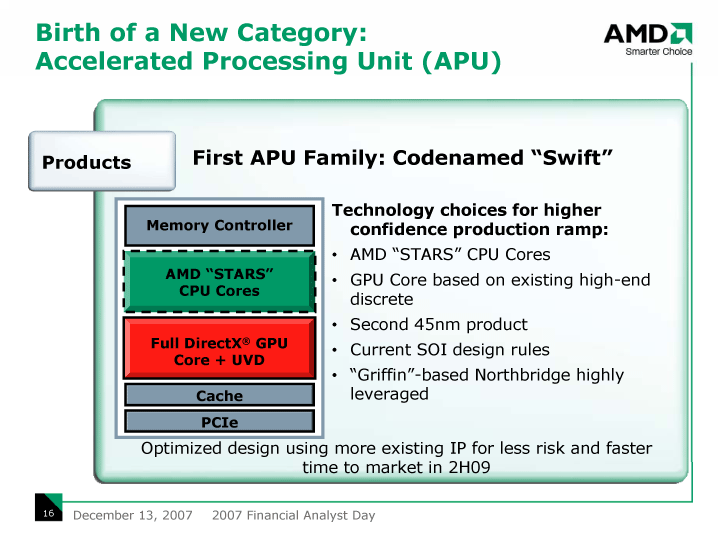 |
| AMDのAPUプラン |
PCにとっては、この動きはシステムパーティショニングの変化となる。CPUチップ側がCPUコアとGPUコア、そしてDRAMインターフェイスと高速I/Oを統合する。コンパニオンチップであるI/Oチップ側が中速及び低速I/Oを統合する。従来の、CPUコア、GPU+DRAMインターフェイス+高速I/O、中速及び低速I/Oという3分割から変わる。
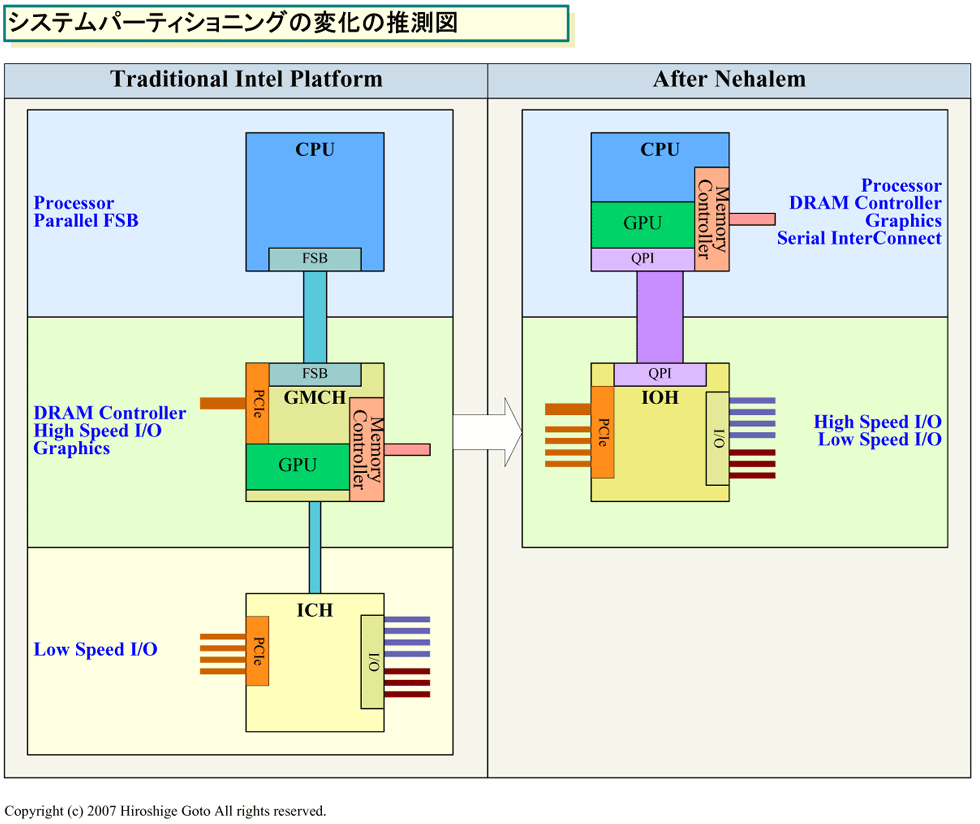 |
| システムパーティショニングの変化の推測図 (※別ウィンドウで開きます) PDF版はこちら |
これはPCにとっては大きな変化だが、組み込み系ではDRAMインターフェイスがCPU側にあるのは当たり前で、グラフィックス機能もCPU側に統合されていることが多い。また、システム統合化は、コスト面から見れば自然な流れだ。当然の統合化が、PCにもやってきたことを示しているに過ぎない。
オンダイの統合化までを視野に入れると、CPUとGPU、DRAMコントローラの統合は自然な流れだ。プロセス技術が微細化するにつれて、オンチップに統合できる機能は増えるのに、オフチップのインターコネクトの帯域はそれに見合うだけ増えて行かないからだ。CPUコアとGPUコアがリッチになると、両コア間と両コアとDRAMコントローラの間のデータ転送量が増える。ところが、FSBの帯域をそれに見合うだけ増やそうとすると、電力効率の面から不利になってしまう。電力効率の視点からは、ネイティブ統合化は必須だと言える。
ただし、I/OチップはCPUへの統合化が合わない。理由の1つは、互換性検証が非常にやっかいであるためだ。多くのデバイスを接続するI/Oチップは、検証に時間と手間がかかるため、開発サイクルが長いCPUに統合すると、CPU開発の足を引っ張りかねない。そのため、別チップにすることが合理的となる。実際には、DRAMインターフェイスとPCI Express Gen2も、検証がやっかいだ。しかし、そこまでは許容しようというのが、今の流れとなっているようだ。
●CPUとチップセットでバランスを取るIntelのFabキャパシティ戦略
統合化はCPUメーカーにとってFab戦略の仕切り直しも意味する。それは、キャパシティの配分が変わってしまうからだ。例えば、CPUとチップセットの両方を自社生産して来たIntelは、CPUを選択プロセスで、チップセットをCPUより1世代遅れたプロセスで製造して来た。
IntelのStephen L. Smith(スティーブ・L・スミス)氏(Vice President, Director, Digital Enterprise Group Operations, Intel)は、昨年(2007年)のIDF時に次のように説明していた。
「今日、チップセットは、大きなFabキャパシティを消費している。チップセットは、通常、CPUが使う最先端のプロセス技術『ジェネレーション“n”』より1世代遅れたプロセス技術を使っている。この世代のプロセス技術を、『ジェネレーション“n-1”』と呼んでいる。ジェネレーションn-1の製造キャパシティは、時にはジェネレーションnと同程度か、より大きな場合すらある。そして、ジェネレーションn-1では、GMCHとICHが大きなボリュームをドライブしている」
しかし、CPUとチップセットの統合化が進むとこの構図が狂うことになる。Intelは来年(2009年)投入するNehalemファミリの統合CPU「Havendale(ヘイブンデール)」と「Auburndale(オーバーンデール)」では、MCMによってGMCHをCPUに統合する。この段階では、GMCHはまだ独立したチップだが、製造プロセス自体はCPUと同じ45nmプロセスに移行すると推定される。そして、次の「Sandy Bridge(サンディブリッジ)」世代で、オンダイにGMCHが統合されるとすれば、GMCH機能は完全にCPUと同じ32nmプロセスとなる。
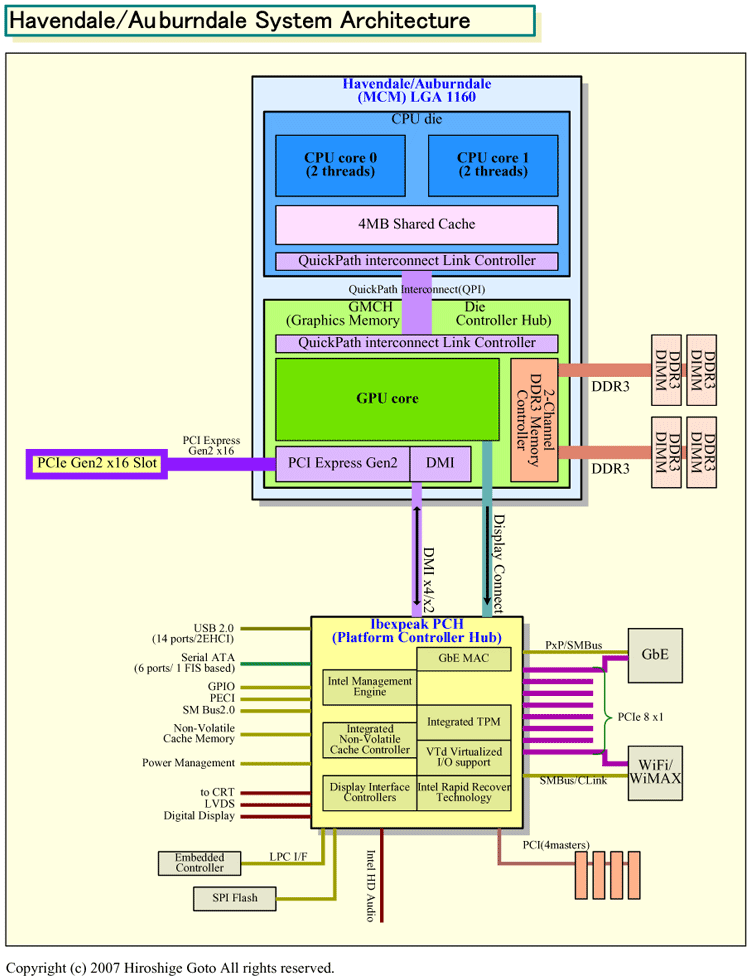 |
| Havendale/Auburndaleシステムアーキテクチャ (※別ウィンドウで開きます) PDF版はこちら |
●ジェネレーションnへと移行するGMCH部分
もちろん、チップセットの全てがCPUと同じプロセス世代に移行するわけではない。従来のサウスブリッジチップ(ICH)、Nehalem世代では「PCH(Platform Controller Hub)」と呼ばれるチップは、依然として古いプロセスに留まる。
「(製造プロセスがn-1からnに)移行するのは、グラフィックスコアについてだ。I/O回りのHubについては、ジェネレーションnには移行しない。グラフィックス機能の部分のゲート(回路)は、ジェネレーションnへと移行するが、いくつかのI/Oはジェネレーションn-1にまとめられるだろう。
なぜなら、I/Oインターフェイスによっては、依然として古い世代の(プロセス)技術が必要だからだ。(古いI/Oのために)より高い電圧をサポートしなければならないためだ。他にもいくつかの理由から、(I/O回りはジェネレーションn-1のチップとする)システムパーティショニングが必要となる」とSmith氏は説明する。
Intel全体で見ると、従来GMCH側にあったGPUコアとDRAMコントローラ、PCI Express Gen2の機能に必要なトランジスタが、ジェネレーションn-1での製造からジェネレーションnでの製造に移行する。しかし、それ以外のPCI Express Gen 1インターフェイスや、そのほかのICHの機能に必要なトランジスタはジェネレーションn-1のまま残ることになる。システムパーティショニングが変わったことで、Intelの全体のFabキャパシティの中で、ジェネレーションnとジェネレーションn-1の比率が変わることになるはずだ。
GMCH機能を統合してもダイサイズ(半導体本体の面積)が同じなら、Fabキャパシティへのインパクトはない。しかし、CPUメーカーは当然GMCH分のコストはCPU価格に加えるだろうし、ある程度のダイ増加は見込んでいるはずだ。その分のFabキャパシティは、ジェネレーションnへと移るだろう。
「その疑問は、部分的には正しい。ある程度の(ジェネレーションn-1の)製造キャパシティは、ジェネレーションnへと移行することになるだろう。残りの(ジェネレーションn-1の)Fabキャパシティは、依然としてI/Oデバイスを作るだろう。答えは、Fabによってそれぞれということになる。我々のアプローチの基本は、時間とともに、より多くのものをCPUへと統合して行くことにある。それにつれて、キャパシティも変わる」
●高騰する先端Fabのキャパシティがより必要になるCPUメーカー
先端プロセスのジェネレーションnのFabはまず付加価値の高いCPU生産で儲け、減価償却が進んだジェネレーションn-1のFabで、より利幅の薄いチップセットを製造する。これが、従来のIntelのFabキャパシティ戦略だった。だが、統合化によってその流れが崩れることになる。しかし、Smith氏は、状況が変わったことで、今ではその意味が薄くなってきたと説明する。
「我々のFabのスタッフは、これまで“n-1”から“n”へのプロセスジェネレーション転換を効率的にする方法を蓄積してきた。そのため、以前と比べると、効率的にジェネレーションnへと転換できるようになりつつある。
また、現状でもFabに対する投資の60%以上は、ジェネレーションnとn-1それぞれの再利用に使われている。つまり、ジェネレーションn-1のFabを走らせ続けるにもコストがかかっている。だから、投資の面では、次世代のテクノロジ(ジェネレーションn)にFabを転換させることに、それほどペナルティがあるわけではない。もちろん、現状のn-1をただ走らせる方が安い。しかし、転換しても、新Fabを建造するよりは安くつく」
従来は、ジェネレーションn-1からジェネレーションnへのFabの製造設備の転換に、かなりのコストがかかった。そのため、ジェネレーションn-1のFabはそのまま走らせて、ジェネレーションnのFabは新たに建てた方が経済的だった。だが、今では、n-1からnへの転換が効率的になったというわけだ。実際、Intel関係者は、45nmプロセスでは、Fabのツールのかなりの部分が65nm世代から継続利用できているという。
もっとも、32nmプロセス以降もこの原則が当てはまるかどうかはわからない。32nm以降は、プロセス世代毎に、さまざまな技術革新が必要となるため、プロセス移行のコストが跳ね上がる可能性があるからだ。実際、あるIntel関係者は、「この先は特に露光関係のコストが高騰し、コストの比率が変わる。全体で、どの部分のコストを削れるかを真剣に検討している」という。
Intelも、32nm世代からは液浸露光技術を採用する。その先にはIntelが長年研究開発を進めてきたEUV露光が待っている。また、22nmから先ではトランジスタ構造の変革も必要となる。コストの高騰は必至で、それをカバーする必要がある。その答えはFabの大型化とウェハの大型化だ。つまり、CPUメーカーのギガFabの建造競争は、ますます過熱することになる。
□関連記事
【2007年10月11日】【海外】Intel NehalemとAMD FUSION両社のCPU+GPU統合の違い
http://pc.watch.impress.co.jp/docs/2007/1011/kaigai392.htm
【2007年10月5日】【海外】Intelが目指すNehalemでのGPUとCPUの統合
http://pc.watch.impress.co.jp/docs/2007/1005/kaigai391.htm
【2007年9月21日】【元麻布】液浸露光技術で32nmプロセスを目指すIntel
http://pc.watch.impress.co.jp/docs/2007/0921/hot506.htm
(2008年1月22日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.