 |


■後藤弘茂のWeekly海外ニュース■現実路線へ修正されたAMDのFUSION |
●CPUコアとGPUコアが入れ替わった新FUSIONプラン
AMDはGPU統合型CPU「FUSION(フュージョン)」ファミリのファーストステップである「Swift(スィフト)」を、より穏当な計画に軌道修正した。AMDは8月の時点では、統合するCPUコアは次世代の「Bulldozer(ブルドーザ)」コアとしていたが、これは現行のK10(K8L)世代の「STARS」系コアに変わった。また、今春、日本AMDは、FUSIONのためにGPUコアを開発すると説明していたが、現在の計画ではSwiftに統合されるコアは「既存のハイエンドディスクリートグラフィックスコア」となる。これらの変更は、AMDの最終的なビジョンである、命令レベルでのCPUコアへのGPUコアの統合に、よりステップが必要になることを示唆している。
また、AMDは、2009年後半に登場するFUSIONが、45nmプロセスの最初の製品ではなく、45nmの2世代目の製品になることも明らかにしている。今春の時点では、日本AMDも、FUSIONが最初の45nmプロセス世代になるのか、その前に45nm CPUがあるのかわからないと説明していた。AMDは、45nmでいきなりFUSIONに踏み出すのではなく、枯れた製品でプロセスをドライブしてからFUSIONに至る、穏当なプランを明かしたことになる。
ATI Technologiesを買収して以降のAMDは、非常に論理的で壮大な技術ビジョンを示しているが、現実の製品の立ち上げはもたつくという、アンバランスな状況にあった。つまり、先の話はできても、手近なプランがうまく行っていなかった。AMDは、そうした状況を立て直そうとしているように見える。
今回の変更には、プラス面とマイナス面がある。プラス面は、変更の結果、FUSIONを含めたAMDのCPU計画がより現実的になったこと。マイナス面は、その結果として、AMDの技術ビジョンが、やや不鮮明になったことだ。AMDは、修正した統合的なビジョンを打ち出す必要がありそうだ。
 |
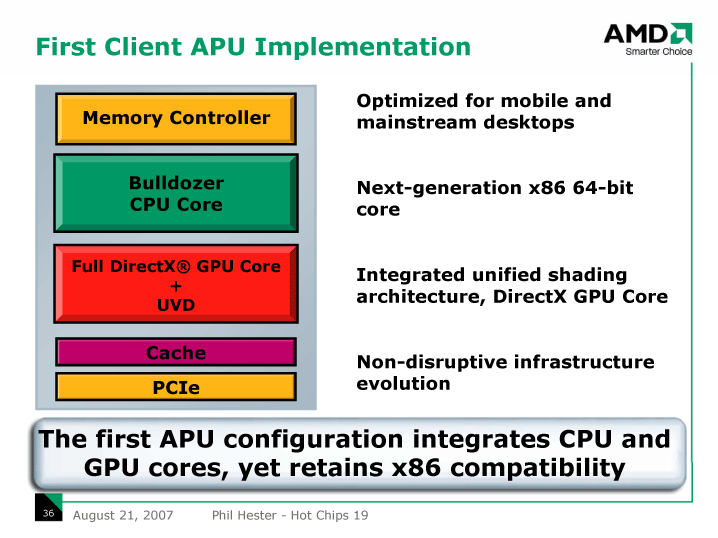 |
| 現在のFUSIONのプラン | 今年(2007年)8月のFUSIONのプラン |
●Barcelonaのもたつきで現実路線を強調するAMD
AMDの路線の変更は、半年の間を置いた2つのアナリストカンファレンスを見ると明確だ。今年(2007年)7月の「2007 Technology Analyst Day」では、次世代CPUコア「Bulldozer(ブルドーザ:BD)」と「Bobcat(ボブキャット)」を含む、大きな技術ビジョンが打ち上げられた。それに対して12月の「2007 Financial Analyst Day」では、BulldozerとBobcatはほぼ触れられず、FUSIONのより穏当な実装を含む、現実的な路線が明らかにされた。
もちろん、7月のAnalyst Dayが技術フォーカスで、12月のそれは財務フォーカスというカンファレンス自体の性格の違いもある。しかし、それ以上に目立つのは、現実的な製品ロードマップを示すことで、ネイティブクアッドコアの「Barcelona(バルセロナ)」の遅れによって失った信頼を回復したいというAMDの姿勢だ。
実際、12月のAnalyst Dayでは、アナリストからの質問も、Barcelonaの遅れとAMDの競争力への疑問や財務などに集中していた。針のむしろ状態で、AMDとしては短期的に市場を掴み売り上げを上げるためのプランに説明を集中せざるをえなかった。つまり、AMDを取り巻く環境が「長期的な技術的なことはいいから、今の状況をどうするのか説明しろ」といった雰囲気であったために、AMDもそれに応えたわけだ。
●立ち上げを確実にするための慎重な技術選択
AMDは、これまでコードネームFUSIONで呼んできた、ヘテロジニアス(Heterogeneous:異種混合)型CPUプランを、夏頃から「Accelerated Processing Unit(APU)」とカテゴライズしている。また、12月にはAPU部門担当の副社長として、元MIPSのCTOだったMike Uhler氏を迎え入れた。AMDは、過去数年間、CPU業界の技術畑の人材を引き寄せ続けているが、ここに、また新たな人物が加わった。
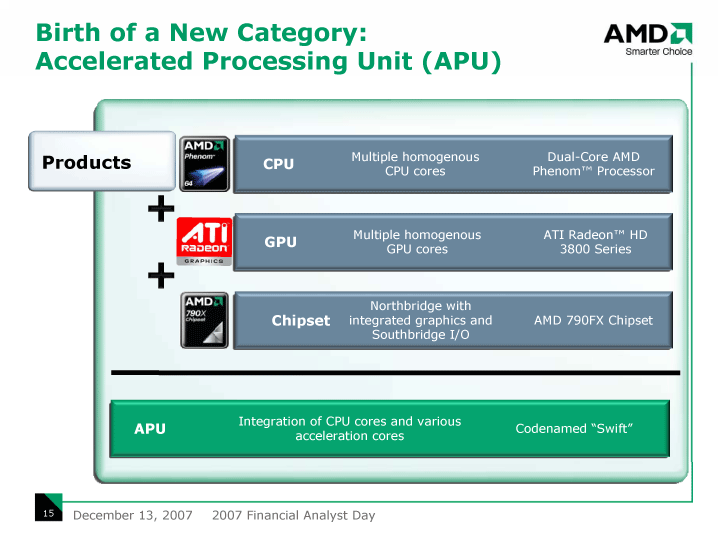 |
| 新カテゴリ「APU」の解説 |
APUという名称は、FUSIONと比べると、よりAMDの目指すプロセッサ像を正確に表している。AMDのビジョンでは、最終的にCPUがデコードする命令ストリームの中で、SSE5命令の一部などがGPUコア側のブロックで実行されるようになる。つまり、CPUの中で特定処理をアクセラレートするユニットとしてGPUコアを融け込ませようという発想だ。x86 CPUにx87 コプロセッサが融合して、結果として浮動小数点演算がアクセラレートされたのと同じイメージだ。そう考えると、APUの方が、より実態に即した表現と言えるかもしれない。
もっとも、最初のAPUであるSwiftは、そうしたビジョンからは遠い。Swiftは複数のCPUコア、フルDirectX GPUコアとUVDユニット、DDR3メモリインターフェイス、キャッシュメモリ、PCI Expressインターフェイスなどで構成される。CPUコアはAMDの「STARS」シリーズをベースにした第3世代STARSコア、GPUコアは既存のハイエンドディスクリートGPUをベースにする、また、ノースブリッジ部分はAMDの来年(2008年)のモバイルCPU「Griffin(グリフィン)」ベースとする。どちらかと言えば、SOC(System on a Chip)型のユニットの統合であり、FUSION改めAPUのビジョンにはまだ道のりがある。
既存の製品、またはSwift登場時点で既存となる製品のユニットを再利用することで「生産立ち上げをより確実にする技術チョイス」と、Analyst DayでMario Rivas氏(Executive Vice President, Computing Products Group)は説明した。APU用に新しいユニットを開発していると、間に合わない可能性があるから、すでに実証済みのコアを再利用する。これがSwiftのコンセプトだ。
●影を落とすIntelのGPU統合CPU Havendale/Auburndale
AMDのこの決定の理由は簡単だ。それは、Intelが2009年の中盤に、GPU統合型のNehalem(ネハーレン)ファミリ「Havendale(ヘイブンデール)」「Auburndale(オーバーンデール)」を投入するからだ。Havendale/Auburndaleに対抗して2009年後半までにAPUを投入するためには、確実なプランを選ぶしかないというわけだ。ここでIntelに大きくリードされると、クアッドコアでリードされた今回の再現になってしまう。
IntelのHavendale/Auburndaleは、CPUダイ(半導体本体)とGMCHダイの2個のダイで構成されるMCM(Multi-Chip Module)だ。AMDのSwiftについては、まだMCMなのか1個のダイに統合されるのか、わかっていない。以前は、AMDはFUSIONでは統合化によって消費電力を減らすことができると明言しており、MCMではなくワンシリコンに統合するソリューションで計画していた。だが、既存技術で固めた現在のSwiftのプランではMCMであってもおかしくはない。
ただし、AMDは依然としてSwiftを、消費電力がクリティカルなモバイルから投入としており、その点を見るとワンシリコンの可能性がある。また、AMDはBarcelona世代から、CPUの各ブロックのモジュラー化を強力に指向しており、インターフェイスのクリーン化や明文化を進めて来た。そのため、Intelと比べると、SOC(System on a Chip)型の統合化は容易なはずだ。逆を言えば、ワンシリコンに統合しないと、AMDが、せっかく進めてきたモジュラー化の意味が薄れてしまう。モジュラー化にはオーバヘッドがつきもので、AMDは犠牲を払っている。そのため、IntelよりAMDの方が、ワンシリコン化へのモチベーションが強い。
もっとも、逆の証拠もある。AMDが最近、IntelのMCMソリューションへの攻撃を控え始めていることだ。以前は、同社は、IntelのMCM対AMDのネイティブソリューションを対立軸に持ってきていた。しかし、Analyst Dayでもその部分は強調されなかった。これは、AMD自身がMCMを投入する前兆だと言われている。ただし、現在わかっている限りでは、MCMはサーバーサイドだ。
●AMDの路線変更に影を落とす旧ATI人材の流出
AMDがSwiftに“既存グラフィックス”を使うと発表したことは、SwiftのGPUコアがVLIW(Very Long Instruction Word)型のR6xx系命令セットになることを示唆している。しかし、R6xxのVLIW型命令セットは、AMDのCPU命令セット拡張の方向性とは明らかに一致しない。また、現状のR6xxアーキテクチャでの、ベクタ長が非常に大きく、長レイテンシのセットアップが必要となる。AMDのPhil Hester(フィル・へスター)氏(Senior Vice President & Chief Technology Officer(CTO))は、9月にFUSIONの統合はステップ毎に進み、命令レベルでの統合やベクタ長の細粒化を進めてゆくと説明していた。そうしたステップは、全てSwiftの次の世代からスタートすることになりそうだ。
AMDがSwiftに既存GPUアーキテクチャを使うことを決定した背景には、人材流出があるかもしれない。AMDとATIが合併して以来、旧ATIキャンプからは、トップのDavid(Dave) E. Orton(デイブ・オートン)氏(Executive Vice President, Visual and Media Businesses, AMD)を始め、何人かの有力な人材が抜けた。GPU開発の社内リーダーシップが弱まっている可能性もある。
また、AMDとの合併によって、GPUアーキテクチャも、CPUとの統合を見据えた方向に修正する必要が出てきている。AMDはAnalyst Dayで示したロードマップで、次期ディスクリートGPUアーキテクチャ「R700」が2009年になることも示した。もともとの計画ではR700は2008年であり、スケジュールは後退している。
GPUの開発サイクルは現在2~4年と、以前の1年半(18カ月)より長くなっている。そして、AMDとATIが合併した時点では、すでにR700はATI社内で走っていた。しかし、R700が2009年にスリップすると、開発サイクル的にはAMD合併後から上流設計をスタートしても間に合うことになる。今回の仕切り直しは、R700のアーキテクチャ自体がAPU化を前提に軌道修正されたことを意味するかもしれない。だとしたら、R700では、VLIWからSIMDへ、粒度の大きなベクタから粒度の小さなベクタへ、シングルコンテキストからマルチコンテキストへ、といった方向へ進む可能性が高い。
 |
 |
| 段階的に融合して行くCPUコアとGPUコア | 融合の図解 |
 |
| エンスージアスト向けプラットフォームのロードマップ |
●Stanford Graphics Labからの人材流入
ちなみに、AMDはGPUアーキテクチャ開発に、有力な人材をスカウトしたようだ。スタンフォード大学のStanford Graphics Labの研究者として知られているMike Houston氏で、AMDに加わると見られている。
Houston氏は、スタンフォード大学でのストリームプログラミング言語「BrookGPU」や、分散コンピューティング「Folding@Home」でのGPUクライアントなどのプロジェクトをリードした。GPUの汎用コンピューティング活用「GPGPU(General Purpose GPU)」の専門家と見られている。将来のAPUの命令セットアーキテクチャを、GPU側から考えるには、うってつけの人材かもしれない。
もっとも、Houston氏の研究範囲はGPGPUに留まっていない。例えば、Houston氏がスタンフォード大学で進めている「Sequoia(セコイア)」プロジェクトは、プロセッサのメモリ階層をプログラミング言語の中でモデル化するためのプロジェクトだ。Sequoiaでは、GPUはもちろん、Cell B.E.のような特殊なメモリ階層を持つプロセッサのプログラミングを画期的に容易にできる。ストリーム型の処理の場合、従来のCPUのキャッシュは向かないが、局在性を活かすためにメモリの階層化は必要となる。Houston氏のSequoiaは、そうしたプロセッサの最大の問題である、データ移動のプログラミングの労力を取り去ろうというものだ。
Houston氏は今年(2007年)4月のAMDのGPUカンファレンス「Tech Day」の際に「Sequoiaの目的は、コンパイラによって、メモリ階層間のデータ移動を自動化することだ。言語の中で適切なモデル化がなされれば、コンパイラ自体の開発はそれほど難しくないと考えている」と語っていた。もちろん、言語から拡張しようというSequoiaがそのままAMDの短期プロジェクトとなるとは思えない。しかし、AMDがこうした背景の人物を獲得するとしたら、それは、AMDがより深くヘテロジニアス型の融合を考えている証拠だと考えられる。
ちなみに、Stanford Graphics Labからは、同じくBrookGPUを手がけたことで有名なIan Buck氏が、NVIDIAにCUDAの技術リーダ(NVIDIA CUDA Software Manager)として引っ張られている。GPUがプログラマブル化するにつれて、その分野での研究を重ねてきたStanford Graphics Labが人材供給源の色彩を強めている。
 |
| 「Sequoia」プロジェクト |
□関連記事
【10月11日】【海外】Intel NehalemとAMD FUSION両社のCPU+GPU統合の違い
http://pc.watch.impress.co.jp/docs/2007/1011/kaigai392.htm
【6月28日】【海外】AMDの製品戦略全体の再構築となるFUSION
http://pc.watch.impress.co.jp/docs/2007/0628/kaigai368.htm
【2月27日】【海外】CPUとGPUの統合プロセッサのチャレンジ
http://pc.watch.impress.co.jp/docs/2007/0227/kaigai340.htm
(2007年12月25日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.