
|
IDFレポート
【カンファレンスレポート】
CPUロードマップとマイクロアーキテクチャーの詳細を公開
 |
会期:3月7日~9日(現地時間)
会場:米San Francisco
Moscone Center West
IDFの2日目からは、基調講演がなく、一般参加者はカンファレンスやIntelのフェローが質問に答える「Shop Talk」、黒板を前にエンジニアが説明を行なう「Chork Talk」などが開催された。また、カンファレンスでは、マイクロアーキテクチャーなどの詳細公開され、場合によっては担当エンジニアが直接解説する。
●2006~2007年のロードマップ
初日の基調講演でも、来年以降のプロセッサなどの話が出たが、こうしたプロセッサのロードマップをまとめた解説がプレス向けに行なわれた。
Intelは、2006年内にデスクトップ、モバイル、サーバーのすべての領域(ただしメインストリームとプレミア領域のみ)で、出荷の70%(サーバーは85%)以上をマルチコアにすることを計画している。また、2007年には、その比率を90%にまで上げる予定だ。バリュークラスとなるCeleronは当面デュアル化はしないが、それ以外では、急速にデュアル化が進むことになる。
2006~2007年のロードマップは、下記のようなものとなる。サーバーなどはクワッドコアへの移行が始まるが、一般向けデスクトップでも、Extreme Editionとして2007年中にクワッドコアとなるKentsfiledが導入される予定。なお、クワッドコアの本格展開は、45nmプロセスや新プラットフォームを待ってからになる。
 |
| Intelは2006年、モバイルやデスクトップ向けのプロセッサの7割がマルチコア(デュアルコア)になると予想。サーバーは、85%がマルチコアとなる。2007年には、デスクトップやモバイルの9割、サーバーは完全にマルチプロセッサに切り替わる予定 |
 |
| 「Intel Core Microarchitecture」を採用するプロセッサとプラットフォームのロードマップ。今回、MPサーバ(2つを越えるプロセッサを搭載するサーバ)用として2007年にクワッドコアのTigertonとそれを利用するCanelandプラットフォームが登場予定。また、 DP(2つまでのプロセッサパッケージを搭載可能なサーバ)は、Woodcrestのあと2007年にClovertown(クワッドコア)が、UPサーバ(ユニプロセッサ。1つのCPUパッケージのみ搭載可能なサーバ)は、Conroeのあとkentsfiledが登場。それぞれ、既存のプラットフォームを利用し、すべてがクワッドコアになる。 なお、図からは抜けているが、2007年には、Meromを使うSanta Rosaプラットフォームが登場予定 |
●セッションでIntel Core Architectureが細部まで公開される
IDFで新しいマイクロアーキテクチャが発表されると、ある程度情報を公開するセッションも開催される。ただ、今回は、以前のNetBurstやBaniasなどに比べると、より詳しい情報が公開された。
現在はIntel副社長で、以前はイスラエルの開発チームを率いていたMooly Eden氏は、プレス向けのラウンドテーブルで、「キモノの前をはだける」ように情報を公開すると発言しており、実際に、詳細な情報を得ることができた。たとえば、セッションでは、Merom/Conroeのブロックダイアグラムが公開されたが、Baniasは、こうしたブロック図が公開されたとことはなかった。
結論からいうと、すでに後藤氏の記事で推測されていたことが裏付けられた形である。一番のポイントとなるMacro-Fusionは、比較命令(CompまたはTest)と条件ジャンプ命令の組み合わせにのみ適用され、これを直接実行できるALUが1つ用意されている。
 |
| 公開されたIntel Core Microarchitectureのブロックダイアグラム。実行ユニットは、3つのALUとLoad、Storeのユニットが各1つからなる。3つのALUのうち、1つだけがブランチの処理が可能で、ここでのみMacro-Fusionされた命令が実行できる。また、残りの2つのALUは、128bitの浮動小数点の加算(FAdd)と乗算(FMul)をそれぞれ実行できるようになっている |
●電力効率のポイントは、周波数とIPC
今回のIntel Core Microarchitectreの最大の特徴は電力効率である。つまり、小さな消費電力でより高い性能を出すことが目標の1つだった。その設計のポイントは、周波数とIPC(Instruction Per Cycle。1クロックあたりの命令実行数)だったという。
まず、CPUの性能は、周波数とIPCの積で表される。周波数は1秒間のくり返し数を意味するので、その1回分に対して命令を実行できる数を表すIPCを乗ずることで、1秒間に実行される命令数が得られる。
また、電力消費量は、電圧の2乗と周波数の積に、プロセッサ自体が持つ静電容量を乗じたものに比例する。このとき、周波数は、両方に影響するパラメータで、これを低くすると、消費電力は下がるが、性能も下がってしまう。また、IPCを高めようとすると、回路が複雑になるため、回路が持つ静電容量が大きくなり、結果的に消費電力が大きくなってしまう。
つまり、適当な周波数とIPCの組合せを見つけることで電力効率を最大にするようなプロセッサを作ることが可能になるわけだ。ここでIntelは、これまで右肩上がりだったクロック周波数を下げる方向に向かう。その代わり、IPCは従来のものよりも向上させ同時4命令以上が可能になった。また、Macro-Fusionを導入することで、最大15%程度、命令数をへらすことができ、同クロックで比較すれば、従来のマイクロアーキテクチャよりもより高速になっている。逆に、同等の性能を確保するなら、クロック周波数を下げることができる。
 |
 |
| プロセッサの性能は、クロック周波数とIPC(1クロック当たりの実行可能命令数)で決まる。また、消費電力は、電圧の2乗(V*V)と周波数(Frequency)を乗算したものに、回路などから決まるC(動作している回路が持つ静電容量)を乗じたもので決まる。ここで、周波数は両者に影響し、また、IPCを高めることは、信号の経路(回路)を複雑にするため、Cを大きくしてしまう。つまり、電力消費と性能のバランスは、IPCをいくつまで高めるかと、動作周波数で決まってくる |
●細かい動作も解説が行なわれる
このIntel Core Microarchitectureの解説は、プレス向けのセッションとしても行なわれたが「highly Technical」と注意書きが行なわれるほど。説明中に左右のコアをわかるように片側を逆向きにした図を見せたとき、講師は「こっちのコアはBig Endianだ」という冗談を言ったのだが、笑う人も少なかった。
これでも、プレス向けに一部が省略されていたようで、エンジニア向けのセッションはまだ詳しい情報があったようだ。しかも、このセッションは、満員で遅れて入ることもできず、最終日にもう1回行なわれるほどの人気セッションであった。
以下、説明に使われたスライドとキャプションで各技術を解説する。
□Intel Wide Dynamic Execution - Macro-Fusion
 |
 |
| Macro-Fusionとは、プリフェッチし、プリデコードした5つの命令の中から比較命令(CompまたはTest命令)と条件ジャンプ命令を組み合わせて1つのマクロ命令として、デコーダ経由でパイプラインに送り込む。もし、Macro-Fusionが行なわれなかったときには、5つ目の命令は、次のサイクルでパイプラインに送り込まれる |
□Intel Advanced Digital Media Boost
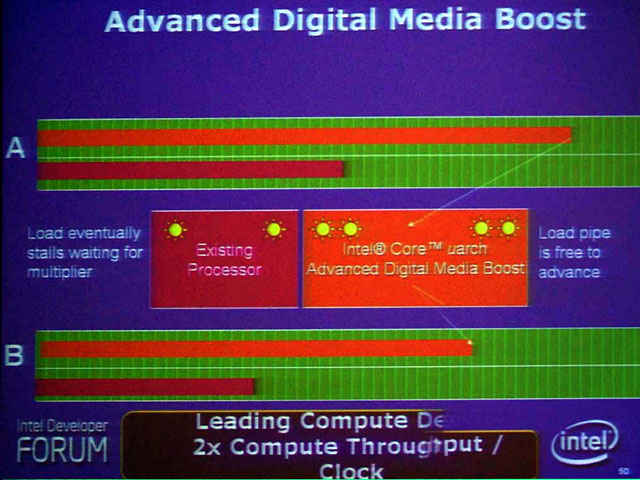 |
| Intel Core Microarchtectureでは、128bitの浮動小数点演算(加算または乗算)が1クロックで可能になった。現在のYona(Core Duo)では、128bitの浮動小数点演算は、2クロック必要であるため、結果的に性能が倍になる |
□Intel Smart Memory Access - Memory Disambiguation
 |
| メモリ依存関係の解決(Memory Disambiguation)がない場合、命令は順番通りに実行しなければならない。これは、(1)と(2)のように同じアドレスに対して、ストアとロードが行なわれる可能性があるからである。しかし、(4)のように依存関係のないロード命令も順番通りに実行されてしまう |
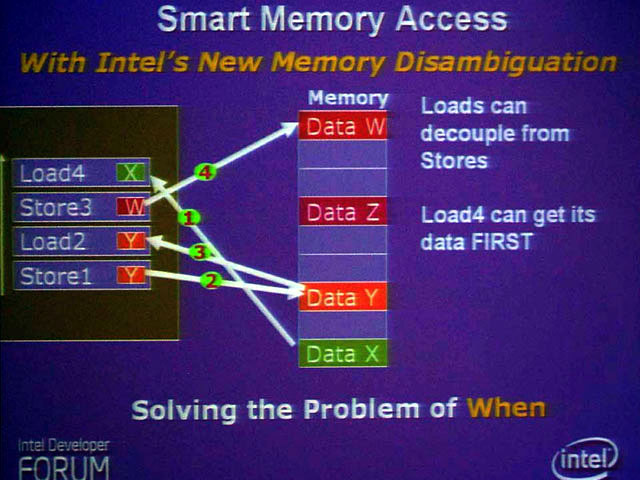 |
| メモリ依存関係の解決が行なわれると、後ろにあっても、依存関係のないロード命令を先に実行させることができる |
□Intel Smart Memory Access - Advanced Pre-fetch
 |
| プリフェッチ機構(Prefetcher)は、プログラムのメモリアクセスパターンを検出。この場合、メモリは1つおきにアクセスされている |
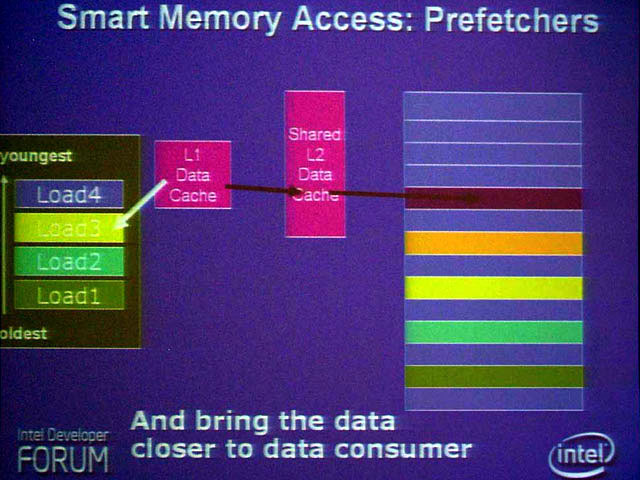 |
| このため、プリフェッチ機構は、先回りして、1つ先のデータを読み出し、L1、L2へと格納しておく。その後、ロード命令が実行されると、L1に格納されたデータが使えるため、メインメモリに比べると高速にロード命令が実行できる |
 |
| プリフェッチ機構は、各コアに3つ(命令用1つ、データ用2つ)あり、L2キャッシュには2つある。L2キャッシュのプリフェッチ機構は、2つのコアで共有されている。2つのコアを区別するために右側のコア部分はわざと逆向きになっている |
□Intel Advanced Smart Cache
 |
| 独立したL2キャッシュの場合(図右側)、既にキャッシュされているアドレスを他方のコアが要求したとき、FSBを介してその値がコピーされる。CPUの内部速度に比べるとFSBの動作は遅いので、これには時間がかかってしまう。L2キャッシュが共有の場合(図の左側)は、FSBを介することなく、L2キャッシュ内のデータをどちらのコアに渡すこともできる |
□IDF Spring 2006のホームページ(英文)
http://www.intel.com/idf/us/spring2006/
□IDF Spring 2006レポートリンク集
http://pc.watch.impress.co.jp/docs/2006/link/idfs.htm
(2006年3月10日)
[Reported by 塩田紳二]
【PC Watchホームページ】
PC Watch編集部 [email protected] お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2006 Impress Watch Corporation, an Impress Group company. All rights reserved.