 |
■大原雄介のEmbedded Processor Forum 2004レポート■ARMがDSP「OptimoDE」を提供 |
前回に引き続きARMの話題を取り上げたい。まず、同社のMike Muller氏が行なった初日の基調講演からすこしピックアップしてご紹介し、後半では「OptimoDE」についてとりあげよう。
●大量のトランジスタを使い切る方法
 |
| ARM社のCTOを勤めるMike Muller氏 |
半導体製造のトレンドが移り変わるのと同じように、IPも流行り廃りで採用されたり敬遠されたりするのかというと、決してそんな事はないと力説する。その最大の理由は、コストだという。一切IPなどを使わずに開発を行なった場合、設計コストは天文学的な金額に跳ね上がる傾向を見せており、これをさまざまな設計技法でカバーすることでコスト上昇を防いでいるのだという。その設計技法のうちの75%はIPによって得られているわけで、これだけでもIPはすでに欠かせない要因になっている、とした。
加えて、今後のプロセスの微細化に伴い、より多くのトランジスタを利用できるようになるが、これをIP無しで使い切るのは非常に難しいという問題がある。
実際のところIPを使う場合、SoC(System on Chip:1つのダイ上に複数の機能ブロックを搭載することで、機能ブロック単体ではなく「システム」を提供するもの。IPはこの場合、個別の機能ブロックとして提供されるのが普通)を使う形になるのが一般的だが、そのSoCの開発コストがどんどん上がっているという。SoCのコストを考える場合
・新命令の定義
・CPUのインプリメント
・プラットフォームの開発
・サポートコスト
の4つに分けて考えねばならないが、このうち新命令の定義には平均300万ドルかかるという。
一方、CPUのインプリメントコストは増大の一途をたどっており、またSoCプラットフォームの開発も決して安くはない。しかも、当然ながら開発後のサポートやメンテナンス、ついでにマーケティング費用を考えると、大雑把ながら大体毎年2,000万ドルが必要とされる。
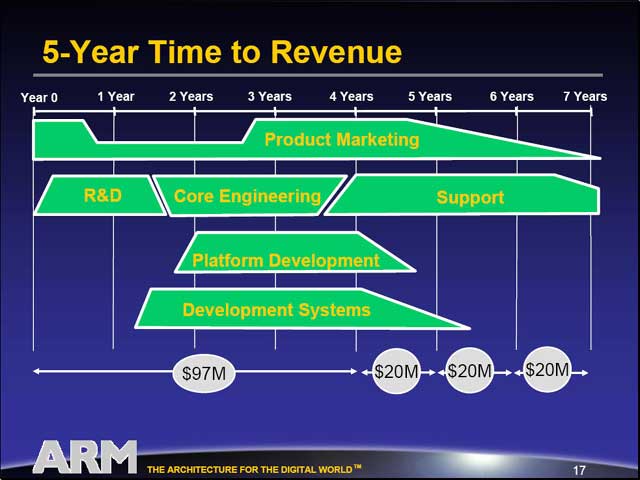
この費用、当然ながらまとめてかかるわけではない。開発がスタートしてから実際に収入を生むまでに平均5年を要している、というのが難しい点だ。
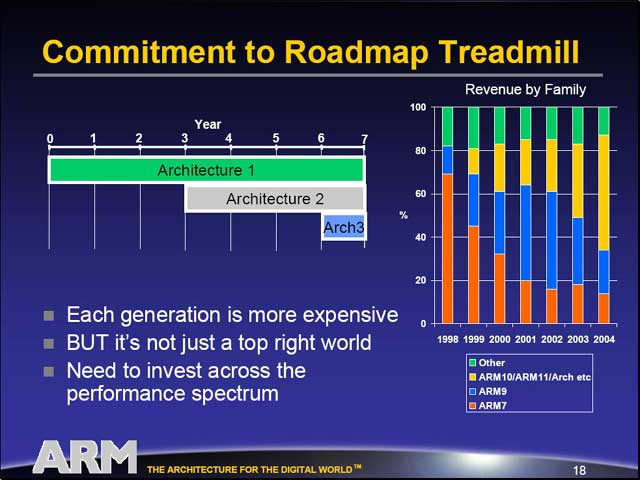
実際ARMの場合、やっと今年はARM10/11による収入が大きな比率になりつつあるが、昨年まではARM9が大きな割合を占めていたし、いまだにARM7の比率も馬鹿にできないほど大きいというあたりが、(特にEmbeddedマーケットにおける)CPUアーキテクチャの難しさを物語っている。
もちろん、はじめからこうした5年周期でのアーキテクチャの投入を前提に投資を行なってゆけばいいわけだが、年々開発にかかるコストは上昇してゆくことや、5年という期間は大抵のCEOの在任期間よりも長い(!)というあたりが、こうした長期的投資をさらに難しくしている。それゆえ、標準的なプラットフォームが重要である、というわけだ。
また、今後の開発の方向性に関しては、Makimoto's Waveを例に引きながら、しばらくは標準プラットフォームの上で独自のカスタマイズを行ってゆく方向になるという形で方向性を示した。ではその標準プラットフォームとはというと、RISCコア/DSP/Dedicated Logicなどをベースにさまざまなプラットフォームが考えられ、均一なものにはならないだろう、と言う。この部分はOptimoDEに繋がる訳だが、とりあえずそれは後で説明することにしたい。
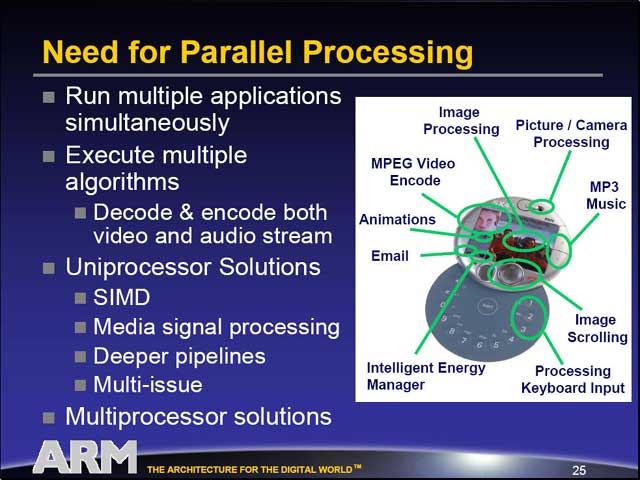
さて、ここから話はパラレルプロセッサに移ってゆく。昨今の組み込み系プロセッサの場合、同時に多数のジョブが要求される事が多くなっている。こうしたケースでは、一つの高速なSingle-Threadedプロセッサで全処理をタスクスイッチしながら行なうよりは、Multi-Threadコアのプロセッサ、あるいはマルチプロセッサで処理をしたほうが、結果として設計が容易であり、かつ処理性能も要求を満たしやすいという話は昨年のEPFでも出ていた事である。
もちろん十分に最適化すれば、どちらのソリューションでも概ねコスト/パフォーマンスは変わらないわけで、後はどちらのソリューションを取るか、という話になる。ただ、パフォーマンスの向上が難しい(PC向けと異なり、Embedded向けではPentium 4のような設計は許容されない)事を考えると、ソフトウェアの面で多少難易度は高いものの、マルチプロセッサ/Multi-Threadの構造の方が柔軟性が高いという事はいえるわけだ。
また、先ほどの話に戻るがプロセスルールの縮小に伴い、利用できるトランジスタの数は増えつつあるが、問題はそのトランジスタをどう使うか、という話である。
「無駄に使わずに、その分ダイを縮小すればいいのでは」という話は勿論あるが、現実問題としてパッド(パッケージ側と配線をつなぐ部分)の数を減らせない以上、パッドに必要な分からコアの最小面積が決まってきてしまうため、結局コアの面積自体は変わらない。であれば、シリコンを無駄にするより、そこにトランジスタを作って付加価値をつけたいと思うのは当然の発想である。
実際、今のペースでプロセスが縮小してゆくと、2007年には10億トランジスタがASICで使えるようになってしまう。ではどう使うかといえば、やはりプロセッサの数を増やすのが一番早い。現にAgereはARM9を8つ搭載したコアを試作している。逆に、マルチプロセッサにしないで使い切ろうとすると、凄まじいものが出来上がるというわけだ。
 |
 |
 |
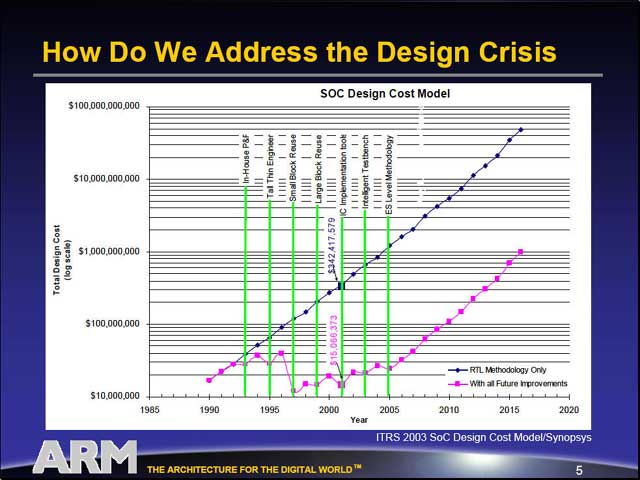
| 例えば配線方式について、かつては90°と45°の両方が用いられていたが、自動化ツールが45°に対応しきれないということで、'90年代は90°のものだけになった。ところがトランジスタの数が多くなり、配線がより複雑化する中で、従来の90°配線だけだと配線層が多くなりすぎ、遅延の問題も出てくるということで、2年ほど前から斜め配線(45°)が再び見直されつつあるといった具合だ。こうした動きはさまざまな部分であり、それが“Back to the beginning”という言葉に集約されるわけだ | RTL(Resistor Transistor Logic)とは、回路をNANDの組み合わせ論理回路で表現するという、一番原始的な回路の記述方法のこと。確かにこれ「だけ」で全てを設計していたら、回路規模に比例して手間が増えるわけで、デザインコストが指数級数的に増えても不思議ではない。ところが実際には様々なデザインツールを投入することで、そのコストを引き下げているという話。2005年以降は単調増加になっているが、これはまだこの時点でどんなツールを投入するか見えていないだけであって、何もしないというわけではない | 左図で示されたさまざまなツールの詳細。黄色で示している部分がIPに関係する部分、水色の部分は今後投入が決まっている(が、まだ現実には投入されていない)技術 |
 |
 |
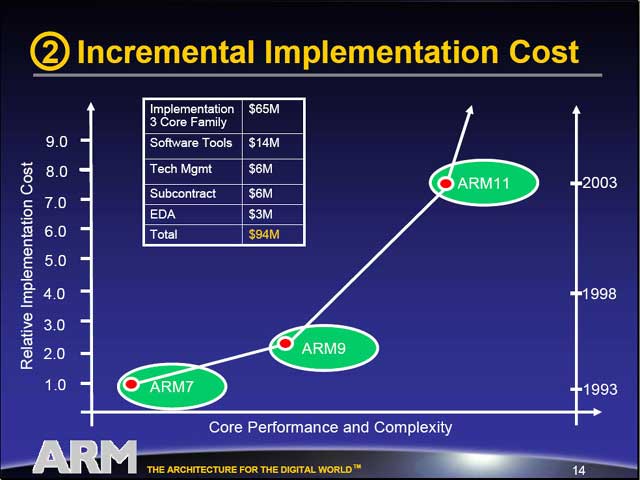 |
| ARM9/10/11の特徴を比較したもの。注目すべきはDesign Costの欄。myというのはMan-Yearで、例えばARM9なら20人年(20人のエンジニアが1年これにかかりっきり)、ARM11では78人年に達している。エンジニア1人年のコストを例えば2000万としても、人件費だけで馬鹿にならないのがおわかりいただけよう。(もちろん開発費>人件費である) | CPUのコストを算出するために必要な4つの要素。特に4番目は忘れがちになる | ARMにおける各CPUの開発コスト。ARM7の開発コストを1.0とした場合、ARM11は7倍以上に達している。3つのコアの開発の内訳が表に示されているが、合計9,400万ドルだから、単純に換算するとARM9が900万ドル、ARM10で1,800万ドル、ARM11で6,700万ドルというところか? |
 |
 |
 |
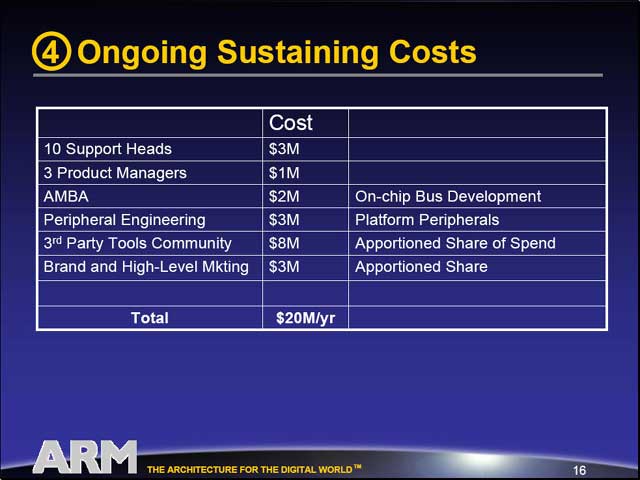
| どんなSoCも単体では動作しないので、動作させるためのプラットフォームの開発は当然必要になる。また、SoCの場合は内部でデバイス同士を接続するInternal Busが必要になる。加えて、デバイスに関する開発費用も必要というわけだ | メンテナンスに要する費用。3人のプロダクトマネージャと10人のサポート要員、AMBAのコスト、周辺機器やサードパーティツールなどで合計20億/年というのは、さすがに大きめの数字ではあるが、ARMの規模を考えれば妥当な数字かもしれない | とにかく最初の4年で約1億ドルという投資が必要なわけで、もう小さなベンダーでは開発すらままならない感じだ |
 |
 |
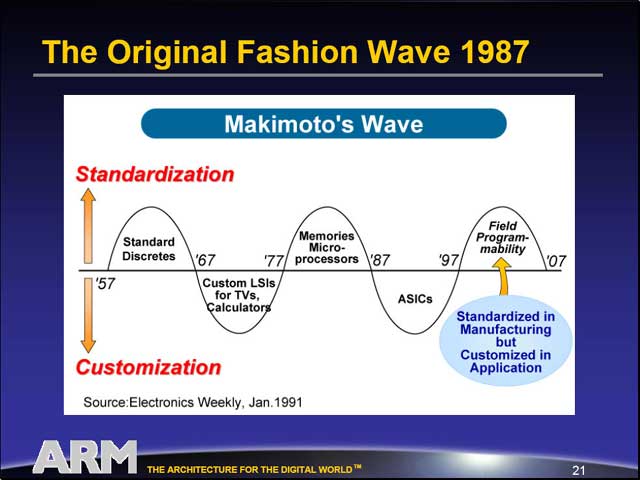 |
| 2000年あたりまではARM7が、2001年から2002年まではARM9がそれぞれ売上の重要な柱になっており、ARM10以降が貢献するのは2003年以降、本格的には今年からということになる。発表から普及までこれだけのタイムラグがあるのも、Embeddedならではといえる | 「CTOはちょっとマシ」(在任期間がCEOより長い)というあたりでさすがに会場からも笑いが | ここでMakimoto's Waveが出てきたのにはちょっとびっくり。これは元々ソニー顧問の牧本次生氏が提唱したもの。Makimoto's Waveの詳細に関してはこちらを参照 |
 |
 |
 |
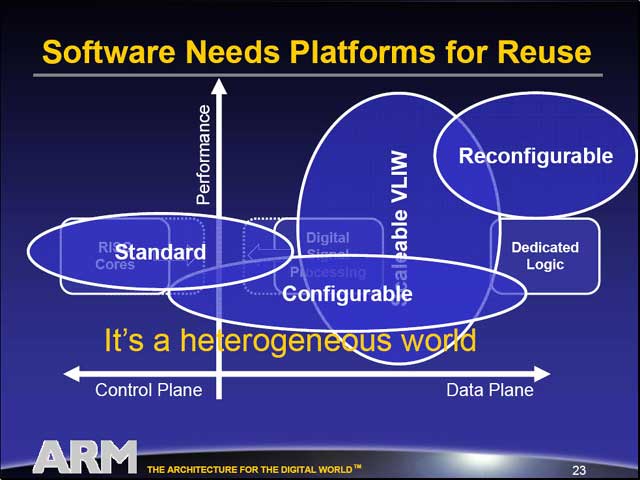
| 今はRISCコアと一部のDSPが標準コア、DSPがConfigurable(静的に変更可能)コアとVLIWの領域にあり、一部がReconfigurable(動的に変更可能)として提供されている | まぁこれらを本当に「同時に」行なう事はありえないわけだが、考え方としてはこれらをスムーズに使うためにはMulti-Thread環境が必要だし、それであればMulti-Threadプロセッサもしくはマルチプロセッサが有効なわけだ | マルチプロセッサ/マルチスレッドの構造の場合、どうやって処理をうまく分割するか、がキーになるわけで、ここがソフトウェアの面での難しさとなる |
 |
 |
| これはAgereが昨年5月に発表したSoC。単に8つ突っ込めば出来上がりというわけではなく、色々と課題は多いわけで、ARMがARM MPCoreを発表したのもこのあたりを容易にするためだ | こちらはziptronixが自社の3D配線テクノロジを使って作ったサンプル。ARM9ベースのASSP(Application Specific Standard Product)にReconfigurable Processor、フラッシュメモリとSDRAMまで統合したお化けチップである。ARM9/Reconfigurable Processorをまずダイ上に構築し、その上にさらにSDRAMを構築するという方法で、合計10Gトランジスタになっている。これだけのものを集約できるほどトランジスタがあまるわけだ |
●ARMお墨付きのDSP「OptimoDE」
 |
| ARM BelgiumでProduct Development Manager, Data Engine Divisionの職にあるKoen Van Nieuwenhove氏。'97年~2001年までは、ARMでVice President of engineering at Frontier Designのポジションにあったお方だ |
従来ARMが提供してきたのは、JAVA拡張やSIMD拡張があるとは言え、あくまでStandard RISC Coreの範囲に留まっていた。だからDSPが必要な場合、ARMコアに別のDSPコアを組み合わせたSoCを作る形になっていたわけだ。TIのOMAP、あるいはIntelのXscaleなどはこの典型例である。
OptimoDEはOptimal Data Engine technologyの略(いまいち略になってない気がするが)で、VLIWスタイルのDSP型プロセッサである。ConfigurableとScalable VLIW、それとDigital Signal Processingの3つが重なった部分に位置するものである。
そのOptimoDE、基本的にはAHB経由でCPUと接続される形を取る。つまり、純然たるSoCの1コンポーネントであって、CPUコア自体の拡張ではない。
内部的には、データエンジンの中間にAIKO(AMBA Integration Kit for OptimoDE)が挟まる形で入る構造になっている。物理的なエンジンは1つだが、途中のAIKOの部分でデータの流れの制御ができるため、見かけ上Data Engine 1と2に分けて考えられるあたりが面白い。
内部のアーキテクチャは、典型的なDSPのそれである。ただ、ここで特徴的なのは命令の幅を16~256bitの範囲で任意に決められること。また、VLIWというだけに、複数の命令を同時に実行できることになる。このために、複数のFunctional UnitやMemory、I/Oポートを準備しているわけで、(おそらく上限はあるのだろうが)任意の処理を自在に構成できることになる。処理自体は単純なパイプライン構成だが、DSP用途であればこれで十分だし、むしろプログラミングが容易になる分望ましいだろう。
ちなみに講演の中ではあまり細かい話は出なかったが、プレスリリースによれば、Data Engin Coreは最小で9,500ゲートで構築でき、また26,200ゲートで構築したOptimoDEのData Engine CoreはTSMCの0.13μmプロセスで0.0215mW/MHzを達成しているという。ちょっと古いデータだが、オリジナルのA|RTコアは45,6000ゲートに6.3KBのSRAMを組み合わせ、150MHz動作で全二重のturbo codecを実現できたというから、その威力はかなりのものだろう。
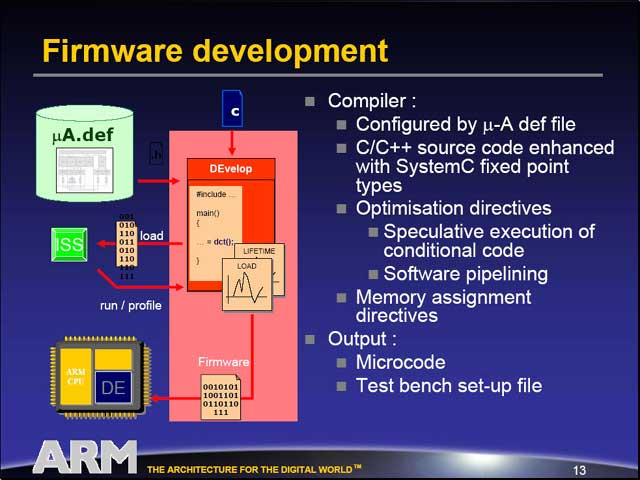
気になるのはConfigurableの部分だが、まずマイクロアーキテクチャに関してはDesignDEと呼ばれるツールで設計し、その結果をDEvelopと呼ばれるツールで検証できる。検証後のマイクロアーキテクチャのインプリメントは、BuildDEというツールを使ってVerilogに変換することが出来る。そうなると、後はそのままASICなりFPGAで回路を構築出来るわけだ。
またファームウェアに関しては、DesignDEの出力を再びDEvelopに入力して、ここからファームウェアのマイクロコードを生成できる。もちろん、こうしたツールは別にOptimoDEだけでなく、多くのDSPには必ず用意される類のものではあるが、クライアントが自分でDSPの設計をできるようになった、という事のインパクトは大きいだろう。
もちろん従来でも、Adelante Technologies BelgiumからA|RTを購入して自社で組み合わせることは可能だったのだが、その場合はクライアントがその組み合わせでの動作に責任を持つ必要があったわけだ。ところがOptimoDEを使えば、ある意味ではARMのお墨付きとなったわけで、「正しく設計すれば正しく動く」事が保証されているだけでも大きな違いだろう。
ちなみに32pointのFFT演算をインプリメントした場合のパラメータが示されたが、速度優先とサイズ優先、さらにメモリ圧縮をする/しないでかなりパラメータが変わることも示された。このあたりの柔軟性も、OptimoDEを使うクライアントには嬉しいところだろう。
気になるのは、今回はじめてARMはIPコアの提供に踏み切ったことだ。従来のARMのビジネスモデルでは、ARMはあくまでプロセッサコアやInterconnect(AHB/APB)の提供に留まっており、ビジネスパートナーがIPを提供する形で付加価値をつける、という仕組みだった。つまりARMとIPベンダーは補完関係にあったわけだが、これでARMはIPベンダーと(一部ではあるが)競合関係になってしまったことになる。なぜIPの提供に踏み込んだか、といえばSoCの立ち上がりがあまり芳しくないために、勢いをつける上でいくつか「標準」のIPコアを提供する必要があったのではないか、と考えられるが、これが協業ベンダーとの間の摩擦をもたらさないか、機会があれば関係者に聞いてみたいところだ。
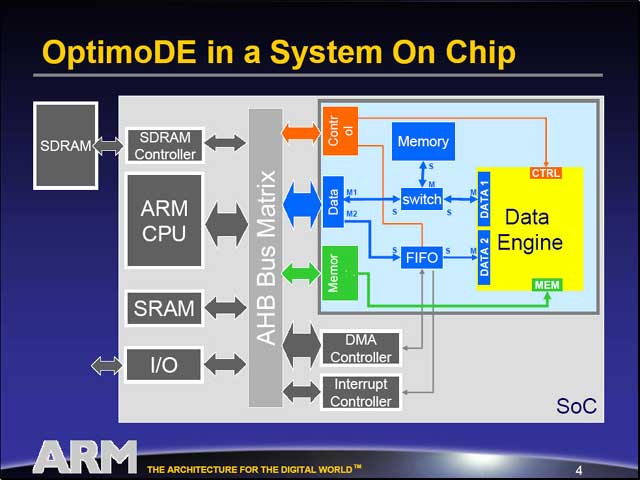 |
 |
 |
| OptimoDEの概略。あくまでSoCのコンポーネントとして動作する。AHBに接続されるから、端的に言えばCPUがARMで無くても動作するはずだ。もともとこのコアは、ベルギーのAdelante Technologies BelgiumをARMが買収した一環として手に入れたA|RT coprocessor technologyを元にしているからで、その意味では汎用性のあるコアである | 詳しい説明はなかったのだが、Data Engine 2にあたる部分でデータのセットアップ、Data Engine 1にあたる部分で処理を行なうという形を取るようだ。左図でのデータの流れもこれを裏付けている | Interconnect経由で、まずレジスタにプログラムとデータを格納し(ここまでがData Engine 2)、次いでプログラムにあわせて処理を行なう(これがData Engine 1の領域)形になるようだ。ここで途中にAIKOをはさむ事で、データの流れを自在に設定しやすい、という事らしい |
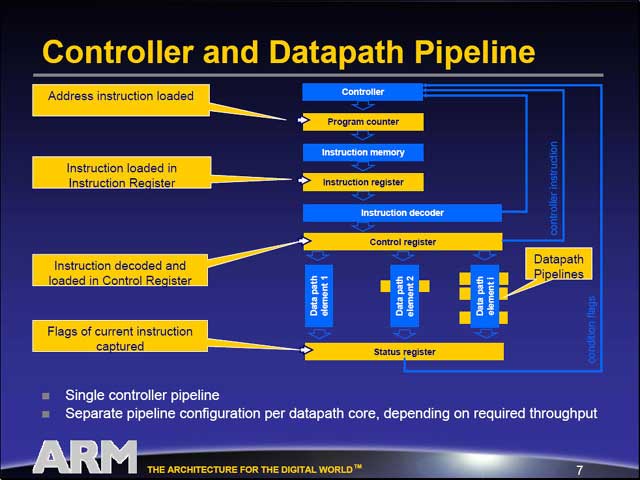 |
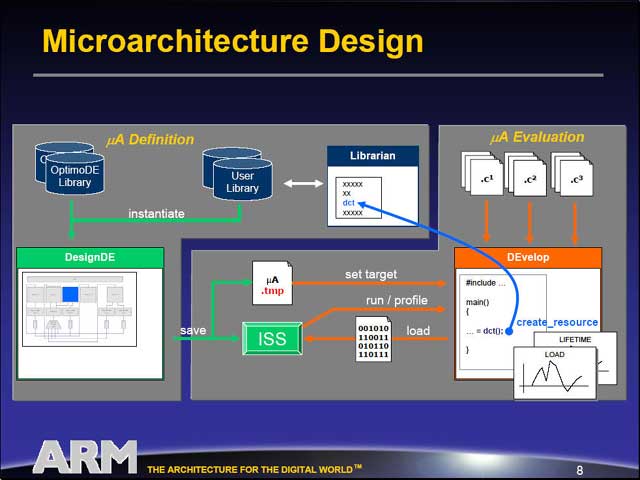 |
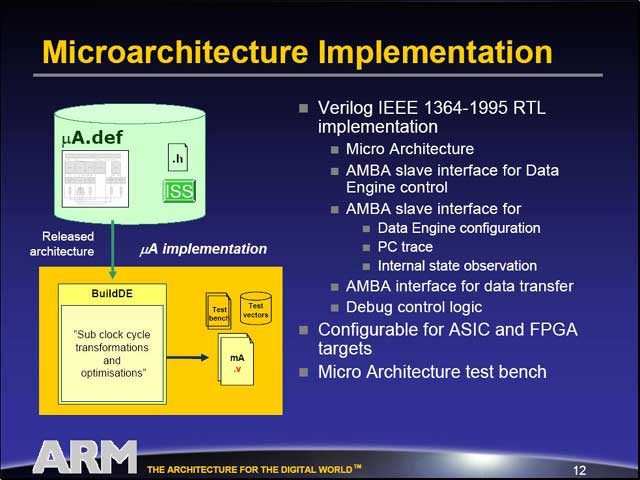 |
| もちろん、簡単な制御はあるが、基本的には単純なVLIW方式のシングルパイプエンジンである | アーキテクチャの設計は、OptimoDEの標準ライブラリの他、必要ならユーザーライブラリを組み合わせ、DesignDEで作成する。このレベルでは、抽象化の高いレベルの設計になる。その段階でDEvelopを使い、動作の検証も行なう | 設計が決まったら、BuildDEを使ってVerilogのソース(図の中の.vファイル)を作成する。ASICやFPGAは基本的にVerilogのソースから回路を生成できるほか、Verilogレベルでのテストベンチもあるので、ここで動作の精密な検証も可能だ。この時点で、アーキテクチャに関する作業は完了である |
 |
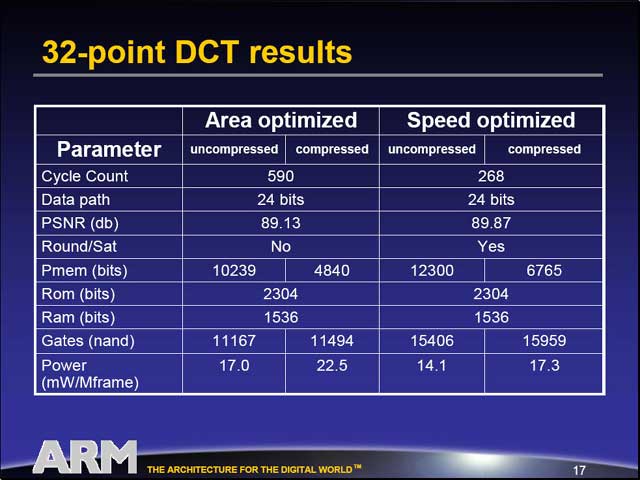 |
| アーキテクチャとは別に、起動時に読み込むファームウェアも作成しなければならないが、これは先にDesignDEで作ったμA.def(マイクロアーキテクチャの定義)を使い、あとはSystemC(“最近流行の”ハードウェアの動作を記述できるC言語)で記述する | Cycle Countが1回の処理を行なうのに必要なサイクル数、Pmem(bit)が動作に必要とするSRAMの容量、Gates(nand)がNANDゲートをいくつ必要とするかの数である |
【お詫びと訂正】記事初出時、OptimoDEの命令幅をデータ幅と誤って記述しておりました。また、データエンジンに関する説明を誤っておりました。お詫びして訂正させていただきます。
●補足:AMPとSMP
前回のレポートに対して「ARM MPCoreはAMP(Asymmetric Multi Processor)ではなくSMP(Symmetric Multi-Processor)ではないか」という疑問が寄せられたが、そもそもSMPかAMPかはハードウェアだけで決まるものではない。OSが全てのプロセッサに処理を均等に割り振れるからこそSMPになるのであって、例えば2プロセッサであってもOSがそれを認識しなければSMPとは呼べない。Dual Processor構成のPCにWindows 9xをインストールしても、それはSMPどころかDual Processorにならないのと同じことである。
もう少し具体的に説明しよう。例えば4プロセッサのARM MPCoreでブロードバンドルータを作るとしよう。Processor 1はWAN側の制御(PPPoEのハンドリング含む)を、Processor 2はLAN側の制御のみ(QoSの管理を含む)、Processor 3はNAPTの処理だけを、Processor 4はインターフェース(Apacheあたりを動かしてWebインターフェースを提供)するとする。これを、OSを使わずにがりがり書いた場合、SMPとはならない。例えばProcessor 1が止まるとWANアクセスが一切できなくなってしまうからだ。ところがここで4プロセッサをサポートするOS(VXWorksMPとかLinuxのMPカーネルとか)を入れて、プロセッサ資源を動的に配分できると、例えばProcessor 1が止まっても動作にそれほど大きな支障はない。Context Switchingによって他のCPUの資源をPPPoEの処理やWAN側制御にあてられるからだ。この状態がSMPである。
ちなみに電源管理に関してもこれは言える。例えばWANと接続しない場合、SMP構成でなくてもProcessor 1の電源を落としても別に支障はない。つまりARM MPCoreの構成はSMPとAMPのどちらにでも、OSの構成次第で対応できるようになっているということだ。
□Embedded Processor Forum 2004のホームページ(英文)
http://www.mdronline.com/epf04/index.html
□OptimoDE プレスリリース(英文)
http://www.jp.arm.com/pressroom/04/040518_2.html
□Makimoto's Wave 解説
http://www.sony.co.jp/Products/SC-HP/cx_pal/vol57/index.html
□関連記事
【2003年6月19日】大原雄介のEmbedded Processor Forum 2003レポート
ARMが3つの機能拡張を発表
http://pc.watch.impress.co.jp/docs/2003/0619/epf01.htm
(2004年5月24日)
[Reported by 大原雄介]
【PC Watchホームページ】
PC Watch編集部 [email protected] 個別にご回答することはいたしかねます。
Copyright (c) 2004 Impress Corporation All rights reserved.