 |


■後藤弘茂のWeekly海外ニュース■これが真のNetBurstアーキテクチャだ |
●デコーダのレイテンシをカバーするアーキテクチャ
 |
| Intel Patrick P. GelsingerCTO兼上級副社長 |
Pentium 4のNetBurstアーキテクチャの真の特徴は、高機能なMicrocode層で内部のマイクロアーキテクチャを隠蔽。それによって柔軟なアーキテクチャ拡張を実現するものだった。
前回のレポートで、IntelのPatrick P. Gelsinger(パット・P・ゲルシンガー)CTO兼上級副社長(CTO & Senior Vice President)が明かしたNetBurstの柔軟性の秘密を説明した。Gelsinger氏は「リッチなMicrocode層に加えて、ディープでフレキシブルなパイプラインなどが、機能拡張を容易にする」と言う。
こうした特徴から推定できるのは、NetBurstは、デコード、つまり、CPU内部命令(MicroOPs)生成までのオーバーヘッドが大きいこと。つまり、柔軟性のトレードオフとして、レイテンシが長いアーキテクチャになったと思われる。そこで、IntelはNetBurstをレイテンシトレランスなアーキテクチャにすることに集中した。その路線にあるのがHyper-Threadingの実装だ。
Hyper-Threadingのような「サイマルテニアスマルチスレッディング(Simultaneous Multithreading:SMT)」技術は、メモリレイテンシの隠蔽に効果がある。片方のスレッドがメモリアクセス待ちをしている間も、もう片方のスレッドを実行し続けることができるからだ。
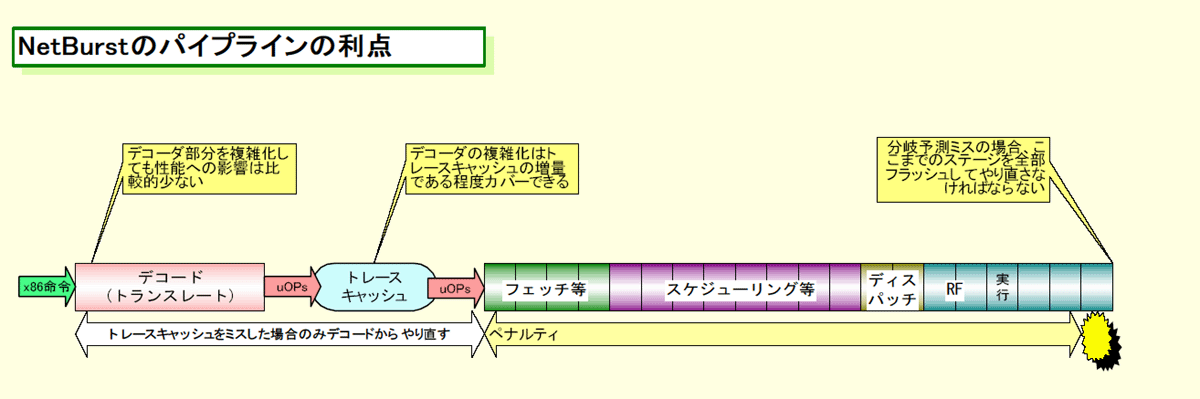
そして、NetBurstのパイプライン構造も、レイテンシの長いアーキテクチャに最適化されている。NetBurstパイプラインの最大のポイントは、デコーダをL1命令キャッシュであるトレースキャッシュ(Execution Trace Cache)の前に出したことだ。この改革によって、NetBurstではデコーダ部分のトランスレーションを複雑化することが容易になったと考えられる。
 |
| NetBurstのパイプラインの利点 PDF版はこちら |
従来のCPUのパイプラインの場合、デコーダの前に命令キャッシュがある。そのため、分岐予測ミスが発生した場合には、x86命令デコードからもう一度やり直さなければならなかった。その場合、デコーダ部分のMicrocodeをリッチに複雑にすると、パイプラインのペナルティが大きくなってしまう。だから、できるだけデコーダ部の負担を小さくしなければならなくなってしまう。実際、他のCPUアーキテクチャは、この部分が軽くなるように設計している。
ところが、NetBurstアーキテクチャの場合はデコーダの後にトレースキャッシュがある。そのため、トレースキャッシュにヒットし続ける限り、デコードをやり直す必要がない。逆を言えば、NetBurstではデコーダ部分を比較的自由に強化できるわけだ。デコーダをかなり複雑にしても、再デコードが必要になるのはトレースキャッシュミスする数%のケースだけなので、性能への影響は比較的小さい。
だから、NetBurstではデコーダ部分にx86命令の単純なトランスレートだけでなく、モード移行など様々な機能を実装することができる。Microcodeを複雑にして、内部命令(MicroOPs)へのトランスレートに時間がかかっても、許容されるというわけだ。そして、デコードに時間をかける分、内部の実行リソースを単純化できる。
●Transmetaとフィロソフィは似ている?
これは、Transmetaアーキテクチャと比較するとわかりやすいかもしれない。Transmetaでは「コードモーフィングソフトウェア(CMS:Code Morphing Software)」と呼ばれるソフトウェアレイヤに命令セットや機能を実装。CMSでx86命令をCPUのネイティブ命令(molecule-atom)にトランスレートして実行する。CPU自体は、比較的シンプルな「VLIW(Very Long Instruction Word:超長命令語)」型。一般的なx86 CPUとはかけ離れていが、CMSによって仮想的にx86 CPUに化ける仕組みになっている。
また、CMSがトランスレートしたネイティブ命令は、モーフィングキャッシュにストアされるので、キャッシュにヒットし続ける限りは再トランスレートの必要がない。だから、CMSに様々な機能を実装できる。
非常に乱暴な例えをすると、NetBurstでは、TransmetaのCMSの役割をデコーダが行ない、モーフィングキャッシュの役割をトレースキャッシュが行なうと考えることができるかもしれない。もちろんTransmetaはソフトウェアソリューションでCPUコアもVLIWなので、スーパースカラハードウェアのNetBurstとは全く違う。
しかし、フロントエンドに厚い仮想化層を持ってきて、CPU内部のマイクロアーキテクチャを覆うという考え方は共通している。デコーダ部分が、CPUコアのマイクロアーキテクチャを仮想化しているため、様々な機能を比較的容易に実装できるわけだ。
振り返ると、IntelはNetBurstを最初に導入した時から、デコーダ部分についてはひた隠しに隠していた。デコーダで何サイクルを消費するといった、ごく基本的な情報も提供されなかった。説明は、必ずトレースキャッシュ以降の部分で、デコーダは一切触れられなかった。それは、デコーダに最大の秘密が隠されていたからだと思われる。
●デコーダで高度の仮想化を行なうNetBurst
いずれにせよ、NetBurstでは、デコーダを高機能にすることで、パイプラインの柔軟性を高めたことは確かだ。また、デコードのオーバーヘッドを考慮して、レイテンシが長いアーキテクチャに合わせた設計を取った。その結果、パイプラインを細分化してレイテンシを長くしても性能のペナルティが大きくならないようにした。だから、0.18/0.13μm版Pentium 4(Willamette/Northwood)で20段、90nm版Pentium 4(Prescott:プレスコット)で31段というパイプラインが可能になったと思われる。
では、実際にはNetBurstのデコーダはどういう仮想化を行なっているのだろう。Gelsinger氏は、LaGrandeを例に取り、モード移行はMicrocodeで吸収してしまうことを示した。そこから想像すると、今回の「64-bit Extension Technology(通称IA-32e、コードネームClackamas:クラカマス)」も、相当部分がMicrocodeで実装されていると見られる。
例えば、塩田紳二氏は「NetBurstなら64bit時のIA-32e命令を、2個の32bit MicroOPsに変換して実行させることもできるかもしれない」と指摘する。つまり、内部のリソースは32bitのユニットを二重化して用意、そこに2つの32bit MicroOPsを発行することで64bit演算を実行するという可能性もあるわけだ。
実際、Prescottでは、以前から整数演算パイプラインがダイ(半導体本体)上に2本存在するように見えることが指摘されていた。指摘したのは「Chip-Architect」( http://www.chip-architect.com/ )で、プロセッサのアーキテクトであるHans de Vries氏が、これは64bit化のためだと早くから指摘していた。2本の32bit 整数演算パイプに、2個のMicroOPsを発行して64bit演算を行なわせると考えると、つじつまは合う。
もちろん、Prescottが本当に64bit x86命令を32bitに分解しているかどうかはわからない。しかし、NetBurstなら原理的にそうしたトランスレーションも可能だと推定される。
●NetBurstの自由度でAMD64互換へと変更?
NetBurstアーキテクチャを考えると、Intelが比較的容易にAMD64とソフトウェア互換のインターフェイスへと変更できたことも納得できる。元のIntelの64bit拡張(Yamhill?)が、現在のIA-32eと異なるプログラミングインターフェイスやモードを備えていたとしても、Microcodeを入れ替えることで、柔軟に実装を変えることができると推測される。
例えば、NetBurstならモード変更の制御レジスタ参照は簡単に変更できる。命令プリフィックスも可能だろう。よりクリティカルな動作モードの変更も、Microcodeレベルで吸収できる可能性が高い。というのは、ソフトウェア側から見える動作モードの実装は異なっても、結果としてデコーダでトランスレートした後のMicroOPsは以前の実装と同じようにできるからだ。
では論理レジスタ数はどうだろう。もし、Intelがオリジナルプランでは8本の論理レジスタを計画していた場合、AMD64互換の16本の論理レジスタへの変更はできただろうか。
おそらく、NetBurstではこれも自由にできると思われる。そもそも、今のIA-32プロセッサは、論理レジスタを上回る数の物理レジスタを備えている。これは、レジスタ競合を避けるためにレジスタリネーミングを行なうからだ。だから、論理レジスタの数は、どれだけの数のレジスタをプログラム側から見えるようにするかという問題になる。
そして、NetBurstでは、もともとレジスタはデコード時点で仮想化されている。例えば、Hyper-Threadingで複数スレッドを同時にフェッチ/デコードしたら、それぞれのスレッドを異なるレジスタマップにマッピングする。つまり、Hyper-Threadingでスレッドが2つなら2面のレジスタマップを持つわけだ。そして、Hyper-Threadingが無効になっている時は、1面のレジスタマップにマッピングする。それで、同じ論理レジスタを使うスレッド同士を競合させることなくSMTを可能にしている。
つまり、NetBurstでは最初からレジスタは仮想化されていて、かなりの設定が可能になっていると思われる。それなら、論理レジスタ本数を8本から16本に拡張することも、行なうことができると推定される。
●推定できるYamhillの姿
NetBurstアーキテクチャを考えると、Intelの元の64bit拡張(Yamhill?)プランがどんなテクノロジだったかも見えてくる。まず、明確なのはパイプライン自体に大幅な手を入れる変更であったはずはないということだ。NetBurstのフィロソフィは、Microcodeレイヤに機能を実装し、パイプラインはシンプルにすることで高速化をやりやすくすることにある。だから、変更もほぼMicrocodeレベルだったと推定される。
とはいえ、Microcodeでカバーできる範囲は限られている。そのため、Yamhillはそれほど現在のIA-32eとかけ離れたテクノロジではありえない。例えば、YamhillがIA-64と互換性の高い(IA-64のコードもデコードできるような)アーキテクチャだった可能性は薄い。
それは、IA-64とIA-32ではアーキテクチャの思想自体が大きく異なるため、原理的に互換性を取ることが難しいからだ。IA-64は命令のスケジューリングをコンパイラ側に移し、CPUコア側にはハードウェアスケジューラを省く代わりに、演算ユニットや論理レジスタといったリソースをふんだんに用意することで、高並列化を実現する。こうしたハードとの互換を高めながら、限られたトランジスタ数で効率よくIA-32の性能を上げることは難しい。
IA-64互換は論外としても、AMD64互換への切り替えに、リソースの大きな変更が必要だった場合には、CPUの場合設計変更は年単位の話になってしまう。そのため、必要とするリソースは共通で、64bit拡張のプログラミングインターフェイスをMicrocodeで変えるような変更だったと推定される。
●明瞭になってきたNetBurstの弱点
Intelの64bit拡張を機に、ようやく見えてきたNetBurstの本当の姿。しかし、これはNetBurstの弱点も明瞭にしている。それはトランジスタ効率・電力効率だ。レイテンシの長いNetBurstは、その分パフォーマンスに対するトランジスタと電力の効率が悪い。その結果、NetBurst系CPUは、比較的大きなダイと、猛烈に高い消費電力になってしまっている。
そして、NetBurstにとって不運なのは、このアーキテクチャが、プロセス技術が低消費電力化で行き詰まり始めた時に導入されたことだ。現在の最先端シリコンは、電力のスケーリングの縮小と、リーク電流の増大によって、微細化しても消費電力が下がらなくなってしまっている。そのため、TDP(Thermal Design Power:熱設計消費電力)は世代毎にどんどん上昇している。PrescottでTDPは115W、来年のTejas(テハス)では125W。
そうなると、次の世代でデュアルコア化する際には、さらに大きな消費電力を予期しなければならなくなる。ところが、PCで許容できるCPU TDPの上限は140W程度とIntel自身も認めている。つまり、NetBurstは柔軟性のトレードオフとして失った効率性のために、行き詰まり始めているのだ。
おそらく、IntelはTejas/Ceadermillの次のCPU世代では、パフォーマンス/消費電力にフォーカスした、高効率アーキテクチャを取らなければならないだろう。とすると、それはおそらくNetBurstの延長ではない。むしろ、同じIntel CPUでも、Pentium Mのような、効率化に集中したアーキテクチャになるはずだ。
最後に、このレポートと前回のレポートで説明している内容を、最初に洞察した人物は塩田紳二氏だ。彼はIA-32e発表の直前から「機能の多くをMicrocodeとして実装し、マイクロアーキテクチャを仮想化することで拡張性を実現しているから、柔軟なアーキテクチャ拡張ができるのでは。カギとなるのはデコーダだ」と推察していた。その推論を、Gelsinger氏にぶつけた結果、まさにその通りの答えが出てきたわけだ。オリジナルの洞察は彼のものだ。
□関連記事
【3月9日】【海外】HT/CT/LT/VT-4つのテクノロジを拡張できるNetBurstの秘密
http://pc.watch.impress.co.jp/docs/2004/0309/kaigai071.htm
【2月25日】【海外】Intelは昨年秋にAMD64互換を決めた
http://pc.watch.impress.co.jp/docs/2004/0225/kaigai067.htm
(2004年3月10日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] 個別にご回答することはいたしかねます。
Copyright (c) 2004 Impress Corporation All rights reserved.