 |


■後藤弘茂のWeekly海外ニュース■パイプライン論争に決着?
|
●Pixel Shaderを用途によって組み替える
“バーチャルパイプライン”で最も効率のよい構成にGPUのリソースを組み替える。NVIDIAのGeForce FXは、GPUの従来のパイプラインの考え方を崩し、新しいGPU設計の方向性を見せる。
NVIDIAのChief Scientist、David B. Kirk(デビッド・B・カーク)氏との電話インタビューの結果、GeForce FX登場以来、疑問だったGeForce FXアーキテクチャの一部が見えてきた。また、データパスは最小に留めながら、プログラマブルな演算ユニットアレイをフレキシブルに構成できるようにする、今後2~3年のGPUの大きな流れも見えてきた。
まず、GeForce FX 5800/5900(NV30/NV35)アーキテクチャでは、演算ユニット群とデータパスを、用途によって再構成できる。NVIDIAでは、これをバーチャルパイプラインと呼んでおり、NVIDIAがGeForce FXには従来のような固定パイプラインがないと主張する根拠となっている。
GeForce FXのPixel Shaderの中心となるユニットは、32bit×4Wayの128bit SIMD演算ユニットだ。32bit浮動小数点ピクセルのデータは、各32bitのカラー3色+アルファの4値で合計128bitになる。128bit SIMDユニットは、128bit幅のデータパス(実際にはオペランドの数だけ必要)でそのデータを読み出し演算を行なうわけだ。NV35ではフルレンダリングでは最大4個のユニットが並列に処理できる。
しかし、NVIDIAのアーキテクチャでは、データタイプによっては、ユニットとパスを2つの方法で分割できるらしい。
ひとつは、フルのカラーレンダリング以外の場合。「Zとステンシル(シャドウ)レンダリングでは、我々はもっと多くのピクセルをクロック当たりレンダリングできる。Zとステンシルのデータ量は少ないので、多くのピクセルを処理できるように、データパスを構成したからだ」とKirk氏は説明する。
Zとステンシルの処理の場合は、各ピクセルあたり、整数32bitのスカラ演算で済むと推測される。この2つの処理は、基本的には2値の比較計算だからだ。例えば、Zを32bitで表現している場合は、2つの32bit値を比較することで処理できることになる。ステンシルも、各シャドウのサイドと3Dオブジェクトの深度の比較で、処理は基本的に同じだ。
そのため、これらの演算の場合、GeForce FXではSIMD演算ユニットを分解して、複数のスカラ演算を実行していると見られる。実際、NVIDIAの資料でも、Zとステンシルの処理は、NV30/35では8 Pixel/Clockとなっている。つまり、ノーマルピクセルの2倍の並列処理だ(本当は4倍になってもよさそうだが)。
もうひとつの分割はデータ幅が異なる場合。GeForce FXでは、各32bit演算ユニットを半分に分割して、2個の16bit演算が実行できる。32bit×4の128bit SIMDユニットは、2個の64bit SIMDユニット(16bit×4)として動作すると推測される。これについては、議論があったが、Kirk氏はあっさり認めている。もっとも、この手法自体は、CPUやDSPでは珍しくない。限られたトランジスタ数の中でGPUの性能を上げようとしたら当然の選択となる。
このように、NVIDIAのアーキテクチャでは、バーチャルパイプラインにより処理に合わせたリソースの構成が可能となっている。しかし、現在のNV30/35の実装では、完全に自由な構成が可能というわけではない。例えば、NV30/35では、基本的には4または8パイプラインの切り替えとなる。そのため、ライバルメーカーからは、8つに分割できる4ピクセルパイプに過ぎないという声もあがっている。
●バーチャルパイプアーキテクチャの理由
NVIDIAがバーチャルパイプラインアーキテクチャを採った理由は、限られたダイサイズ(半導体本体の面積)とトランジスタ数の中で、精度と性能を上げるためだ。
NVIDIAの演算ユニットは内部精度32bitであるため、内部24bitの他のGPUベンダーよりもどうしても必要なトランジスタ数が多くなる。また、データサイズは128bit(32bit×4)であるため、データパスも複雑になりダイサイズが大きくなる。さらに、演算速度も必ず遅くなる。「これは物理だ。そこには“マジック”はない」とKirk氏はいう。
そのため、GeForce FXはそのまま設計したら、精度は高いが、どの処理も遅いGPUになってしまう。しかし、バーチャルパイプラインを採ることで、NVIDIAは精度と性能の両立を可能にした。つまり、NV30/35の浮動小数点カラー+Zのフルレンダリングは最大4ピクセル/クロックに過ぎないが、バーチャルパイプによりステンシル処理とZ処理は最大8ピクセル/クロックでできる。また、カラー演算も、データ精度を落とした場合には、演算の並列度を上げる(8ピクセル)ことができる。見方によっては、苦肉の策とも言える。
また、NVIDIAがこうしたアーキテクチャを採ったのは、ソフトウェア側の変化に対応するという意味もある。それは、ソフトウェアの進化によって、処理によってShaderに必要とされるリソースや性能が異なるようになってきたからだという。
例えば、Zとステンシルの処理は、演算自体は単純でデータ量も少ない。その代わり、特にステンシルでは最近は多くのピクセル処理が必要とされる。単純な作業を大量に行なうというわけだ。そのため、こうした処理では、ピクセルパイプラインの並列度を高めた方が効果が上がる。
一方、通常のレンダリング処理は、シェーダプログラムもどんどん複雑になりつつある。そのため、ひとつのピクセルに対して、何10または何100ものサイクルをかけて処理を行なうことになる。また、データ量も多い(カラー+アルファで最大128bit)。こうした処理では、パイプラインの並列度を高めるよりも、パイプラインの処理効率を高める方がいいとNVIDIAは考えている。
ひと昔前なら、シェーダも単純でステンシルシャドウもそんなにガンガンに使わなかったので、パイプラインを固定していても性能が上がった。しかし、今後は、ソフトウェア側の進化により、処理に合わせてパイプラインの構成を変えられた方が効率がよくなると考えたわけだ。複雑なシェーダプログラムやステンシルシャドウの多用でも、性能が上がるアーキテクチャということになる。
また、NVIDIAはGPUのボトルネックがShaderの演算性能に依存するようになりつつあると考えている。「通常、ボトルネックはテクスチャかステンシルにあり、カラー+Zパフォーマンスであることはまれ」とKirk氏は言う。
●処理を集中させるNVIDIAと分散させるATI
GeForce FXでは、多くの処理を中核となる浮動小数点SIMD演算ユニットに集中させていることも明らかになった。例えば、テクスチャアドレスに必要な浮動小数点演算や、テクスチャリング処理の一部も行なっているとKirk氏は言う。
これが他のGPUとどう違うのか。例えば、RADEON 9700/9800(R300/350)系ではPixel Shader内部に、浮動小数点カラー&アルファ演算ユニット、浮動小数点テクスチャユニット、浮動小数点テクスチャアドレスユニットを分離した形で備える。そのため「テクスチャ、アドレス、カラーの3命令を同時に実行することができる」(ATI Technologies, Ed Huang氏, Director, Workstation)という。
もしATIアーキテクチャでは全てのテクスチャ命令が並列に実行できるのなら、ATIではテクスチャユニットもフル機能を備えている可能性がある。また、アドレス生成については、ATIがわざわざ“浮動小数点”アドレスユニットと呼んでいるのは、3Dオブジェクトにテクスチャをマップする演算もアドレスユニットで行なっているためと推測される。
それに対して、NVIDIAの場合、少なくとも3Dオブジェクト上にマップする演算は、メインのSIMD演算ユニットでやっている。メモリへの物理アドレス生成は別ユニットでやっている可能性はあるが。また、テクスチャリングでも、ある程度の処理はメインのSIMD演算ユニットでやっているようだ。もちろん、テクスチャ系の処理では、Cube Environment MapやAnisotropic Filteringのように、プログラマブルハードウェアではなく専用目的ハードウェアで実装した方がずっと効率がいい処理がある。これについては両社とも、専用ハードを用意している可能性が高い。
こうして見ると、ATIはそれぞれの処理をある程度特化した演算ユニットに割り振っているのに対して、NVIDIAはできる限り処理をひとつのユニットに集中しようとしている。
●見えてきた今後のNVIDIAのGPUの方向性
Kirk氏が演算パワーは2倍にしたが、データパスは2倍に増やしていないと言っていることも重要だ。ロジックチップの場合、データパスが増大すると配線レイヤが複雑になりダイサイズも増える。そのため、NVIDIAが、NV35で演算ユニットを強化しながら、ダイサイズの増大を避けるためにデータパスの拡張は抑えた可能性はある。NV35でも、個々の処理の並列度が増えていない理由はそのあたりにありそうだ。ただし、このあたりの詳細はまだわからない。
こうしたGeForce FXのアーキテクチャから、NVIDIAのNV40やNV50の方向性も見えてくる。NVIDIAが目指しているのは、おそらく、汎用性が比較的高いShaderユニットが多数並び、そのユニットとデータパスをフレキシブルに構成することで、仮想的に多数のパイプラインを構成できるようなGPUだ。例えば、将来は、16個のShaderユニットで、最大64個のバーチャルパイプラインが構成できるアーキテクチャになるかもしれない。
NVIDIAは、今回、Kirk氏が休暇中であるにも関わらず、電話インタビューに引っ張り出して来た。これは、NVIDIAがアーキテクチャを説明する重要性を認識し始めたことを意味している。また、GPU設計の総責任者であるKirk氏が5月中旬から長期休暇に入ったということは、別な面白いことを意味している。
それは、次世代製品の設計が一段落したということだ。もっともありうるのは、NV40のネットリスト(論理設計)までは終わり、テープアウト(設計完了)を待つばかりの状態になったという可能性。だとすれば、次の製品のファーストシリコンは夏の比較的早い時期ということになる。そこから、2回バリデーションサイクルを回すとすると年末出荷になる。昨夏にテープアウトしたGeForce FX 5800(NV30)よりは早いペースとなる。
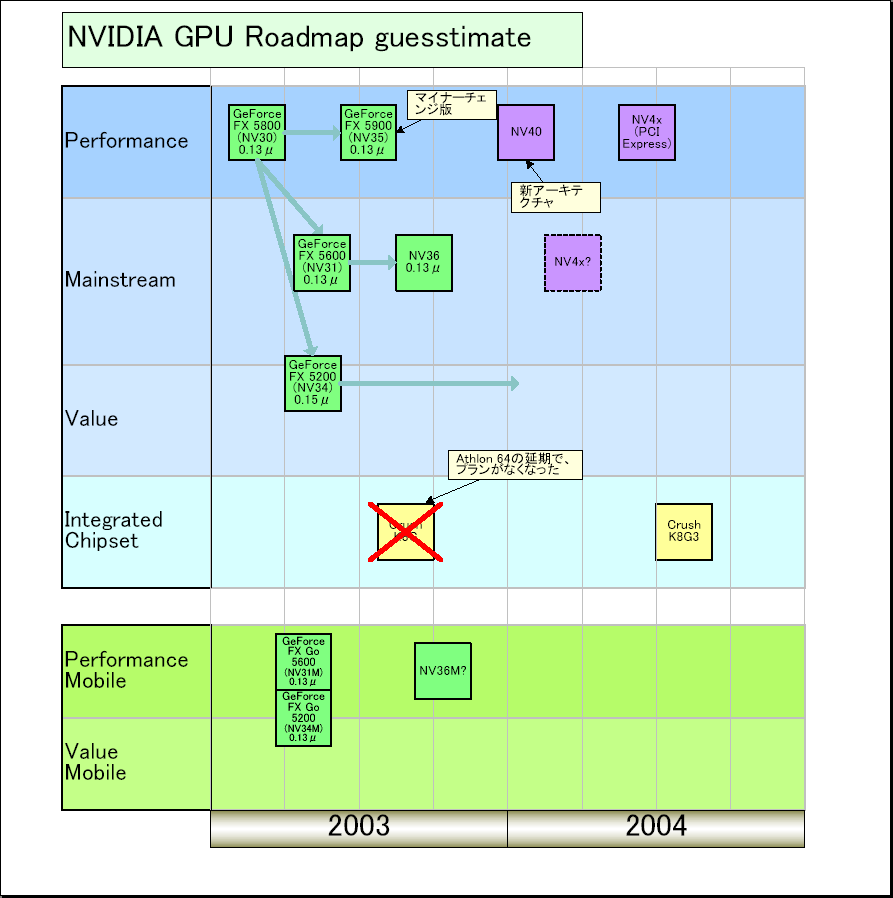 |
NVIDIA最新GPUロードマップ(再掲) |
□関連記事
【6月13日】【海外】Shader 3.0とPCI Express x16への対応を進めるNVIDIA
~NVIDIAキーパースンインタビュー2
http://pc.watch.impress.co.jp/docs/2003/0613/kaigai01.htm
【6月12日】【海外】GeForce FXアーキテクチャの秘密を明かす
~NVIDIAキーパースンインタビュー
http://pc.watch.impress.co.jp/docs/2003/0612/kaigai01.htm
【5月22日】【海外】まだまだ疑問が残るGeForce FX 5900のアーキテクチャ
http://pc.watch.impress.co.jp/docs/2003/0522/kaigai01.htm
(2003年6月13日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2003 Impress Corporation All rights reserved.