 |


■後藤弘茂のWeekly海外ニュース■RADEON 9800の性能向上の鍵はメモリ性能の向上 |
●GPUハードウェア自体の違いは最小
 |
| Andrew B. Thompson氏 |
また、RADEON 9800はRADEON 9700と比べて、複雑化する方向へ向かっていない。RADEON 9800は、うたい文句だけを見るとRADEON 9700からの大きなジャンプのように見える。しかし、違いは実は最小で、アーキテクチャは下手にいじらずに、性能を中心にチューンナップしたGPUだ。
そもそも、表面のAPIレベルでは、両GPUはほぼ変わっていない。GPUの中心となるVertex Shader(ジオメトリ処理を担当するプログラマブル演算ユニット)とPixel Shader(ピクセル&テクスチャ処理を担当するプログラマブル演算ユニット)のどちらについても「(サポートする)命令については、DirectX 9からの変化はない」とATIのAndrew B. Thompson氏(Director, Advanced Technology Marketing, ATI Research)は説明する。申し訳ないことに、これについては、以前間違えた記事を書いた。もちろん、最新CPUと同様に内部命令が変わっている可能性はあるが、ソフトウェア側から見る限りは同等だ。また、Pixel Shaderの内部処理精度も、最大各色24bit浮動小数点精度で、RADEON 9700から変わっていない。
そのため「トランジスタ数は500~1,000万程度増えただけ、ダイサイズ(半導体本体の面積)もほぼ同じ」(Thompson氏)という。プロセス技術自体もTSMCの0.15μmでほぼ同じだと思われるため、製造コストも原理的には変わらない。つまり、GeForce FX 5800(NV30)に対しては、依然として製造コスト面で有利だ。ボードでは最小構成時のDRAM個数がGeForce FX 5800より4個多くなるが、コスト面での優位は揺らがない。NVIDIAがNV30かその後継のNV35で、ダイ(半導体本体)を物理設計の最適化で縮小しない限りコストでは勝てない。
●DDR2を採用しなかったわけ
では、RADEON 9800の改良ポイントは何なのか。大きなポイントは3つだ。
- 物理設計の最適化による高周波数化
- メモリアクセスの効率向上
- Pixel Shaderのサポートする命令数の無制限化
周波数は380MHzで、向上の幅は劇的ではないが明瞭だ。ATIはこの周波数の向上を、プロセスの微細化ではなく、GPUの設計の変更だけで実現している。「我々が発表したクロックは380MHzだ。しかし、将来はそれ以上にできるだろう」とThompson氏は余裕があることを示唆する。もっとも、0.15μmのASIC(特定用途向けIC)はそれほど上げられるとは思えない。選別品で400MHzが採れるかどうかだと思われる。
メモリも同様だ。グラフィックス向けDDR1メモリの上限は350MHz(700MHz)前後で、それ以上には上げにくい。ちなみに、RADEON 9600/9700/9800シリーズはDDR1メモリだけでなく、DDR2メモリにも対応している。しかし、ATIはモバイル版以外ではグラフィックス向けDDR2(GDDR2)メモリは採用しない。今回のRADEON 9800でも、DDR2版ボードはアナウンスされていない。
「(RADEON 9800の)256MB版ではDDR2も検討した。しかし、どちらかというと高速なDDR1の方がいいと判断した。それは、DDR1の方が廉価で低消費電力だからだ。RADEON 9600も機能としてはDDR2をサポートできる」とThompson氏はその理由を説明する。
「えっ、DDR2ってDDR1より低消費電力だったのでは?」と思う人もいるかもしれない。これは説明が必要だ。メインメモリ用のDDR2がDDR1より低消費電力になるのは同クロックで比較した場合。そして、主な理由は、駆動電圧が2.5Vから1.8Vに下がるからだ。ところが、現在Samsung Electronicsが提供しているハイパフォーマンスのグラフィックス用の「GDDR2」は、プロセス技術の制約からコア電圧(Vdd)が2.5V(I/O電圧は1.8V)となっている。そのために、消費電力は周波数の向上分上昇してしまう。そうすると、NVIDIAのような排熱技術が必要になってしまう。
GDDR2はメインメモリ用のDDR2の派生品(x32)で、バスプロトコルやPrefetchアーキテクチャなど基本機能はDDR2と同じ。しかし、現在のコアはVdd 2.5Vで、メインメモリ用DDR2で言うと第1世代で量産化されなかったダイ(半導体本体)と同等となっている。
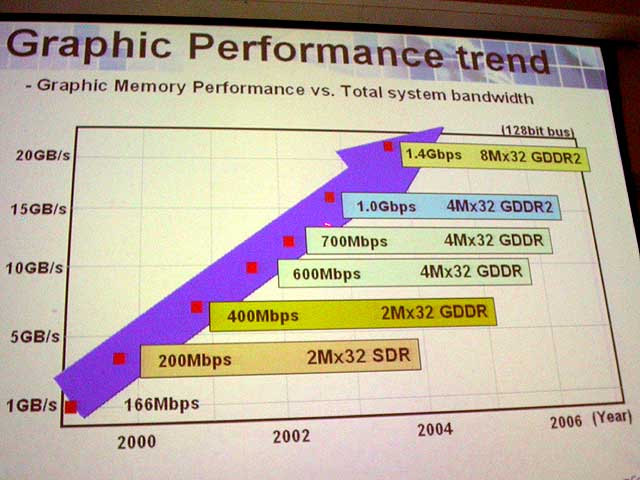 |
| メモリパフォーマンスのロードマップ |
「DDR2の利点は高クロックだ。DDR2が(DDR1)もっとずっと高速になったら、間違いなくDDR2に移るだろう。しかし、今のところはそこまで高速ではない」とThompson氏は言う。
Samsung Electronicsの提供するGDDR2は最高1GHz。プロセスを移行した次世代GDDR2を今年第2四半期からサンプル出荷する予定でいる。この新しいGDDR2は1.4GHzに達する見込みだ。だから、ATIがデスクトップでGDDR2を採用するとしたら今年後半のタイミングだろう。
価格も壁だ。「RADEON 9600もDDR2をサポートしている。しかし、価格が重要な製品ではDDR2は高価過ぎる。OEMメーカーがやりたいと決定するかもしれない。しかし、今のところはDDR2は推奨していない」とThompson氏は語る。ちなみに、同じGDDR2でも、Samsungとエルピーダメモリでは狙いも供給価格も異なる。
もうひとつ言うと、GDDR2自体の供給量も問題がある。まだDRAMベンダーはGDDR2に本腰は入れていない。今年後半からが本格となる。
また、ATIのハイエンドGPUの場合、GDDR2のコンフィギュレーションはおそらく256MBボードからになる。というのは、Samsungなどの次世代のグラフィックスメモリは256Mbitチップ(8M×32)になるからだ。256bitメモリインターフェイスでは8個のDRAMチップが必要となるため、ビデオメモリ容量は最低でも256MB(256Mbit×8)からとなる。もし、NVIDIAが次世代GPUで256bitメモリインターフェイスを採用した場合には、同様に256MBが最小構成となる。
●メモリの効率を向上させたRADEON 9800
しかし、RADEON 9800は、実際に性能を大きく向上させているのはメモリ周りの改良だ。
もともと、ATIはGPUの性能の鍵はメモリにあると考えている。そのため、ATIはRADEON 9700でメモリアクセス性能を大幅に高めた。例えば、昨年夏にATIのDavid E. Orton(デビッド・E・オートン)社長兼COOは次のように説明していた。「従来のチップ(RADEON 8500)ではメモリインターフェイスの効率はたった75%でしかなかった。しかし、RADEON 9700では80~90%をターゲットに、アーキテクチャ開発もここにフォーカスした」。
つまり、同じメモリ帯域でも、より効率よく使えるように改良したわけだ。だが、RADEON 9800ではそのRADEON 9700以上にメモリ効率を高めたという。どうやって?
「RADEON 9800では、メモリコントローラは再設計した。RADEON 9700が完成した後、そのパフォーマンスを解析、メモリコントローラと各クライアントブロックの間で、パイプラインを止める要因を見つけて改良した。メモリへの読み書きを最小回数に減らす最適化に力を入れた」とThompson氏は説明する。
つまり、RADEON 9800では、DRAMへのアクセス自体の効率を高めたのではなく、GPU内の他のブロックからのメモリアクセスの効率化と、そのアクセスパターンに合わせたメモリコントローラの最適化を行なったというわけだ。
●実は性能を大きく左右するZバッファ
実は、GPUは非常に無駄の多いことをやっている。本来、画面表示のために必要なピクセルよりも、ずっと多くのピクセルをレンダリングしている。そのために、「非常に高速なチップが必要になってしまう」とThompson氏は笑う。つまり、無駄なレンダリングのために、GPUは高速化して来たのだ。
GPUに無駄が生じるのは隠れていて描画しなくていいものまでレンダリングしてしまうためだ。現実世界でカメラが撮影するときは、何か物体の背後になっていて見えないものは映さない(映せない)。撮るのはあくまでも前面にある物体だけだ。3Dグラフィックスでは、隠面消去によって、背面にある物体を描かないようにする。
現在のGPUは、Zバッファアルゴリズムで隠面消去を行なっている。Zバッファではオブジェクトを描画するときに、Zバッファに各ピクセルの奥行きを示すZ値を格納する。そして、別なオブジェクトを描画する際に、このZ値を比較することで、どちらのオブジェクトが前面でどちらが背面かを判断する。
GPUではZバッファの隠面消去をもともとはピクセルパイプの下の方で行なっていたが、その場合、多くの無駄が生じてしまう。レンダリングしたあとのピクセルが、実は背面にあると判明して破棄されるケースが出てくるからだ。昨年のRADEON 9700の説明会ではATIのEric Lundgren氏(Product Manager)が「通常のゲームでは3~4回ピクセルをオーバードローしている。3~4倍のレンダリング(能力)が必要で、そのためにパフォーマンスが必要となっている」と説明していた。つまり、本来必要なレンダリング能力の3~4倍の能力が必要となっていたわけだ。だから、この部分の改良は、GPUの性能に劇的に影響する。
そこで、RADEON 9700など先端GPUはピクセルパイプの前の段階で行なう「Early Z Culling」という手法を併用している。つまり、ピクセルパイプの前のラスタライズの段階で、オブジェクトをピクセルレベルに分割(sub-divide)してZテストを行ない、隠面消去を行なう。
「これには2つの利点がある。ひとつは、(ピクセル)データのプロセッシングにかけるサイクルが不要になること。しかし、もっと重要なのはメモリの読み書きが減ることだ。あるオブジェクトが不要なら、そのオブジェクトに貼るテクスチャのフェッチも不要になる。これは、非常に重要だ。だから、NVIDIAも同じようなタイプの手法を用いている」とThompson氏は言う。
 |
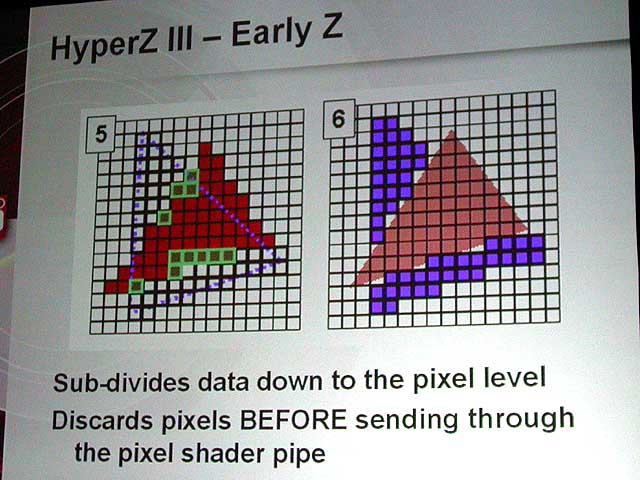 |
| 階層型Z(Hierarchical Z) | データをピクセルレベルに分割して隠面消去を行なう「Early Z」 |
●Zバッファの改良でメモリアクセス要求を減らす
しかし、Early Zでの消去はまだまだ完全ではないらしい。「完全に行くなら、あるシーン上のピクセルは1回しかレンダリングされない。隠れているオブジェクトは除去されるからだ。ところが、(GPUでは)完全ではないので、同じピクセルを何度も描くことになる」とThompson氏は言う。
そのため、ATIはRADEON 9800ではこの部分を改良した。「(RADEON 9800では)パイプラインの上流での、隠面消去のロジックを大きく改良した」とThompson氏は言う。つまり、RADEON 9800では、ピクセルパイプに送る前に“見えない”ピクセルを除去し、“見える”ピクセルだけに極力減らしてしまうわけだ。そのため、RADEON 9800とRADEON 9700は、GPUのレンダリングコア自体はほぼ同じでも、レンダリング性能が上がる。
またATIは、RADEON系ではZバッファに階層型Z(Hierarchical Z)を採用している。これは、オブジェクトの奥行き情報を格納するZバッファをブロック単位で管理する手法だ。「4×4ピクセルのブロックレベルでシーンを解析。ひとつのブロックが、すでに描画されたブロックが前面に来るなら、そのブロックを破棄する」(Thompson氏)。
つまり、Zバッファ値を最初に比較する単位を、ピクセル単位よりも大きく取る。1つのZ値で4×4=16ピクセル分のZ値を代表させる。すると、ブロック単位のZ値ならデータ量がその段階で16分の1へと少なくなる。RADEON 9700ではこのブロック単位のZ値をZキャッシュ(Z-cache)に格納することで、メモリ上にあるピクセル単位のZ値を納めたZバッファへのアクセスを低減、メモリ帯域を節約するとともに、Z値参照のレイテンシを低減した。RADEON 9800ではこのブロック単位での隠面消去のアルゴリズムをさらに強化したと見られる。
またRADEON 9800では、アンチエイリアシング処理時のメモリ性能も上げている。
「RADEON 9700との最大の違いはアンチエイリアシングのパフォーマンス。我々は特にメモリコントローラをアンチエイリアシング時のパフォーマンスを高めることに最適化した。実際のレビュー結果では、RADEON 9700と9800を比較して、同クロック時にアンチエイリアシング処理を行なった場合には9800の方がずっと速いという結果が出ている」とThompson氏は言う。
こうして見ると、RADEON 9800の改良は、小幅でも非常に効率的に性能を上げるものであることがわかる。
□関連記事
【4月7日】違いは小さいが方向性が異なるRADEON 9800とRADEON 9700
http://pc.watch.impress.co.jp/docs/2003/0407/kaigai01.htm
(2003年4月8日)
[Reported by 後藤 弘茂]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2003 Impress Corporation All rights reserved.