 |


■後藤弘茂のWeekly海外ニュース■IntelがGDCでLarrabeeの命令セットの概要を公開 |
●Larrabee新命令の情報だけを公開
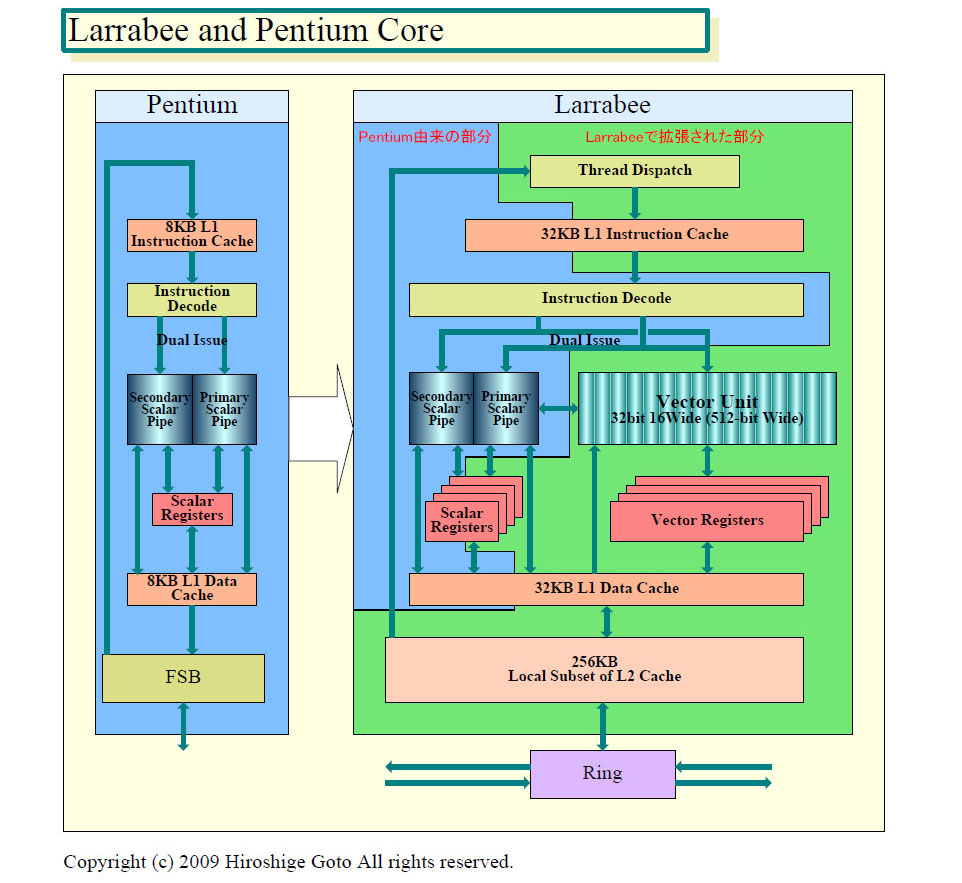
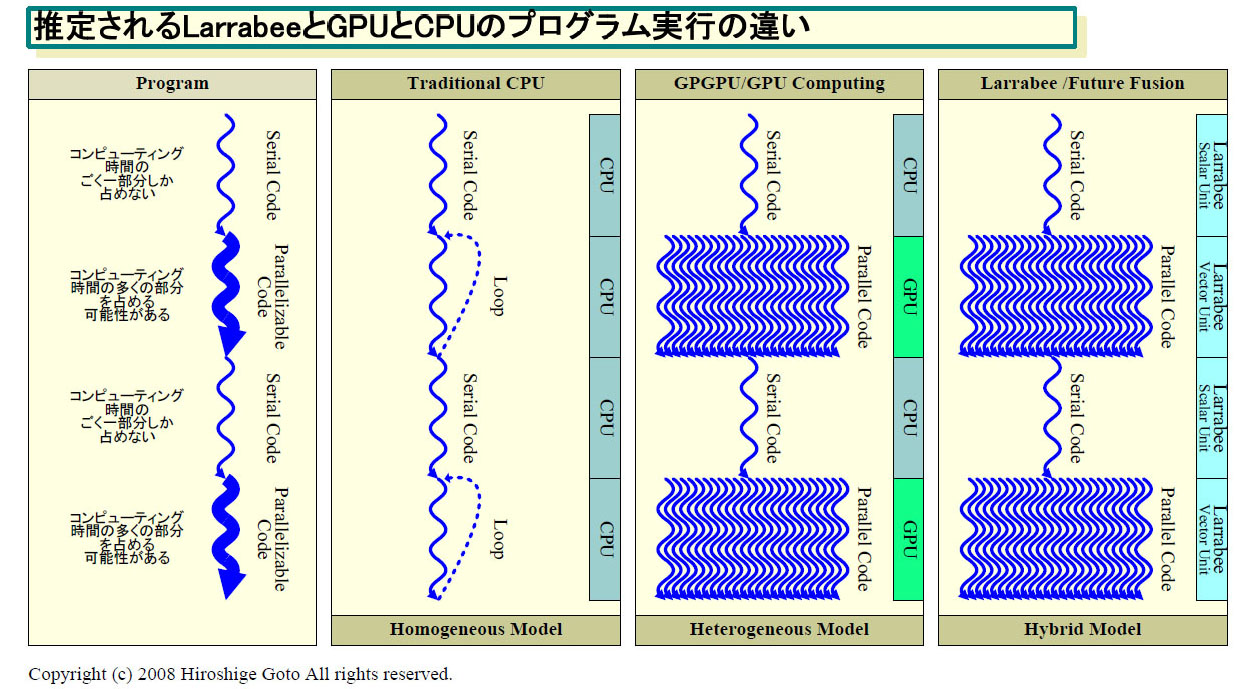
Intelはゲーム開発者向けカンファレンス「GDC(Game Developers Conference)」の技術セッションの中で、新アーキテクチャの高スループットメニイコアCPU「Larrabee(ララビ)」の命令セットの概要を明らかにした。Larrabeeは16~24個(2世代目)のCPUコアを搭載すると言われるx86系メニイコアCPUだ。CPUコアはPentium(P54C)相当のIn-Order実行2命令発行のパイプラインで、それぞれのCPUコアに16-wideのベクタユニットを搭載する。CPUとしてプログラムできるが、GPUと同レベルのグラフィックス処理もできる、つまり、CPUとGPUを兼ねることができる点がLarrabeeの大きな特徴だ。
GDCでは、x86命令セットに拡張として加えられた100以上のLarrabee新命令(LRBniまたはLNI)の大まかな概要や、LRBni(LNI)を使ったソフトウェアベースのラスタライザの概要などが説明された。命令セットの概要が明らかになったのは、今回が初めて。ただし、GDCでもLarrabeeの実チップのよるデモなどは行なわれなかった。今春頃には公開されると噂されていたLarrabeeの実物の姿は、今回のGDCでも秘されたままに終わった。また、製品化時期の正式なアナウンスなどもなく、製品レベルでは情報に進展はなかった。
Larrabeeのベクタユニットは、従来のIntel CPUに搭載されているSSEベクタユニットの拡張版だ。しかし、大きな違いがいくつかある。ベクタ幅を広げて、より多くの演算を並列にできるようにした点と、命令フォーマットを大きく変えた点、積和算やグラフィクス処理のため命令を加えた点、そしてベクタ型スーパーコンピュータや最新GPUが採用するのと同じマスクレジスタによるベクタ分岐を可能にした点。今回のGDCでは、LRBni(LNI)の説明を通じて、これらの違いが説明された。
 |
| Larrabee x86 Core Block Diagram_Pentium比較版 PDF版はこちら |
 |
| LarrabeeとCPUとGPUプログラミング PDF版はこちら |
 |
 |
 |
 |
 |
 |
 |
 |
 |
●ベクタレジスタは32本/スレッドで合計128本
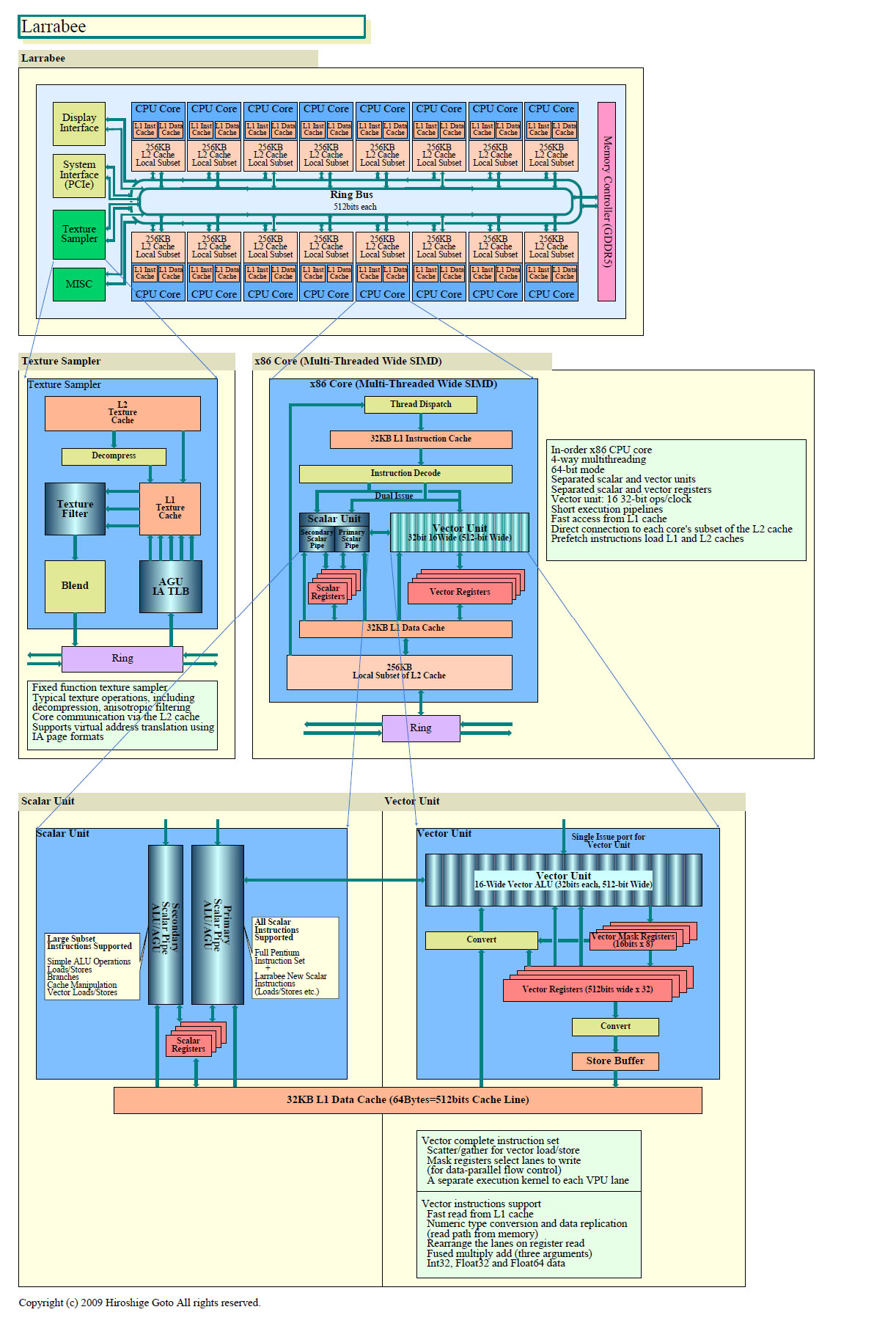
Larrabeeのベクタユニットは32-bit単精度の浮動小数点データ16個に対して、積和算演算を含む演算をSIMD(Single Instruction, Multiple Data)型に行なうことができる。SSEベクタユニットの4倍のSIMD幅のベクタユニットだ。1サイクルにより多くの演算を並列に行なうことができるため、Larrabeeの浮動小数点演算性能は既存のCPUより1桁高く、GDCでは1TFLOPS以上と説明された。各CPUコアは積和算が可能な16-wideのベクタユニットを持つため、16コアとするとLarrabeeは1.96GHzで1TFLOPSに達する(スカラパイプの浮動小数点演算は含まない)。このことから、Larrabeeは2GHz以上で製品化される予定であることが推測できる。
 |
 |
 |
| intel Tom Forsyth氏 |
Larrabeeの、各CPUコアのベクタユニットは、新設のベクタレジスタを使う。ベクタレジスタは、32-bitデータスロットを16個備えた512-bit長となっている。ベクタレジスタの数は各スレッド32本(v0-v31)ずつ。Intelの命令セットアーキテクチャはレジスタ本数が少ない(8~16)ことが弱点だったが、Larrabee新命令(LRBniまたはLNI)では、いよいよレジスタ本数を32本に拡張した。Larrabeeは4wayのハードウェアマルチスレッディングをサポートするため、「Larrabeeの各CPUコアは合計で128本の物理ベクタレジスタを持つ」(Tom Forsyth氏, Intel)という。Cell B.E.のSPU(Synergistic Processor Unit)も128本の物理レジスタを持つが、こちらは128本全てが1スレッドの中でアクセスできる。
Larrabeeは、メモリアクセスレイテンシや実行レイテンシの隠蔽をハードウェアマルチスレッディングとソフトウェアマルチスレッディングの組み合わせで行なう。数10スレッド以上のハードウェアマルチスレッディングをサポートするGPUと較べると、マルチスレッディング機能は小さい。しかし、ソフトウェアマルチスレッディングも、L1キャッシュが非常に短レイテンシでマルチポートであるため短時間に待避できるという。「LarrabeeではL1キャッシュをレジスタの延長と考えることができる」とIntelのTom Forsyth氏は説明する。
 |
| Larrabee Over View PDF版はこちら |
 |
 |
●マスクレジスタによりベクタ条件分岐が可能に
LRBni(LNI)は、モダンな3オペランドフォーマットを取る。Intelの伝統的な2オペランドフォーマットから拡張されたため、ソースオペランドのデータを破壊せずに演算結果をセーブできる。また、オペランドの1つはメモリアドレスとすることができる。レジスタ間演算に絞るRISC型のフォーマットではなく、演算とロードが1命令にパックされたIntelの伝統的なスタイルを取る。
LRBni(LNI)では、32-bit整数演算(int32)、32-bit浮動小数点演算(float32)、64-bit浮動小数点演算(float64)のオペレーションがサポートされる。mul, add, sub, abc, sbb, subr, and, or, xor, madd(multiply-add), multiply-subといった一般的な演算命令が含まれるほか、ベクタ比較命令、アライン/アンアラインのストア/ロード、スキャッタ/ギャザ、bitマニピュレーションなどの命令がある。つまり、ベクタプロセッサとして必要な命令はフルに備える。
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
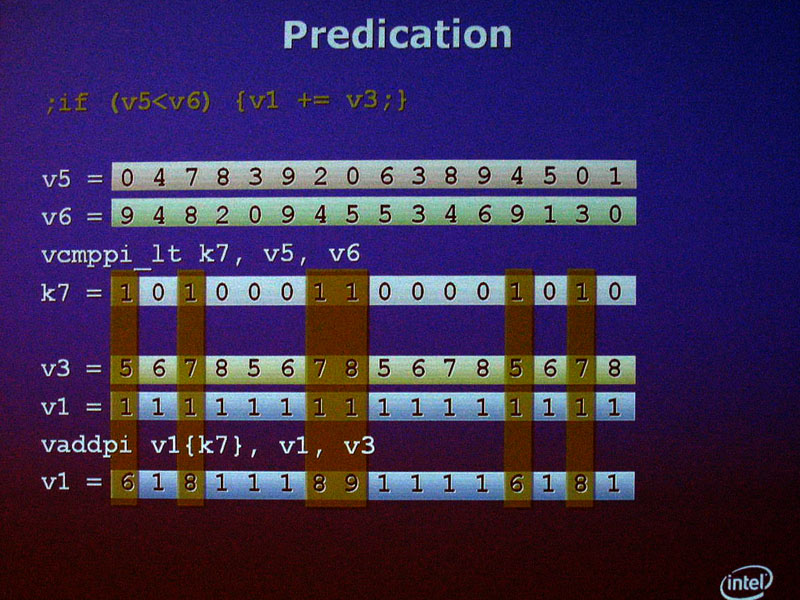
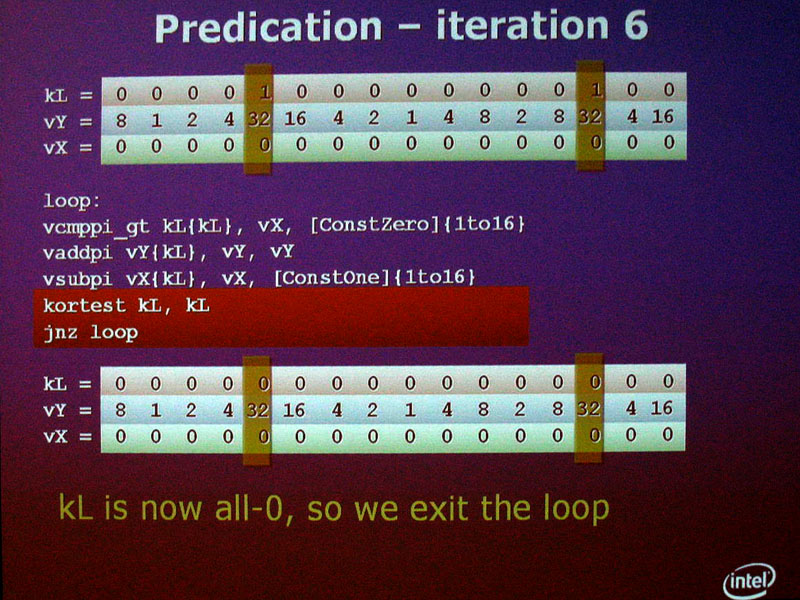
Larrabeeのベクタユニットは、8本の16-bit長のマスクレジスタを備える。これは、ベクタレジスタに対する書き込みのマスクを制御するレジスタとして使われる。ベクタスーパーコンピュータや最新GPUで一般的な手法だ。これによって、16-wideのベクタプロセッサの各レーン毎に、事実上の条件分岐を実現する「プレディケーション(Predication)」が可能となる。プレディケーションは、現在のGPUも備えている。
従来のSSE型のベクタユニットでは、4個のデータ全てに対して同じ演算を実行しなければならなかった。しかし、Larrabeeのベクタユニットでは、16個のデータに対して行なった演算の結果を、それぞれレジスタに書き込むか書き込まないかをマスクレジスタによって制御する。それによって、異なるプログラムパスを実行させることができる。つまり、ベクタプロセッサの中で分岐が可能となる。
 |
| ベクタ条件分岐フロー PDF版はこちら |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
●SOA型のデータ配列を標準とするLarrabee
LRBni(LNI)では、プレディケーションが可能であるため、SSEとは異なるデータ配列を取りやすい。SSEでは、データを「AOS(array of structure)」と呼ぶ配列にするのが一般的だ。それに対して、LRBniでは、多くの場合データを「SOA(structure of array)」と呼ぶ配列にすることを前提としている。AOSは「パックド(packed)」と言い換えることが可能で、SOAは「スカラ(scalar)」と言い換えることが可能だ。
AOSとSOAは、大きな違いとなる。例えば、SSEでSOAの場合、同じ演算を行なうデータのセットを最大4データ分、揃える必要がある。グラフィックスの頂点処理を例に取ると、3次元座標のxyzそれぞれの値をパックし、xyzに対して同じ演算処理を行なう。それに対して、LRBniでSOAの場合、16個ものデータのセットを揃えてパックする必要はない。頂点処理なら、多くの頂点のxyzをそれぞれまとめて処理する。例えば、最初に16個のxを処理し、次に16個のyを処理、最後に16個のzを処理する。
従来のSSE型のベクタユニットの場合、SOAを取った場合、特定の処理を行なう頂点と行なわない頂点を混在させることができなかった。しかし、LRBniでは、この場合も、プレディケーションによって、個々の頂点毎に、特定の演算パスを実行するかどうかを制御することができる。例えば、1つ目の頂点にはプログラム中のパスAを実行しない場合は、マスクレジスタによってレジスタに演算結果を書き込まないように制御する。
 |
 |
 |
 |
 |
 |
 |
 |
 |
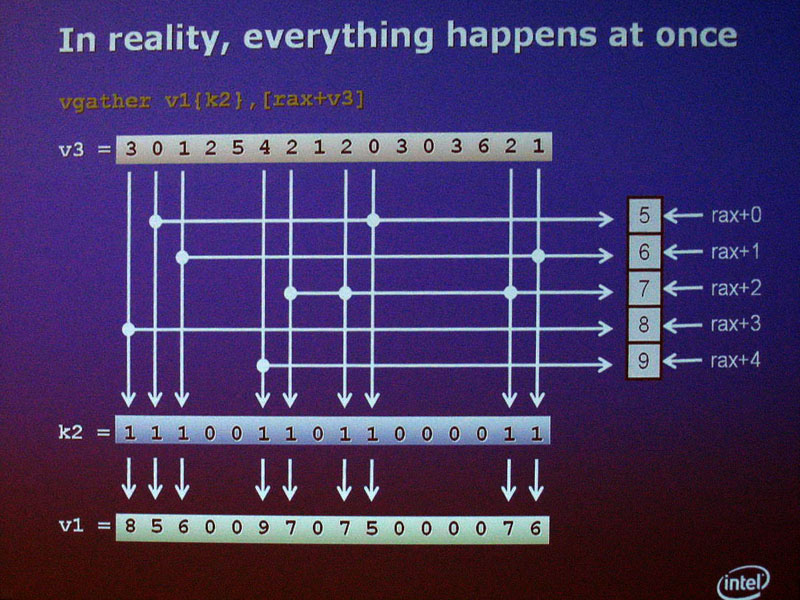
LRBniはSOAを基本とするため、メモリからレジスタへデータをロードする際に、分散したデータを集める「ギャザー(gather)」を行なう必要のある場合が多い。ストアする際にはその逆にデータを分散する「スキャッタ(scatter)」が必要になる場合が多い。スキャッタ/ギャザでも、LRBniはマスクレジスタを使い、データレーン毎にロード/ストアするデータを選択することができる。
 |
 |
 |
 |
 |
 |
IntelはGDCで、Larrabeeのこうした命令セットを明らかにするとともに、グラフィックス処理の中のラスタライズで、新命令を使った効率的なアルゴリズムの実装を明らかにした。通常、GPUはラスタライズのための専用ハードウェアを備えるが、Larrabeeではラスタライズをソフトウェアで処理する。従来のソフトウェアソリューションでは、総当たり戦でスカラ型に行なっていたラスタライズを、Larrabeeではベクタプロセッサである程度効率的に行なうことができるという。また、Intelは「C++ Larrabee Prototype Library」をLRBni理解のために提供することも明らかにした。
命令セットが明らかになったことで、Larrabeeの性格はより鮮明になった。CPUとGPUのちょうど中間地点。高スループットなフルプログラマブルプロセッサであるLarrabeeは、将来のグラフィックスアーキテクチャを刷新する可能性を秘めている。それは、グラフィックスAPIに縛られない、ソフトウェアレンダラの世界だ。しかし、そこに至るために超えなければならない壁も高い。
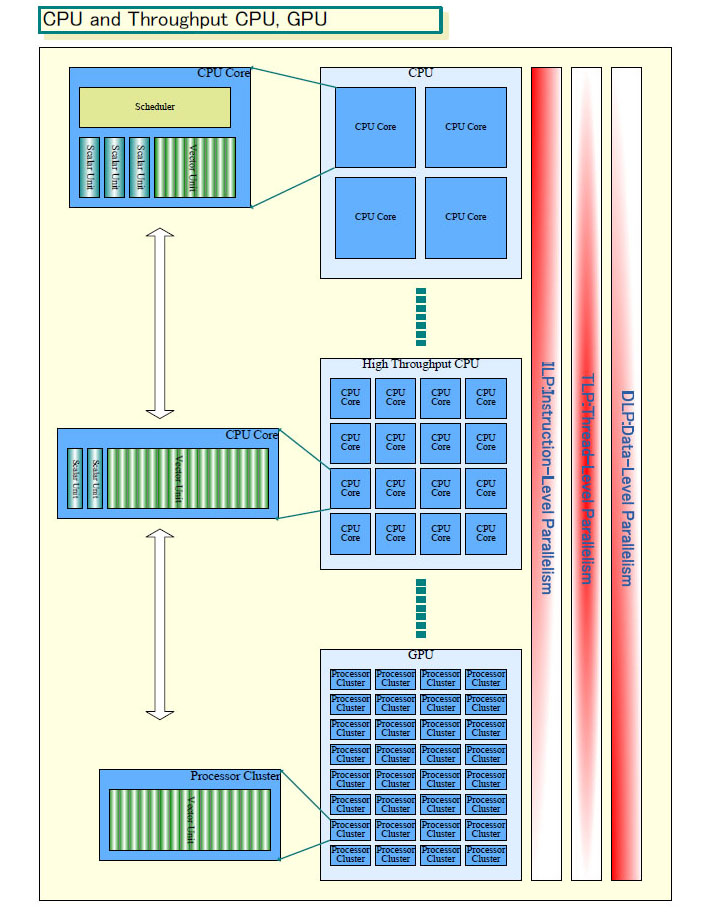 |
| CPUアーキテクチャの分化と共通化 PDF版はこちら |
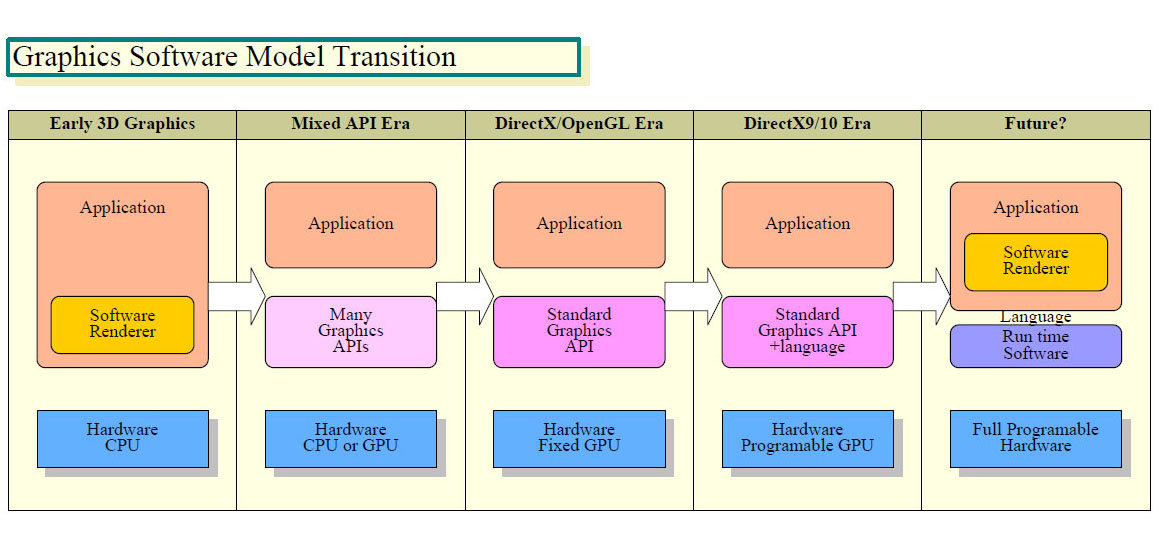 |
| グラフィックスソフトウェアモデルの変化 PDF版はこちら |
□関連記事
【2008年8月22日】【海外】正式発表されたLarrabeeアーキテクチャ
http://pc.watch.impress.co.jp/docs/2008/0822/kaigai461.htm
【2008年10月6日】【海外】CPUに統合できるLarrabeeアーキテクチャ
http://pc.watch.impress.co.jp/docs/2008/1006/kaigai470.htm
【3月5日】【海外】なぜLarrabeeベースのPS4はハードルが高いのか
http://pc.watch.impress.co.jp/docs/2009/0305/kaigai493.htm
(2009年3月30日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2009 Impress Watch Corporation, an Impress Group company. All rights reserved.