 |
【開発者特別レポート】
|
独立行政法人情報処理推進機構(IPA)が主催する「未踏ソフトウェア創造事業」は、個人又は数名のグループを対象として、独創的なソフトウェア技術や事業アイディアを公募し、その開発を支援する制度だ。
その2007年第I期で採択された案件の1つが美崎薫氏の「PilePaperFile」である。美崎氏は、BTORNや超漢字、ユビキタス環境をテーマにした書籍の執筆でも知られている。
採択理由は、「重ねた紙,綴じた紙、広げた紙をモチーフとした統合デスクトップ環境の提案である。本開発者はこれまでにも極めて多数のラスタデータを閲覧する環境を提案してきたが、今回の提案は紙のパラパラ感、書店の平積み台の一覧感をデスクトップ上にいかに表現し、操作できるようにするかがチャレンジとなる。特に操作に関してはジェスチャの利用を考えているようだが、その再考を条件に採択とする」とされている。
今回は美崎氏本人に「PilePaperFile」の概要と現状について寄稿いただいた。(編集部)
 |
| 2007年度未踏ソフトウェアに採択されたPilePaperFileプロジェクト |
2004年度の独立行政法人情報処理推進機構未踏ソフトウェアに採択された「SmartCalendar」プロジェクトの時系列を継承しながら、より紙らしさを採り入れた新しいプロジェクト「PilePaperFile」の開発期間が終了した。
●SmartCalendarからPilePaperFileへ
コンピュータの進歩を背景に、記録できる情報量は圧倒的に増え始めている。
そこでPilePaperFileでは、100万以上の情報を柔軟に扱えるシステムを目指した。SmartCalendarを継承して、写真、テキストをシームレスに扱えるようにするほか、メールも混在して扱えるようにする。可能な限り、音楽や映像データにも対応することを目標とした。
PilePaperFileの基本方針を次のように立てた。
- 手作業と自動化のバランスをとること。不要な手作業に時間を費やさない。「たくさん感」を表現しながら、必要な手作業には時間をかけられるようにする。
- WIMP(Window/Icon/Menu/Pointing device)インターフェースを再設計し、「重ね」を情報として使いスクロールバーを廃止、紙らしさを表現してアイコンを廃止する。
- 実装は重複をいとわず、複数実装とする。
PilePaperFileでは、手作業と自動化の二兎を追っている。そのため、1つのプロジェクトの中で、2つの局面が同時に進行するが、それらはユーザーの操作履歴と合わせて最適化した。
●紙のように
PilePaperFileとは、紙のように情報を扱うシステムの仕様である。「紙のように」を実際に実現したPileDesktopを見た人からは、ノスタルジックなシステムと評されたが、どこにノスタルジーを感じているかと言えば、それは紙そのものにだ。どれほどコンピュータが進歩しても、まだ紙には紙ならではの魅力がある、と感じていて、その魅力をコンピュータの上に再現したいと感じたのだ。
いくら情報が増えたとしても、最後に人間が判断をする部分では、絶対に手作業が必要である。書類をめくったり、比較したりするような作業は必要不可欠だ。従って、PilePaperFileでは、手作業を支援することを1つの方針とした。
手作業を心地よく行なうためには、手作業で扱える情報を制限する必要がある。1日にメールが1,000通も届いたら、どんなに時間があってもそれを処理することは困難だろう。机の上に未決の書類が10通乗っていたり、100冊の本が積み上がっていても同様だ。コーヒーと紅茶を同時に飲むことはできないだろう。可能だとしても心地よくはない。
手作業の心地よさを追求するためには、ある種の自動化は避けて通れない。そこで、PilePaperFileでは、可能な限り自動化にも注力をした。
●「自動化」と「たくさん感」
例えば、PilePaperFileでは、コンピュータ作業で不可欠と思われている各種の確認パネルを全廃する、という目標を立てた。保存する。「保存しますか? 」。終了する。「終了しますか? 」。メールを送る。「メールを送りますか? 」、「メールを送りました」。まるで、今いったことを、まったく聞いていないような慇懃なコンピュータとつきあっているのには、とことん愛想が尽きたのだ。紙の書類に確認作業が存在しただろうか。
「自動化」の1つはメールの振り分けシステムである。自動的にキーワードで振り分けすることで、目を通して決断し回答するメールの数は激減した。
「たくさん感」とは、手で触れるものの奥に、こうした自動化による豊富な背景を前提とした満足感を意味する。例えば筆者が20年以上通っている神田神保町の東京堂書店の平台は、一望するだけで経験豊かな書店員の手によって選び抜かれた70冊以上の本を視野に入れることができる、国内でも有数の(おそらくNo.1の)書店である。
 |
| PilePaperFileの重要なキーワード「たくさん感」は、東京堂書店とアマゾンを比較して得られた |
この棚のリッチさは、例えば年間に数十万円も購入するAmazonの「おすすめ」よりも、はるかに上をいっている。ほとんど次元の違うクオリティだ。
Amazonの「おすすめ」の悪いところは、1画面にせいぜい3つか4つしか表示できず、スクロールをし、ページをめくらなければ多数の情報にアクセスできないところにある。ぜんぜん「たくさん」でない。むしろ貧乏くさいのである。
PliePaperFileでは、コンピュータに「たくさん感」を再現することにした。具体的にはテキストファイル、メール、写真などを混在して、50~100の情報を同時に見ることができるようにした。
●重ね=Pileでスクロールバーを廃止
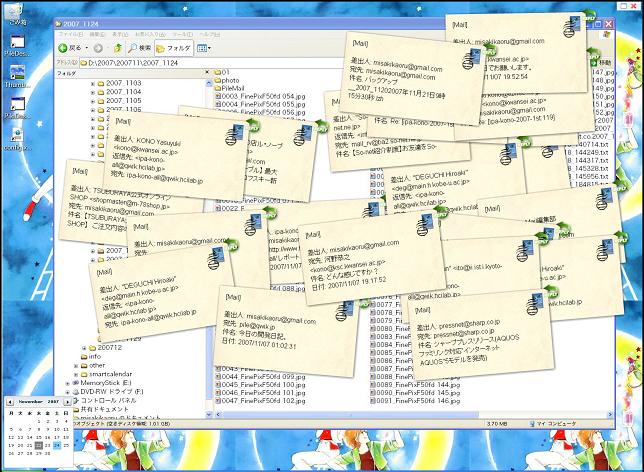
人間の情報処理の特徴は、モノの一部分でも見えていれば、必要か不要かを瞬時に判断できるところにある。新聞の見出しや、書店の平差しの本棚がそうである。従来のコンピュータのWIMPインターフェースでは、このようなことを行ないにくい。だいたいアイコンだけ見ても、ファイルの中身はわからない。サムネイルなら少しはマシだが、小さなサムネイルでは、これまた中身がわからない。
PileDesktopでは、「重ね」を情報として使いスクロールバーを廃止した。テキストやメールも内部の情報をPalmView(ソニーCSLの綾塚氏の命名による手のひらサイズの巨大なサムネイル)表示するので、ほとんど紙やカード、絵はがきなどを見ている感覚である。見るだけで大まかな情報を読み取れるのである。
自動化して、最小限表示するものを大きく表示して、瞬間的に判断できるようにしたわけだ。
●仕様と実装を分離し複数の実装
実装上の特徴としては、重複をいとわず、複数実装としたことである。SmartCalendarの場合、Windows版とMacintosh版があるとはいえ、基本的には実装は1つしかなかった。その反省から、PilePaperFileでは、さまざまな機能をパーツに分け、同時に多数の実装を並行して行なった。
例えばメール送信の機能は複数あり、ユーザーは好きなものをチョイス可能である。メール送信といっても、写真を送るのか、送り先はFlickrなのか友人なのか、縮小するのかしないのか、テキストのメールなのか、など、細かいニーズによって操作体系も使うソフトも異なっていてよいはずなのだ。
ユーザーはしたいことをしたいように操作するだけであり、背面で何が選択されどのように動いているかは、可能な限りコンピュータが自動的に判断する。自動的にといっても別に隠しているわけではなく、基本的にモジュールの組み合わせをスクリプトで動かすという挙動なので、手を加えればいくらでも加えることができるようになっている。当然ながらソースもある。
発想としては、複数のプログラムをスクリプトで駆動させてGUIシェルをかぶせたUNIXやMac OS Xと、大変近い考え方だ。そういう意味では、伝統的なOSの開発に近いの(というかそのもの)であって、ことさら新しいことを目指していないともいえる。
●PilePaperFileのモジュール群
以上の方針から、PilePaperFileは、ほとんどOSそのもののように、多数のモジュールからできている。主なものとしては、
- PileMail(インターフェースをもたないメールソフト)
- CapturePile(タギングをしながらキャプチャするキャプチャソフト)aki.氏作
- PileDesktop(紙と机を模したデスクトップGUIシェル)神原啓介氏作
- Flickrアップローダー 中蔵聡哉氏作
- テキストタギング
- PileTagcloud
などがあり、そのほかに開発ツールとして、
- NeXTジェネレーションマクロ(キーマクロツール)ジョニー氏作
- smbclient 豊福親信氏作
- tray2file/vobj2tray(トレーとファイルのやりとり)ささの氏作
- send(ファイル送信ツール) TUNE氏作
- 検索起動ツール ジョニー氏作
などがあるほか、名前のないツールも多数。PilePaperFile仕様に一部準拠したツールとして、
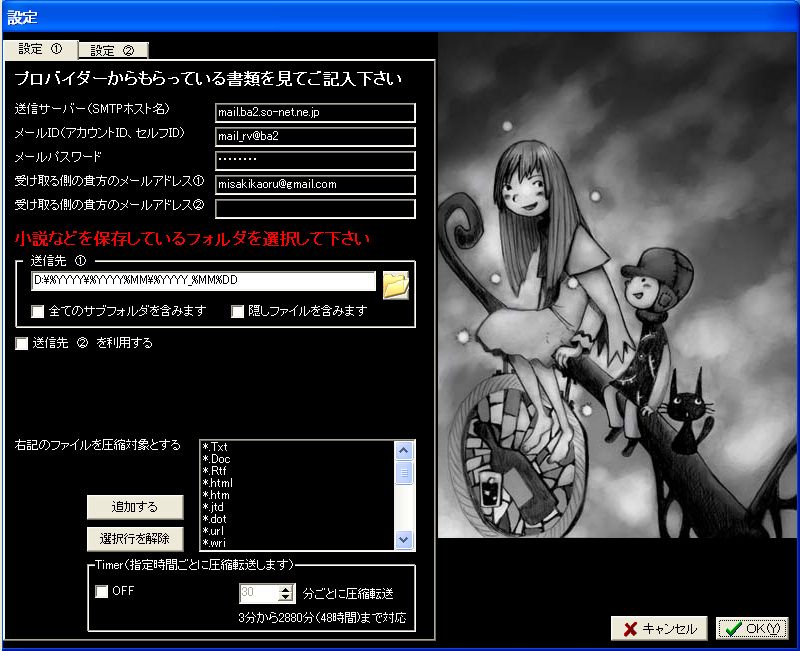
- 小説家志望支援ツール 表裏未里氏作
- Exif読取り君 遠雷氏作
- Clunch ゆうき氏作
- AlbumWeaver/ExportManager 綾塚祐二氏@ソニーCSL作
がある。
 |
 |
 |
| 表裏未里氏作の「小説家志望支援ツール」は、年月日機能をもつことでPilePaperFileのファイル構造と共通化できている | 神原啓介氏作の紙と机を模したデスクトップGUIシェル「PileDesktop」 | 「PileDesktop」は、インターフェイスをもたない「PileMail」のシェルとしても設計されている |
ほかに、Hyper Estraierの移植なども進めているし、ひょっとするとPileDesktopはMacintosh版も開発できるかもしれない。連携できる先もFlickr、はてなのほか、メモジャ! (吉田一星氏作)、Googleカレンダーなどと広がっている。
開発自体は順調だが、なにしろ物量が多く、外部のツール以外は、ほとんどリリースできていないのが現状である。手許では動いているので、ご興味のある方はぜひご連絡いただきたい。
PilePaperFileプロジェクトは現在も継続しており、今後は企業スポンサーと共同研究として続けられる見込みである。リリースフェーズに入るのは、かなり先になるだろう。当面、今回の記事を契機に、CapturePileを窓の杜でリリースしたいと考えている。ご使用、ご高覧とご意見をたまわれればうれしい。この場を借りて、実装された各位に謝意を表したい。
●CapturePile
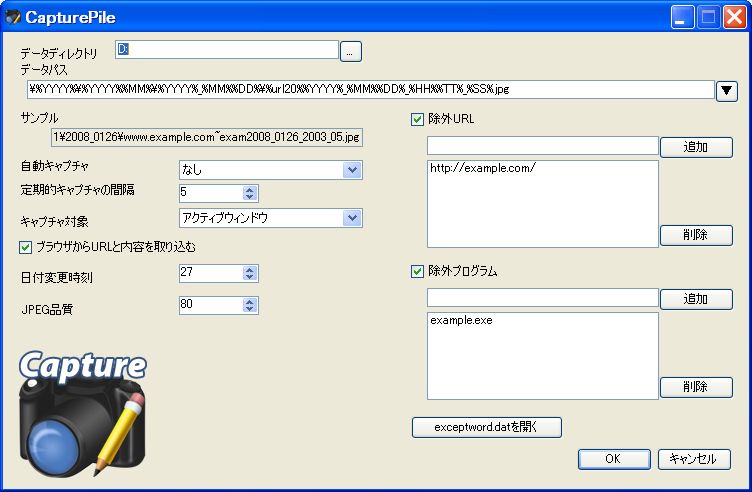 |
| aki.氏作の「CapturePile」 |
CapturePileは、PilePaperFileプロジェクトのなかでは、もっとも独立性の高いアプリケーションである。それもその名のとおり、画面キャプチャのツールだ。
従来のキャプチャツールともっとも異なる点は、単に画像をキャプチャするだけでなく、その画像にテキスト情報をタグとして自動的に埋め込む機能を持つことである。
インターネットアーカイブなどがあるとはいえ、Webページはしばしばなくなってしまうので、見たページを残しておくことは有効であると考えられる。
この場合、従来は、htmlで残す、html+画像で残す、txtのみを残す、写真のみを残す、などの方法があるが、Webページが複数の要素でできているので、それをうまく残すのはなかなか難しいものである。
再活用の可能性でいうと、面倒なタグのいらないテキストファイルがもっとも手軽に思えるのだが、テキストでは画像を残すことができないし、別々に保持するとしても互いのリンクは切れてしまう。
もう1つ問題な点は、そもそもWebページには、記録を制限しているページが少なくないことである。
CapturePileでは、画面をキャプチャとして保存し、そこにテキスト情報を埋め込むことにした。CapturePileで作成されるファイルは単なる画像ファイルではなく、テキストタグつきのメタ画像ファイルとなるわけである。
保存形式はWindows標準のJPEG形式なので、Windowsを使えばOS標準の機能で検索も可能である。Webページの場合、記録したURLも記述しておくことができるので、あとで引用する場合にも、出典を容易に情報として得ることができる。URLをWebページで開けば、オリジナルのページへと再アクセスもできる。
 |
| 「CapturePile」でキャプチャしたImpress Watchのトップページ。キャプチャしたWebのURLや時刻、中身のテキストなど豊富な情報が自動的に記録されている |
タグとして使用するテキストは、Webページに記述されているhtmlそのものなので、読んだ言葉がすべてキーワードとなる。Webページを記録するときに、新規にキーワードを手作業でつけるよりも、遙かに効率的である。念のため、キーワードは自分で追記もできる。
記述するテキストからは、Webページによくある見出しやインデックスなどを取り除くこともできる。CapturePileフォルダにあるexcept.txtというテキストファイルに、不要な見出し語などを記述しておくことで、その言葉をのぞいた文章だけを記録する。
CapturePileを起動すると、タスクトイレに常駐し、アイコンをクリック、または右クリックして[設定]メニューを選択することで、各種設定を行なうことができる。保存フォルダには、年月日も使える。
設定画面から設定できる機能は基本的な機能に限られるが、同梱のCapturePile.iniファイルを編集することで、動作するキー、表示する言語などをカスタマイズできる。表示言語は、英語のほか、日本語にも対応している。
□IPAのホームページ
http://www.ipa.go.jp/
□2007年度第Ⅰ期 未踏ソフトウェア創造事業 採択案件概要
http://www.ipa.go.jp/jinzai/esp/2007mito1/gaiyou/4-13.html
(2008年2月29日)
[Text by 美崎薫]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.