
【IDF Fall 2007レポート】
テラスケールコンピューティングのための言語「Ct」
会期:9月18日~20日(現地時間)
会場:San Francisco「Moscone Center West」
Intelは、メニイコア、ヘテロジニアスなど、いわゆるTera-Scale Computingと呼ばれる領域で、大きく3つの研究成果を発表している。1つは、昨年(2006年)春のIDFでラトナー氏が基調講演で語ったTransactonal Memoryである。これは、今回、ソフトウェアでこれを実現するSTM(Software Transactional Memory)対応のコンパイラが公開されている。
残りの2つが、「Accelerator Exoskeleton」と「Ct」である。Accelerator Exoskeletonについては別途レポートしたので、今回は、Ctについてレポートする。
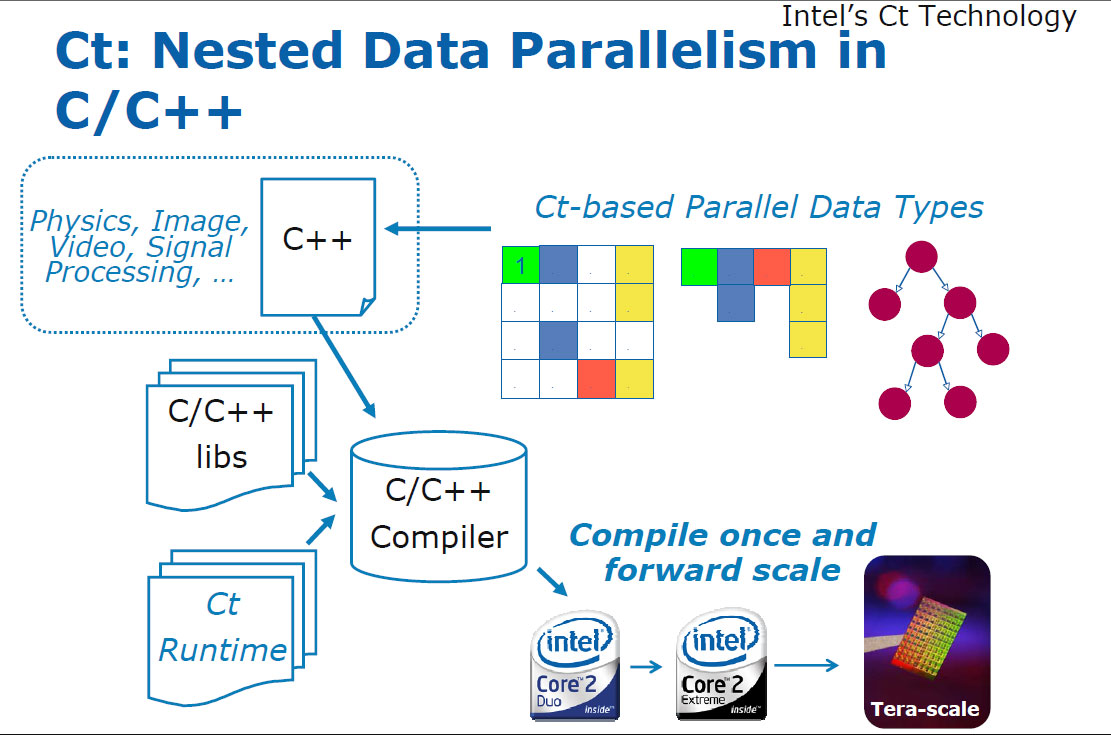 |
| Ctは、Ctで定義したデータタイプに対する演算処理をOpenMP対応C/C++コンパイラのソースへと変換する。一度作られた実行ファイルは、コア数に応じて並列化を実行時に行なうため、よりコア数の多いシステムで実行するほど、並列度が高くなり高速に処理できる |
Ctは簡単にいうとC++ベースの言語で、巨大な行列などを対象とした計算処理をマルチコアプロセッサで行なうためのものだ。
ただし、Ctは、ソースコードをOpenMP準拠のC++コードに変換して出力し、実行ファイルへのコンパイルなどは、OpenMPに対応したコンパイラ(Intelコンパイラ)などが行なう。
OpenMPは、C/C++に対して、並列化のためにコンパイラに与える指示などの拡張機能を規定したものだ。標準のC/C++には、並列処理のための機能やライブラリなどがなく、これを拡張して、並列処理するバイナリを生成できるようにするためものがOpenMPである。なお、このOpenMPは、並列実行されるスレッドがメモリを共有することを前提として並列化を行なう。
具体的には、ユーザーがソースコード中に記述した「プラグマ」(#pragmaで始まる行)で、並列化を指示し、これをコンパイラが、複数スレッドで同時実行するコードへと変換する。たとえばループなどによる計算を複数のスレッドに分割して同時に実行させる。基本的なアルゴリズムとしては、従来と同じ1スレッドによる処理として記述しておけば、複数スレッドへの分割自体は、生成されたバイナリが自動的に行なう。このため、シングルスレッドのプロセッサでも実行が可能なバイナリとなり、また、実行時に並列実行可能なスレッド数に応じて並列実行数が設定される。通常のシングルスレッドの逐次処理を記述するだけでいいため、複雑な並列化のためのプログラミングが必要ないというのがメリットである。
しかし、画像の変換や大規模な3Dシミュレーションなどでは、巨大な配列を扱うことが多い。このような場合、データ構造を工夫しないと、データをメモリ内で扱うことができなくなってしまう。
Ctは、こうした巨大なデータを扱うための機能を持ち、OpenMPにてコンパイル可能なソースコードを生成する言語である。
●巨大な配列を扱うとき
たとえば、倍精度浮動小数点(64bit=8byte)で表現された1,000×1,000×1,000の配列は、約8GBとなり、IA-32が持つ仮想メモリ空間4GBを越えてしまう。通常の言語が持つ配列は、メモリ内に要素を順番に並べた形式となっており、大きなデータを扱うには限界がある。そうなると、データはファイルとして記録し、その一部をメモリへと読み込んで処理しなくてはならなくなる。
しかし、科学技術計算などで扱う行列の中には、大半の要素がゼロで、ごく一部の要素のみが非ゼロの値を持つものがある。これを疎行列(Sparse Matrix)という。こうした行列は、値とインデックス(行列内での位置を表すもの。2次元行列なら行番号と列番号)の組としてデータを表現すると、小さなデータとして扱えることがある。1つの要素を表す効率はあまりよくないが、全体からみると値を持っている要素が少ないために結果的に、行列全体を小さなデータとして扱うことができる。こうしたデータ構造には、CSC/CSR(Compressed Sparse Column/Row)などがある。
また、計算で扱うデータは、必ずしも行列のような形とは限らず、リンクリスト(要素が他の要素を指し示すリンクを持つ形式)や木構造などもあり得る。
メモリ内に要素を順番に並べた配列は、単純なループで行列に対する処理を記述することができるが、CSC/CSR、あるいはリンクリストや木構造で計算を行なうには、少し複雑な処理を記述しなければならない。
Ctは、CSC/CSRやリンクリストなどを基本的なデータ形式として、データの構造に応じた行列演算などが行なえる。Ct内では、ベクトルや行列を扱い、個々の要素に関する演算を記述する必要はない。このため、元になる数式に近い形でプログラムを記述することができる。
Ctは、ソースコードを解析して、並列に実行可能な演算を見つけ出し、これを並列処理するOpenMPのソースコードを生成する。もともと、行列のようなデータとその演算が定義されているので、並列化可能な部分を見つけるのは比較的容易である。
●メニイコアやGPGPUでの利用を想定
Ctが想定するのは、多数の演算を並列実行可能なシステムで、それぞれの演算性能が均質なものだ。これは、IntelのいうメニイコアやGPUによる汎用演算などが相当する。
Ctを使うことで、科学技術計算や画像などの巨大なメディアデータに対する処理を実行システムを想定することなく記述可能になる。また、OpenMPは、実行時にスレッドへの分割を行なうため、よりコア数の多いシステムで動作させれば、それに応じた並列化実行が可能だ。
開発時には、行列やベクトルの形で計算式を記述でき、データ構造を気にする必要がない(もちろん、数学的に演算が正しく行なえるようなデータになっている必要はある)。このため、複雑な処理処理も簡単に記述可能だ。画像処理やシミュレーションなどが具体的な例として挙げられていた。
メニイコア、GPGPUといった多数のスレッドの同時実行が可能なシステムで並列処理プログラムを開発するのは容易ではない。スレッドの制御などをプログラマが全部把握するのは困難だし、本質的な処理以外の部分が大きくなり、効率的な開発が困難になる。しかし、Ctを使うと、プログラマは、並列化や実行制御を何も気にすることなくソフトウェアの開発が行なえるとしている。
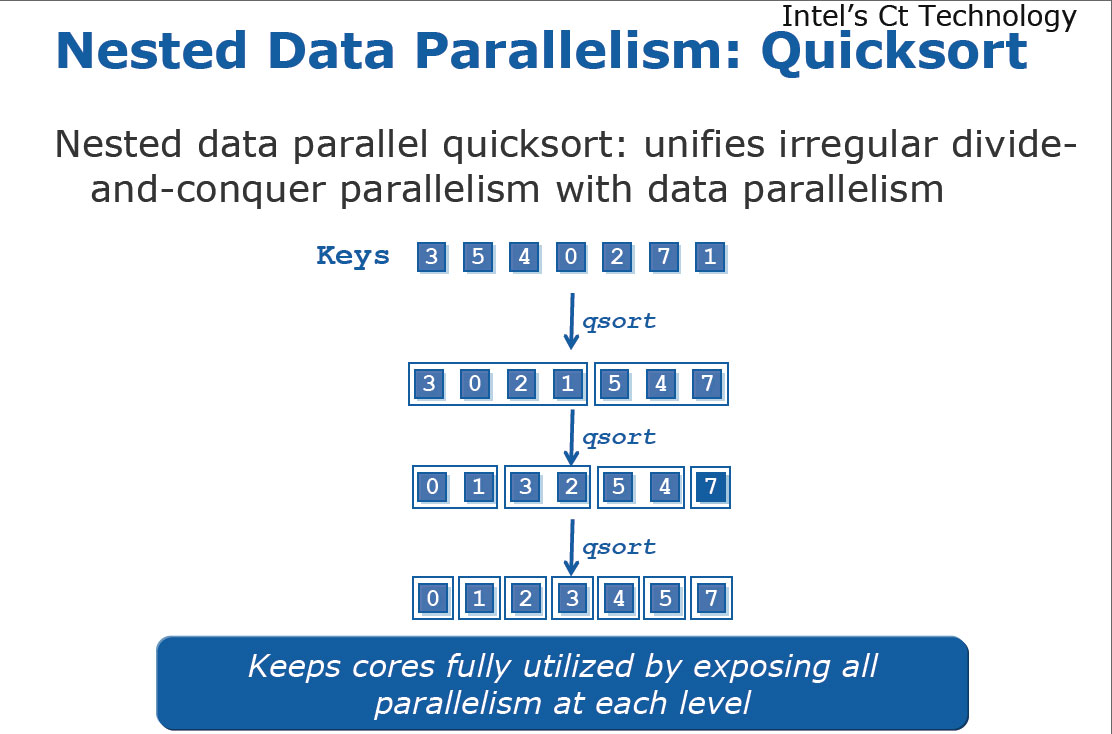 |
 |
| Ctを使うことで、クイックソートのような処理も可能になる。データ(Keys)を複数の領域に分割し、その中でQuick Sort処理を並列に適用していく。Ctはこのような配列の中に配列があるようなネストしたデータ構造をサポートする | Ctで6行のコードを書くと、それがOpenMPベースの172行のソースコードへと変換される。Ctでは、SSEを想定したC/C++のコードを出力できるという |
□IDF Fall 2007のホームページ(英文)
http://www.intel.com/idf/us/fall2007/
□関連記事
【9月20日】【IDF】メニイコア、ヘテロジニアスコアのプログラミング言語
http://pc.watch.impress.co.jp/docs/2007/0920/idf04.htm
【2006年8月29日】【海外】CPUはイノベーションの時代に
http://pc.watch.impress.co.jp/docs/2006/0829/kaigai298.htm
【2006年3月8日】【IDF】メインテーマは“新アーキテクチャ”
http://pc.watch.impress.co.jp/docs/2006/0308/idf02.htm
□IDF Spring 2007レポートリンク集
http://pc.watch.impress.co.jp/docs/2007/link/idfs.htm
(2007年9月25日)
[Reported by 塩田紳二]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2007 Impress Watch Corporation, an Impress Group company. All rights reserved.